 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Bayesian Optimization with $φ$-divergences
Mar 04, 2022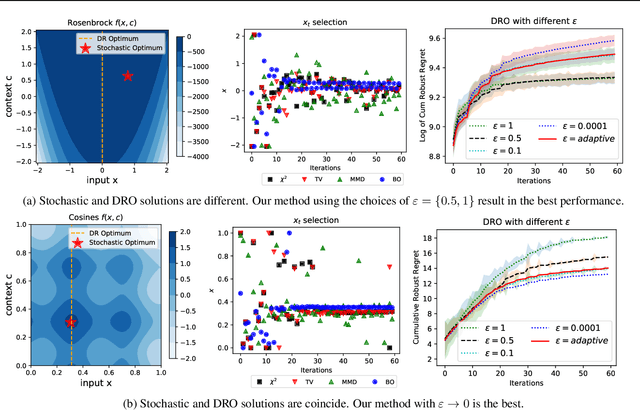
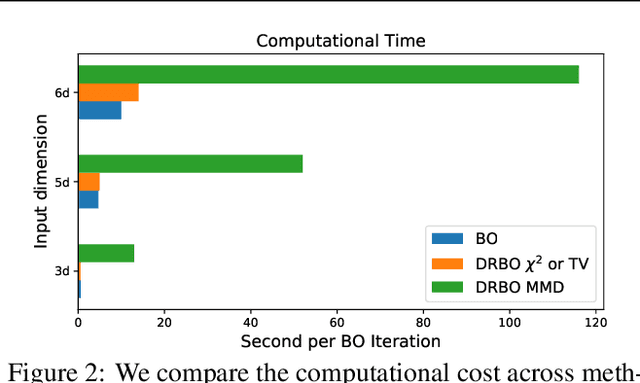
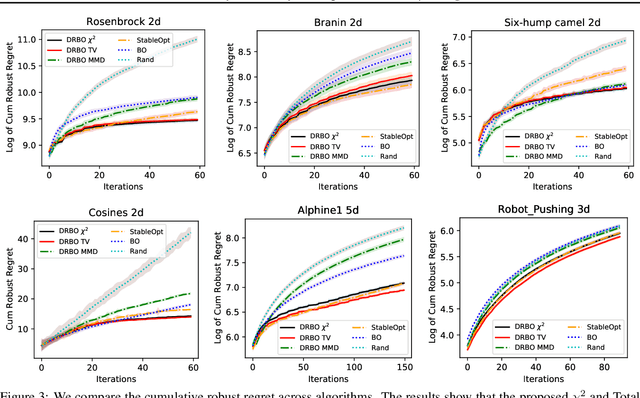
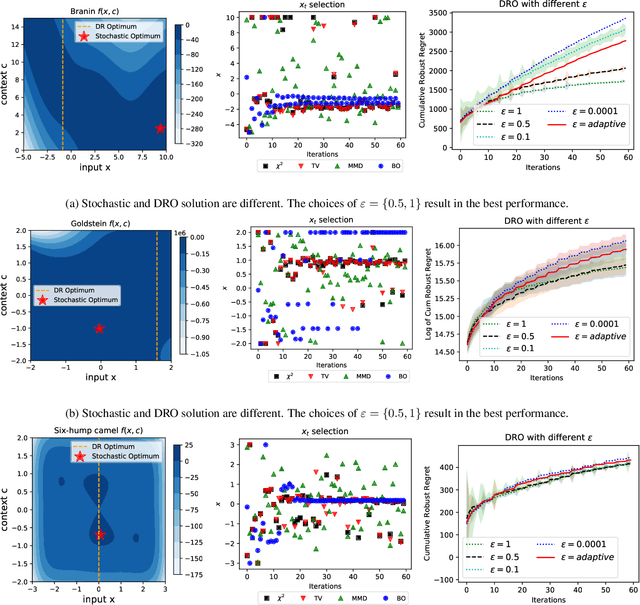
The study of robustness has received much attention due to its inevitability in data-driven settings where many systems face uncertainty. One such example of concern is Bayesian Optimization (BO), where uncertainty is multi-faceted, yet there only exists a limited number of works dedicated to this direction. In particular, there is the work of Kirschner et al. (2020), which bridges the existing literature of Distributionally Robust Optimization (DRO) by casting the BO problem from the lens of DRO. While this work is pioneering, it admittedly suffers from various practical shortcomings such as finite contexts assumptions, leaving behind the main question Can one devise a computationally tractable algorithm for solving this DRO-BO problem? In this work, we tackle this question to a large degree of generality by considering robustness against data-shift in $\phi$-divergences, which subsumes many popular choices, such as the $\chi^2$-divergence, Total Variation, and the extant Kullback-Leibler (KL) divergence. We show that the DRO-BO problem in this setting is equivalent to a finite-dimensional optimization problem which, even in the continuous context setting, can be easily implemented with provable sublinear regret bounds. We then show experimentally that our method surpasses existing methods, attesting to the theoretical results
