 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCo RL: Distribution-Conditioned Reinforcement Learning for General-Purpose Policies
Apr 23, 2021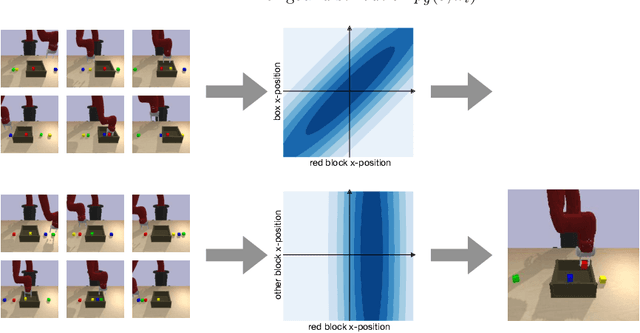
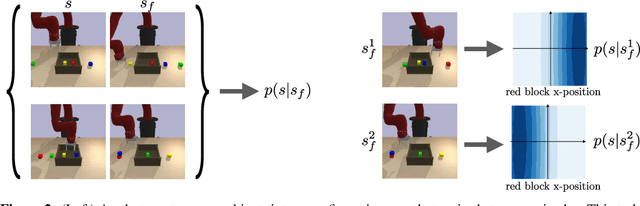
Can we use reinforcement learning to learn general-purpose policies that can perform a wide range of different tasks, resulting in flexible and reusable skills? Contextual policies provide this capability in principle, but the representation of the context determines the degree of generalization and expressivity. Categorical contexts preclude generalization to entirely new tasks. Goal-conditioned policies may enable some generalization, but cannot capture all tasks that might be desired. In this paper, we propose goal distributions as a general and broadly applicable task representation suitable for contextual policies. Goal distributions are general in the sense that they can represent any state-based reward function when equipped with an appropriate distribution class, while the particular choice of distribution class allows us to trade off expressivity and learnability. We develop an off-policy algorithm called distribution-conditioned reinforcement learning (DisCo RL) to efficiently learn these policies. We evaluate DisCo RL on a variety of robot manipulation tasks and find that it significantly outperforms prior methods on tasks that require generalization to new goal distributions.
Accelerating Online Reinforcement Learning with Offline Datasets
Jun 16, 2020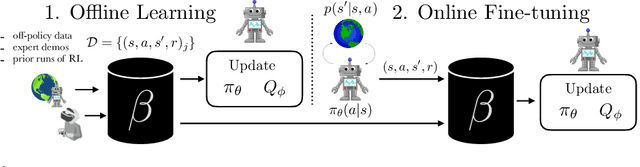
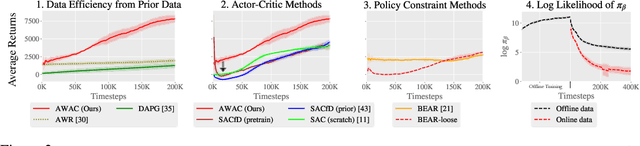
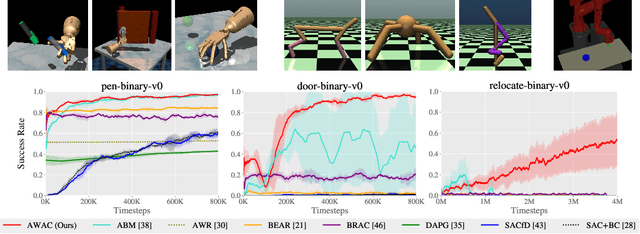
Reinforcement learning provides an appealing formalism for learning control policies from experience. However, the classic active formulation of reinforcement learning necessitates a lengthy active exploration process for each behavior, making it difficult to apply in real-world settings. If we can instead allow reinforcement learning to effectively use previously collected data to aid the online learning process, where the data could be expert demonstrations or more generally any prior experience, we could make reinforcement learning a substantially more practical tool. While a number of recent methods have sought to learn offline from previously collected data, it remains exceptionally difficult to train a policy with offline data and improve it further with online reinforcement learning. In this paper we systematically analyze why this problem is so challenging, and propose a novel algorithm that combines sample-efficient dynamic programming with maximum likelihood policy updates, providing a simple and effective framework that is able to leverage large amounts of offline data and then quickly perform online fine-tuning of reinforcement learning policies. We show that our method enables rapid learning of skills with a combination of prior demonstration data and online experience across a suite of difficult dexterous manipulation and benchmark tasks.
