 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeamless Deception: Larger Language Models Are Better Knowledge Concealers
Mar 15, 2026Language Models (LMs) may acquire harmful knowledge, and yet feign ignorance of these topics when under audit. Inspired by the recent discovery of deception-related behaviour patterns in LMs, we aim to train classifiers that detect when a LM is actively concealing knowledge. Initial findings on smaller models show that classifiers can detect concealment more reliably than human evaluators, with gradient-based concealment proving easier to identify than prompt-based methods. However, contrary to prior work, we find that the classifiers do not reliably generalize to unseen model architectures and topics of hidden knowledge. Most concerningly, the identifiable traces associated with concealment become fainter as the models increase in scale, with the classifiers achieving no better than random performance on any model exceeding 70 billion parameters. Our results expose a key limitation in black-box-only auditing of LMs and highlight the need to develop robust methods to detect models that are actively hiding the knowledge they contain.
A Representation Sharpening Framework for Zero Shot Dense Retrieval
Nov 07, 2025Zero-shot dense retrieval is a challenging setting where a document corpus is provided without relevant queries, necessitating a reliance on pretrained dense retrievers (DRs). However, since these DRs are not trained on the target corpus, they struggle to represent semantic differences between similar documents. To address this failing, we introduce a training-free representation sharpening framework that augments a document's representation with information that helps differentiate it from similar documents in the corpus. On over twenty datasets spanning multiple languages, the representation sharpening framework proves consistently superior to traditional retrieval, setting a new state-of-the-art on the BRIGHT benchmark. We show that representation sharpening is compatible with prior approaches to zero-shot dense retrieval and consistently improves their performance. Finally, we address the performance-cost tradeoff presented by our framework and devise an indexing-time approximation that preserves the majority of our performance gains over traditional retrieval, yet suffers no additional inference-time cost.
Language Models Can Predict Their Own Behavior
Feb 18, 2025



Autoregressive Language Models output text by sequentially predicting the next token to generate, with modern methods like Chain-of-Thought (CoT) prompting achieving state-of-the-art reasoning capabilities by scaling the number of generated tokens. However, are there times when we can infer how the model will behave (e.g. abstain from answering a question) early in the computation, making generation unnecessary? We show that internal representation of input tokens alone can often precisely predict, not just the next token, but eventual behavior over the entire output sequence. We leverage this capacity and learn probes on internal states to create early warning (and exit) systems. Specifically, if the probes can confidently estimate the way the LM is going to behave, then the system will avoid generating tokens altogether and return the estimated behavior instead. On 27 text classification datasets spanning five different tasks, we apply this method to estimate the eventual answer of an LM under CoT prompting, reducing inference costs by 65% (average) while suffering an accuracy loss of no more than 1.4% (worst case). We demonstrate the potential of this method to pre-emptively identify when a model will abstain from answering a question, fail to follow output format specifications, or give a low-confidence response. We explore the limits of this capability, showing that probes generalize to unseen datasets, but perform worse when LM outputs are longer and struggle to predict properties that require access to knowledge that the models themselves lack. Encouragingly, performance scales with model size, suggesting applicability to the largest of models
A Little Human Data Goes A Long Way
Oct 17, 2024



Faced with an expensive human annotation process, creators of NLP systems increasingly turn to synthetic data generation. While this method shows promise, the extent to which synthetic data can replace human annotation is poorly understood. We investigate the use of synthetic data in Fact Verification (FV) and Question Answering (QA) by studying the effects of incrementally replacing human generated data with synthetic points on eight diverse datasets. Strikingly, replacing up to 90% of the training data only marginally decreases performance, but replacing the final 10% leads to severe declines. We find that models trained on purely synthetic data can be reliably improved by including as few as 125 human generated data points. We show that matching the performance gain of just a little additional human data (only 200 points) requires an order of magnitude more synthetic data and estimate price ratios at which human annotation would be a more cost-effective solution. Our results suggest that even when human annotation at scale is infeasible, there is great value to having a small proportion of the dataset being human generated.
Controllable Text Generation in the Instruction-Tuning Era
May 02, 2024While most research on controllable text generation has focused on steering base Language Models, the emerging instruction-tuning and prompting paradigm offers an alternate approach to controllability. We compile and release ConGenBench, a testbed of 17 different controllable generation tasks, using a subset of it to benchmark the performance of 9 different baselines and methods on Instruction-tuned Language Models. To our surprise, we find that prompting-based approaches outperform controllable text generation methods on most datasets and tasks, highlighting a need for research on controllable text generation with Instruction-tuned Language Models in specific. Prompt-based approaches match human performance on most stylistic tasks while lagging on structural tasks, foregrounding a need to study more varied constraints and more challenging stylistic tasks. To facilitate such research, we provide an algorithm that uses only a task dataset and a Large Language Model with in-context capabilities to automatically generate a constraint dataset. This method eliminates the fields dependence on pre-curated constraint datasets, hence vastly expanding the range of constraints that can be studied in the future.
FeedbackLogs: Recording and Incorporating Stakeholder Feedback into Machine Learning Pipelines
Jul 28, 2023