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022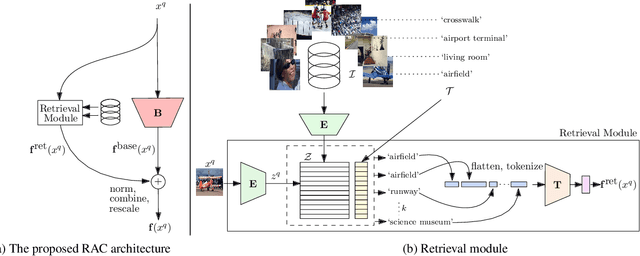
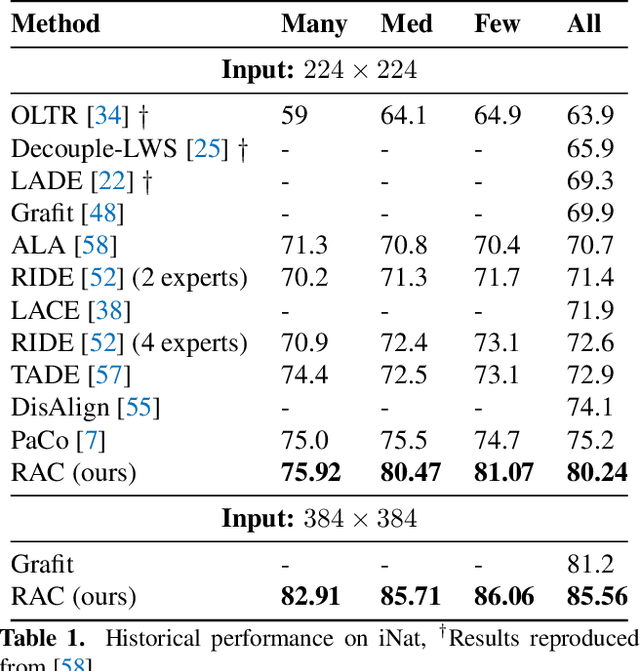
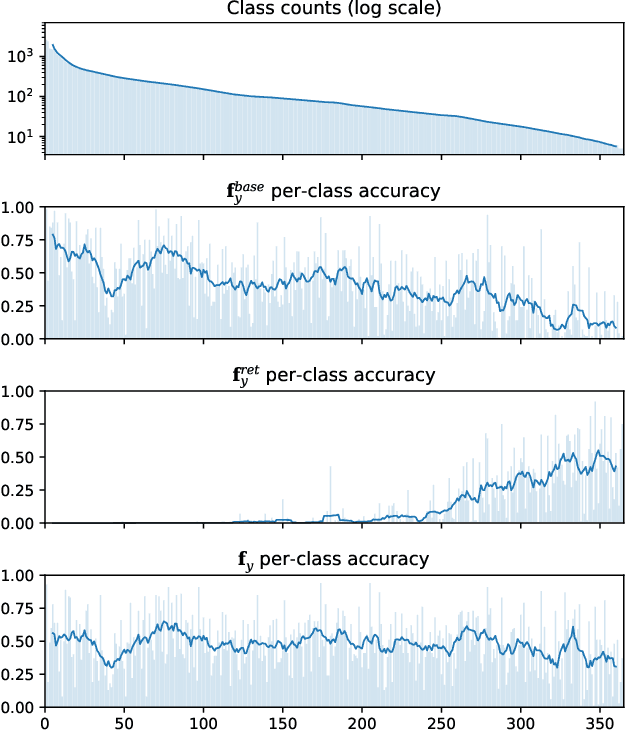
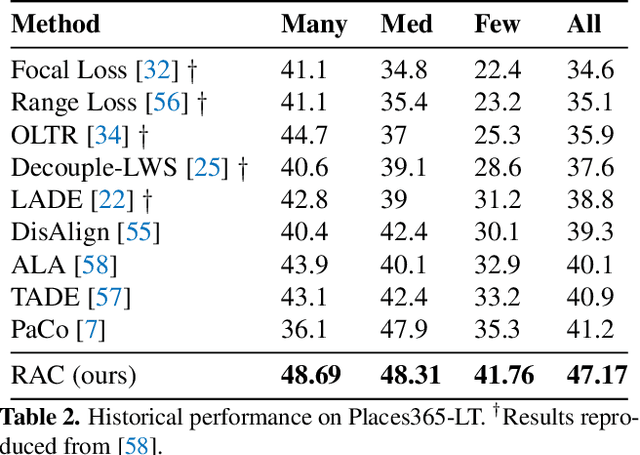
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Learning Bayesian Sparse Networks with Full Experience Replay for Continual Learning
Feb 21, 2022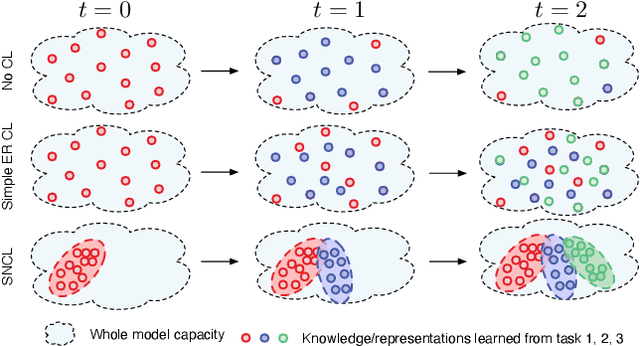
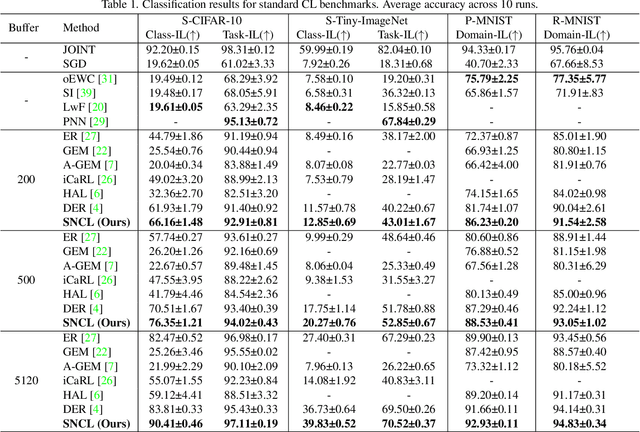
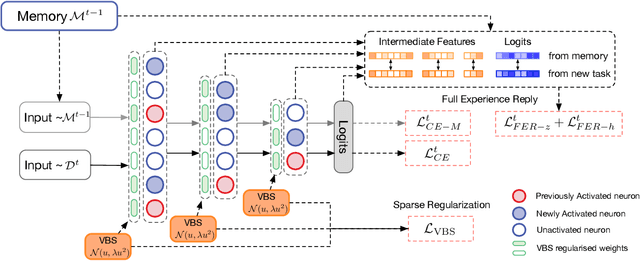
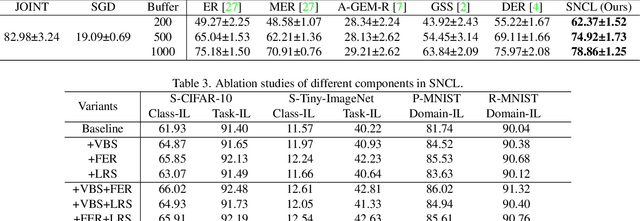
Continual Learning (CL) methods aim to enable machine learning models to learn new tasks without catastrophic forgetting of those that have been previously mastered. Existing CL approaches often keep a buffer of previously-seen samples, perform knowledge distillation, or use regularization techniques towards this goal. Despite their performance, they still suffer from interference across tasks which leads to catastrophic forgetting. To ameliorate this problem, we propose to only activate and select sparse neurons for learning current and past tasks at any stage. More parameters space and model capacity can thus be reserved for the future tasks. This minimizes the interference between parameters for different tasks. To do so, we propose a Sparse neural Network for Continual Learning (SNCL), which employs variational Bayesian sparsity priors on the activations of the neurons in all layers. Full Experience Replay (FER) provides effective supervision in learning the sparse activations of the neurons in different layers. A loss-aware reservoir-sampling