 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Physics Event Classification with the CMS Open Data: Applying Image-based Deep Learning on Detector Data to Directly Classify Collision Events at the LHC
Jul 31, 2018
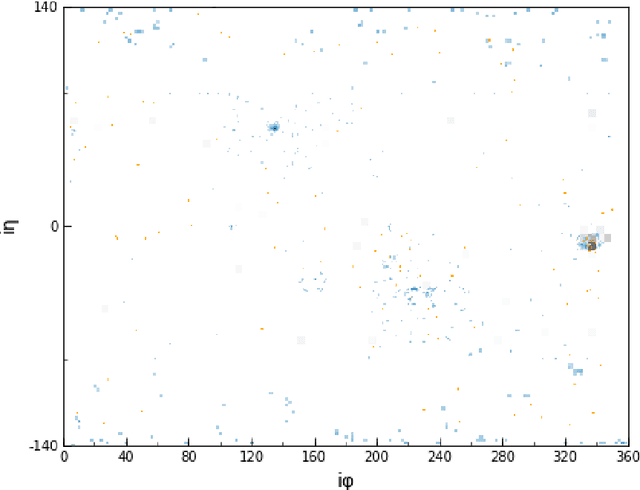

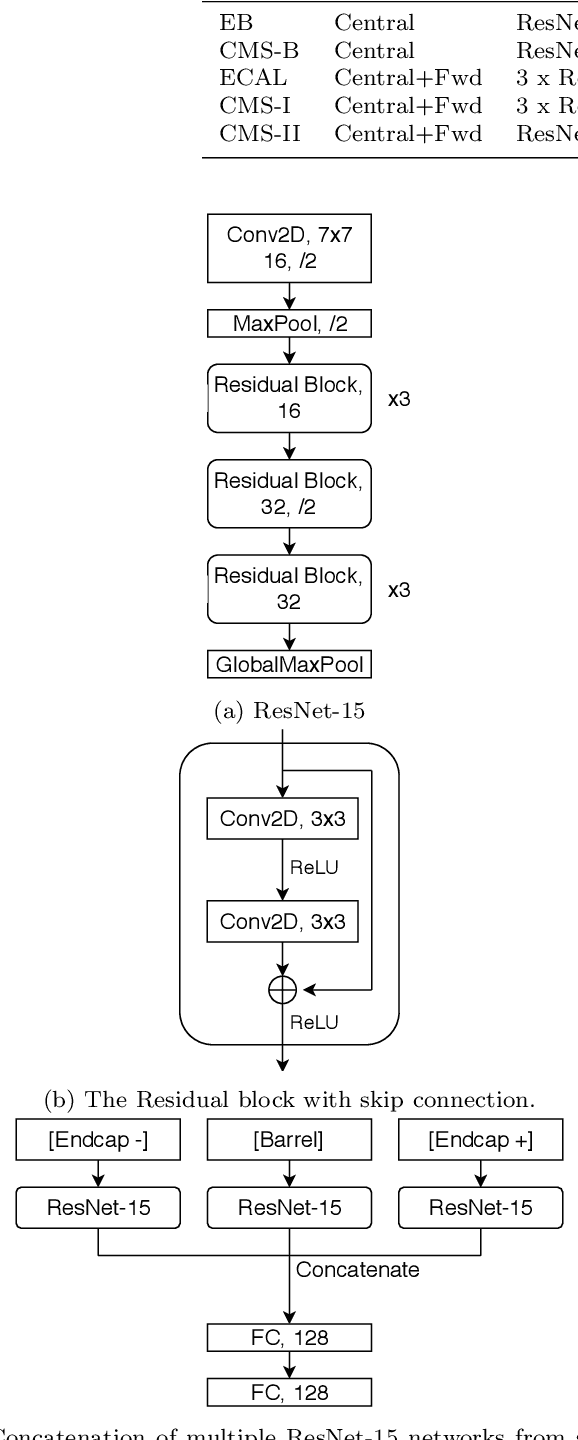
We describe the construction of a class of general, end-to-end, image-based physics event classifiers that directly use simulated raw detector data to discriminate signal and background processes in collision events at the LHC. To better understand what such classifiers are able to learn and to address some of the challenges associated with their use, we attempt to distinguish the Standard Model Higgs Boson decaying to two photons from its leading backgrounds using high-fidelity simulated detector data from the 2012 CMS Open Data. We demonstrate the ability of end-to-end classifiers to learn from the angular distribution of the electromagnetic showers, their shape, and the energy scale of their constituent hits, even when the underlying particles are not fully resolved.
