 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Data Limits of Laplace Learning for Gaussian Measure Data in Infinite Dimensions
Jan 20, 2026Laplace learning is a semi-supervised method, a solution for finding missing labels from a partially labeled dataset utilizing the geometry given by the unlabeled data points. The method minimizes a Dirichlet energy defined on a (discrete) graph constructed from the full dataset. In finite dimensions the asymptotics in the large (unlabeled) data limit are well understood with convergence from the graph setting to a continuum Sobolev semi-norm weighted by the Lebesgue density of the data-generating measure. The lack of the Lebesgue measure on infinite-dimensional spaces requires rethinking the analysis if the data aren't finite-dimensional. In this paper we make a first step in this direction by analyzing the setting when the data are generated by a Gaussian measure on a Hilbert space and proving pointwise convergence of the graph Dirichlet energy.
Laplace Learning in Wasserstein Space
Nov 17, 2025The manifold hypothesis posits that high-dimensional data typically resides on low-dimensional sub spaces. In this paper, we assume manifold hypothesis to investigate graph-based semi-supervised learning methods. In particular, we examine Laplace Learning in the Wasserstein space, extending the classical notion of graph-based semi-supervised learning algorithms from finite-dimensional Euclidean spaces to an infinite-dimensional setting. To achieve this, we prove variational convergence of a discrete graph p- Dirichlet energy to its continuum counterpart. In addition, we characterize the Laplace-Beltrami operator on asubmanifold of the Wasserstein space. Finally, we validate the proposed theoretical framework through numerical experiments conducted on benchmark datasets, demonstrating the consistency of our classification performance in high-dimensional settings.
Higher-Order Regularization Learning on Hypergraphs
Oct 30, 2025Higher-Order Hypergraph Learning (HOHL) was recently introduced as a principled alternative to classical hypergraph regularization, enforcing higher-order smoothness via powers of multiscale Laplacians induced by the hypergraph structure. Prior work established the well- and ill-posedness of HOHL through an asymptotic consistency analysis in geometric settings. We extend this theoretical foundation by proving the consistency of a truncated version of HOHL and deriving explicit convergence rates when HOHL is used as a regularizer in fully supervised learning. We further demonstrate its strong empirical performance in active learning and in datasets lacking an underlying geometric structure, highlighting HOHL's versatility and robustness across diverse learning settings.
Uncertainty-Based Smooth Policy Regularisation for Reinforcement Learning with Few Demonstrations
Sep 19, 2025



In reinforcement learning with sparse rewards, demonstrations can accelerate learning, but determining when to imitate them remains challenging. We propose Smooth Policy Regularisation from Demonstrations (SPReD), a framework that addresses the fundamental question: when should an agent imitate a demonstration versus follow its own policy? SPReD uses ensemble methods to explicitly model Q-value distributions for both demonstration and policy actions, quantifying uncertainty for comparisons. We develop two complementary uncertainty-aware methods: a probabilistic approach estimating the likelihood of demonstration superiority, and an advantage-based approach scaling imitation by statistical significance. Unlike prevailing methods (e.g. Q-filter) that make binary imitation decisions, SPReD applies continuous, uncertainty-proportional regularisation weights, reducing gradient variance during training. Despite its computational simplicity, SPReD achieves remarkable gains in experiments across eight robotics tasks, outperforming existing approaches by up to a factor of 14 in complex tasks while maintaining robustness to demonstration quality and quantity. Our code is available at https://github.com/YujieZhu7/SPReD.
Expected Sliced Transport Plans
Oct 17, 2024



The optimal transport (OT) problem has gained significant traction in modern machine learning for its ability to: (1) provide versatile metrics, such as Wasserstein distances and their variants, and (2) determine optimal couplings between probability measures. To reduce the computational complexity of OT solvers, methods like entropic regularization and sliced optimal transport have been proposed. The sliced OT framework improves efficiency by comparing one-dimensional projections (slices) of high-dimensional distributions. However, despite their computational efficiency, sliced-Wasserstein approaches lack a transportation plan between the input measures, limiting their use in scenarios requiring explicit coupling. In this paper, we address two key questions: Can a transportation plan be constructed between two probability measures using the sliced transport framework? If so, can this plan be used to define a metric between the measures? We propose a "lifting" operation to extend one-dimensional optimal transport plans back to the original space of the measures. By computing the expectation of these lifted plans, we derive a new transportation plan, termed expected sliced transport (EST) plans. We prove that using the EST plan to weight the sum of the individual Euclidean costs for moving from one point to another results in a valid metric between the input discrete probability measures. We demonstrate the connection between our approach and the recently proposed min-SWGG, along with illustrative numerical examples that support our theoretical findings.
Manifold learning in Wasserstein space
Nov 14, 2023


