 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Model based Fisher Vector Coding for Image Classification
Jan 08, 2017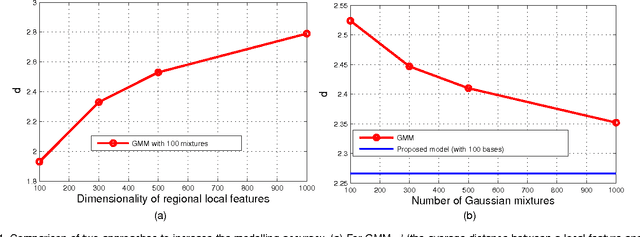
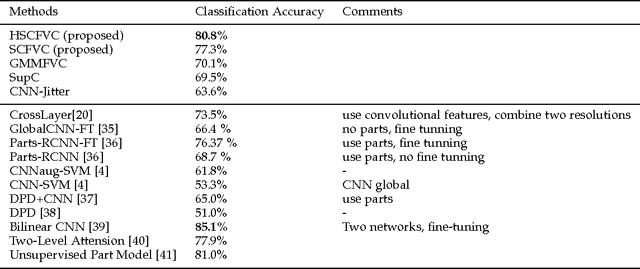
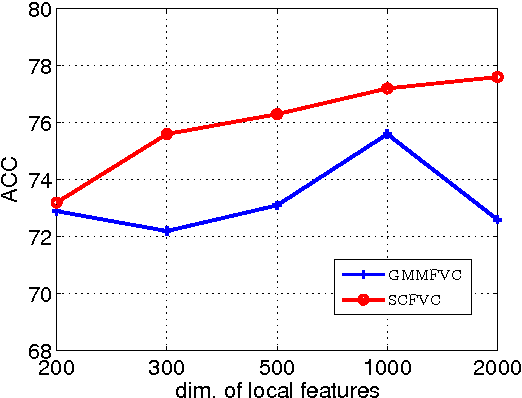

Deriving from the gradient vector of a generative model of local features, Fisher vector coding (FVC) has been identified as an effective coding method for image classification. Most, if not all, FVC implementations employ the Gaussian mixture model (GMM) to depict the generation process of local features. However, the representative power of the GMM could be limited because it essentially assumes that local features can be characterized by a fixed number of feature prototypes and the number of prototypes is usually small in FVC. To handle this limitation, in this paper we break the convention which assumes that a local feature is drawn from one of few Gaussian distributions. Instead, we adopt a compositional mechanism which assumes that a local feature is drawn from a Gaussian distribution whose mean vector is composed as the linear combination of multiple key components and the combination weight is a latent random variable. In this way, we can greatly enhance the representative power of the generative model of FVC. To implement our idea, we designed two particular generative models with such a compositional mechanism.
Cross-convolutional-layer Pooling for Image Recognition
Dec 22, 2016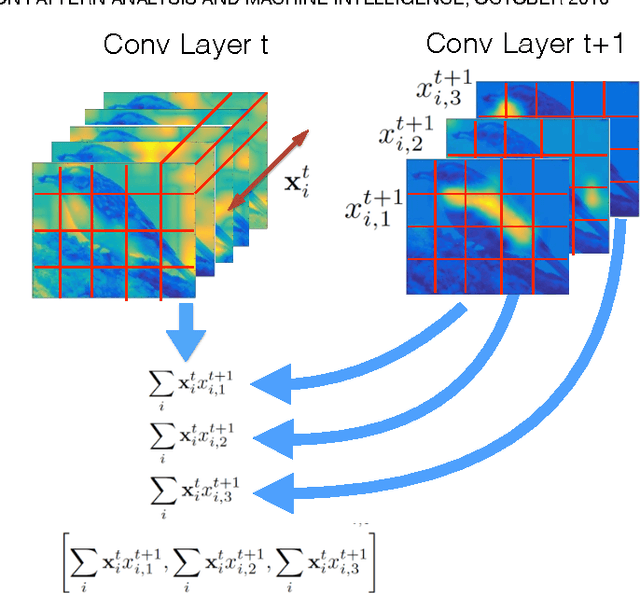
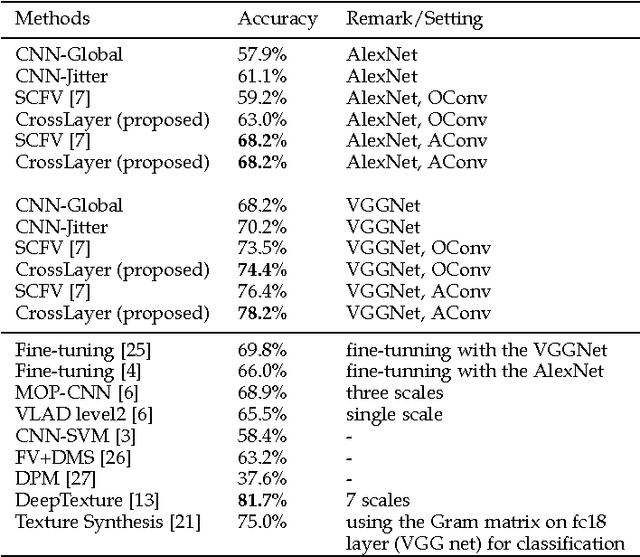

