 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited-Memory Greedy Quasi-Newton Method with Non-asymptotic Superlinear Convergence Rate
Jun 27, 2023



Non-asymptotic convergence analysis of quasi-Newton methods has gained attention with a landmark result establishing an explicit superlinear rate of O$((1/\sqrt{t})^t)$. The methods that obtain this rate, however, exhibit a well-known drawback: they require the storage of the previous Hessian approximation matrix or instead storing all past curvature information to form the current Hessian inverse approximation. Limited-memory variants of quasi-Newton methods such as the celebrated L-BFGS alleviate this issue by leveraging a limited window of past curvature information to construct the Hessian inverse approximation. As a result, their per iteration complexity and storage requirement is O$(\tau d)$ where $\tau \le d$ is the size of the window and $d$ is the problem dimension reducing the O$(d^2)$ computational cost and memory requirement of standard quasi-Newton methods. However, to the best of our knowledge, there is no result showing a non-asymptotic superlinear convergence rate for any limited-memory quasi-Newton method. In this work, we close this gap by presenting a limited-memory greedy BFGS (LG-BFGS) method that achieves an explicit non-asymptotic superlinear rate. We incorporate displacement aggregation, i.e., decorrelating projection, in post-processing gradient variations, together with a basis vector selection scheme on variable variations, which greedily maximizes a progress measure of the Hessian estimate to the true Hessian. Their combination allows past curvature information to remain in a sparse subspace while yielding a valid representation of the full history. Interestingly, our established non-asymptotic superlinear convergence rate demonstrates a trade-off between the convergence speed and memory requirement, which to our knowledge, is the first of its kind. Numerical results corroborate our theoretical findings and demonstrate the effectiveness of our method.
Accelerated Quasi-Newton Proximal Extragradient: Faster Rate for Smooth Convex Optimization
Jun 03, 2023In this paper, we propose an accelerated quasi-Newton proximal extragradient (A-QPNE) method for solving unconstrained smooth convex optimization problems. With access only to the gradients of the objective, we prove that our method can achieve a convergence rate of ${O}\bigl(\min\{\frac{1}{k^2}, \frac{\sqrt{d\log k}}{k^{2.5}}\}\bigr)$, where $d$ is the problem dimension and $k$ is the number of iterations. In particular, in the regime where $k = {O}(d)$, our method matches the optimal rate of ${O}(\frac{1}{k^2})$ by Nesterov's accelerated gradient (NAG). Moreover, in the the regime where $k = \Omega(d \log d)$, it outperforms NAG and converges at a faster rate of ${O}\bigl(\frac{\sqrt{d\log k}}{k^{2.5}}\bigr)$. To the best of our knowledge, this result is the first to demonstrate a provable gain of a quasi-Newton-type method over NAG in the convex setting. To achieve such results, we build our method on a recent variant of the Monteiro-Svaiter acceleration framework and adopt an online learning perspective to update the Hessian approximation matrices, in which we relate the convergence rate of our method to the dynamic regret of a specific online convex optimization problem in the space of matrices.
Greedy Pruning with Group Lasso Provably Generalizes for Matrix Sensing and Neural Networks with Quadratic Activations
Mar 20, 2023Pruning schemes have been widely used in practice to reduce the complexity of trained models with a massive number of parameters. Several practical studies have shown that pruning an overparameterized model and fine-tuning generalizes well to new samples. Although the above pipeline, which we refer to as pruning + fine-tuning, has been extremely successful in lowering the complexity of trained models, there is very little known about the theory behind this success. In this paper we address this issue by investigating the pruning + fine-tuning framework on the overparameterized matrix sensing problem, with the ground truth denoted $U_\star \in \mathbb{R}^{d \times r}$ and the overparameterized model $U \in \mathbb{R}^{d \times k}$ with $k \gg r$. We study the approximate local minima of the empirical mean square error, augmented with a smooth version of a group Lasso regularizer, $\sum_{i=1}^k \| U e_i \|_2$ and show that pruning the low $\ell_2$-norm columns results in a solution $U_{\text{prune}}$ which has the minimum number of columns $r$, yet is close to the ground truth in training loss. Initializing the subsequent fine-tuning phase from $U_{\text{prune}}$, the resulting solution converges linearly to a generalization error of $O(\sqrt{rd/n})$ ignoring lower order terms, which is statistically optimal. While our analysis provides insights into the role of regularization in pruning, we also show that running gradient descent in the absence of regularization results in models which {are not suitable for greedy pruning}, i.e., many columns could have their $\ell_2$ norm comparable to that of the maximum. Lastly, we extend our results for the training and pruning of two-layer neural networks with quadratic activation functions. Our results provide the first rigorous insights on why greedy pruning + fine-tuning leads to smaller models which also generalize well.