Subject2Vec: Generative-Discriminative Approach from a Set of Image Patches to a Vector
Jun 28, 2018
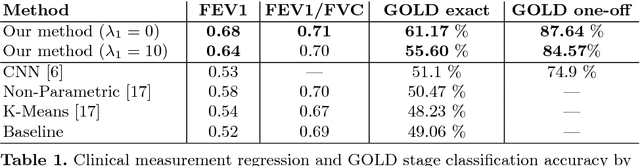
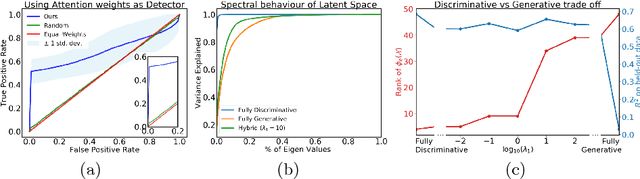

We propose an attention-based method that aggregates local image features to a subject-level representation for predicting disease severity. In contrast to classical deep learning that requires a fixed dimensional input, our method operates on a set of image patches; hence it can accommodate variable length input image without image resizing. The model learns a clinically interpretable subject-level representation that is reflective of the disease severity. Our model consists of three mutually dependent modules which regulate each other: (1) a discriminative network that learns a fixed-length representation from local features and maps them to disease severity; (2) an attention mechanism that provides interpretability by focusing on the areas of the anatomy that contribute the most to the prediction task; and (3) a generative network that encourages the diversity of the local latent features. The generative term ensures that the attention weights are non-degenerate while maintaining the relevance of the local regions to the disease severity. We train our model end-to-end in the context of a large-scale lung CT study of Chronic Obstructive Pulmonary Disease (COPD). Our model gives state-of-the art performance in predicting clinical measures of severity for COPD. The distribution of the attention provides the regional relevance of lung tissue to the clinical measurements.
Gradient Descent Learns One-hidden-layer CNN: Don't be Afraid of Spurious Local Minima
Jun 15, 2018
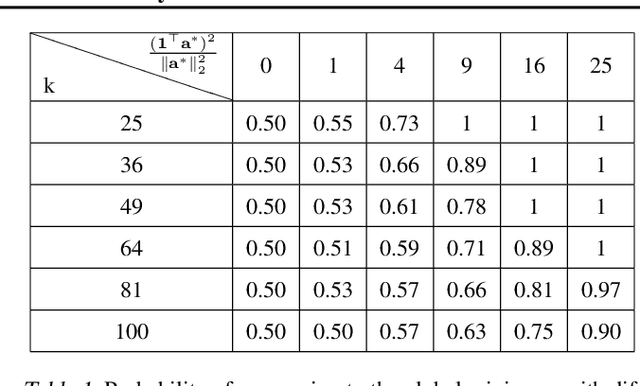
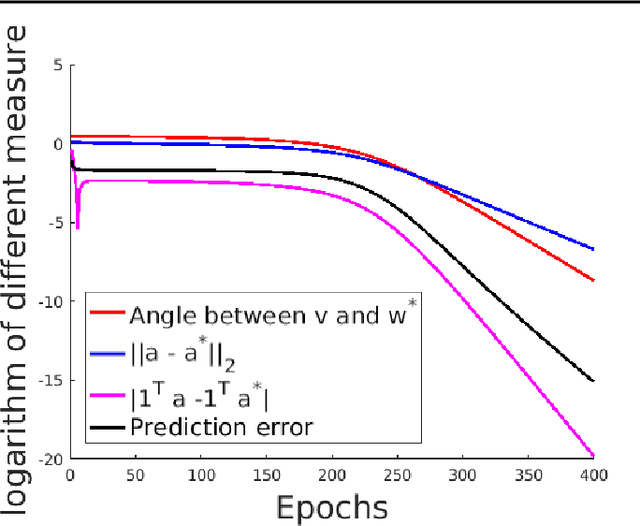
We consider the problem of learning a one-hidden-layer neural network with non-overlapping convolutional layer and ReLU activation, i.e., $f(\mathbf{Z}, \mathbf{w}, \mathbf{a}) = \sum_j a_j\sigma(\mathbf{w}^T\mathbf{Z}_j)$, in which both the convolutional weights $\mathbf{w}$ and the output weights $\mathbf{a}$ are parameters to be learned. When the labels are the outputs from a teacher network of the same architecture with fixed weights $(\mathbf{w}^*, \mathbf{a}^*)$, we prove that with Gaussian input $\mathbf{Z}$, there is a spurious local minimizer. Surprisingly, in the presence of the spurious local minimizer, gradient descent with weight normalization from randomly initialized weights can still be proven to recover the true parameters with constant probability, which can be boosted to probability $1$ with multiple restarts. We also show that with constant probability, the same procedure could also converge to the spurious local minimum, showing that the local minimum plays a non-trivial role in the dynamics of gradient descent. Furthermore, a quantitative analysis shows that the gradient descent dynamics has two phases: it starts off slow, but converges much faster after several iterations.
Neural Architecture Search with Bayesian Optimisation and Optimal Transport
Jun 10, 2018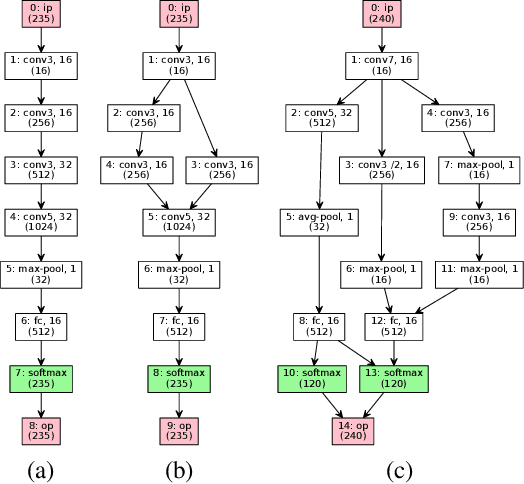


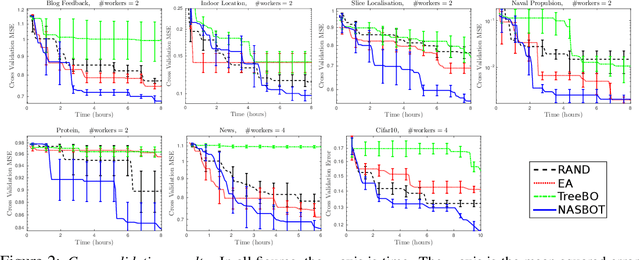
Bayesian Optimisation (BO) refers to a class of methods for global optimisation of a function $f$ which is only accessible via point evaluations. It is typically used in settings where $f$ is expensive to evaluate. A common use case for BO in machine learning is model selection, where it is not possible to analytically model the generalisation performance of a statistical model, and we resort to noisy and expensive training and validation procedures to choose the best model. Conventional BO methods have focused on Euclidean and categorical domains, which, in the context of model selection, only permits tuning scalar hyper-parameters of machine learning algorithms. However, with the surge of interest in deep learning, there is an increasing demand to tune neural network \emph{architectures}. In this work, we develop NASBOT, a Gaussian process based BO framework for neural architecture search. To accomplish this, we develop a distance metric in the space of neural network architectures which can be computed efficiently via an optimal transport program. This distance might be of independent interest to the deep learning community as it may find applications outside of BO. We demonstrate that NASBOT outperforms other alternatives for architecture search in several cross validation based model selection tasks on multi-layer perceptrons and convolutional neural networks.
