 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeLAVA: Learning-Agnostic Data Valuation for Time Series
Jun 17, 2026Data valuation quantifies the intrinsic quality of individual samples to enable principled data curation, quality control, and robust learning. For time series in critical domains such as healthcare, finance, and industrial monitoring, effective valuation methods are essential yet fundamentally lacking. Existing approaches are either model-dependent, limiting their generalizability, or designed for i.i.d. data and thus fail to capture temporal dependencies, multi-scale patterns, and non-stationary dynamics inherent to sequential data. We introduce TimeLAVA, a learning-agnostic framework that values temporal segments by their marginal contribution to minimizing distributional discrepancy between evaluated and reference data. At its core is a novel Selective Wavelet-based Wasserstein discrepancy combining multi-scale wavelet transforms for temporal localization with unbalanced optimal transport for robustness to distributional shifts. Segment values are efficiently computed via sensitivity analysis without requiring model training and aggregated into point-wise scores. We provide theoretical guarantees linking valuation to model-agnostic generalization and prove bounded sensitivity to outlier contamination. Extensive experiments across anomaly detection, data pruning, and label noise detection demonstrate that TimeLAVA produces significantly more informative value scores than existing methods on diverse real-world datasets.
* 34pages
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
Apr 12, 2026Chain-of-Thought (CoT) prompting has improved LLM reasoning, but models often generate explanations that appear coherent while containing unfaithful intermediate steps. Existing self-evaluation approaches are prone to inherent biases: the model may confidently endorse coherence even when the step-to-step implication is not valid, leading to unreliable faithfulness evaluation. We propose FACT-E, a causality-inspired framework for evaluating CoT quality. FACT-E uses controlled perturbations as an instrumental signal to separate genuine step-to-step dependence from bias-driven artifacts, producing more reliable faithfulness estimates (\textit{intra-chain faithfulness}). To select trustworthy trajectories, FACT-E jointly considers \textit{intra-chain faithfulness} and \textit{CoT-to-answer consistency}, ensuring that selected chains are both faithful internally and supportive of the correct final answer. Experiments on GSM8K, MATH, and CommonsenseQA show that FACT-E improves reasoning-trajectory selection and yields stronger in-context learning exemplars. FACT-E also reliably detects flawed reasoning under noisy conditions, providing a robust metric for trustworthy LLM reasoning.
Observationally Informed Adaptive Causal Experimental Design
Mar 04, 2026Randomized Controlled Trials (RCTs) represent the gold standard for causal inference yet remain a scarce resource. While large-scale observational data is often available, it is utilized only for retrospective fusion, and remains discarded in prospective trial design due to bias concerns. We argue this "tabula rasa" data acquisition strategy is fundamentally inefficient. In this work, we propose Active Residual Learning, a new paradigm that leverages the observational model as a foundational prior. This approach shifts the experimental focus from learning target causal quantities from scratch to efficiently estimating the residuals required to correct observational bias. To operationalize this, we introduce the R-Design framework. Theoretically, we establish two key advantages: (1) a structural efficiency gap, proving that estimating smooth residual contrasts admits strictly faster convergence rates than reconstructing full outcomes; and (2) information efficiency, where we quantify the redundancy in standard parameter-based acquisition (e.g., BALD), demonstrating that such baselines waste budget on task-irrelevant nuisance uncertainty. We propose R-EPIG (Residual Expected Predictive Information Gain), a unified criterion that directly targets the causal estimand, minimizing residual uncertainty for estimation or clarifying decision boundaries for policy. Experiments on synthetic and semi-synthetic benchmarks demonstrate that R-Design significantly outperforms baselines, confirming that repairing a biased model is far more efficient than learning one from scratch.
Interventional Fairness on Partially Known Causal Graphs: A Constrained Optimization Approach
Jan 19, 2024



Fair machine learning aims to prevent discrimination against individuals or sub-populations based on sensitive attributes such as gender and race. In recent years, causal inference methods have been increasingly used in fair machine learning to measure unfairness by causal effects. However, current methods assume that the true causal graph is given, which is often not true in real-world applications. To address this limitation, this paper proposes a framework for achieving causal fairness based on the notion of interventions when the true causal graph is partially known. The proposed approach involves modeling fair prediction using a Partially Directed Acyclic Graph (PDAG), specifically, a class of causal DAGs that can be learned from observational data combined with domain knowledge. The PDAG is used to measure causal fairness, and a constrained optimization problem is formulated to balance between fairness and accuracy. Results on both simulated and real-world datasets demonstrate the effectiveness of this method.
Counterfactual Fairness with Partially Known Causal Graph
May 27, 2022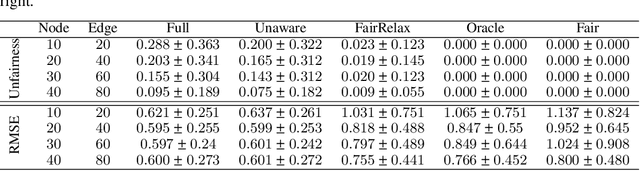
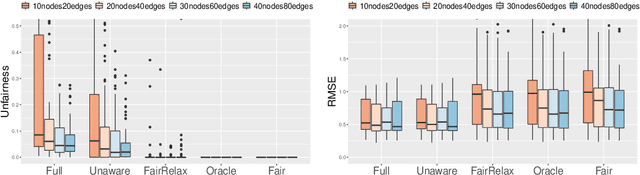

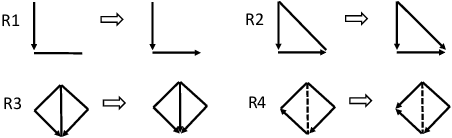
Fair machine learning aims to avoid treating individuals or sub-populations unfavourably based on \textit{sensitive attributes}, such as gender and race. Those methods in fair machine learning that are built on causal inference ascertain discrimination and bias through causal effects. Though causality-based fair learning is attracting increasing attention, current methods assume the true causal graph is fully known. This paper proposes a general method to achieve the notion of counterfactual fairness when the true causal graph is unknown. To be able to select features that lead to counterfactual fairness, we derive the conditions and algorithms to identify ancestral relations between variables on a \textit{Partially Directed Acyclic Graph (PDAG)}, specifically, a class of causal DAGs that can be learned from observational data combined with domain knowledge. Interestingly, we find that counterfactual fairness can be achieved as if the true causal graph were fully known, when specific background knowledge is provided: the sensitive attributes do not have ancestors in the causal graph. Results on both simulated and real-world datasets demonstrate the effectiveness of our method.