 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeglassoformer: a query-sparse transformer for post-fault power grid voltage prediction
Jan 22, 2022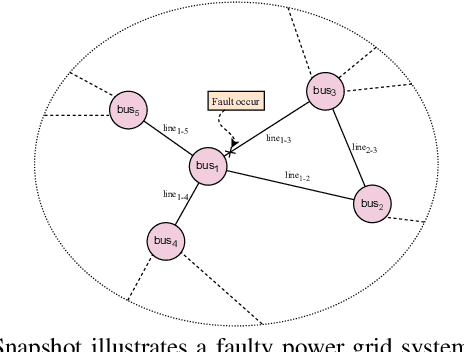
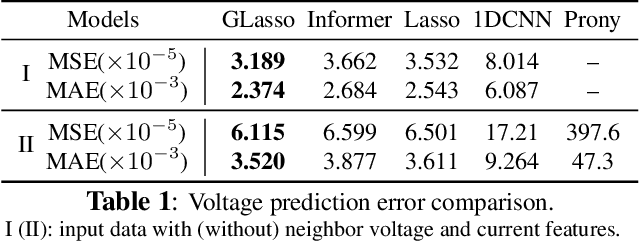
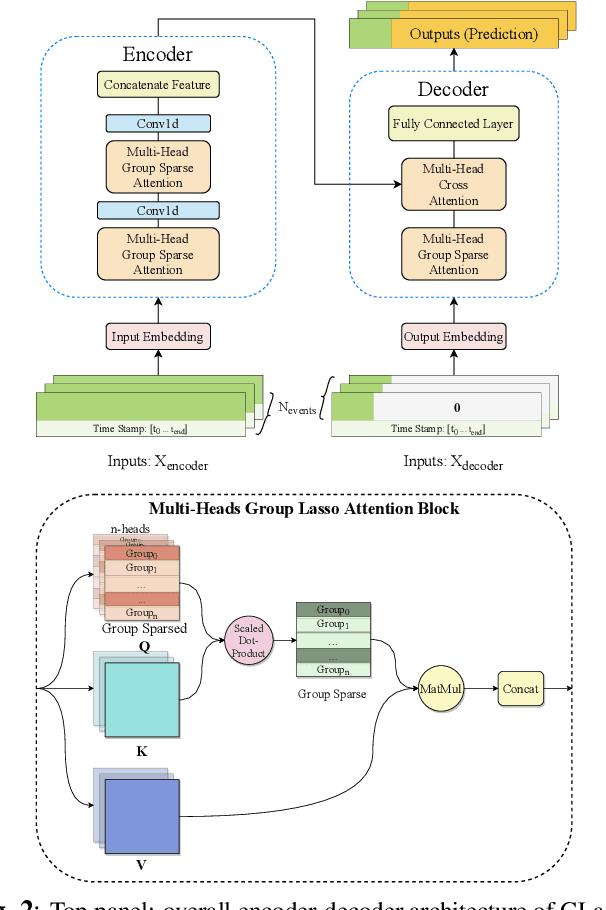
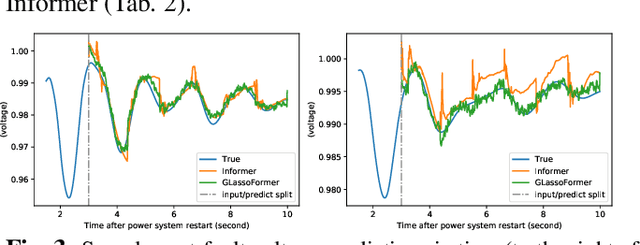
We propose GLassoformer, a novel and efficient transformer architecture leveraging group Lasso regularization to reduce the number of queries of the standard self-attention mechanism. Due to the sparsified queries, GLassoformer is more computationally efficient than the standard transformers. On the power grid post-fault voltage prediction task, GLassoformer shows remarkably better prediction than many existing benchmark algorithms in terms of accuracy and stability.