Myopic Bayesian Design of Experiments via Posterior Sampling and Probabilistic Programming
May 25, 2018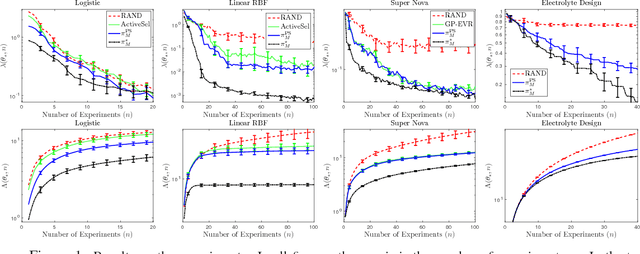
We design a new myopic strategy for a wide class of sequential design of experiment (DOE) problems, where the goal is to collect data in order to to fulfil a certain problem specific goal. Our approach, Myopic Posterior Sampling (MPS), is inspired by the classical posterior (Thompson) sampling algorithm for multi-armed bandits and leverages the flexibility of probabilistic programming and approximate Bayesian inference to address a broad set of problems. Empirically, this general-purpose strategy is competitive with more specialised methods in a wide array of DOE tasks, and more importantly, enables addressing complex DOE goals where no existing method seems applicable. On the theoretical side, we leverage ideas from adaptive submodularity and reinforcement learning to derive conditions under which MPS achieves sublinear regret against natural benchmark policies.
Deep Sets
Apr 14, 2018
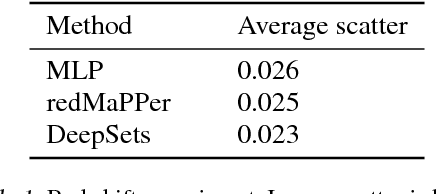
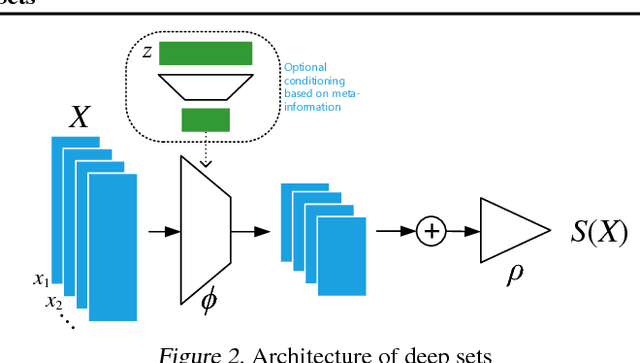
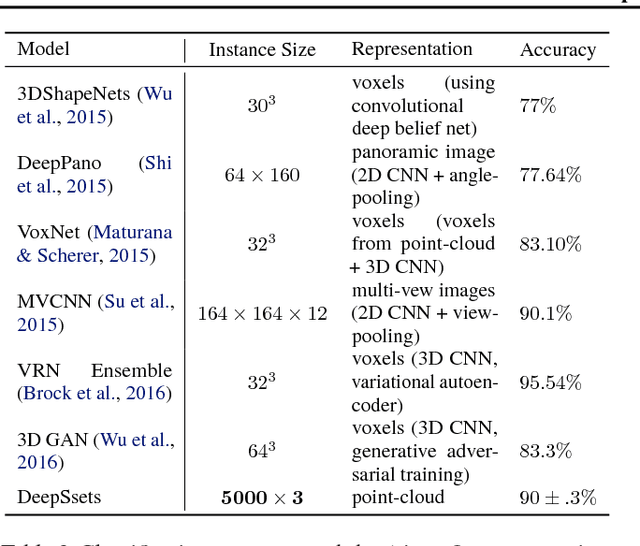
We study the problem of designing models for machine learning tasks defined on \emph{sets}. In contrast to traditional approach of operating on fixed dimensional vectors, we consider objective functions defined on sets that are invariant to permutations. Such problems are widespread, ranging from estimation of population statistics \cite{poczos13aistats}, to anomaly detection in piezometer data of embankment dams \cite{Jung15Exploration}, to cosmology \cite{Ntampaka16Dynamical,Ravanbakhsh16ICML1}. Our main theorem characterizes the permutation invariant functions and provides a family of functions to which any permutation invariant objective function must belong. This family of functions has a special structure which enables us to design a deep network architecture that can operate on sets and which can be deployed on a variety of scenarios including both unsupervised and supervised learning tasks. We also derive the necessary and sufficient conditions for permutation equivariance in deep models. We demonstrate the applicability of our method on population statistic estimation, point cloud classification, set expansion, and outlier detection.
