 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Point Neural Optimal Transport without Implicit Differentiation
May 11, 2026We propose an implicit neural formulation of optimal transport that eliminates adversarial min--max optimization and multi-network architectures commonly used in existing approaches. Our key idea is to parameterize a single potential in the Kantorovich dual and reformulate the associated c-transform as a proximal fixed-point problem. This yields a stable single-network framework in which dual feasibility is enforced exactly through proximal optimality conditions rather than adversarial training. Despite the inner fixed-point computation, gradients can be computed without differentiating through the fixed-point iterations, enabling efficient training without requiring implicit differentiation. We further establish convergence of stochastic gradient descent. The resulting framework is efficient, scalable, and broadly applicable: it simultaneously recovers forward and backward transport maps and naturally extends to class-conditional settings. Experiments on high-dimensional Gaussian benchmarks, physical datasets, and image translation tasks demonstrate strong transport accuracy together with improved training stability and favorable computational and memory efficiency.
SymPlex: A Structure-Aware Transformer for Symbolic PDE Solving
Feb 03, 2026We propose SymPlex, a reinforcement learning framework for discovering analytical symbolic solutions to partial differential equations (PDEs) without access to ground-truth expressions. SymPlex formulates symbolic PDE solving as tree-structured decision-making and optimizes candidate solutions using only the PDE and its boundary conditions. At its core is SymFormer, a structure-aware Transformer that models hierarchical symbolic dependencies via tree-relative self-attention and enforces syntactic validity through grammar-constrained autoregressive decoding, overcoming the limited expressivity of sequence-based generators. Unlike numerical and neural approaches that approximate solutions in discretized or implicit function spaces, SymPlex operates directly in symbolic expression space, enabling interpretable and human-readable solutions that naturally represent non-smooth behavior and explicit parametric dependence. Empirical results demonstrate exact recovery of non-smooth and parametric PDE solutions using deep learning-based symbolic methods.
On the Convergence of Jacobian-Free Backpropagation for Optimal Control Problems with Implicit Hamiltonians
Jan 31, 2026Optimal feedback control with implicit Hamiltonians poses a fundamental challenge for learning-based value function methods due to the absence of closed-form optimal control laws. Recent work~\cite{gelphman2025end} introduced an implicit deep learning approach using Jacobian-Free Backpropagation (JFB) to address this setting, but only established sample-wise descent guarantees. In this paper, we establish convergence guarantees for JFB in the stochastic minibatch setting, showing that the resulting updates converge to stationary points of the expected optimal control objective. We further demonstrate scalability on substantially higher-dimensional problems, including multi-agent optimal consumption and swarm-based quadrotor and bicycle control. Together, our results provide both theoretical justification and empirical evidence for using JFB in high-dimensional optimal control with implicit Hamiltonians.
Accelerated Regularized Wasserstein Proximal Sampling Algorithms
Jan 16, 2026We consider sampling from a Gibbs distribution by evolving a finite number of particles using a particular score estimator rather than Brownian motion. To accelerate the particles, we consider a second-order score-based ODE, similar to Nesterov acceleration. In contrast to traditional kernel density score estimation, we use the recently proposed regularized Wasserstein proximal method, yielding the Accelerated Regularized Wasserstein Proximal method (ARWP). We provide a detailed analysis of continuous- and discrete-time non-asymptotic and asymptotic mixing rates for Gaussian initial and target distributions, using techniques from Euclidean acceleration and accelerated information gradients. Compared with the kinetic Langevin sampling algorithm, the proposed algorithm exhibits a higher contraction rate in the asymptotic time regime. Numerical experiments are conducted across various low-dimensional experiments, including multi-modal Gaussian mixtures and ill-conditioned Rosenbrock distributions. ARWP exhibits structured and convergent particles, accelerated discrete-time mixing, and faster tail exploration than the non-accelerated regularized Wasserstein proximal method and kinetic Langevin methods. Additionally, ARWP particles exhibit better generalization properties for some non-log-concave Bayesian neural network tasks.