Efficient and Reliable Overlay Networks for Decentralized Federated Learning
Dec 12, 2021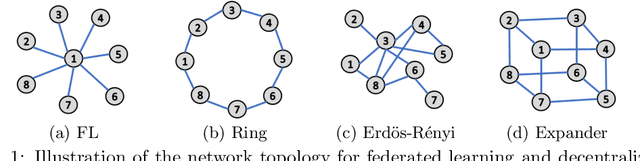
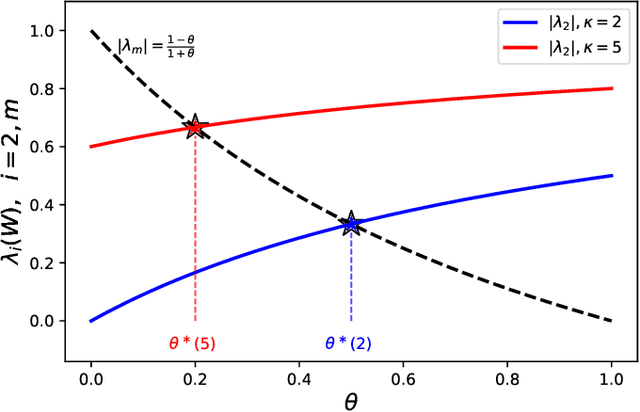
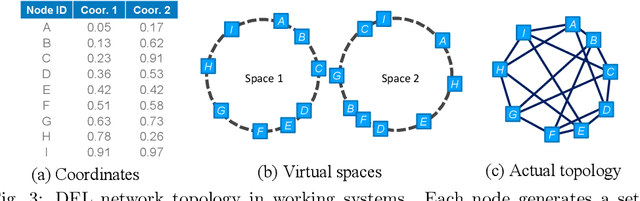
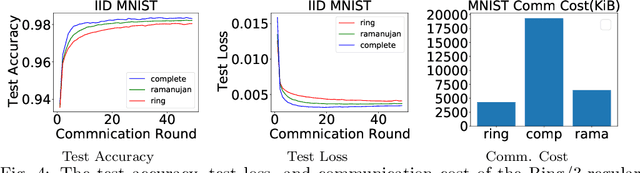
We propose near-optimal overlay networks based on $d$-regular expander graphs to accelerate decentralized federated learning (DFL) and improve its generalization. In DFL a massive number of clients are connected by an overlay network, and they solve machine learning problems collaboratively without sharing raw data. Our overlay network design integrates spectral graph theory and the theoretical convergence and generalization bounds for DFL. As such, our proposed overlay networks accelerate convergence, improve generalization, and enhance robustness to clients failures in DFL with theoretical guarantees. Also, we present an efficient algorithm to convert a given graph to a practical overlay network and maintaining the network topology after potential client failures. We numerically verify the advantages of DFL with our proposed networks on various benchmark tasks, ranging from image classification to language modeling using hundreds of clients.
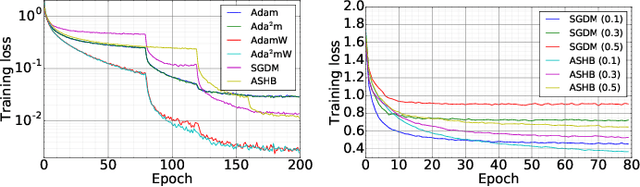
How Does Momentum Benefit Deep Neural Networks Architecture Design? A Few Case Studies
Oct 19, 2021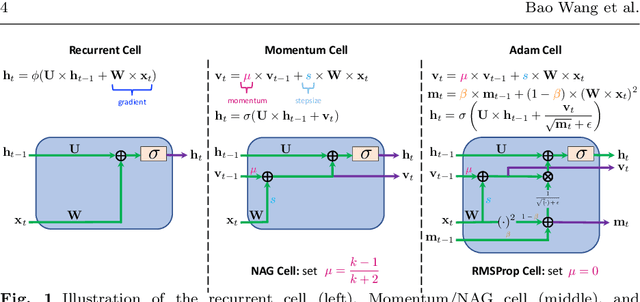
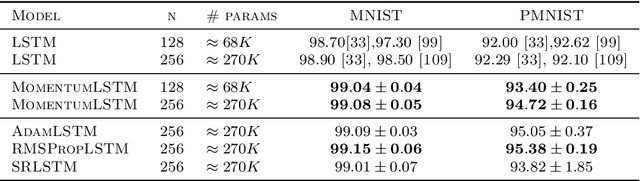
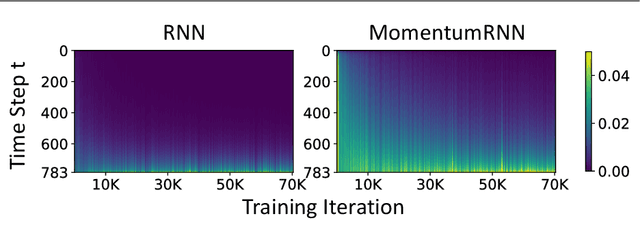
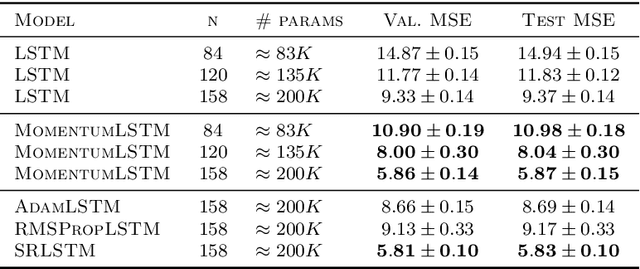
We present and review an algorithmic and theoretical framework for improving neural network architecture design via momentum. As case studies, we consider how momentum can improve the architecture design for recurrent neural networks (RNNs), neural ordinary differential