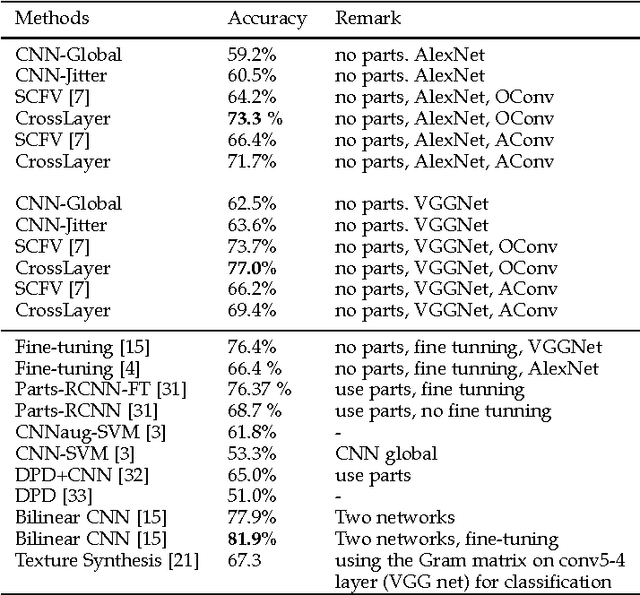
Recent studies have shown that a Deep Convolutional Neural Network (DCNN) pretrained on a large image dataset can be used as a universal image descriptor, and that doing so leads to impressive performance for a variety of image classification tasks. Most of these studies adopt activations from a single DCNN layer, usually the fully-connected layer, as the image representation. In this paper, we proposed a novel way to extract image representations from two consecutive convolutional layers: one layer is utilized for local feature extraction and the other serves as guidance to pool the extracted features. By taking different viewpoints of convolutional layers, we further develop two schemes to realize this idea. The first one directly uses convolutional layers from a DCNN. The second one applies the pretrained CNN on densely sampled image regions and treats the fully-connected activations of each image region as convolutional feature activations. We then train another convolutional layer on top of that as the pooling-guidance convolutional layer. By applying our method to three popular visual classification tasks, we find our first scheme tends to perform better on the applications which need strong discrimination on subtle object patterns within small regions while the latter excels in the cases that require discrimination on category-level patterns. Overall, the proposed method achieves superior performance over existing ways of extracting image representations from a DCNN.