strategy is developed to maintain the memory buffer. The proposed method is agnostic as to the network structures and the task boundaries. Experiments on different datasets show that our approach achieves state-of-the-art performance for mitigating forgetting.
Deep Learning for Hate Speech Detection: A Comparative Study
Feb 19, 2022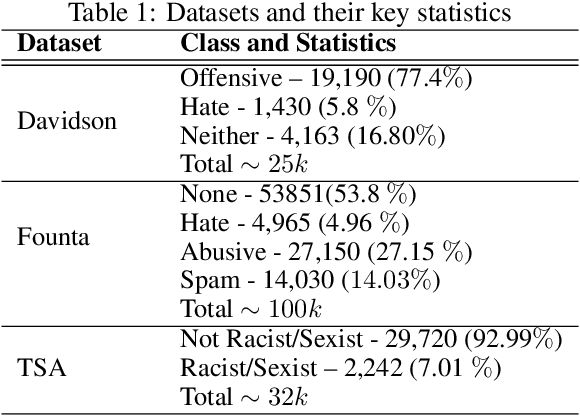
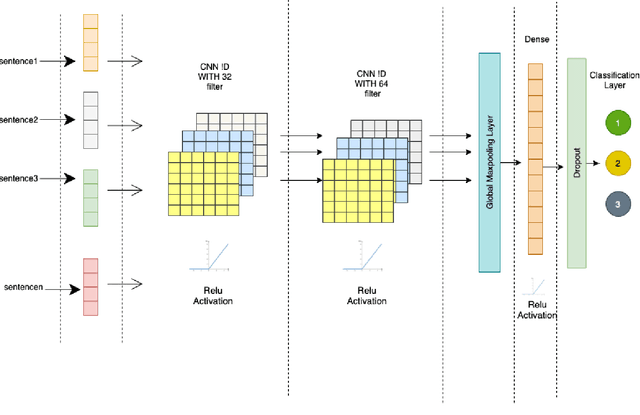
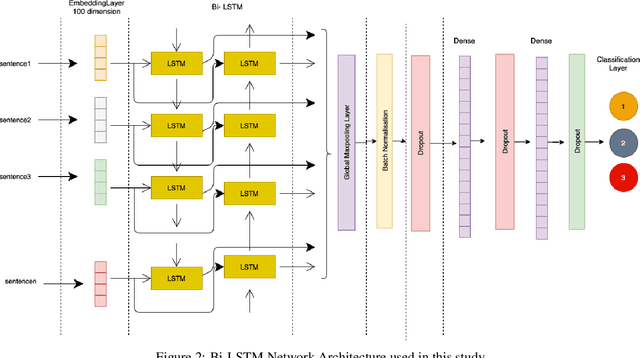
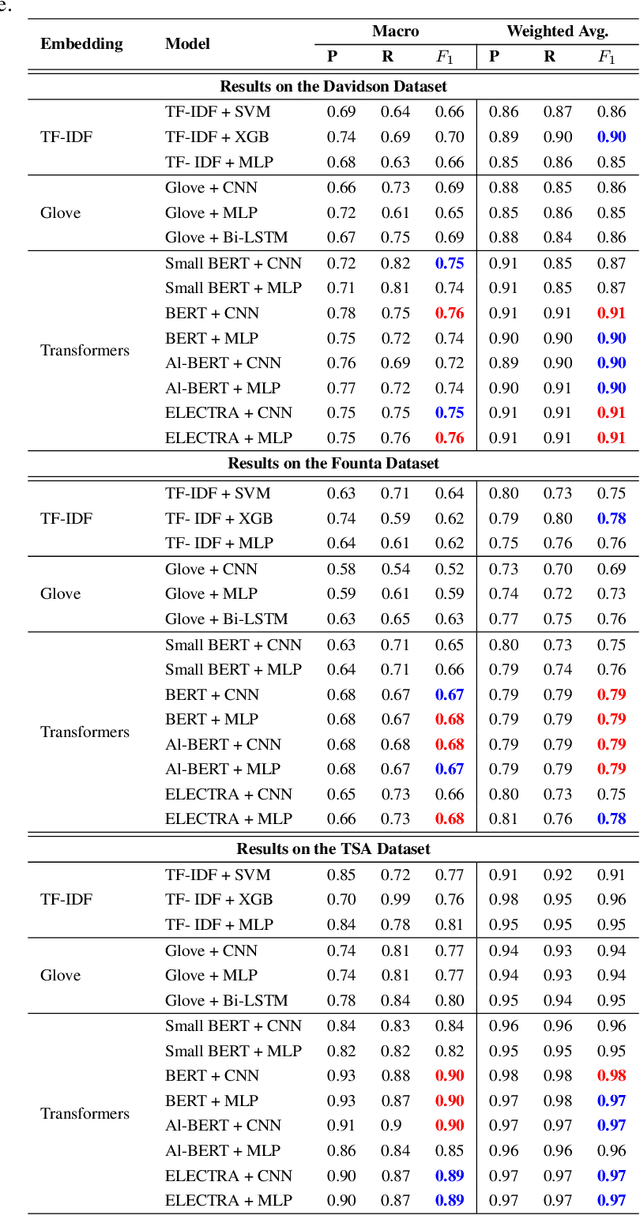
Automated hate speech detection is an important tool in combating the spread of hate speech, particularly in social media. Numerous methods have been developed for the task, including a recent proliferation of deep-learning based approaches. A variety of datasets have also been developed, exemplifying various manifestations of the hate-speech detection problem. We present here a large-scale empirical comparison of deep and shallow hate-speech detection methods, mediated through the three most commonly used datasets. Our goal is to illuminate progress in the area, and identify strengths and weaknesses in the current state-of-the-art. We particularly focus our analysis on measures of practical performance, including detection accuracy, computational efficiency, capability in using pre-trained models, and domain generalization. In doing so we aim to provide guidance as to the use of hate-speech detection in practice, quantify the state-of-the-art, and identify future research directions. Code and dataset are available at https://github.com/jmjmalik22/Hate-Speech-Detection.