equations (ODEs), and transformers. We show that integrating momentum into neural network architectures has several remarkable theoretical and empirical benefits, including 1) integrating momentum into RNNs and neural ODEs can overcome the vanishing gradient issues in training RNNs and neural ODEs, resulting in effective learning long-term dependencies. 2) momentum in neural ODEs can reduce the stiffness of the ODE dynamics, which significantly enhances the computational efficiency in training and testing. 3) momentum can improve the efficiency and accuracy of transformers.
Training Deep Neural Networks with Adaptive Momentum Inspired by the Quadratic Optimization
Oct 18, 2021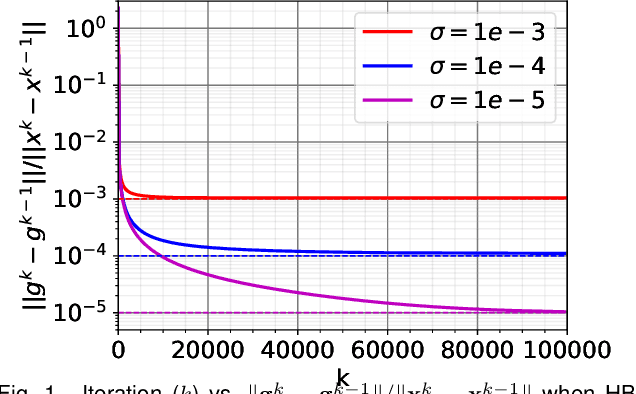


Heavy ball momentum is crucial in accelerating (stochastic) gradient-based optimization algorithms for machine learning. Existing heavy ball momentum is usually weighted by a uniform hyperparameter, which relies on excessive tuning. Moreover, the calibrated fixed hyperparameter may not lead to optimal performance. In this paper, to eliminate the effort for tuning the momentum-related hyperparameter, we propose a new adaptive momentum inspired by the optimal choice of the heavy ball momentum for quadratic optimization. Our proposed adaptive heavy ball momentum can improve stochastic gradient descent (SGD) and Adam. SGD and Adam with the newly designed adaptive momentum are more robust to large learning rates, converge faster, and generalize better than the baselines. We verify the efficiency of SGD and Adam with the new adaptive momentum on extensive machine learning benchmarks, including image classification, language modeling, and machine translation. Finally, we provide convergence guarantees for SGD and Adam with the proposed adaptive momentum.
