 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
Amplify Initiative: Building A Localized Data Platform for Globalized AI
Apr 18, 2025Current AI models often fail to account for local context and language, given the predominance of English and Western internet content in their training data. This hinders the global relevance, usefulness, and safety of these models as they gain more users around the globe. Amplify Initiative, a data platform and methodology, leverages expert communities to collect diverse, high-quality data to address the limitations of these models. The platform is designed to enable co-creation of datasets, provide access to high-quality multilingual datasets, and offer recognition to data authors. This paper presents the approach to co-creating datasets with domain experts (e.g., health workers, teachers) through a pilot conducted in Sub-Saharan Africa (Ghana, Kenya, Malawi, Nigeria, and Uganda). In partnership with local researchers situated in these countries, the pilot demonstrated an end-to-end approach to co-creating data with 155 experts in sensitive domains (e.g., physicians, bankers, anthropologists, human and civil rights advocates). This approach, implemented with an Android app, resulted in an annotated dataset of 8,091 adversarial queries in seven languages (e.g., Luganda, Swahili, Chichewa), capturing nuanced and contextual information related to key themes such as misinformation and public interest topics. This dataset in turn can be used to evaluate models for their safety and cultural relevance within the context of these languages.
InkubaLM: A small language model for low-resource African languages
Sep 03, 2024



High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints. This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task. Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources. Our model and datasets are publicly available at https://huggingface.co/lelapa to encourage research and development on low-resource languages.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022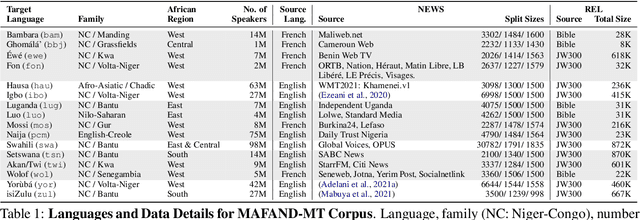
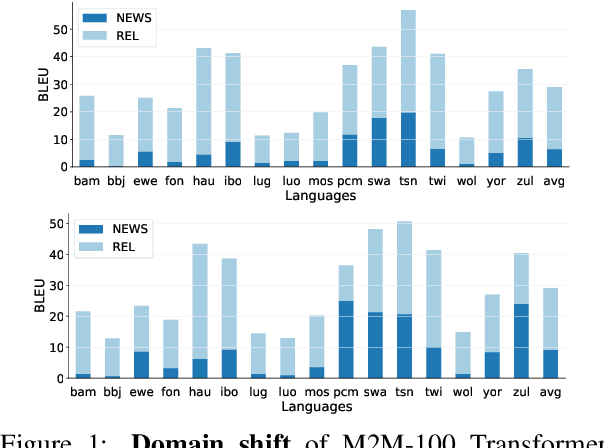

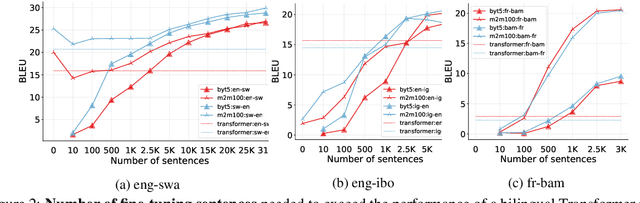
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021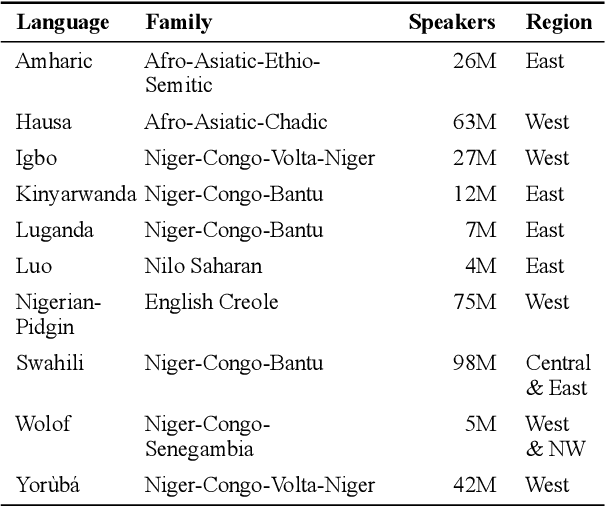

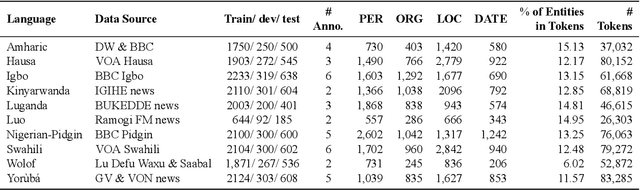
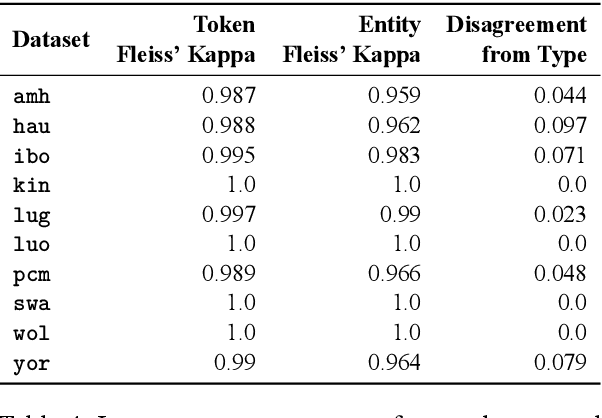
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.