Meta-Reinforcement Learning for Robotic Industrial Insertion Tasks
May 23, 2020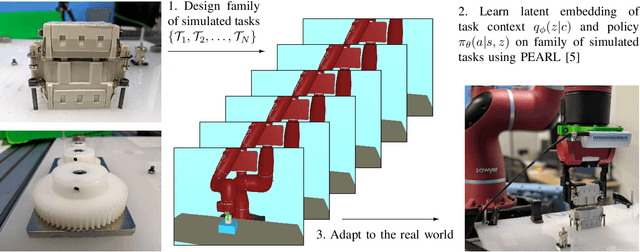



Robotic insertion tasks are characterized by contact and friction mechanics, making them challenging for conventional feedback control methods due to unmodeled physical effects. Reinforcement learning (RL) is a promising approach for learning control policies in such settings. However, RL can be unsafe during exploration and might require a large amount of real-world training data, which is expensive to collect. In this paper, we study how to use meta-reinforcement learning to solve the bulk of the problem in simulation by solving a family of simulated industrial insertion tasks and then adapt policies quickly in the real world. We demonstrate our approach by training an agent to successfully perform challenging real-world insertion tasks using less than 20 trials of real-world experience. Videos and other material are available at https://pearl-insertion.github.io/
Contextual Imagined Goals for Self-Supervised Robotic Learning
Oct 23, 2019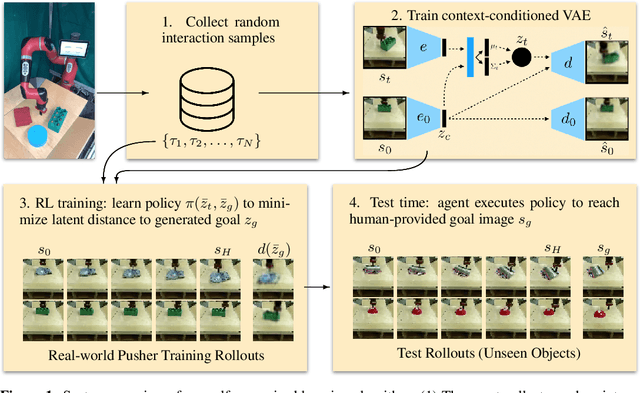
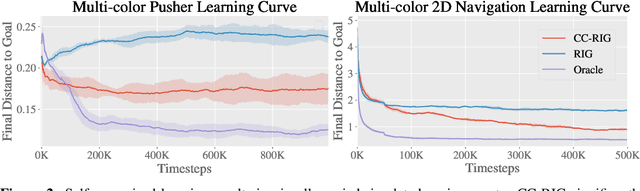

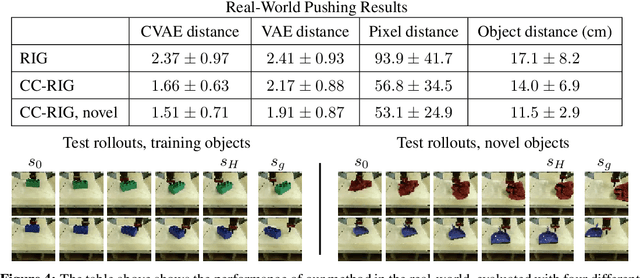
While reinforcement learning provides an appealing formalism for learning individual skills, a general-purpose robotic system must be able to master an extensive repertoire of behaviors. Instead of learning a large collection of skills individually, can we instead enable a robot to propose and practice its own behaviors automatically, learning about the affordances and behaviors that it can perform in its environment, such that it can then repurpose this knowledge once a new task is commanded by the user? In this paper, we study this question in the context of self-supervised goal-conditioned reinforcement learning. A central challenge in this learning regime is the problem of goal setting: in order to practice useful skills, the robot must be able to autonomously set goals that are feasible but diverse. When the robot's environment and available objects vary, as they do in most open-world settings, the robot must propose to itself only those goals that it can accomplish in its present setting with the objects that are at hand. Previous work only studies self-supervised goal-conditioned RL in a single-environment setting, where goal proposals come from the robot's past experience or a generative model are sufficient. In more diverse settings, this frequently leads to impossible goals and, as we show experimentally, prevents effective learning. We propose a conditional goal-setting model that aims to propose goals that are feasible from the robot's current state. We demonstrate that this enables self-supervised goal-conditioned off-policy learning with raw image observations in the real world, enabling a robot to manipulate a variety of objects and generalize to new objects that were not seen during training.