Image Captioning and Visual Question Answering Based on Attributes and External Knowledge
Dec 16, 2016
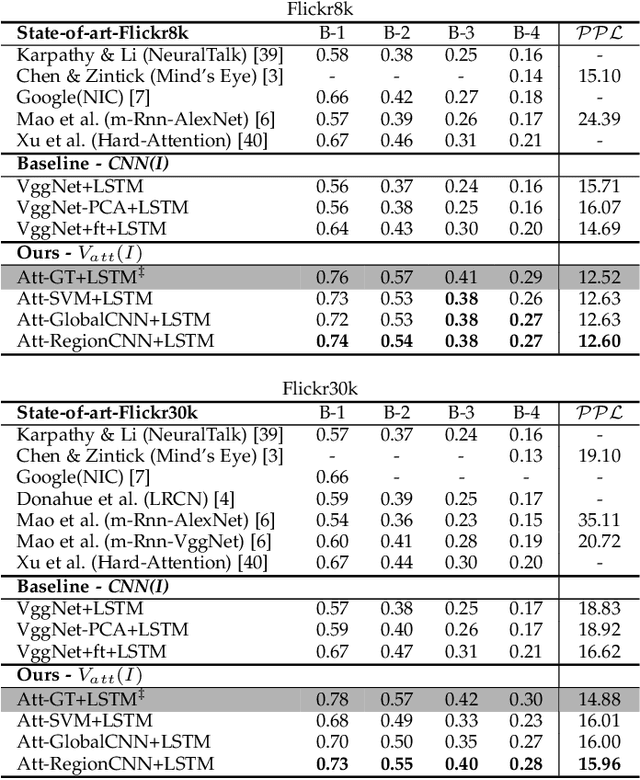
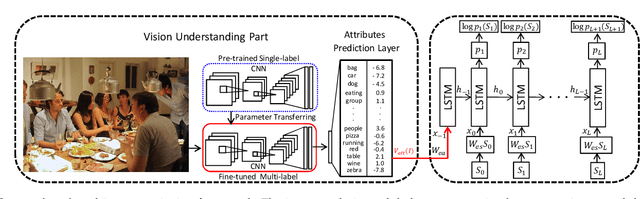
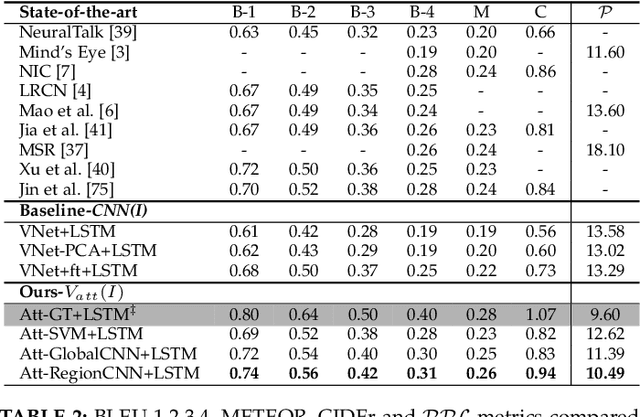
Much recent progress in Vision-to-Language problems has been achieved through a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). This approach does not explicitly represent high-level semantic concepts, but rather seeks to progress directly from image features to text. In this paper we first propose a method of incorporating high-level concepts into the successful CNN-RNN approach, and show that it achieves a significant improvement on the state-of-the-art in both image captioning and visual question answering. We further show that the same mechanism can be used to incorporate external knowledge, which is critically important for answering high level visual questions. Specifically, we design a visual question answering model that combines an internal representation of the content of an image with information extracted from a general knowledge base to answer a broad range of image-based questions. It particularly allows questions to be asked about the contents of an image, even when the image itself does not contain a complete answer. Our final model achieves the best reported results on both image captioning and visual question answering on several benchmark datasets.
The VQA-Machine: Learning How to Use Existing Vision Algorithms to Answer New Questions
Dec 16, 2016

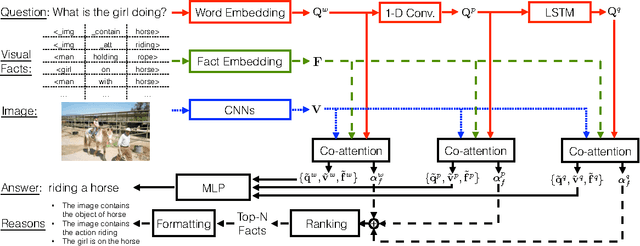
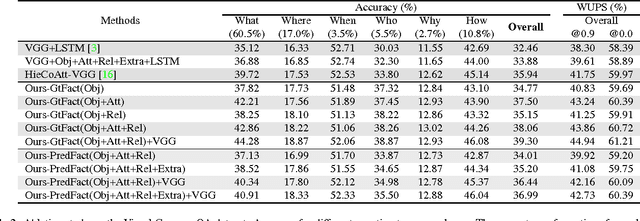
One of the most intriguing features of the Visual Question Answering (VQA) challenge is the unpredictability of the questions. Extracting the information required to answer them demands a variety of image operations from detection and counting, to segmentation and reconstruction. To train a method to perform even one of these operations accurately from {image,question,answer} tuples would be challenging, but to aim to achieve them all with a limited set of such training data seems ambitious at best. We propose here instead a more general and scalable approach which exploits the fact that very good methods to achieve these operations already exist, and thus do not need to be trained. Our method thus learns how to exploit a set of external off-the-shelf algorithms to achieve its goal, an approach that has something in common with the Neural Turing Machine. The core of our proposed method is a new co-attention model. In addition, the proposed approach generates human-readable reasons for its decision, and can still be trained end-to-end without ground truth reasons being given. We demonstrate the effectiveness on two publicly available datasets, Visual Genome and VQA, and show that it produces the state-of-the-art results in both cases.