Neural Implicit Solution Formula for Efficiently Solving Hamilton-Jacobi Equations
Jan 31, 2025This paper presents an implicit solution formula for the Hamilton-Jacobi partial differential equation (HJ PDE). The formula is derived using the method of characteristics and is shown to coincide with the Hopf and Lax formulas in the case where either the Hamiltonian or the initial function is convex. It provides a simple and efficient numerical approach for computing the viscosity solution of HJ PDEs, bypassing the need for the Legendre transform of the Hamiltonian or the initial condition, and the explicit computation of individual characteristic trajectories. A deep learning-based methodology is proposed to learn this implicit solution formula, leveraging the mesh-free nature of deep learning to ensure scalability for high-dimensional problems. Building upon this framework, an algorithm is developed that approximates the characteristic curves piecewise linearly for state-dependent Hamiltonians. Extensive experimental results demonstrate that the proposed method delivers highly accurate solutions, even for nonconvex Hamiltonians, and exhibits remarkable scalability, achieving computational efficiency for problems up to 40 dimensions.
OT-Transformer: A Continuous-time Transformer Architecture with Optimal Transport Regularization
Jan 30, 2025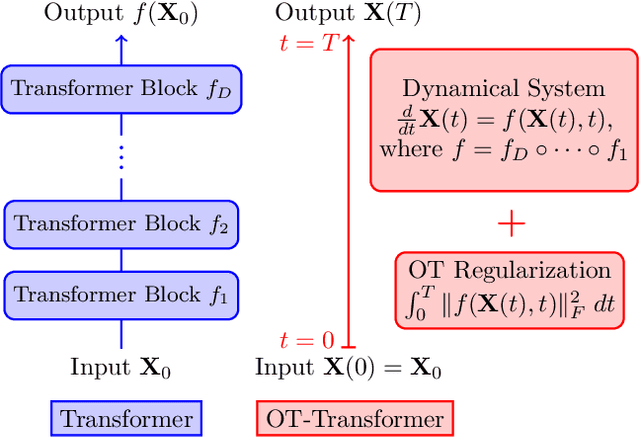
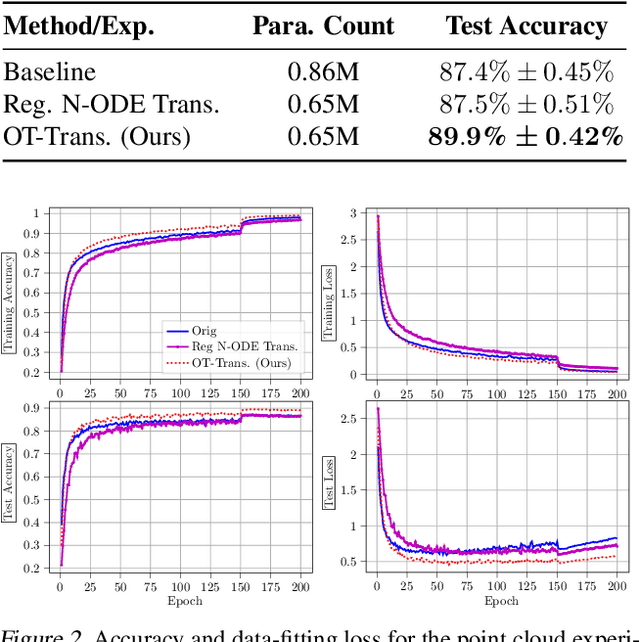

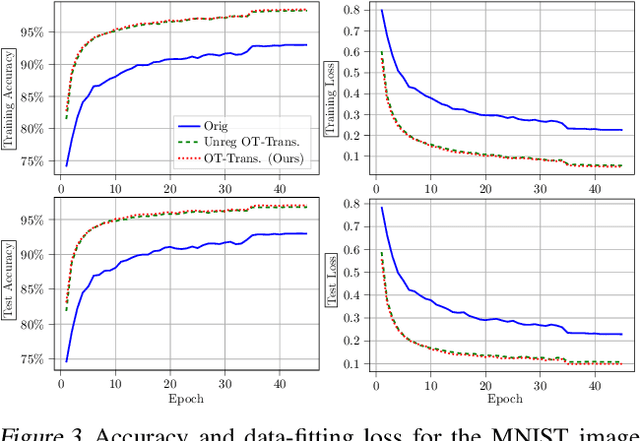
Transformers have achieved state-of-the-art performance in numerous tasks. In this paper, we propose a continuous-time formulation of transformers. Specifically, we consider a dynamical system whose governing equation is parametrized by transformer blocks. We leverage optimal transport theory to regularize the training problem, which enhances stability in training and improves generalization of the resulting model. Moreover, we demonstrate in theory that this regularization is necessary as it promotes uniqueness and regularity of solutions. Our model is flexible in that almost any existing transformer architectures can be adopted to construct the dynamical system with only slight modifications to the existing code. We perform extensive numerical experiments on tasks motivated by natural language processing, image classification, and point cloud classification. Our experimental results show that the proposed method improves the performance of its discrete counterpart and outperforms relevant comparing models.