Deep Reinforcement Learning for Industrial Insertion Tasks with Visual Inputs and Natural Rewards
Jun 13, 2019
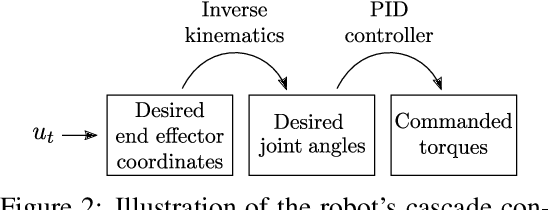

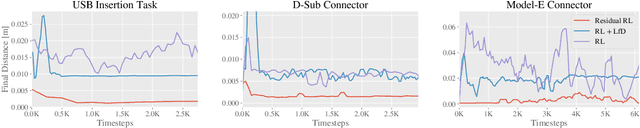
Connector insertion and many other tasks commonly found in modern manufacturing settings involve complex contact dynamics and friction. Since it is difficult to capture related physical effects with first-order modeling, traditional control methods often result in brittle and inaccurate controllers, which have to be manually tuned. Reinforcement learning (RL) methods have been demonstrated to be capable of learning controllers in such environments from autonomous interaction with the environment, but running RL algorithms in the real world poses sample efficiency and safety challenges. Moreover, in practical real-world settings we cannot assume access to perfect state information or dense reward signals. In this paper, we consider a variety of difficult industrial insertion tasks with visual inputs and different natural reward specifications, namely sparse rewards and goal images. We show that methods that combine RL with prior information, such as classical controllers or demonstrations, can solve these tasks from a reasonable amount of real-world interaction.
Skew-Fit: State-Covering Self-Supervised Reinforcement Learning
Mar 08, 2019
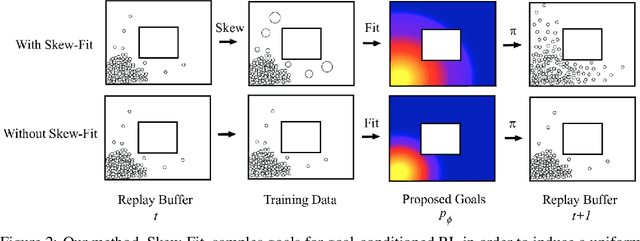
In standard reinforcement learning, each new skill requires a manually-designed reward function, which takes considerable manual effort and engineering. Self-supervised goal setting has the potential to automate this process, enabling an agent to propose its own goals and acquire skills that achieve these goals. However, such methods typically rely on manually-designed goal distributions, or heuristics to force the agent to explore a wide range of states. We propose a formal exploration objective for goal-reaching policies that maximizes state coverage. We show that this objective is equivalent to maximizing the entropy of the goal distribution together with goal reaching performance, where goals correspond to entire states. We present an algorithm called Skew-Fit for learning such a maximum-entropy goal distribution, and show that under certain regularity conditions, our method converges to a uniform distribution over the set of possible states, even when we do not know this set beforehand. Skew-Fit enables self-supervised agents to autonomously choose and practice diverse goals. Our experiments show that it can learn a variety of manipulation tasks from images, including opening a door with a real robot, entirely from scratch and without any manually-designed reward function.
Residual Reinforcement Learning for Robot Control
Dec 18, 2018

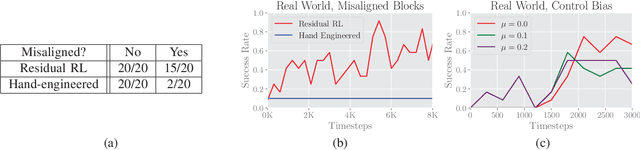
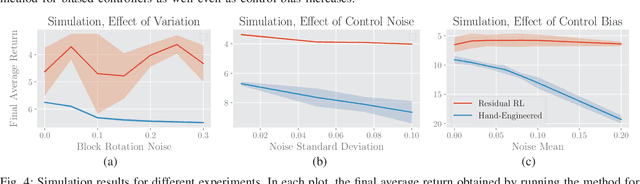
Conventional feedback control methods can solve various types of robot control problems very efficiently by capturing the structure with explicit models, such as rigid body equations of motion. However, many control problems in modern manufacturing deal with contacts and friction, which are difficult to capture with first-order physical modeling. Hence, applying control design methodologies to these kinds of problems often results in brittle and inaccurate controllers, which have to be manually tuned for deployment. Reinforcement learning (RL) methods have been demonstrated to be capable of learning continuous robot controllers from interactions with the environment, even for problems that include friction and contacts. In this paper, we study how we can solve difficult control problems in the real world by decomposing them into a part that is solved efficiently by conventional feedback control methods, and the residual which is solved with RL. The final control policy is a superposition of both control signals. We demonstrate our approach by training an agent to successfully perform a real-world block assembly task involving contacts and unstable objects.