The devil is in the labels: Semantic segmentation from sentences
Feb 04, 2022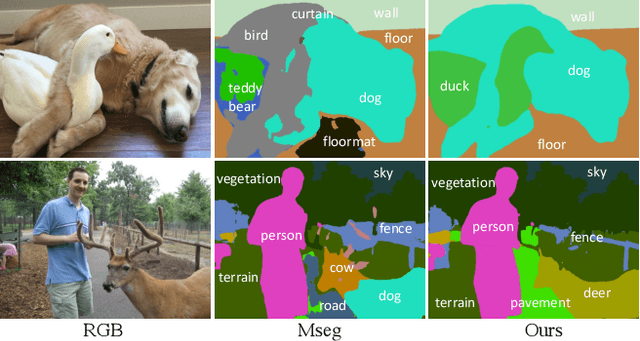
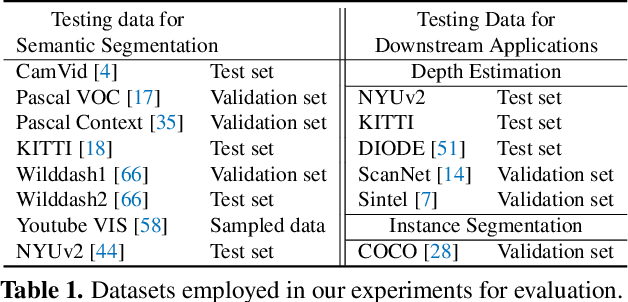
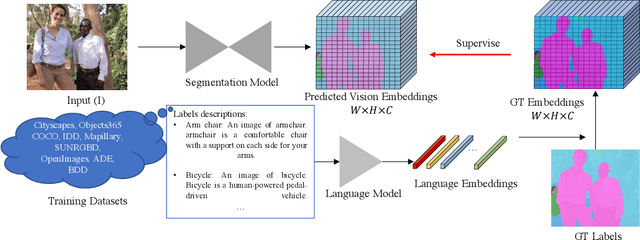
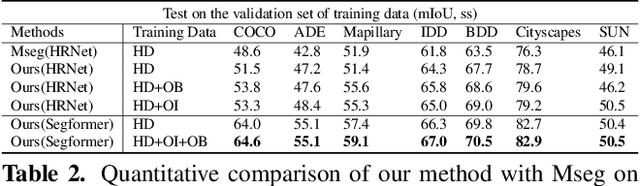
We propose an approach to semantic segmentation that achieves state-of-the-art supervised performance when applied in a zero-shot setting. It thus achieves results equivalent to those of the supervised methods, on each of the major semantic segmentation datasets, without training on those datasets. This is achieved by replacing each class label with a vector-valued embedding of a short paragraph that describes the class. The generality and simplicity of this approach enables merging multiple datasets from different domains, each with varying class labels and semantics. The resulting merged semantic segmentation dataset of over 2 Million images enables training a model that achieves performance equal to that of state-of-the-art supervised methods on 7 benchmark datasets, despite not using any images therefrom. By fine-tuning the model on standard semantic segmentation datasets, we also achieve a significant improvement over the state-of-the-art supervised segmentation on NYUD-V2 and PASCAL-context at 60% and 65% mIoU, respectively. Based on the closeness of language embeddings, our method can even segment unseen labels. Extensive experiments demonstrate strong generalization to unseen image domains and unseen labels, and that the method enables impressive performance improvements in downstream applications, including depth estimation and instance segmentation.