Heavy Ball Neural Ordinary Differential Equations
Oct 10, 2021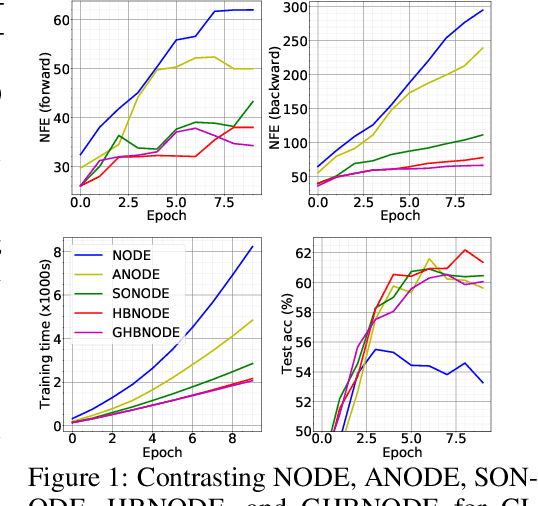

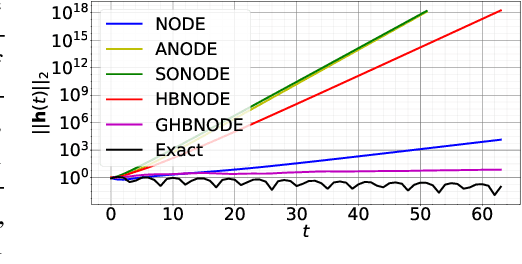
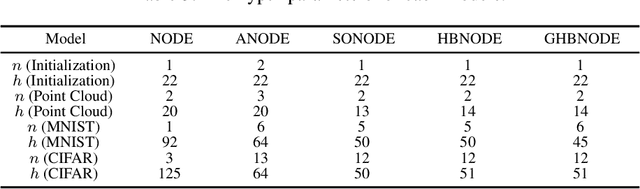
We propose heavy ball neural ordinary differential equations (HBNODEs), leveraging the continuous limit of the classical momentum accelerated gradient descent, to improve neural ODEs (NODEs) training and inference. HBNODEs have two properties that imply practical advantages over NODEs: (i) The adjoint state of an HBNODE also satisfies an HBNODE, accelerating both forward and backward ODE solvers, thus significantly reducing the number of function evaluations (NFEs) and improving the utility of the trained models. (ii) The spectrum of HBNODEs is well structured, enabling effective learning of long-term dependencies from complex sequential data. We verify the advantages of HBNODEs over NODEs on benchmark tasks, including image classification, learning complex dynamics, and sequential modeling. Our method requires remarkably fewer forward and backward NFEs, is more accurate, and learns long-term dependencies more effectively than the other ODE-based neural network models. Code is available at \url{https://github.com/hedixia/HeavyBallNODE}.
FMMformer: Efficient and Flexible Transformer via Decomposed Near-field and Far-field Attention
Aug 05, 2021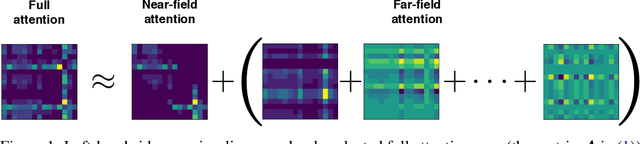

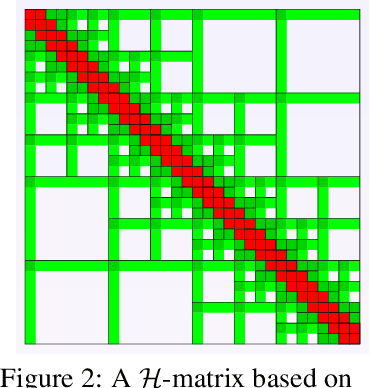
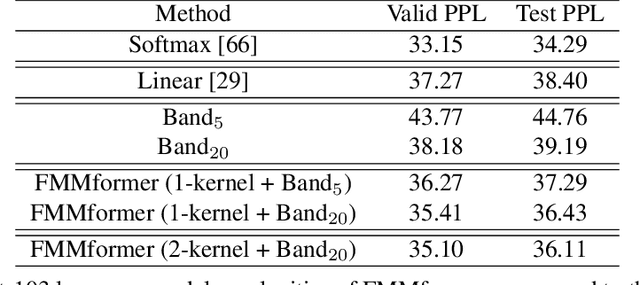
We propose FMMformers, a class of efficient and flexible transformers inspired by the celebrated fast multipole method (FMM) for accelerating interacting particle simulation. FMM decomposes particle-particle interaction into near-field and far-field components and then performs direct and coarse-grained computation, respectively. Similarly, FMMformers decompose the attention into near-field and far-field attention, modeling the near-field attention by a banded matrix and the far-field attention by a low-rank matrix. Computing the attention matrix for FMMformers requires linear complexity in computational time and memory footprint with respect to the sequence length. In contrast, standard transformers suffer from quadratic complexity. We analyze and validate the advantage of FMMformers over the standard transformer on the Long Range Arena and language modeling benchmarks. FMMformers can even outperform the standard transformer in terms of accuracy by a significant margin. For instance, FMMformers achieve an average classification accuracy of $60.74\%$ over the five Long Range Arena tasks, which is significantly better than the standard transformer's average accuracy of $58.70\%$.