Visual Reinforcement Learning with Imagined Goals
Dec 04, 2018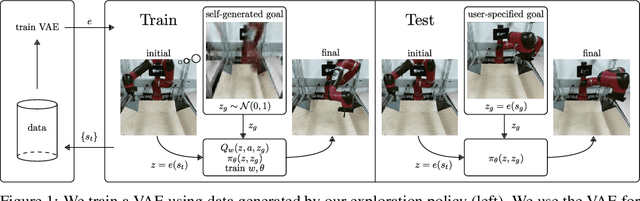
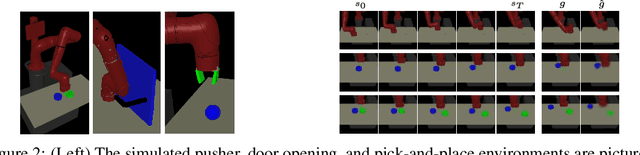
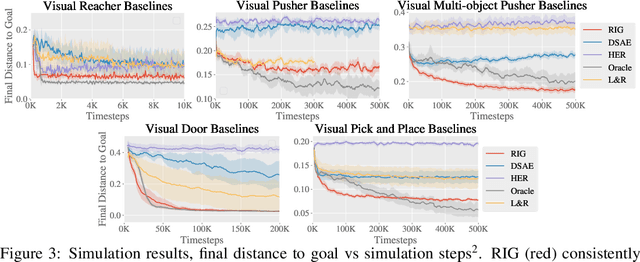
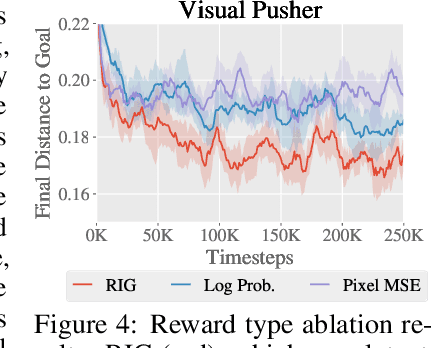
For an autonomous agent to fulfill a wide range of user-specified goals at test time, it must be able to learn broadly applicable and general-purpose skill repertoires. Furthermore, to provide the requisite level of generality, these skills must handle raw sensory input such as images. In this paper, we propose an algorithm that acquires such general-purpose skills by combining unsupervised representation learning and reinforcement learning of goal-conditioned policies. Since the particular goals that might be required at test-time are not known in advance, the agent performs a self-supervised "practice" phase where it imagines goals and attempts to achieve them. We learn a visual representation with three distinct purposes: sampling goals for self-supervised practice, providing a structured transformation of raw sensory inputs, and computing a reward signal for goal reaching. We also propose a retroactive goal relabeling scheme to further improve the sample-efficiency of our method. Our off-policy algorithm is efficient enough to learn policies that operate on raw image observations and goals for a real-world robotic system, and substantially outperforms prior techniques.
Overcoming Exploration in Reinforcement Learning with Demonstrations
Feb 25, 2018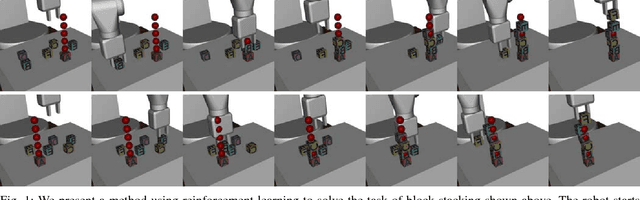
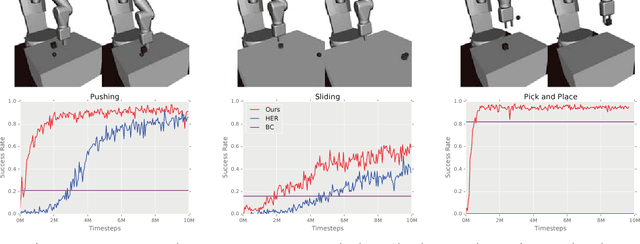
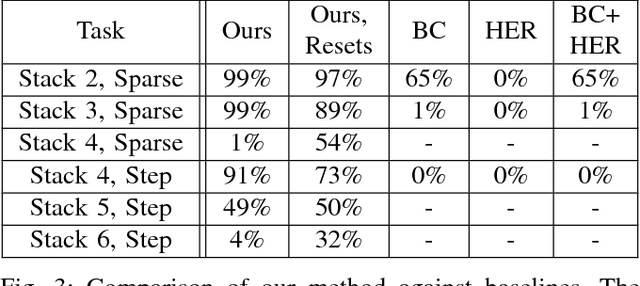
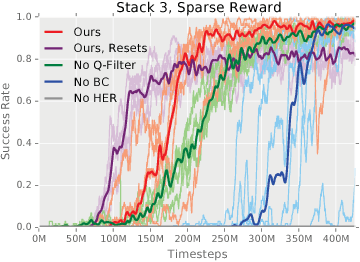
Exploration in environments with sparse rewards has been a persistent problem in reinforcement learning (RL). Many tasks are natural to specify with a sparse reward, and manually shaping a reward function can result in suboptimal performance. However, finding a non-zero reward is exponentially more difficult with