Even though machine learning (ML) pipelines affect an increasing array of stakeholders, there is little work on how input from stakeholders is recorded and incorporated. We propose FeedbackLogs, addenda to existing documentation of ML pipelines, to track the input of multiple stakeholders. Each log records important details about the feedback collection process, the feedback itself, and how the feedback is used to update the ML pipeline. In this paper, we introduce and formalise a process for collecting a FeedbackLog. We also provide concrete use cases where FeedbackLogs can be employed as evidence for algorithmic auditing and as a tool to record updates based on stakeholder feedback.
PromptNER: Prompting For Named Entity Recognition
May 24, 2023



In a surprising turn, Large Language Models (LLMs) together with a growing arsenal of prompt-based heuristics now offer powerful off-the-shelf approaches providing few-shot solutions to myriad classic NLP problems. However, despite promising early results, these LLM-based few-shot methods remain far from the state of the art in Named Entity Recognition (NER), where prevailing methods include learning representations via end-to-end structural understanding and fine-tuning on standard labeled corpora. In this paper, we introduce PromptNER, a new state-of-the-art algorithm for few-Shot and cross-domain NER. To adapt to any new NER task PromptNER requires a set of entity definitions in addition to the standard few-shot examples. Given a sentence, PromptNER prompts an LLM to produce a list of potential entities along with corresponding explanations justifying their compatibility with the provided entity type definitions. Remarkably, PromptNER achieves state-of-the-art performance on few-shot NER, achieving an 11% (absolute) improvement in F1 score on the ConLL dataset, and a 10% (absolute) improvement on the FewNERD dataset. PromptNER also moves the state of the art on Cross Domain NER, outperforming all prior methods (including those not limited to the few-shot setting), setting a new mark on all 5 CrossNER target domains, with an average F1 gain of 9%, despite using less than 2% of the available data.
The student becomes the master: Matching GPT3 on Scientific Factual Error Correction
May 24, 2023



Due to the prohibitively high cost of creating error correction datasets, most Factual Claim Correction methods rely on a powerful verification model to guide the correction process. This leads to a significant drop in performance in domains like Scientific Claim Correction, where good verification models do not always exist. In this work, we introduce a claim correction system that makes no domain assumptions and does not require a verifier but is able to outperform existing methods by an order of magnitude -- achieving 94% correction accuracy on the SciFact dataset, and 62.5% on the SciFact-Open dataset, compared to the next best methods 0.5% and 1.50% respectively. Our method leverages the power of prompting with LLMs during training to create a richly annotated dataset that can be used for fully supervised training and regularization. We additionally use a claim-aware decoding procedure to improve the quality of corrected claims. Our method is competitive with the very LLM that was used to generate the annotated dataset -- with GPT3.5 achieving 89.5% and 60% correction accuracy on SciFact and SciFact-Open, despite using 1250 times as many parameters as our model.
A Solver + Gradient Descent Training Algorithm for Deep Neural Networks
Jul 07, 2022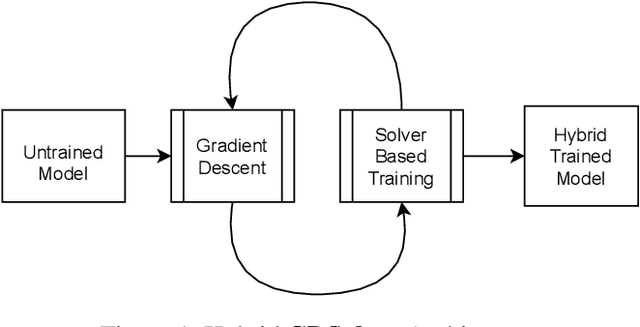
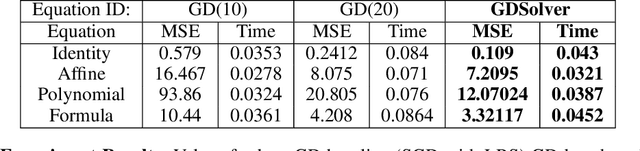