Decentralized Federated Averaging
Apr 23, 2021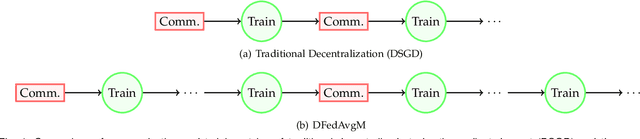
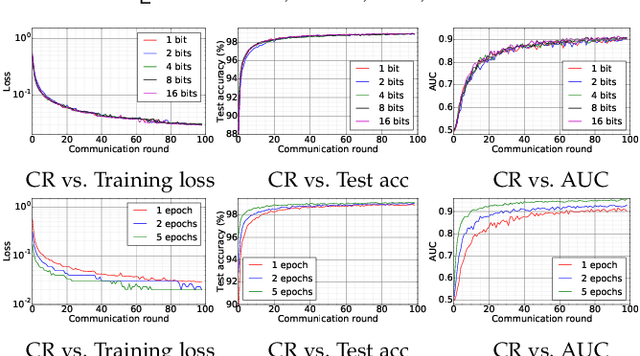
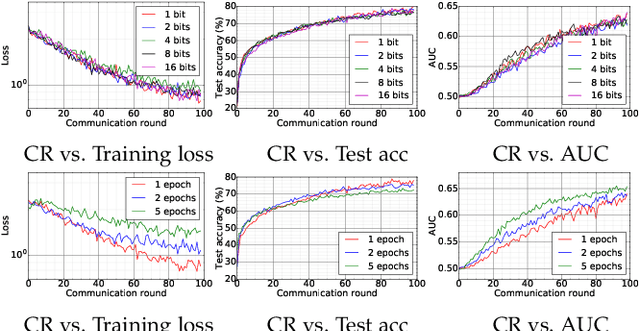
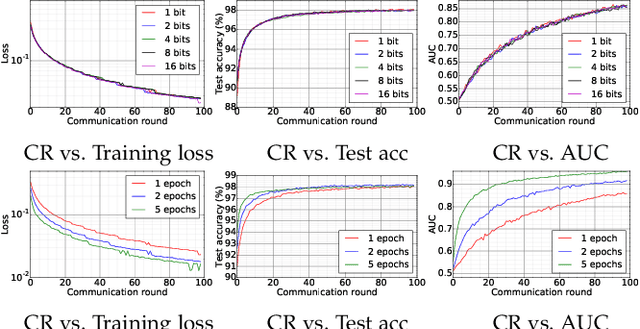
Federated averaging (FedAvg) is a communication efficient algorithm for the distributed training with an enormous number of clients. In FedAvg, clients keep their data locally for privacy protection; a central parameter server is used to communicate between clients. This central server distributes the parameters to each client and collects the updated parameters from clients. FedAvg is mostly studied in centralized fashions, which requires massive communication between server and clients in each communication. Moreover, attacking the central server can break the whole system's privacy. In this paper, we study the decentralized FedAvg with momentum (DFedAvgM), which is implemented on clients that are connected by an undirected graph. In DFedAvgM, all clients perform stochastic gradient descent with momentum and communicate with their neighbors only. To further reduce the communication cost, we also consider the quantized DFedAvgM. We prove convergence of the (quantized) DFedAvgM under trivial assumptions; the convergence rate can be improved when the loss function satisfies the P{\L} property. Finally, we numerically verify the efficacy of DFedAvgM.