Online Learning Guided Curvature Approximation: A Quasi-Newton Method with Global Non-Asymptotic Superlinear Convergence
Feb 16, 2023
Quasi-Newton algorithms are among the most popular iterative methods for solving unconstrained minimization problems, largely due to their favorable superlinear convergence property. However, existing results for these algorithms are limited as they provide either (i) a global convergence guarantee with an asymptotic superlinear convergence rate, or (ii) a local non-asymptotic superlinear rate for the case that the initial point and the initial Hessian approximation are chosen properly. Furthermore, these results are not composable, since when the iterates of the globally convergent methods reach the region of local superlinear convergence, it cannot be guaranteed the Hessian approximation matrix will satisfy the required conditions for a non-asymptotic local superlienar convergence rate. In this paper, we close this gap and present the first globally convergent quasi-Newton method with an explicit non-asymptotic superlinear convergence rate. Unlike classical quasi-Newton methods, we build our algorithm upon the hybrid proximal extragradient method and propose a novel online learning framework for updating the Hessian approximation matrices. Specifically, guided by the convergence analysis, we formulate the Hessian approximation update as an online convex optimization problem in the space of matrices, and relate the bounded regret of the online problem to the superlinear convergence of our method.
InfoNCE Loss Provably Learns Cluster-Preserving Representations
Feb 15, 2023

The goal of contrasting learning is to learn a representation that preserves underlying clusters by keeping samples with similar content, e.g. the ``dogness'' of a dog, close to each other in the space generated by the representation. A common and successful approach for tackling this unsupervised learning problem is minimizing the InfoNCE loss associated with the training samples, where each sample is associated with their augmentations (positive samples such as rotation, crop) and a batch of negative samples (unrelated samples). To the best of our knowledge, it was unanswered if the representation learned by minimizing the InfoNCE loss preserves the underlying data clusters, as it only promotes learning a representation that is faithful to augmentations, i.e., an image and its augmentations have the same representation. Our main result is to show that the representation learned by InfoNCE with a finite number of negative samples is also consistent with respect to clusters in the data, under the condition that the augmentation sets within clusters may be non-overlapping but are close and intertwined, relative to the complexity of the learning function class.
