 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemistry-Inspired Diffusion with Non-Differentiable Guidance
Oct 09, 2024



Recent advances in diffusion models have shown remarkable potential in the conditional generation of novel molecules. These models can be guided in two ways: (i) explicitly, through additional features representing the condition, or (ii) implicitly, using a property predictor. However, training property predictors or conditional diffusion models requires an abundance of labeled data and is inherently challenging in real-world applications. We propose a novel approach that attenuates the limitations of acquiring large labeled datasets by leveraging domain knowledge from quantum chemistry as a non-differentiable oracle to guide an unconditional diffusion model. Instead of relying on neural networks, the oracle provides accurate guidance in the form of estimated gradients, allowing the diffusion process to sample from a conditional distribution specified by quantum chemistry. We show that this results in more precise conditional generation of novel and stable molecular structures. Our experiments demonstrate that our method: (1) significantly reduces atomic forces, enhancing the validity of generated molecules when used for stability optimization; (2) is compatible with both explicit and implicit guidance in diffusion models, enabling joint optimization of molecular properties and stability; and (3) generalizes effectively to molecular optimization tasks beyond stability optimization.
Reconstructing Galaxy Cluster Mass Maps using Score-based Generative Modeling
Oct 03, 2024



We present a novel approach to reconstruct gas and dark matter projected density maps of galaxy clusters using score-based generative modeling. Our diffusion model takes in mock SZ and X-ray images as conditional observations, and generates realizations of corresponding gas and dark matter maps by sampling from a learned data posterior. We train and validate the performance of our model by using mock data from a hydrodynamical cosmological simulation. The model accurately reconstructs both the mean and spread of the radial density profiles in the spatial domain to within 5\%, indicating that the model is able to distinguish between clusters of different sizes. In the spectral domain, the model achieves close-to-unity values for the bias and cross-correlation coefficients, indicating that the model can accurately probe cluster structures on both large and small scales. Our experiments demonstrate the ability of score models to learn a strong, nonlinear, and unbiased mapping between input observables and fundamental density distributions of galaxy clusters. These diffusion models can be further fine-tuned and generalized to not only take in additional observables as inputs, but also real observations and predict unknown density distributions of galaxy clusters.
Recovering Time-Varying Networks From Single-Cell Data
Oct 01, 2024Gene regulation is a dynamic process that underlies all aspects of human development, disease response, and other key biological processes. The reconstruction of temporal gene regulatory networks has conventionally relied on regression analysis, graphical models, or other types of relevance networks. With the large increase in time series single-cell data, new approaches are needed to address the unique scale and nature of this data for reconstructing such networks. Here, we develop a deep neural network, Marlene, to infer dynamic graphs from time series single-cell gene expression data. Marlene constructs directed gene networks using a self-attention mechanism where the weights evolve over time using recurrent units. By employing meta learning, the model is able to recover accurate temporal networks even for rare cell types. In addition, Marlene can identify gene interactions relevant to specific biological responses, including COVID-19 immune response, fibrosis, and aging.
GraphBPE: Molecular Graphs Meet Byte-Pair Encoding
Jul 26, 2024



With the increasing attention to molecular machine learning, various innovations have been made in designing better models or proposing more comprehensive benchmarks. However, less is studied on the data preprocessing schedule for molecular graphs, where a different view of the molecular graph could potentially boost the model's performance. Inspired by the Byte-Pair Encoding (BPE) algorithm, a subword tokenization method popularly adopted in Natural Language Processing, we propose GraphBPE, which tokenizes a molecular graph into different substructures and acts as a preprocessing schedule independent of the model architectures. Our experiments on 3 graph-level classification and 3 graph-level regression datasets show that data preprocessing could boost the performance of models for molecular graphs, and GraphBPE is effective for small classification datasets and it performs on par with other tokenization methods across different model architectures.
Graph Attention with Random Rewiring
Jul 08, 2024Graph Neural Networks (GNNs) have become fundamental in graph-structured deep learning. Key paradigms of modern GNNs include message passing, graph rewiring, and Graph Transformers. This paper introduces Graph-Rewiring Attention with Stochastic Structures (GRASS), a novel GNN architecture that combines the advantages of these three paradigms. GRASS rewires the input graph by superimposing a random regular graph, enhancing long-range information propagation while preserving structural features of the input graph. It also employs a unique additive attention mechanism tailored for graph-structured data, providing a graph inductive bias while remaining computationally efficient. Our empirical evaluations demonstrate that GRASS achieves state-of-the-art performance on multiple benchmark datasets, confirming its practical efficacy.
