 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Syllables in Language Modelling and their Application on Low-Resource Machine Translation
Oct 05, 2022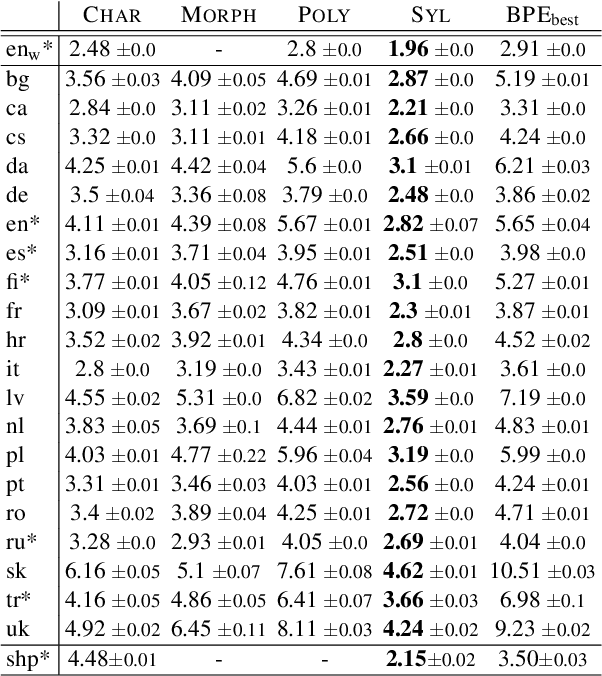
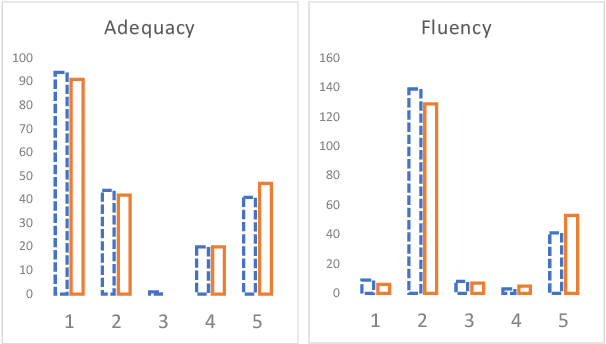

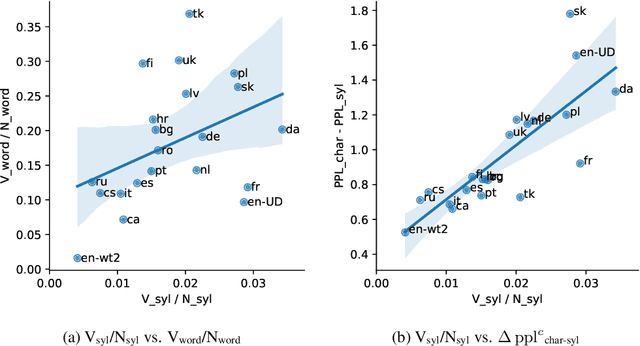
Language modelling and machine translation tasks mostly use subword or character inputs, but syllables are seldom used. Syllables provide shorter sequences than characters, require less-specialised extracting rules than morphemes, and their segmentation is not impacted by the corpus size. In this study, we first explore the potential of syllables for open-vocabulary language modelling in 21 languages. We use rule-based syllabification methods for six languages and address the rest with hyphenation, which works as a syllabification proxy. With a comparable perplexity, we show that syllables outperform characters and other subwords. Moreover, we study the importance of syllables on neural machine translation for a non-related and low-resource language-pair (Spanish--Shipibo-Konibo). In pairwise and multilingual systems, syllables outperform unsupervised subwords, and further morphological segmentation methods, when translating into a highly synthetic language with a transparent orthography (Shipibo-Konibo). Finally, we perform some human evaluation, and discuss limitations and opportunities.
Building an Endangered Language Resource in the Classroom: Universal Dependencies for Kakataibo
Jun 21, 2022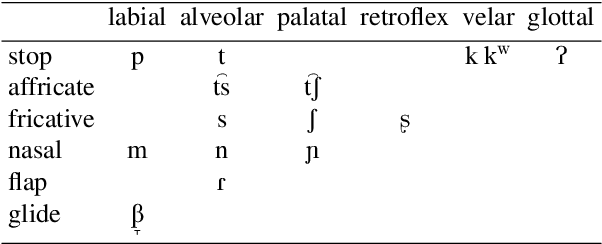
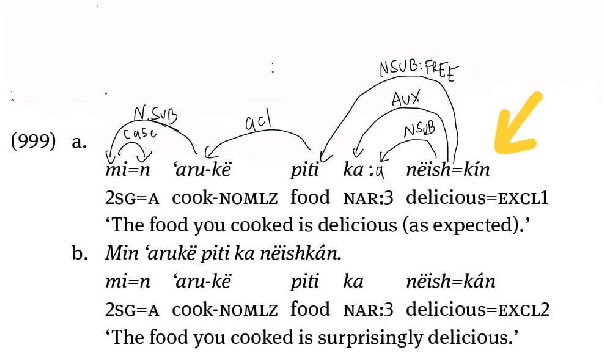
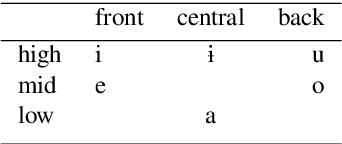
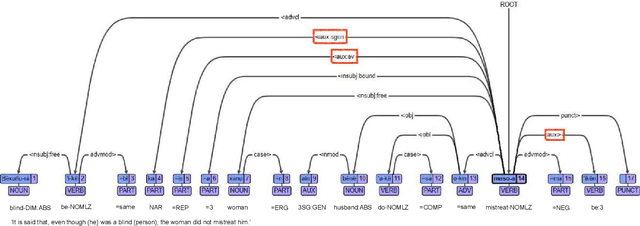
In this paper, we launch a new Universal Dependencies treebank for an endangered language from Amazonia: Kakataibo, a Panoan language spoken in Peru. We first discuss the collaborative methodology implemented, which proved effective to create a treebank in the context of a Computational Linguistic course for undergraduates. Then, we describe the general details of the treebank and the language-specific considerations implemented for the proposed annotation. We finally conduct some experiments on part-of-speech tagging and syntactic dependency parsing. We focus on monolingual and transfer learning settings, where we study the impact of a Shipibo-Konibo treebank, another Panoan language resource.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.