This paper aims at building the theoretical foundations for manifold learning algorithms in the space of absolutely continuous probability measures on a compact and convex subset of $\mathbb{R}^d$, metrized with the Wasserstein-2 distance $W$. We begin by introducing a natural construction of submanifolds $\Lambda$ of probability measures equipped with metric $W_\Lambda$, the geodesic restriction of $W$ to $\Lambda$. In contrast to other constructions, these submanifolds are not necessarily flat, but still allow for local linearizations in a similar fashion to Riemannian submanifolds of $\mathbb{R}^d$. We then show how the latent manifold structure of $(\Lambda,W_{\Lambda})$ can be learned from samples $\{\lambda_i\}_{i=1}^N$ of $\Lambda$ and pairwise extrinsic Wasserstein distances $W$ only. In particular, we show that the metric space $(\Lambda,W_{\Lambda})$ can be asymptotically recovered in the sense of Gromov--Wasserstein from a graph with nodes $\{\lambda_i\}_{i=1}^N$ and edge weights $W(\lambda_i,\lambda_j)$. In addition, we demonstrate how the tangent space at a sample $\lambda$ can be asymptotically recovered via spectral analysis of a suitable "covariance operator" using optimal transport maps from $\lambda$ to sufficiently close and diverse samples $\{\lambda_i\}_{i=1}^N$. The paper closes with some explicit constructions of submanifolds $\Lambda$ and numerical examples on the recovery of tangent spaces through spectral analysis.
PT$\mathrm{L}^{p}$: Partial Transport $\mathrm{L}^{p}$ Distances
Jul 25, 2023



Optimal transport and its related problems, including optimal partial transport, have proven to be valuable tools in machine learning for computing meaningful distances between probability or positive measures. This success has led to a growing interest in defining transport-based distances that allow for comparing signed measures and, more generally, multi-channeled signals. Transport $\mathrm{L}^{p}$ distances are notable extensions of the optimal transport framework to signed and possibly multi-channeled signals. In this paper, we introduce partial transport $\mathrm{L}^{p}$ distances as a new family of metrics for comparing generic signals, benefiting from the robustness of partial transport distances. We provide theoretical background such as the existence of optimal plans and the behavior of the distance in various limits. Furthermore, we introduce the sliced variation of these distances, which allows for rapid comparison of generic signals. Finally, we demonstrate the application of the proposed distances in signal class separability and nearest neighbor classification.
Rates of Convergence for Regression with the Graph Poly-Laplacian
Sep 06, 2022In the (special) smoothing spline problem one considers a variational problem with a quadratic data fidelity penalty and Laplacian regularisation. Higher order regularity can be obtained via replacing the Laplacian regulariser with a poly-Laplacian regulariser. The methodology is readily adapted to graphs and here we consider graph poly-Laplacian regularisation in a fully supervised, non-parametric, noise corrupted, regression problem. In particular, given a dataset $\{x_i\}_{i=1}^n$ and a set of noisy labels $\{y_i\}_{i=1}^n\subset\mathbb{R}$ we let $u_n:\{x_i\}_{i=1}^n\to\mathbb{R}$ be the minimiser of an energy which consists of a data fidelity term and an appropriately scaled graph poly-Laplacian term. When $y_i = g(x_i)+\xi_i$, for iid noise $\xi_i$, and using the geometric random graph, we identify (with high probability) the rate of convergence of $u_n$ to $g$ in the large data limit $n\to\infty$. Furthermore, our rate, up to logarithms, coincides with the known rate of convergence in the usual smoothing spline model.
Classification of datasets with imputed missing values: does imputation quality matter?
Jun 16, 2022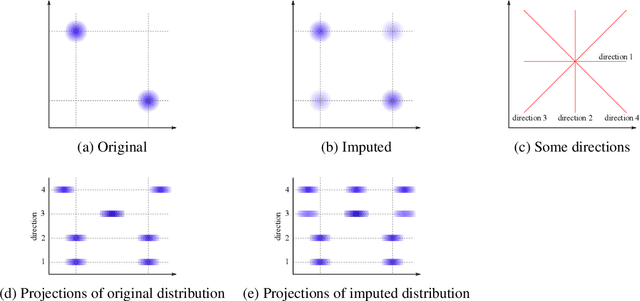