Network Adaptive Federated Learning: Congestion and Lossy Compression
Jan 11, 2023



In order to achieve the dual goals of privacy and learning across distributed data, Federated Learning (FL) systems rely on frequent exchanges of large files (model updates) between a set of clients and the server. As such FL systems are exposed to, or indeed the cause of, congestion across a wide set of network resources. Lossy compression can be used to reduce the size of exchanged files and associated delays, at the cost of adding noise to model updates. By judiciously adapting clients' compression to varying network congestion, an FL application can reduce wall clock training time. To that end, we propose a Network Adaptive Compression (NAC-FL) policy, which dynamically varies the client's lossy compression choices to network congestion variations. We prove, under appropriate assumptions, that NAC-FL is asymptotically optimal in terms of directly minimizing the expected wall clock training time. Further, we show via simulation that NAC-FL achieves robust performance improvements with higher gains in settings with positively correlated delays across time.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022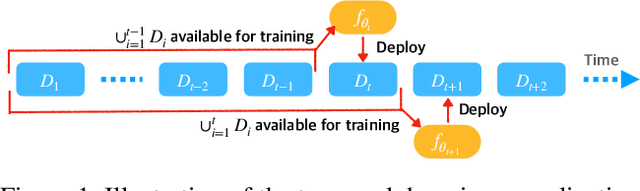
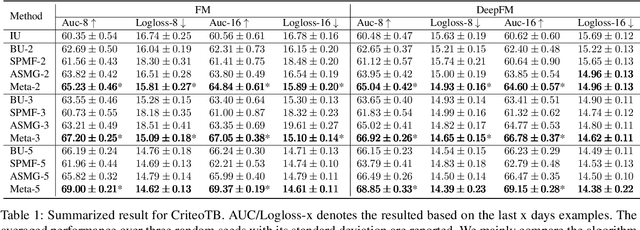
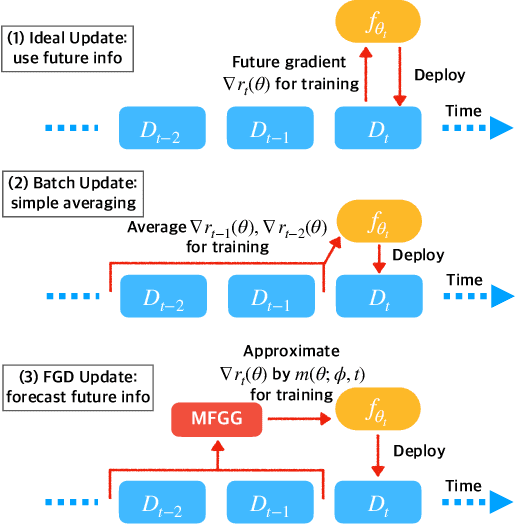
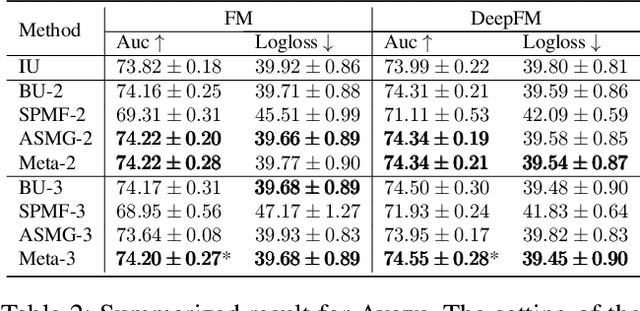
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
Generalized Frank-Wolfe Algorithm for Bilevel Optimization
Jun 17, 2022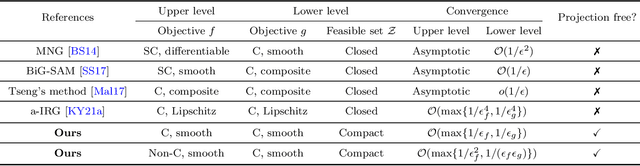
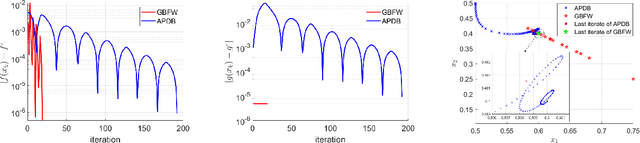
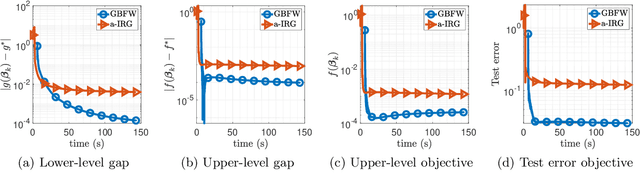
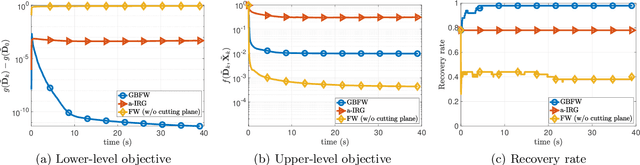
In this paper, we study a class of bilevel optimization problems, also known as simple bilevel optimization, where we minimize a smooth objective function over the optimal solution set of another convex constrained optimization problem. Several iterative methods have been developed for tackling this class of problems. Alas, their convergence guarantees are not satisfactory as they are either asymptotic for the upper-level objective, or the convergence rates are slow and sub-optimal. To address this issue, in this paper, we introduce a generalization of the Frank-Wolfe (FW) method to solve the considered problem. The main idea of our method is to locally approximate the solution set of the lower-level problem via a cutting plane, and then run a FW-type update