Poseur: Direct Human Pose Regression with Transformers
Jan 19, 2022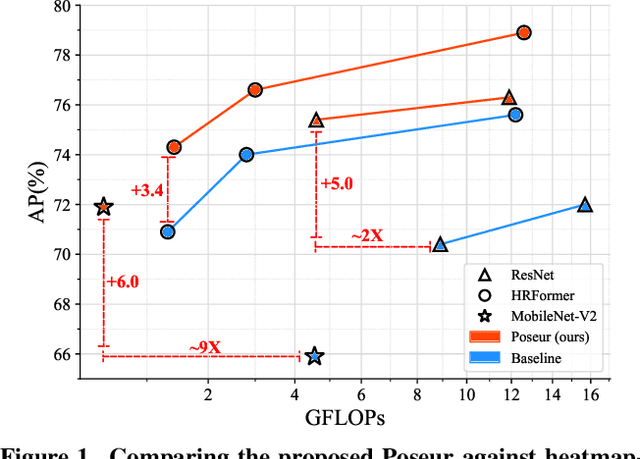
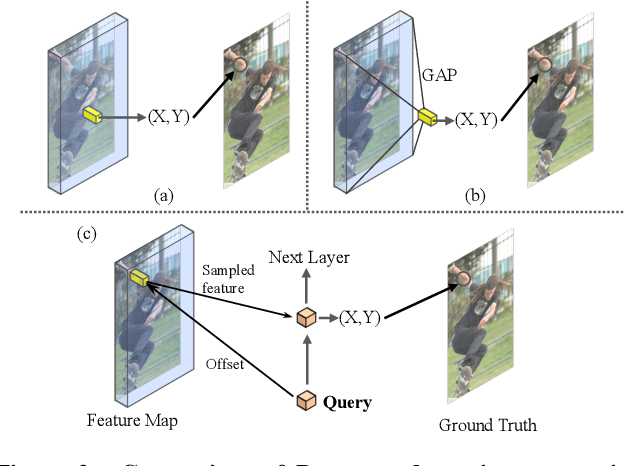
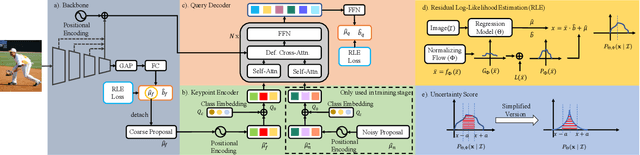

We propose a direct, regression-based approach to 2D human pose estimation from single images. We formulate the problem as a sequence prediction task, which we solve using a Transformer network. This network directly learns a regression mapping from images to the keypoint coordinates, without resorting to intermediate representations such as heatmaps. This approach avoids much of the complexity associated with heatmap-based approaches. To overcome the feature misalignment issues of previous regression-based methods, we propose an attention mechanism that adaptively attends to the features that are most relevant to the target keypoints, considerably improving the accuracy. Importantly, our framework is end-to-end differentiable, and naturally learns to exploit the dependencies between keypoints. Experiments on MS-COCO and MPII, two predominant pose-estimation datasets, demonstrate that our method significantly improves upon the state-of-the-art in regression-based pose estimation. More notably, ours is the first regression-based approach to perform favorably compared to the best heatmap-based pose estimation methods.