From Motion Blur to Motion Flow: a Deep Learning Solution for Removing Heterogeneous Motion Blur
Dec 08, 2016


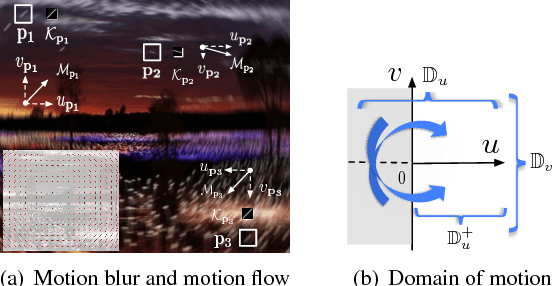
Removing pixel-wise heterogeneous motion blur is challenging due to the ill-posed nature of the problem. The predominant solution is to estimate the blur kernel by adding a prior, but the extensive literature on the subject indicates the difficulty in identifying a prior which is suitably informative, and general. Rather than imposing a prior based on theory, we propose instead to learn one from the data. Learning a prior over the latent image would require modeling all possible image content. The critical observation underpinning our approach is thus that learning the motion flow instead allows the model to focus on the cause of the blur, irrespective of the image content. This is a much easier learning task, but it also avoids the iterative process through which latent image priors are typically applied. Our approach directly estimates the motion flow from the blurred image through a fully-convolutional deep neural network (FCN) and recovers the unblurred image from the estimated motion flow. Our FCN is the first universal end-to-end mapping from the blurred image to the dense motion flow. To train the FCN, we simulate motion flows to generate synthetic blurred-image-motion-flow pairs thus avoiding the need for human labeling. Extensive experiments on challenging realistic blurred images demonstrate that the proposed method outperforms the state-of-the-art.
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
Nov 30, 2016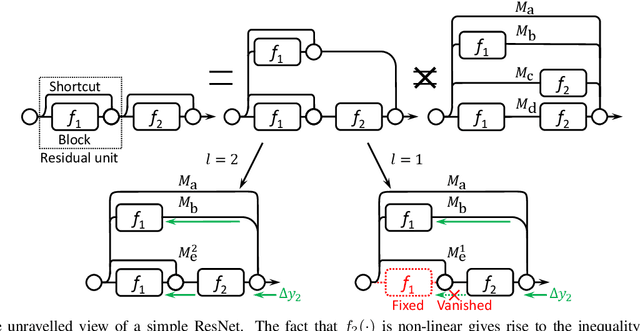
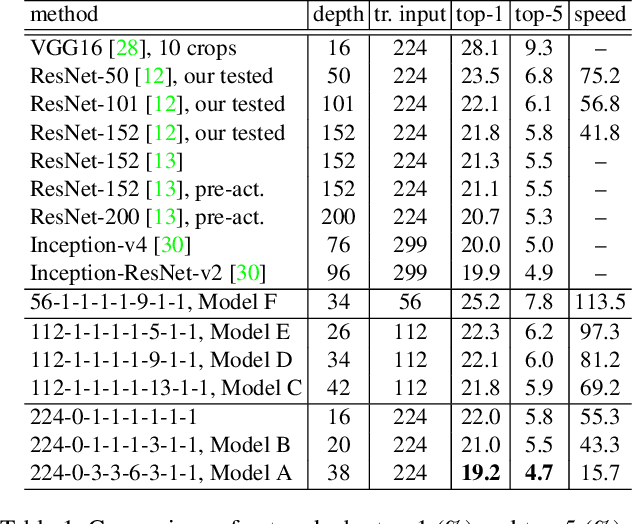