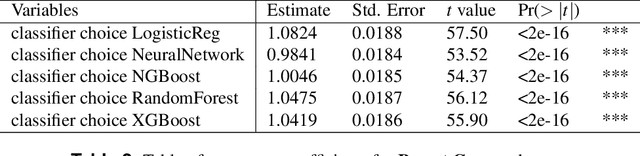
Classifying samples in incomplete datasets is a common aim for machine learning practitioners, but is non-trivial. Missing data is found in most real-world datasets and these missing values are typically imputed using established methods, followed by classification of the now complete, imputed, samples. The focus of the machine learning researcher is then to optimise the downstream classification performance. In this study, we highlight that it is imperative to consider the quality of the imputation. We demonstrate how the commonly used measures for assessing quality are flawed and propose a new class of discrepancy scores which focus on how well the method recreates the overall distribution of the data. To conclude, we highlight the compromised interpretability of classifier models trained using poorly imputed data.
Robust Certification for Laplace Learning on Geometric Graphs
Apr 22, 2021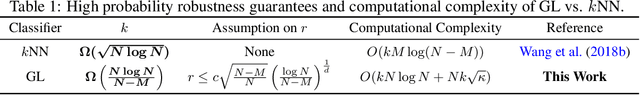
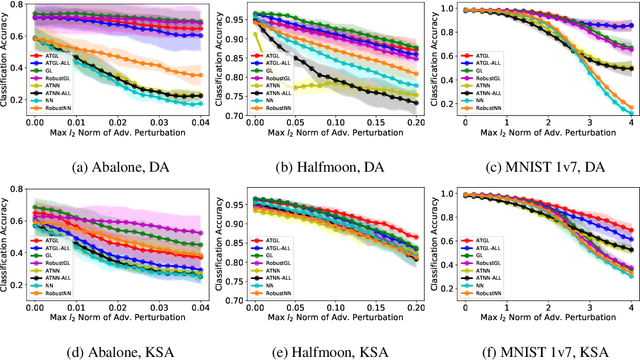

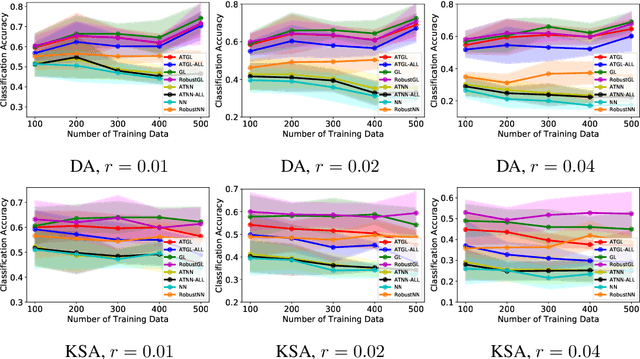
Graph Laplacian (GL)-based semi-supervised learning is one of the most used approaches for classifying nodes in a graph. Understanding and certifying the adversarial robustness of machine learning (ML) algorithms has attracted large amounts of attention from different research communities due to its crucial importance in many security-critical applied domains. There is great interest in the theoretical certification of adversarial robustness for popular ML algorithms. In this paper, we provide the first adversarial robust certification for the GL classifier. More precisely we quantitatively bound the difference in the classification accuracy of the GL classifier before and after an adversarial attack. Numerically, we validate our theoretical certification results and show that leveraging existing adversarial defenses for the $k$-nearest neighbor classifier can remarkably improve the robustness of the GL classifier.