Deep Graph-level Anomaly Detection by Glocal Knowledge Distillation
Dec 19, 2021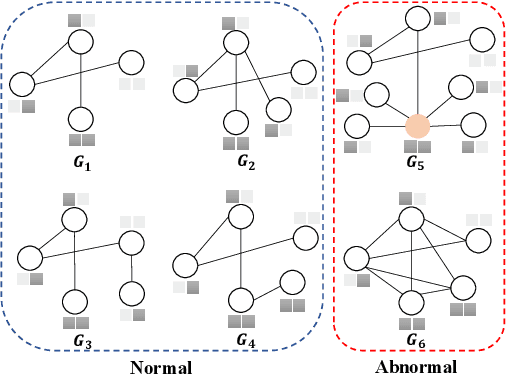
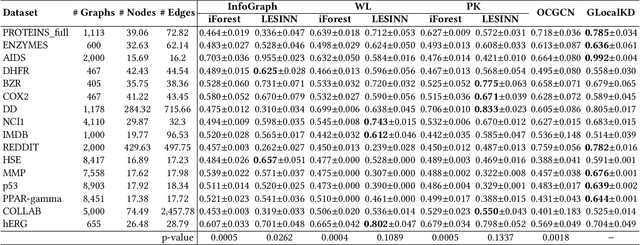
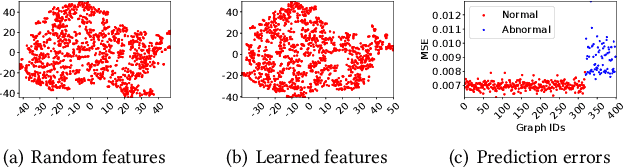
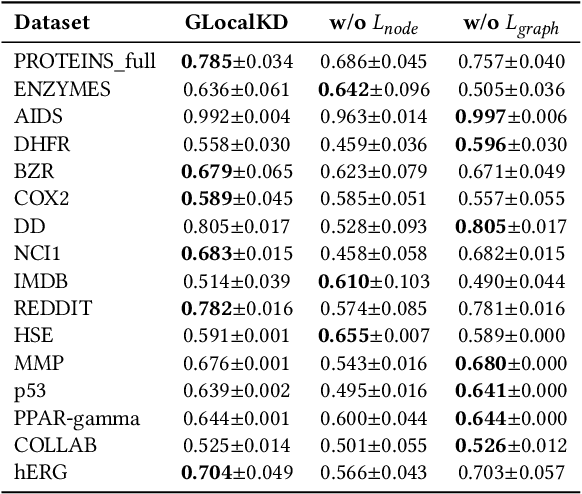
Graph-level anomaly detection (GAD) describes the problem of detecting graphs that are abnormal in their structure and/or the features of their nodes, as compared to other graphs. One of the challenges in GAD is to devise graph representations that enable the detection of both locally- and globally-anomalous graphs, i.e., graphs that are abnormal in their fine-grained (node-level) or holistic (graph-level) properties, respectively. To tackle this challenge we introduce a novel deep anomaly detection approach for GAD that learns rich global and local normal pattern information by joint random distillation of graph and node representations. The random distillation is achieved by training one GNN to predict another GNN with randomly initialized network weights. Extensive experiments on 16 real-world graph datasets from diverse domains show that our model significantly outperforms seven state-of-the-art models. Code and datasets are available at https://git.io/GLocalKD.
Explainable Deep Few-shot Anomaly Detection with Deviation Networks
Aug 01, 2021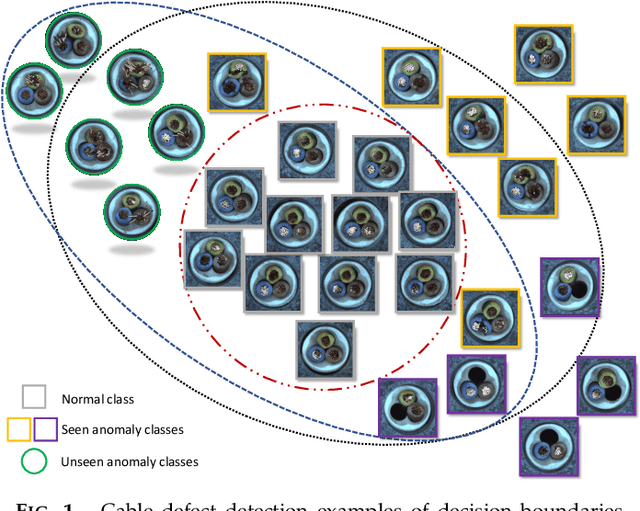
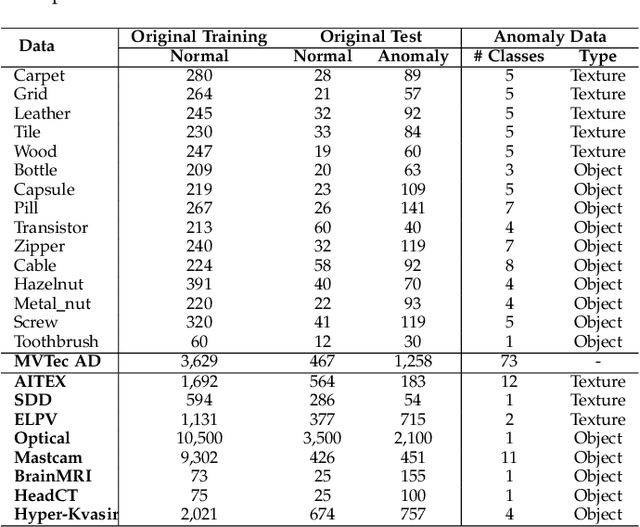
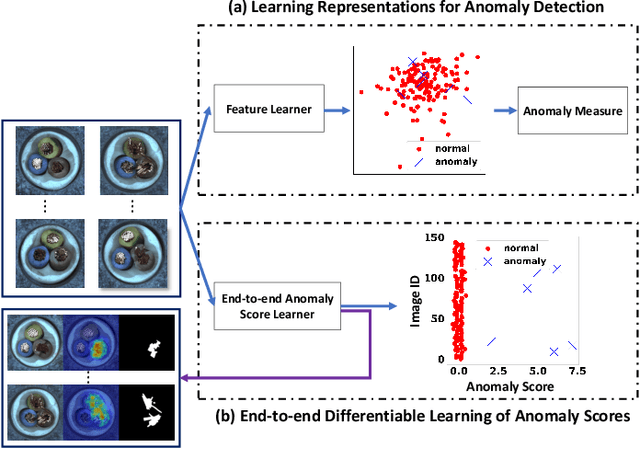
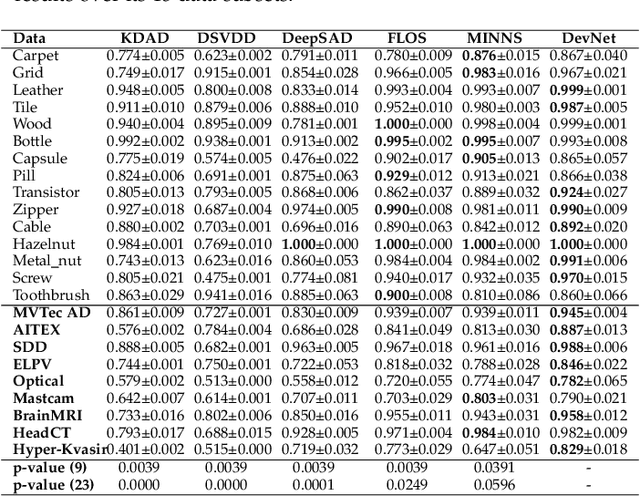
Existing anomaly detection paradigms overwhelmingly focus on training detection models using exclusively normal data or unlabeled data (mostly normal samples). One notorious issue with these approaches is that they are weak in discriminating anomalies from normal samples due to the lack of the knowledge about the anomalies. Here, we study the problem of few-shot anomaly detection, in which we aim at using a few labeled anomaly examples to train sample-efficient discriminative detection models. To address this problem, we introduce a novel weakly-supervised anomaly detection framework to train detection models without assuming the examples illustrating all possible classes of