The student becomes the master: Matching GPT3 on Scientific Factual Error Correction
May 24, 2023



Due to the prohibitively high cost of creating error correction datasets, most Factual Claim Correction methods rely on a powerful verification model to guide the correction process. This leads to a significant drop in performance in domains like Scientific Claim Correction, where good verification models do not always exist. In this work, we introduce a claim correction system that makes no domain assumptions and does not require a verifier but is able to outperform existing methods by an order of magnitude -- achieving 94% correction accuracy on the SciFact dataset, and 62.5% on the SciFact-Open dataset, compared to the next best methods 0.5% and 1.50% respectively. Our method leverages the power of prompting with LLMs during training to create a richly annotated dataset that can be used for fully supervised training and regularization. We additionally use a claim-aware decoding procedure to improve the quality of corrected claims. Our method is competitive with the very LLM that was used to generate the annotated dataset -- with GPT3.5 achieving 89.5% and 60% correction accuracy on SciFact and SciFact-Open, despite using 1250 times as many parameters as our model.
On the Algorithmic Stability and Generalization of Adaptive Optimization Methods
Nov 08, 2022



Despite their popularity in deep learning and machine learning in general, the theoretical properties of adaptive optimizers such as Adagrad, RMSProp, Adam or AdamW are not yet fully understood. In this paper, we develop a novel framework to study the stability and generalization of these optimization methods. Based on this framework, we show provable guarantees about such properties that depend heavily on a single parameter $\beta_2$. Our empirical experiments support our claims and provide practical insights into the stability and generalization properties of adaptive optimization methods.
Coarse-to-Fine Curriculum Learning
Jun 08, 2021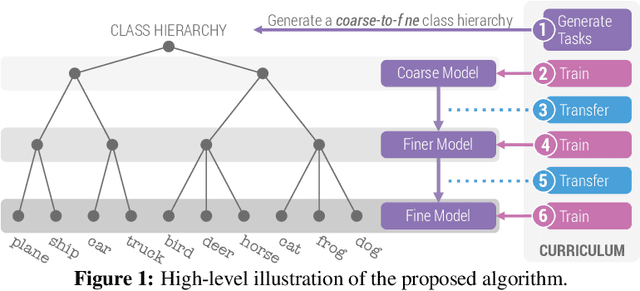

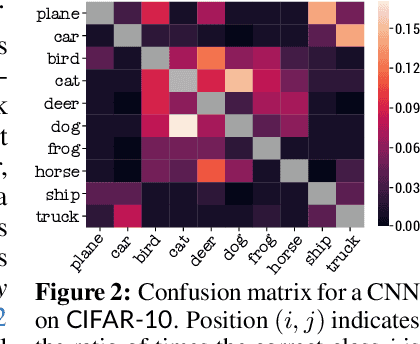
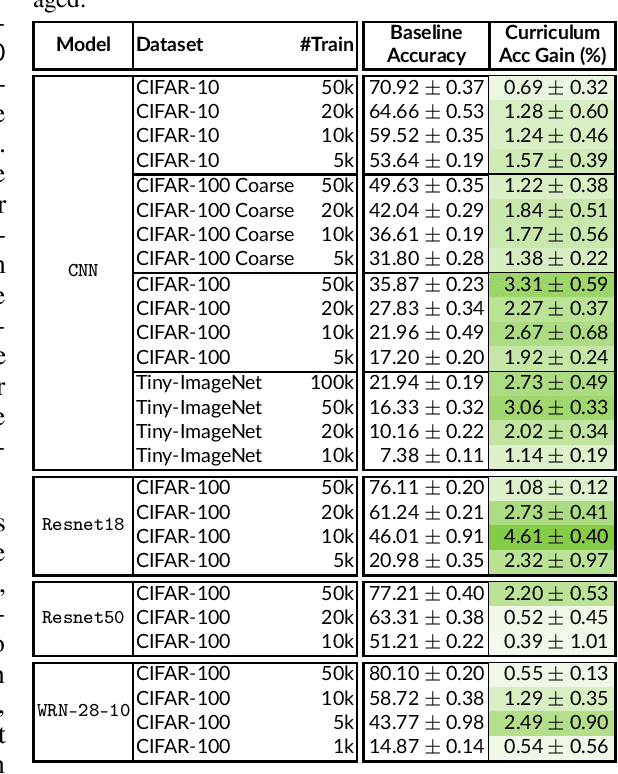
When faced with learning challenging new tasks, humans often follow sequences of steps that allow them to incrementally build up the necessary skills for performing these new tasks. However, in machine learning, models are most often trained to solve the target tasks directly.Inspired by human learning, we propose a novel curriculum learning approach which decomposes challenging tasks into sequences of easier intermediate goals that are used to pre-train a model before tackling the target task. We focus on classification tasks, and design the intermediate tasks using an automatically constructed label hierarchy. We train the model at each level of the hierarchy, from coarse labels to fine labels, transferring acquired knowledge across these levels. For instance, the model will first learn to distinguish animals from objects, and then use this acquired knowledge when learning to classify among more fine-grained classes such as cat, dog, car, and truck. Most existing curriculum learning algorithms for supervised learning consist of scheduling the order in which the training examples are presented to the model. In contrast, our approach focuses on the output space of the model. We evaluate our method on several established datasets and show significant performance gains especially on classification problems with many labels. We also evaluate on a new synthetic dataset which allows us to study multiple aspects of our method.