Towards Understanding the Generalization Bias of Two Layer Convolutional Linear Classifiers with Gradient Descent
Feb 13, 2018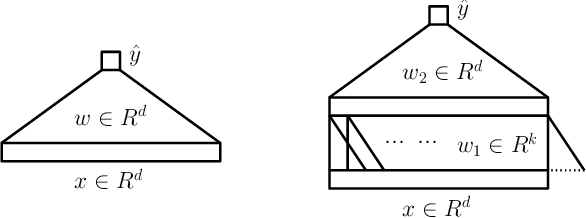
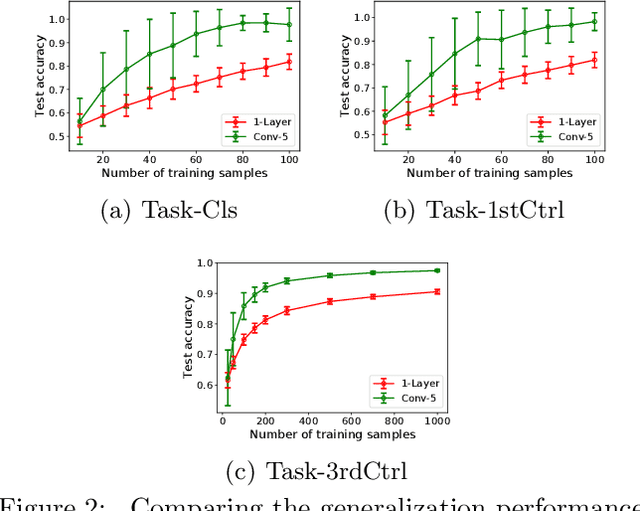
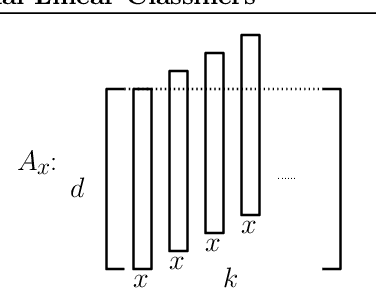
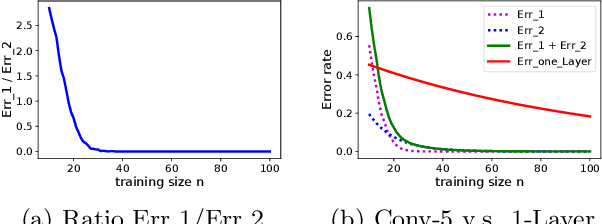
A major challenge in understanding the generalization of deep learning is to explain why (stochastic) gradient descent can exploit the network architecture to find solutions that have good generalization performance when using high capacity models. We find simple but realistic examples showing that this phenomenon exists even when learning linear classifiers --- between two linear networks with the same capacity, the one with a convolutional layer can generalize better than the other when the data distribution has some underlying spatial structure. We argue that this difference results from a combination of the convolution architecture, data distribution and gradient descent, all of which are necessary to be included in a meaningful analysis. We provide a general analysis of the generalization performance as a function of data distribution and convolutional filter size, given gradient descent as the optimization algorithm, then interpret the results using concrete examples. Experimental results show that our analysis is able to explain what happens in our introduced examples.
