 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Collective Structure Knowledge in Data Augmentation for Graph Neural Networks
May 17, 2024Graph neural networks (GNNs) have achieved state-of-the-art performance in graph representation learning. Message passing neural networks, which learn representations through recursively aggregating information from each node and its neighbors, are among the most commonly-used GNNs. However, a wealth of structural information of individual nodes and full graphs is often ignored in such process, which restricts the expressive power of GNNs. Various graph data augmentation methods that enable the message passing with richer structure knowledge have been introduced as one main way to tackle this issue, but they are often focused on individual structure features and difficult to scale up with more structure features. In this work we propose a novel approach, namely collective structure knowledge-augmented graph neural network (CoS-GNN), in which a new message passing method is introduced to allow GNNs to harness a diverse set of node- and graph-level structure features, together with original node features/attributes, in augmented graphs. In doing so, our approach largely improves the structural knowledge modeling of GNNs in both node and graph levels, resulting in substantially improved graph representations. This is justified by extensive empirical results where CoS-GNN outperforms state-of-the-art models in various graph-level learning tasks, including graph classification, anomaly detection, and out-of-distribution generalization.
Imbalanced Graph Classification with Multi-scale Oversampling Graph Neural Networks
May 08, 2024



One main challenge in imbalanced graph classification is to learn expressive representations of the graphs in under-represented (minority) classes. Existing generic imbalanced learning methods, such as oversampling and imbalanced learning loss functions, can be adopted for enabling graph representation learning models to cope with this challenge. However, these methods often directly operate on the graph representations, ignoring rich discriminative information within the graphs and their interactions. To tackle this issue, we introduce a novel multi-scale oversampling graph neural network (MOSGNN) that learns expressive minority graph representations based on intra- and inter-graph semantics resulting from oversampled graphs at multiple scales - subgraph, graph, and pairwise graphs. It achieves this by jointly optimizing subgraph-level, graph-level, and pairwise-graph learning tasks to learn the discriminative information embedded within and between the minority graphs. Extensive experiments on 16 imbalanced graph datasets show that MOSGNN i) significantly outperforms five state-of-the-art models, and ii) offers a generic framework, in which different advanced imbalanced learning loss functions can be easily plugged in and obtain significantly improved classification performance.
Deep Graph-level Anomaly Detection by Glocal Knowledge Distillation
Dec 19, 2021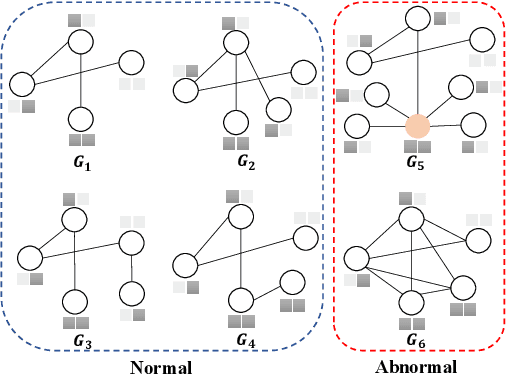
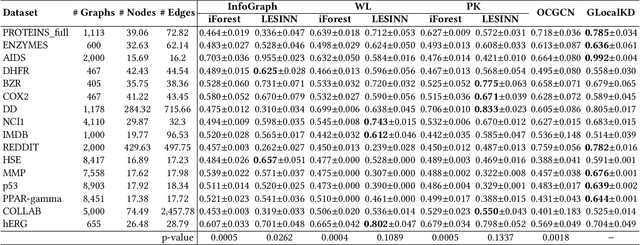
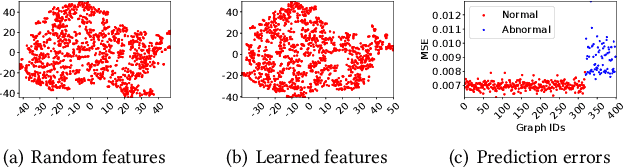
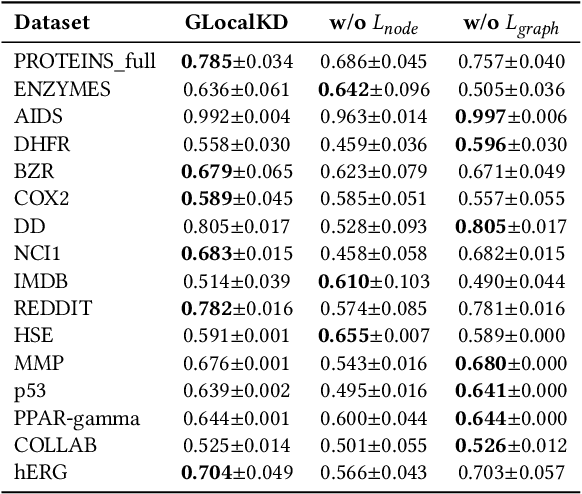
Graph-level anomaly detection (GAD) describes the problem of detecting graphs that are abnormal in their structure and/or the features of their nodes, as compared to other graphs. One of the challenges in GAD is to devise graph representations that enable the detection of both locally- and globally-anomalous graphs, i.e., graphs that are abnormal in their fine-grained (node-level) or holistic (graph-level) properties, respectively. To tackle this challenge we introduce a novel deep anomaly detection approach for GAD that learns rich global and local normal pattern information by joint random distillation of graph and node representations. The random distillation is achieved by training one GNN to predict another GNN with randomly initialized network weights. Extensive experiments on 16 real-world graph datasets from diverse domains show that our model significantly outperforms seven state-of-the-art models. Code and datasets are available at https://git.io/GLocalKD.