anomaly. Specifically, the proposed approach learns discriminative normality (regularity) by leveraging the labeled anomalies and a prior probability to enforce expressive representations of normality and unbounded deviated representations of abnormality. This is achieved by an end-to-end optimization of anomaly scores with a neural deviation learning, in which the anomaly scores of normal samples are imposed to approximate scalar scores drawn from the prior while that of anomaly examples is enforced to have statistically significant deviations from these sampled scores in the upper tail. Furthermore, our model is optimized to learn fine-grained normality and abnormality by top-K multiple-instance-learning-based feature subspace deviation learning, allowing more generalized representations. Comprehensive experiments on nine real-world image anomaly detection benchmarks show that our model is substantially more sample-efficient and robust, and performs significantly better than state-of-the-art competing methods in both closed-set and open-set settings. Our model can also offer explanation capability as a result of its prior-driven anomaly score learning. Code and datasets are available at: https://git.io/DevNet.
Dynamic Convolution for 3D Point Cloud Instance Segmentation
Jul 18, 2021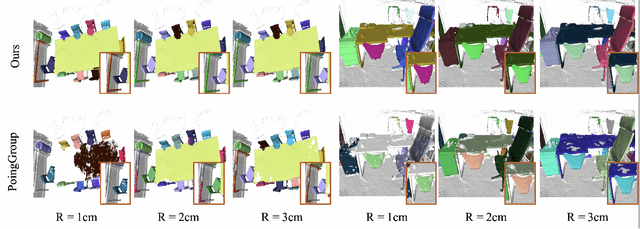
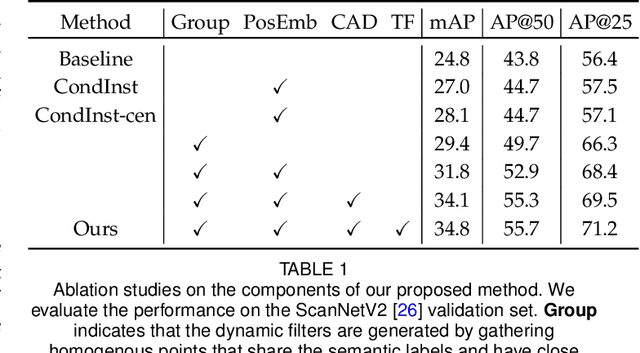

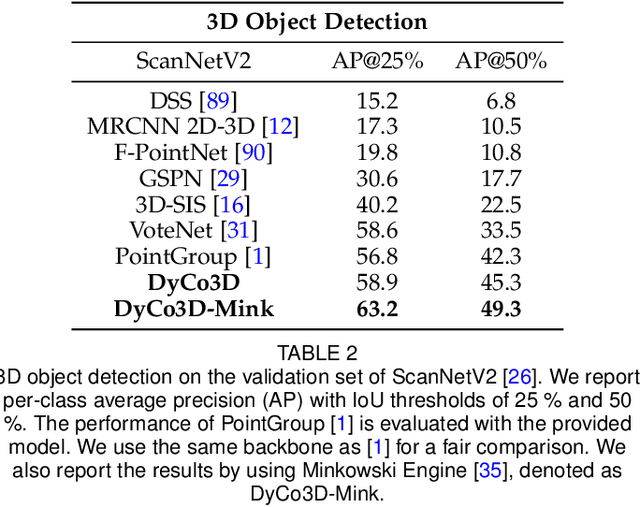
We propose an approach to instance segmentation from 3D point clouds based on dynamic convolution. This enables it to adapt, at inference, to varying feature and object scales. Doing so avoids some pitfalls of bottom up approaches, including a dependence on hyper-parameter tuning and heuristic post-processing pipelines to compensate for the inevitable variability in object sizes, even within a single scene. The representation capability of the network is greatly improved by gathering homogeneous points that have identical semantic categories and close votes for the geometric centroids. Instances are then decoded via several simple convolution layers, where the parameters are generated conditioned on the input. The