Robust Certification for Laplace Learning on Geometric Graphs
Apr 22, 2021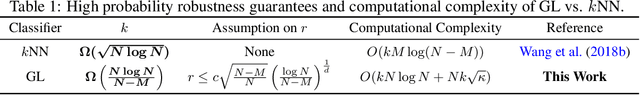
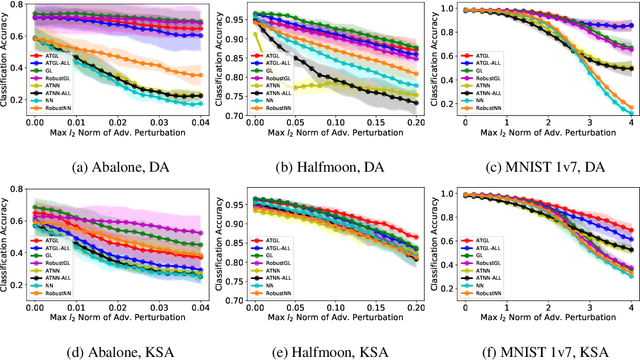

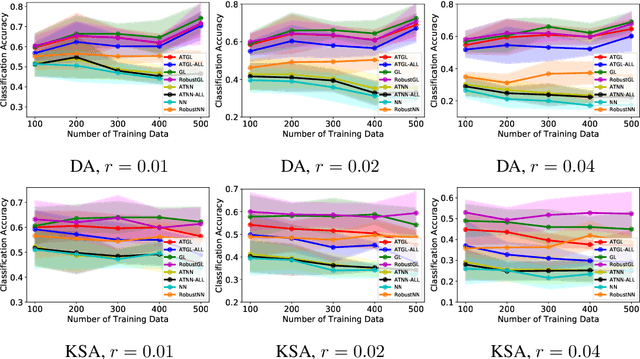
Graph Laplacian (GL)-based semi-supervised learning is one of the most used approaches for classifying nodes in a graph. Understanding and certifying the adversarial robustness of machine learning (ML) algorithms has attracted large amounts of attention from different research communities due to its crucial importance in many security-critical applied domains. There is great interest in the theoretical certification of adversarial robustness for popular ML algorithms. In this paper, we provide the first adversarial robust certification for the GL classifier. More precisely we quantitatively bound the difference in the classification accuracy of the GL classifier before and after an adversarial attack. Numerically, we validate our theoretical certification results and show that leveraging existing adversarial defenses for the $k$-nearest neighbor classifier can remarkably improve the robustness of the GL classifier.
Stability and Generalization of the Decentralized Stochastic Gradient Descent
Feb 23, 2021
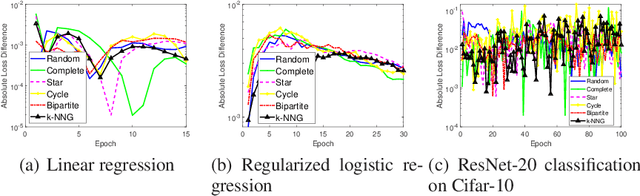
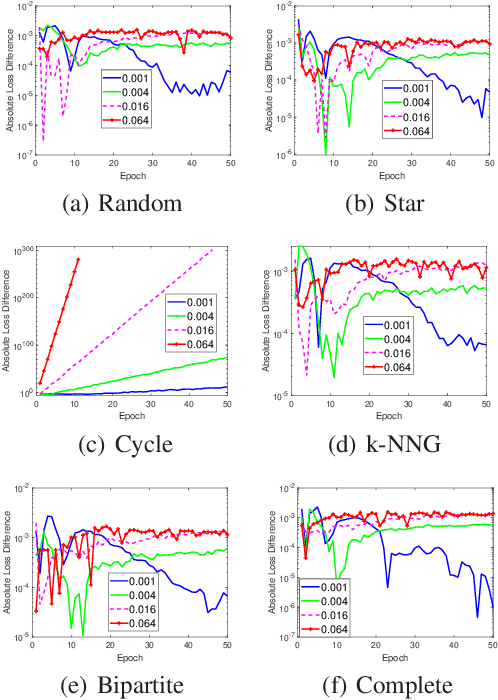
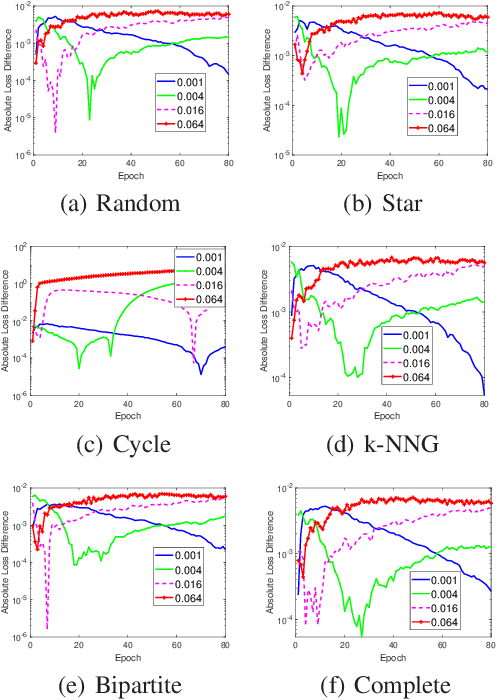
The stability and generalization of stochastic gradient-based methods provide valuable insights into understanding the algorithmic performance of machine learning models. As the main workhorse for deep learning, stochastic gradient descent has received a considerable amount of studies. Nevertheless, the community paid little attention to its decentralized variants. In this paper, we provide a novel formulation of the decentralized stochastic gradient descent. Leveraging this formulation together with (non)convex optimization theory, we establish the first stability and generalization guarantees for the decentralized stochastic gradient descent. Our theoretical results are built on top of a few common and mild assumptions and reveal that the decentralization deteriorates the stability of SGD for the first time. We verify our theoretical findings by using a variety of decentralized settings and benchmark machine learning models.