Bayesian Nonparametric Kernel-Learning
Jan 30, 2018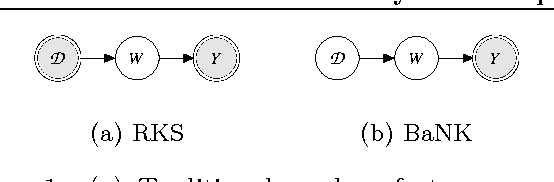

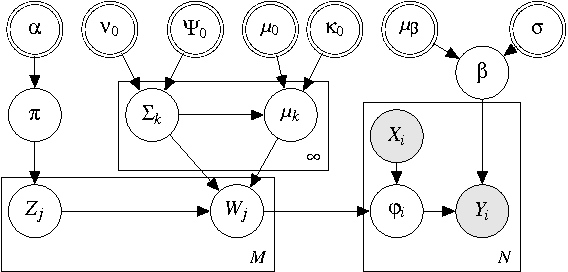

Kernel methods are ubiquitous tools in machine learning. However, there is often little reason for the common practice of selecting a kernel a priori. Even if a universal approximating kernel is selected, the quality of the finite sample estimator may be greatly affected by the choice of kernel. Furthermore, when directly applying kernel methods, one typically needs to compute a $N \times N$ Gram matrix of pairwise kernel evaluations to work with a dataset of $N$ instances. The computation of this Gram matrix precludes the direct application of kernel methods on large datasets, and makes kernel learning especially difficult. In this paper we introduce Bayesian nonparmetric kernel-learning (BaNK), a generic, data-driven framework for scalable learning of kernels. BaNK places a nonparametric prior on the spectral distribution of random frequencies allowing it to both learn kernels and scale to large datasets. We show that this framework can be used for large scale regression and classification tasks. Furthermore, we show that BaNK outperforms several other scalable approaches for kernel learning on a variety of real world datasets.
Estimating Cosmological Parameters from the Dark Matter Distribution
Nov 06, 2017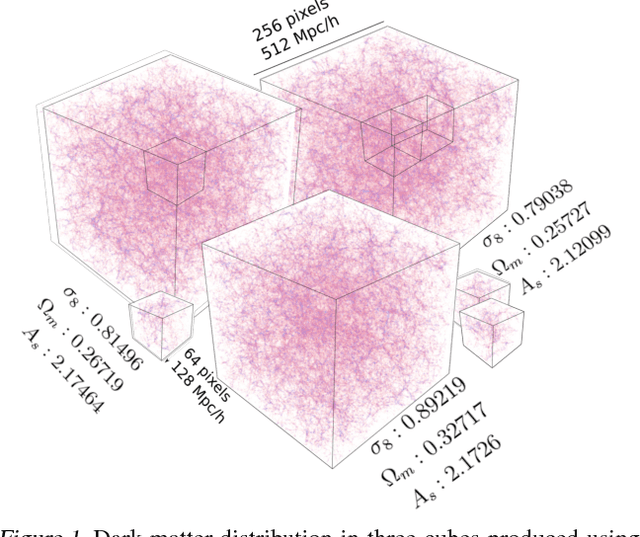
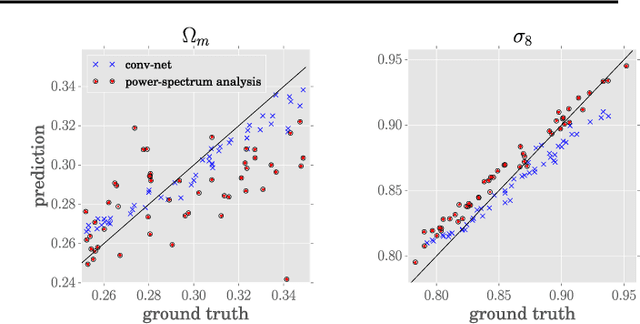

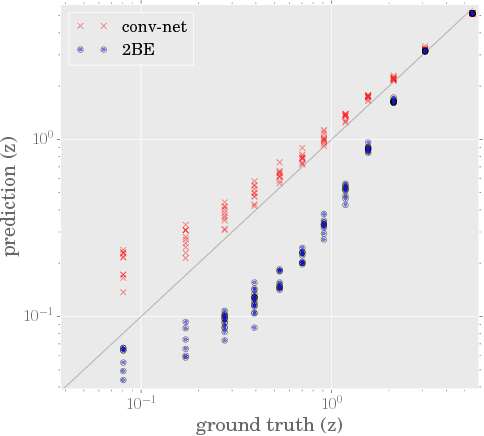