Transformed $\ell_1$ Regularization for Learning Sparse Deep Neural Networks
Jan 04, 2019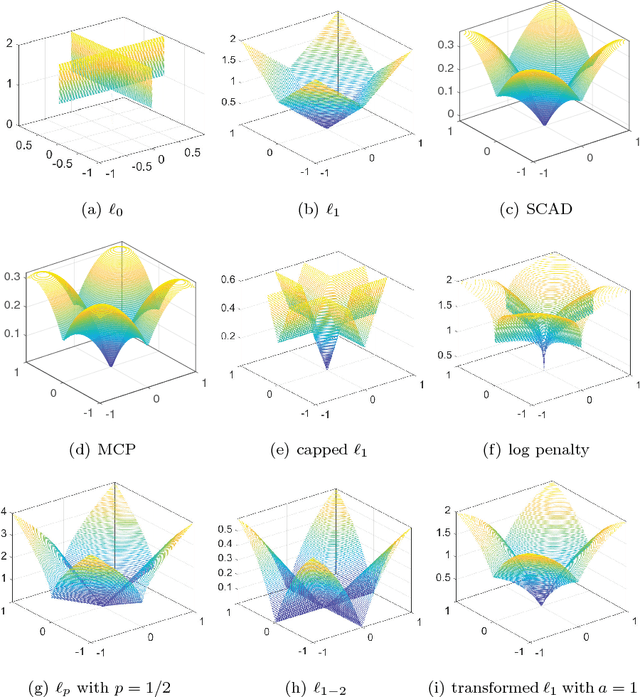
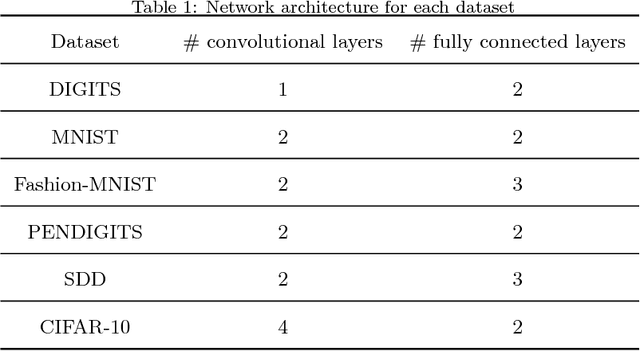
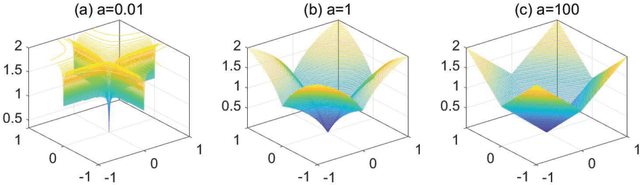
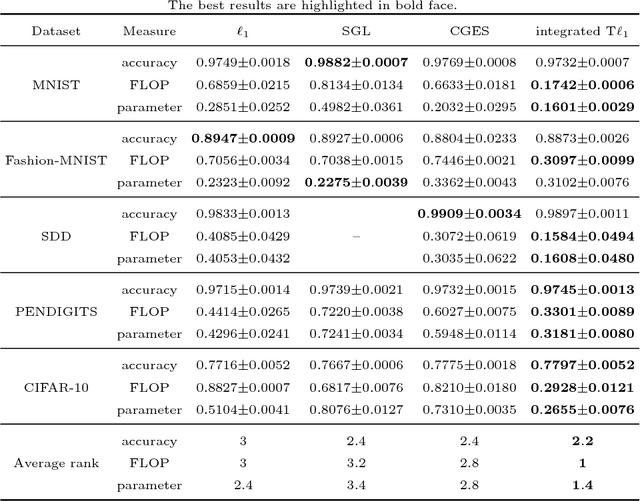
Deep neural networks (DNNs) have achieved extraordinary success in numerous areas. However, to attain this success, DNNs often carry a large number of weight parameters, leading to heavy costs of memory and computation resources. Overfitting is also likely to happen in such network when the training data are insufficient. These shortcomings severely hinder the application of DNNs in resource-constrained platforms. In fact, many network weights are known to be redundant and can be removed from the network without much loss of performance. To this end, we introduce a new non-convex integrated transformed $\ell_1$ regularizer to promote sparsity for DNNs, which removes both redundant connections and unnecessary neurons simultaneously. To be specific, we apply the transformed $\ell_1$ to the matrix space of network weights and utilize it to remove redundant connections. Besides, group sparsity is also employed as an auxiliary to remove unnecessary neurons. An efficient stochastic proximal gradient algorithm is presented to solve the new model at the same time. To the best of our knowledge, this is the first work to utilize a non-convex regularizer in sparse optimization based method to promote sparsity for DNNs. Experiments on several public datasets demonstrate the effectiveness of the proposed method.