Re-TACRED: Addressing Shortcomings of the TACRED Dataset
Apr 16, 2021
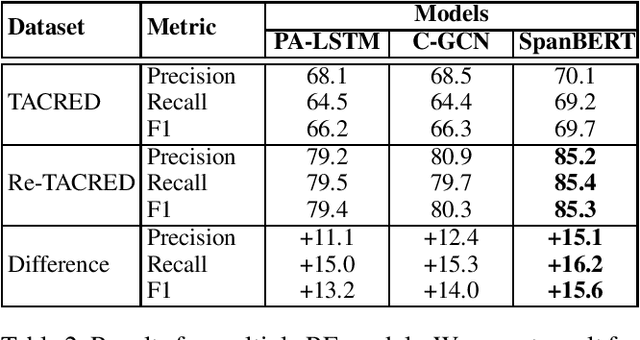
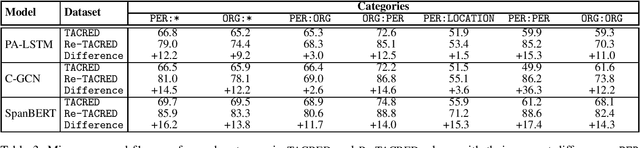
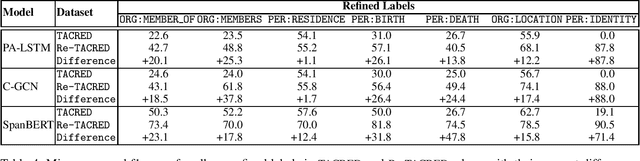
TACRED is one of the largest and most widely used sentence-level relation extraction datasets. Proposed models that are evaluated using this dataset consistently set new state-of-the-art performance. However, they still exhibit large error rates despite leveraging external knowledge and unsupervised pretraining on large text corpora. A recent study suggested that this may be due to poor dataset quality. The study observed that over 50% of the most challenging sentences from the development and test sets are incorrectly labeled and account for an average drop of 8% f1-score in model performance. However, this study was limited to a small biased sample of 5k (out of a total of 106k) sentences, substantially restricting the generalizability and broader implications of its findings. In this paper, we address these shortcomings by: (i) performing a comprehensive study over the whole TACRED dataset, (ii) proposing an improved crowdsourcing strategy and deploying it to re-annotate the whole dataset, and (iii) performing a thorough analysis to understand how correcting the TACRED annotations affects previously published results. After verification, we observed that 23.9% of TACRED labels are incorrect. Moreover, evaluating several models on our revised dataset yields an average f1-score improvement of 14.3% and helps uncover significant relationships between the different models (rather than simply offsetting or scaling their scores by a constant factor). Finally, aside from our analysis we also release Re-TACRED, a new completely re-annotated version of the TACRED dataset that can be used to perform reliable evaluation of relation extraction models.
StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer
Apr 12, 2021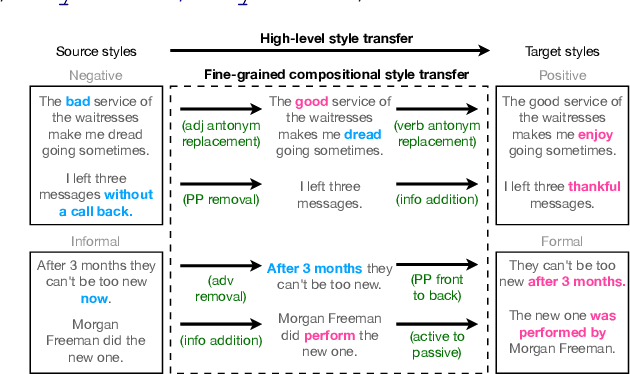
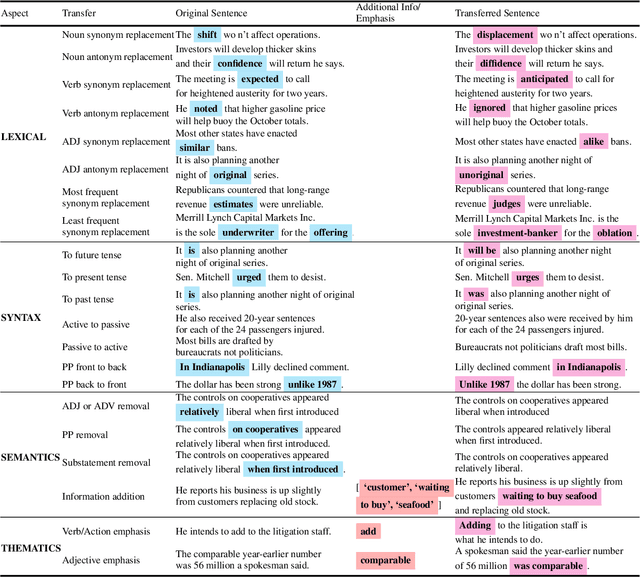
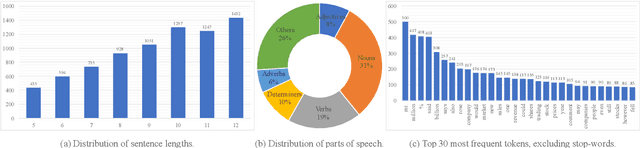
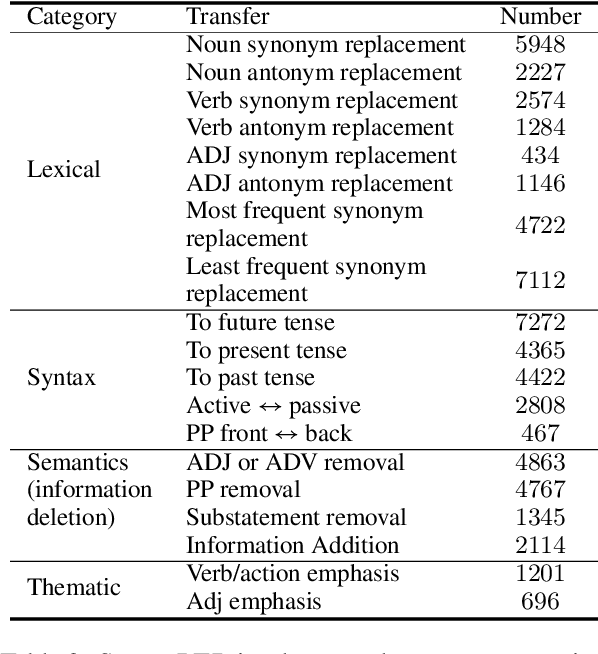
Text style transfer aims to controllably generate text with targeted stylistic changes while maintaining core meaning from the source sentence constant. Many of the existing style transfer benchmarks primarily focus on individual high-level semantic changes (e.g. positive to negative), which enable controllability at a high level but do not offer fine-grained control involving sentence structure, emphasis, and content of the sentence. In this paper, we introduce a large-scale benchmark, StylePTB, with (1) paired sentences undergoing 21 fine-grained stylistic changes spanning atomic lexical, syntactic, semantic, and thematic transfers of text, as well as (2) compositions of multiple transfers which allow modeling of fine-grained stylistic changes as building blocks for more complex, high-level transfers. By benchmarking existing methods on StylePTB, we find that they struggle to model fine-grained changes and have an even more difficult time composing multiple styles. As a result, StylePTB brings novel challenges that we hope will encourage future research in controllable text style transfer, compositional models, and learning disentangled representations. Solving these challenges would present important steps towards controllable text generation.