In-Context Operator Learning for Linear Propagator Models
Jan 25, 2025



We study operator learning in the context of linear propagator models for optimal order execution problems with transient price impact \`a la Bouchaud et al. (2004) and Gatheral (2010). Transient price impact persists and decays over time according to some propagator kernel. Specifically, we propose to use In-Context Operator Networks (ICON), a novel transformer-based neural network architecture introduced by Yang et al. (2023), which facilitates data-driven learning of operators by merging offline pre-training with an online few-shot prompting inference. First, we train ICON to learn the operator from various propagator models that maps the trading rate to the induced transient price impact. The inference step is then based on in-context prediction, where ICON is presented only with a few examples. We illustrate that ICON is capable of accurately inferring the underlying price impact model from the data prompts, even with propagator kernels not seen in the training data. In a second step, we employ the pre-trained ICON model provided with context as a surrogate operator in solving an optimal order execution problem via a neural network control policy, and demonstrate that the exact optimal execution strategies from Abi Jaber and Neuman (2022) for the models generating the context are correctly retrieved. Our introduced methodology is very general, offering a new approach to solving optimal stochastic control problems with unknown state dynamics, inferred data-efficiently from a limited number of examples by leveraging the few-shot and transfer learning capabilities of transformer networks.
VICON: Vision In-Context Operator Networks for Multi-Physics Fluid Dynamics Prediction
Nov 25, 2024



In-Context Operator Networks (ICONs) are models that learn operators across different types of PDEs using a few-shot, in-context approach. Although they show successful generalization to various PDEs, existing methods treat each data point as a single token, and suffer from computational inefficiency when processing dense data, limiting their application in higher spatial dimensions. In this work, we propose Vision In-Context Operator Networks (VICON), incorporating a vision transformer architecture that efficiently processes 2D functions through patch-wise operations. We evaluated our method on three fluid dynamics datasets, demonstrating both superior performance (reducing scaled $L^2$ error by $40\%$ and $61.6\%$ for two benchmark datasets for compressible flows, respectively) and computational efficiency (requiring only one-third of the inference time per frame) in long-term rollout predictions compared to the current state-of-the-art sequence-to-sequence model with fixed timestep prediction: Multiple Physics Pretraining (MPP). Compared to MPP, our method preserves the benefits of in-context operator learning, enabling flexible context formation when dealing with insufficient frame counts or varying timestep values.
A Natural Primal-Dual Hybrid Gradient Method for Adversarial Neural Network Training on Solving Partial Differential Equations
Nov 09, 2024



We propose a scalable preconditioned primal-dual hybrid gradient algorithm for solving partial differential equations (PDEs). We multiply the PDE with a dual test function to obtain an inf-sup problem whose loss functional involves lower-order differential operators. The Primal-Dual Hybrid Gradient (PDHG) algorithm is then leveraged for this saddle point problem. By introducing suitable precondition operators to the proximal steps in the PDHG algorithm, we obtain an alternative natural gradient ascent-descent optimization scheme for updating the neural network parameters. We apply the Krylov subspace method (MINRES) to evaluate the natural gradients efficiently. Such treatment readily handles the inversion of precondition matrices via matrix-vector multiplication. A posterior convergence analysis is established for the time-continuous version of the proposed method. The algorithm is tested on various types of PDEs with dimensions ranging from $1$ to $50$, including linear and nonlinear elliptic equations, reaction-diffusion equations, and Monge-Amp\`ere equations stemming from the $L^2$ optimal transport problems. We compare the performance of the proposed method with several commonly used deep learning algorithms such as physics-informed neural networks (PINNs), the DeepRitz method, weak adversarial networks (WANs), etc, for solving PDEs using the Adam and L-BFGS optimizers. The numerical results suggest that the proposed method performs efficiently and robustly and converges more stably.
Fried deconvolution
Nov 05, 2024In this paper we present a new approach to deblur the effect of atmospheric turbulence in the case of long range imaging. Our method is based on an analytical formulation, the Fried kernel, of the atmosphere modulation transfer function (MTF) and a framelet based deconvolution algorithm. An important parameter is the refractive index structure which requires specific measurements to be known. Then we propose a method which provides a good estimation of this parameter from the input blurred image. The final algorithms are very easy to implement and show very good results on both simulated blur and real images.