proposed approach is proposal-free, and instead exploits a convolution process that adapts to the spatial and semantic characteristics of each instance. A light-weight transformer, built on the bottleneck layer, allows the model to capture long-range dependencies, with limited computational overhead. The result is a simple, efficient, and robust approach that yields strong performance on various datasets: ScanNetV2, S3DIS, and PartNet. The consistent improvements on both voxel- and point-based architectures imply the effectiveness of the proposed method. Code is available at: https://git.io/DyCo3D
Evading the Simplicity Bias: Training a Diverse Set of Models Discovers Solutions with Superior OOD Generalization
May 18, 2021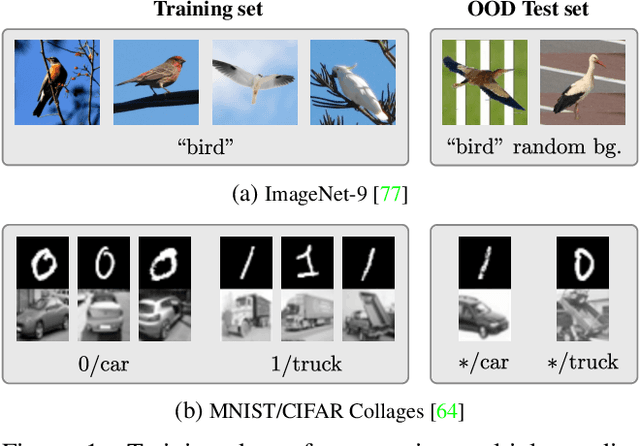
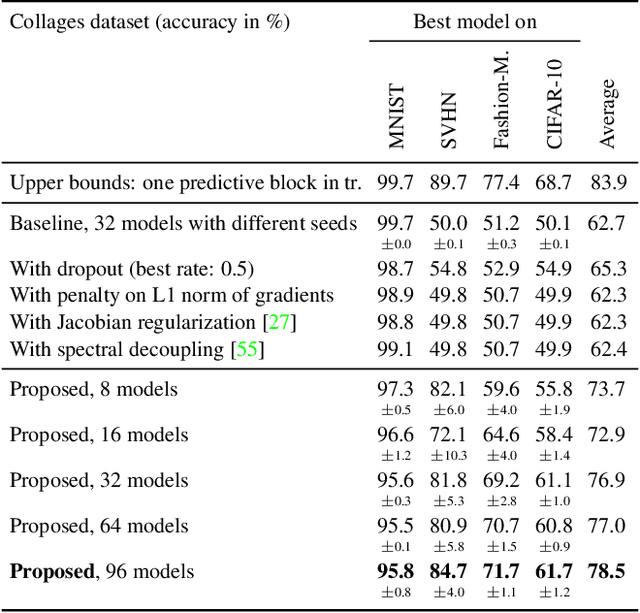
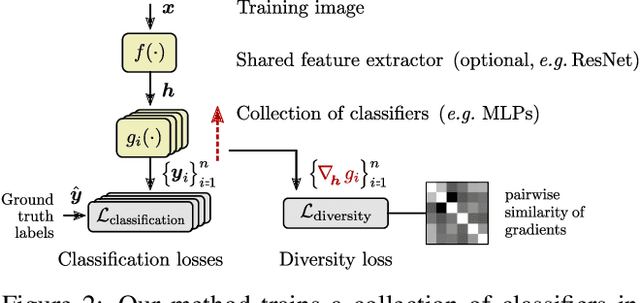
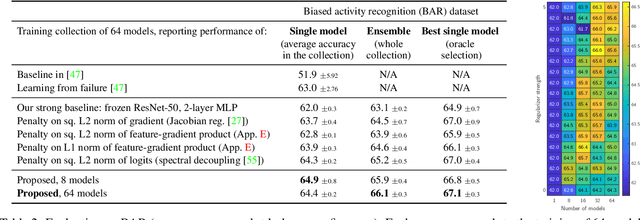
Neural networks trained with SGD were recently shown to rely preferentially on linearly-predictive features and can ignore complex, equally-predictive ones. This simplicity bias can explain their lack of robustness out of distribution (OOD). The more complex the task to learn, the more likely it is that statistical artifacts (i.e. selection biases, spurious correlations) are simpler than the mechanisms to learn. We demonstrate that the simplicity bias can be mitigated and OOD generalization improved. We train a set of similar models to fit the data in different ways using a penalty on the alignment of their input gradients. We show theoretically and empirically that this induces the learning of more complex predictive patterns. OOD generalization fundamentally requires information beyond i.i.d. examples, such as multiple training environments, counterfactual examples, or other side information. Our approach shows that we can defer this requirement to an independent model selection stage. We obtain SOTA results in visual recognition on biased data and generalization across visual domains. The method - the first to evade the simplicity bias - highlights the need for a better understanding and control of inductive biases in deep learning.