to decrease the upper-level objective. When the upper-level objective is convex, we show that our method requires ${\mathcal{O}}(\max\{1/\epsilon_f,1/\epsilon_g\})$ iterations to find a solution that is $\epsilon_f$-optimal for the upper-level objective and $\epsilon_g$-optimal for the lower-level objective. Moreover, when the upper-level objective is non-convex, our method requires ${\mathcal{O}}(\max\{1/\epsilon_f^2,1/(\epsilon_f\epsilon_g)\})$ iterations to find an $(\epsilon_f,\epsilon_g)$-optimal solution. We further prove stronger convergence guarantees under the H\"olderian error bound assumption on the lower-level problem. To the best of our knowledge, our method achieves the best-known iteration complexity for the considered bilevel problem. We also present numerical experiments to showcase the superior performance of our method compared with state-of-the-art methods.
Straggler-Resilient Personalized Federated Learning
Jun 05, 2022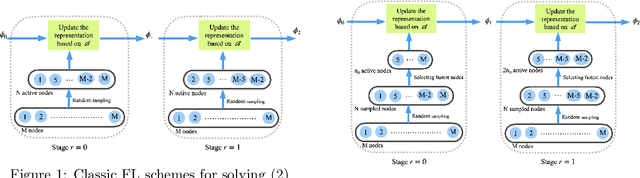
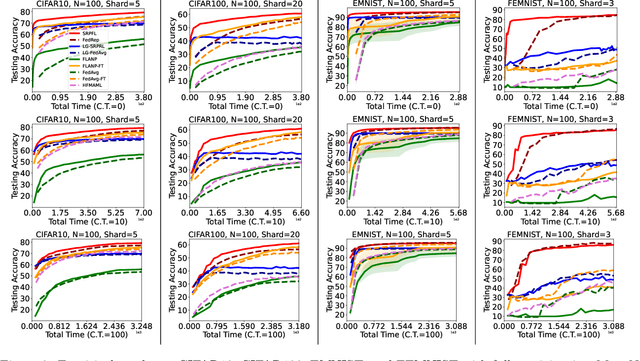
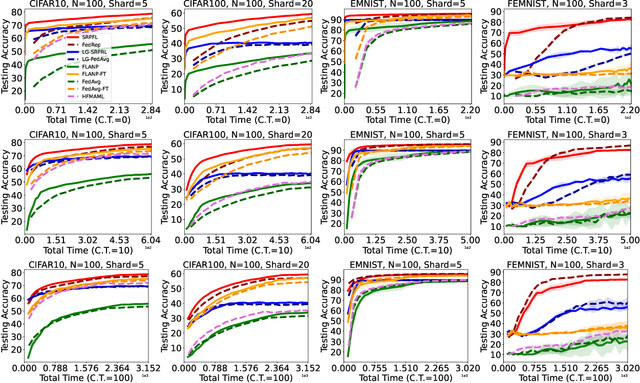
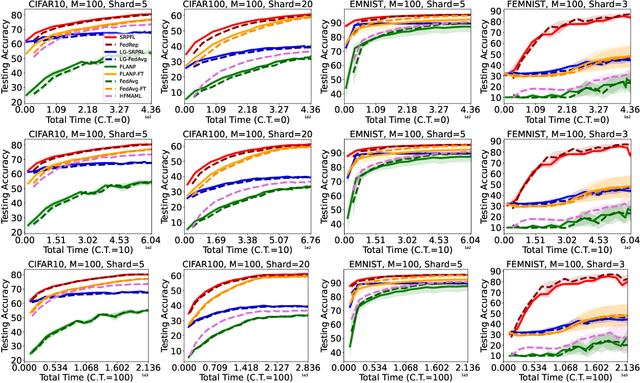
Federated Learning is an emerging learning paradigm that allows training models from samples distributed across a large network of clients while respecting privacy and communication restrictions. Despite its success, federated learning faces several challenges related to its decentralized nature. In this work, we develop a novel algorithmic procedure with theoretical speedup guarantees that simultaneously handles two of these hurdles, namely (i) data heterogeneity, i.e., data distributions can vary substantially across clients, and (ii) system heterogeneity, i.e., the computational power of the clients could differ significantly. Our method relies on ideas from representation learning theory to find a global common representation using all clients' data and learn a user-specific set of parameters leading to a personalized solution for each client. Furthermore, our method mitigates the effects of stragglers by adaptively selecting clients based on their computational characteristics and statistical significance, thus achieving, for the first time, near optimal sample complexity and provable logarithmic speedup. Experimental results support our theoretical findings showing the superiority of our method over alternative personalized federated schemes in system and data heterogeneous environments.