increasing task horizon or action dimensionality. This puts many real-world tasks out of practical reach of RL methods. In this work, we use demonstrations to overcome the exploration problem and successfully learn to perform long-horizon, multi-step robotics tasks with continuous control such as stacking blocks with a robot arm. Our method, which builds on top of Deep Deterministic Policy Gradients and Hindsight Experience Replay, provides an order of magnitude of speedup over RL on simulated robotics tasks. It is simple to implement and makes only the additional assumption that we can collect a small set of demonstrations. Furthermore, our method is able to solve tasks not solvable by either RL or behavior cloning alone, and often ends up outperforming the demonstrator policy.
Combining Self-Supervised Learning and Imitation for Vision-Based Rope Manipulation
Mar 06, 2017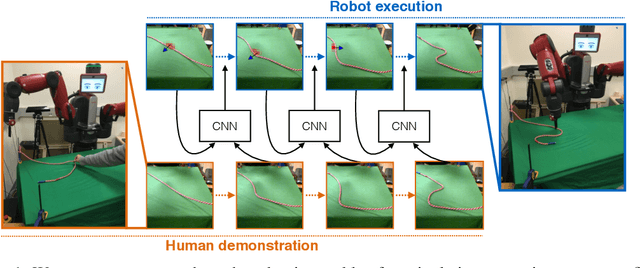
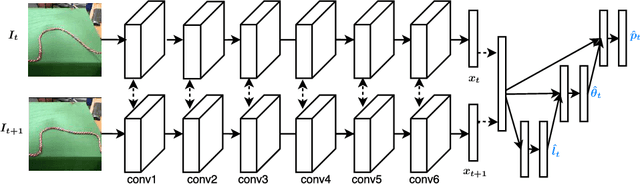
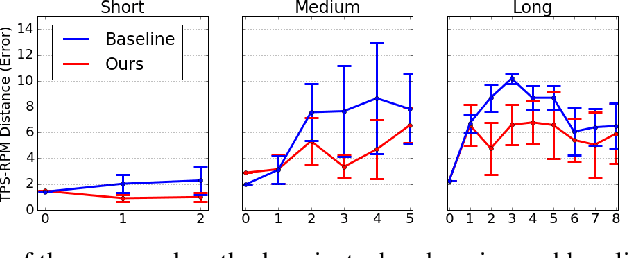
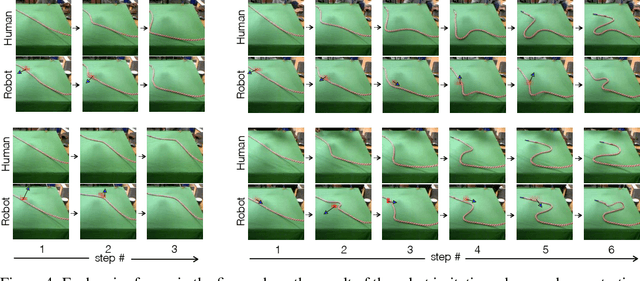
Manipulation of deformable objects, such as ropes and cloth, is an important but challenging problem in robotics. We present a learning-based system where a robot takes as input a sequence of images of a human manipulating a rope from an initial to goal configuration, and outputs a sequence of actions that can reproduce the human demonstration, using only monocular images as input. To perform this task, the robot learns a pixel-level inverse dynamics model of rope manipulation directly from images in a self-supervised manner, using about 60K interactions with the rope collected autonomously by the robot. The human demonstration provides a high-level plan of what to do and the low-level inverse model is used to execute the plan. We show that by combining the high and low-level plans, the robot can successfully manipulate a rope into a variety of target shapes using only a sequence of human-provided images for direction.