A grand challenge of the 21st century cosmology is to accurately estimate the cosmological parameters of our Universe. A major approach to estimating the cosmological parameters is to use the large-scale matter distribution of the Universe. Galaxy surveys provide the means to map out cosmic large-scale structure in three dimensions. Information about galaxy locations is typically summarized in a "single" function of scale, such as the galaxy correlation function or power-spectrum. We show that it is possible to estimate these cosmological parameters directly from the distribution of matter. This paper presents the application of deep 3D convolutional networks to volumetric representation of dark-matter simulations as well as the results obtained using a recently proposed distribution regression framework, showing that machine learning techniques are comparable to, and can sometimes outperform, maximum-likelihood point estimates using "cosmological models". This opens the way to estimating the parameters of our Universe with higher accuracy.
Gradient Descent Can Take Exponential Time to Escape Saddle Points
Nov 05, 2017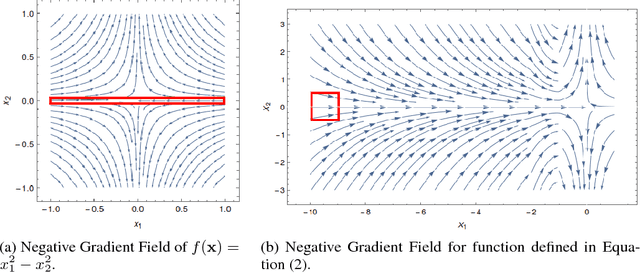
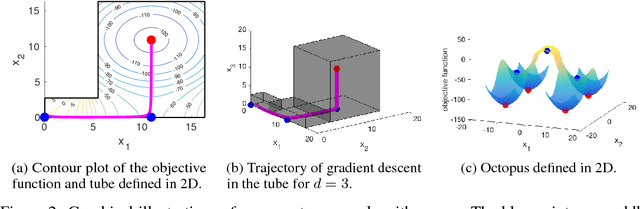
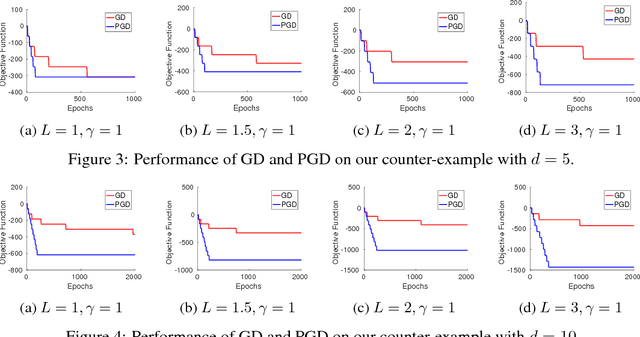
Although gradient descent (GD) almost always escapes saddle points asymptotically [Lee et al., 2016], this paper shows that even with fairly natural random initialization schemes and non-pathological functions, GD can be significantly slowed down by saddle points, taking exponential time to escape. On the other hand, gradient descent with perturbations [Ge et al., 2015, Jin et al., 2017] is not slowed down by saddle points - it can find an approximate local minimizer in polynomial time. This result implies that GD is inherently slower than perturbed GD, and justifies the importance of adding perturbations for efficient non-convex optimization. While our focus is theoretical, we also present experiments that illustrate our theoretical findings.