We present a novel hybrid algorithm for training Deep Neural Networks that combines the state-of-the-art Gradient Descent (GD) method with a Mixed Integer Linear Programming (MILP) solver, outperforming GD and variants in terms of accuracy, as well as resource and data efficiency for both regression and classification tasks. Our GD+Solver hybrid algorithm, called GDSolver, works as follows: given a DNN $D$ as input, GDSolver invokes GD to partially train $D$ until it gets stuck in a local minima, at which point GDSolver invokes an MILP solver to exhaustively search a region of the loss landscape around the weight assignments of $D$'s final layer parameters with the goal of tunnelling through and escaping the local minima. The process is repeated until desired accuracy is achieved. In our experiments, we find that GDSolver not only scales well to additional data and very large model sizes, but also outperforms all other competing methods in terms of rates of convergence and data efficiency. For regression tasks, GDSolver produced models that, on average, had 31.5% lower MSE in 48% less time, and for classification tasks on MNIST and CIFAR10, GDSolver was able to achieve the highest accuracy over all competing methods, using only 50% of the training data that GD baselines required.
Logic Guided Genetic Algorithms
Oct 21, 2020
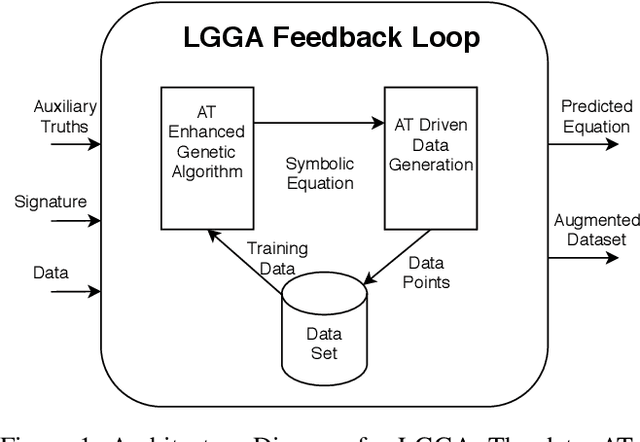
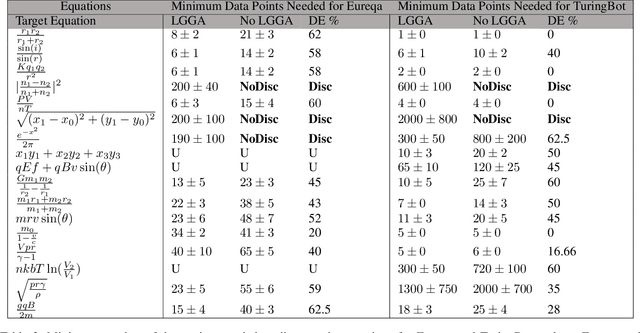
We present a novel Auxiliary Truth enhanced Genetic Algorithm (GA) that uses logical or mathematical constraints as a means of data augmentation as well as to compute loss (in conjunction with the traditional MSE), with the aim of increasing both data efficiency and accuracy of symbolic regression (SR) algorithms. Our method, logic-guided genetic algorithm (LGGA), takes as input a set of labelled data points and auxiliary truths (ATs) (mathematical facts known a priori about the unknown function the regressor aims to learn) and outputs a specially generated and curated dataset that can be used with any SR method. Three key insights underpin our method: first, SR users often know simple ATs about the function they are trying to learn. Second, whenever an SR system produces a candidate equation inconsistent with these ATs, we can compute a counterexample to prove the inconsistency, and further, this counterexample may be used to augment the dataset and fed back to the SR system in a corrective feedback loop. Third, the value addition of these ATs is that their use in both the loss function and the data augmentation process leads to better rates of convergence, accuracy, and data efficiency. We evaluate LGGA against state-of-the-art SR tools, namely, Eureqa and TuringBot on 16 physics equations from "The Feynman Lectures on Physics" book. We find that using these SR tools in conjunction with LGGA results in them solving up to 30.0% more equations, needing only a fraction of the amount of data compared to the same tool without LGGA, i.e., resulting in up to a 61.9% improvement in data efficiency.