Deep Interactive Denoiser for X-Ray Computed Tomography
Dec 06, 2020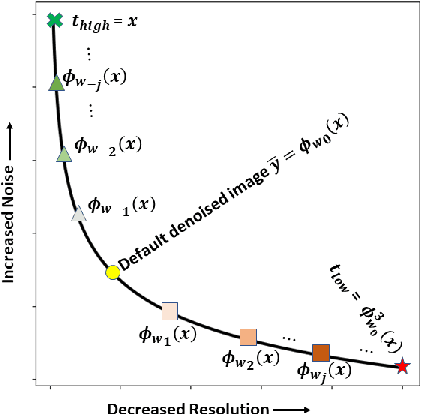
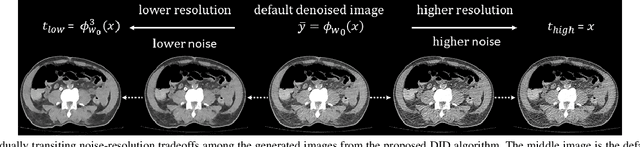
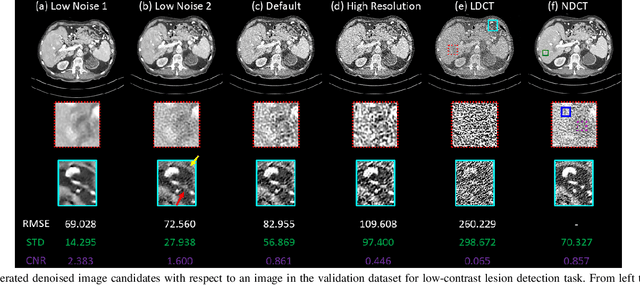
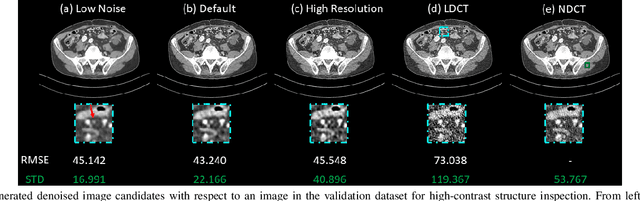
Low dose computed tomography (LDCT) is desirable for both diagnostic imaging and image guided interventions. Denoisers are openly used to improve the quality of LDCT. Deep learning (DL)-based denoisers have shown state-of-the-art performance and are becoming one of the mainstream methods. However, there exists two challenges regarding the DL-based denoisers: 1) a trained model typically does not generate different image candidates with different noise-resolution tradeoffs which sometimes are needed for different clinical tasks; 2) the model generalizability might be an issue when the noise level in the testing images is different from that in the training dataset. To address these two challenges, in this work, we introduce a lightweight optimization process at the testing phase on top of any existing DL-based denoisers to generate multiple image candidates with different noise-resolution tradeoffs suitable for different clinical tasks in real-time. Consequently, our method allows the users to interact with the denoiser to efficiently review various image candidates and quickly pick up the desired one, and thereby was termed as deep interactive denoiser (DID). Experimental results demonstrated that DID can deliver multiple image candidates with different noise-resolution tradeoffs, and shows great generalizability regarding various network architectures, as well as training and testing datasets with various noise levels.