FedAvg with Fine Tuning: Local Updates Lead to Representation Learning
May 27, 2022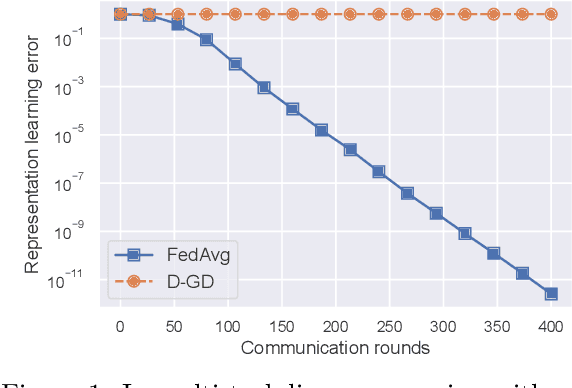

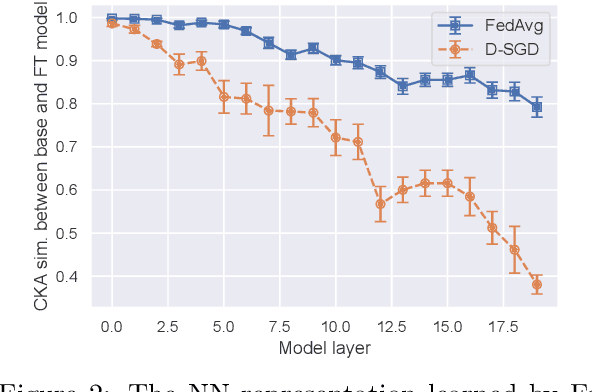
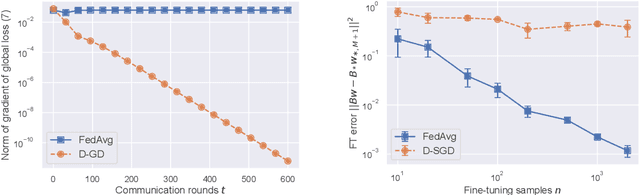
The Federated Averaging (FedAvg) algorithm, which consists of alternating between a few local stochastic gradient updates at client nodes, followed by a model averaging update at the server, is perhaps the most commonly used method in Federated Learning. Notwithstanding its simplicity, several empirical studies have illustrated that the output model of FedAvg, after a few fine-tuning steps, leads to a model that generalizes well to new unseen tasks. This surprising performance of such a simple method, however, is not fully understood from a theoretical point of view. In this paper, we formally investigate this phenomenon in the multi-task linear representation setting. We show that the reason behind generalizability of the FedAvg's output is its power in learning the common data representation among the clients' tasks, by leveraging the diversity among client data distributions via local updates. We formally establish the iteration complexity required by the clients for proving such result in the setting where the underlying shared representation is a linear map. To the best of our knowledge, this is the first such result for any setting. We also provide empirical evidence demonstrating FedAvg's representation learning ability in federated image classification with heterogeneous data.