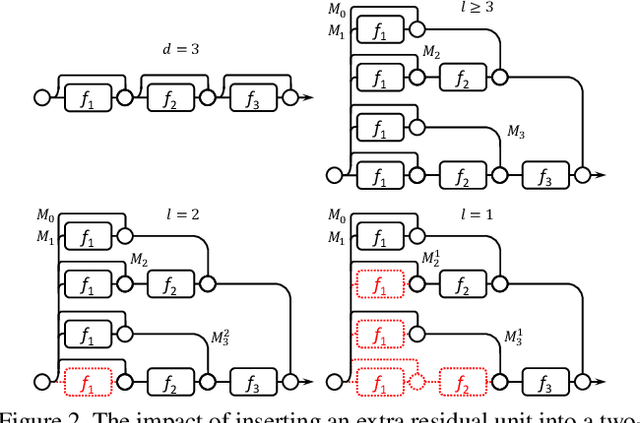
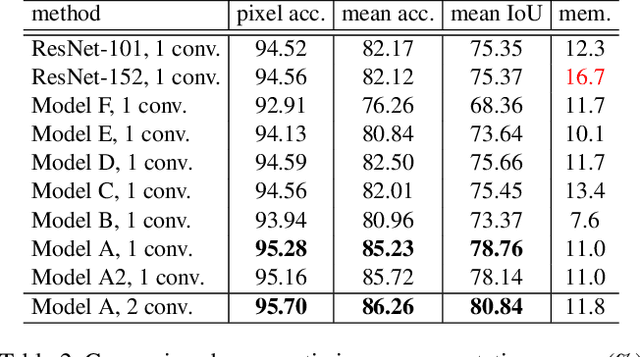
The trend towards increasingly deep neural networks has been driven by a general observation that increasing depth increases the performance of a network. Recently, however, evidence has been amassing that simply increasing depth may not be the best way to increase performance, particularly given other limitations. Investigations into deep residual networks have also suggested that they may not in fact be operating as a single deep network, but rather as an ensemble of many relatively shallow networks. We examine these issues, and in doing so arrive at a new interpretation of the unravelled view of deep residual networks which explains some of the behaviours that have been observed experimentally. As a result, we are able to derive a new, shallower, architecture of residual networks which significantly outperforms much deeper models such as ResNet-200 on the ImageNet classification dataset. We also show that this performance is transferable to other problem domains by developing a semantic segmentation approach which outperforms the state-of-the-art by a remarkable margin on datasets including PASCAL VOC, PASCAL Context, and Cityscapes. The architecture that we propose thus outperforms its comparators, including very deep ResNets, and yet is more efficient in memory use and sometimes also in training time. The code and models are available at https://github.com/itijyou/ademxapp
Sequential Person Recognition in Photo Albums with a Recurrent Network
Nov 30, 2016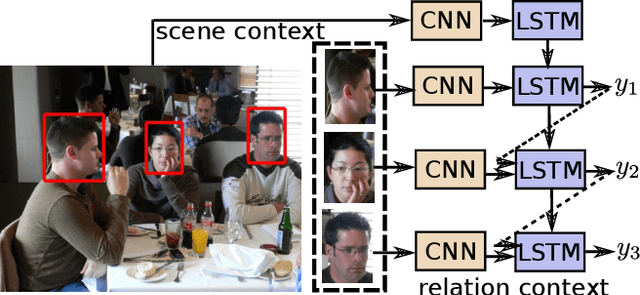
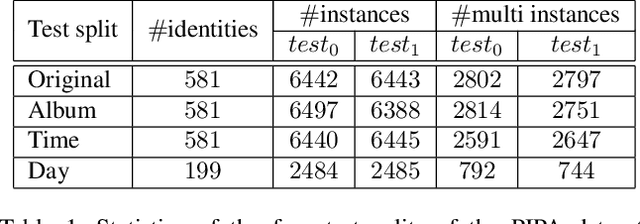

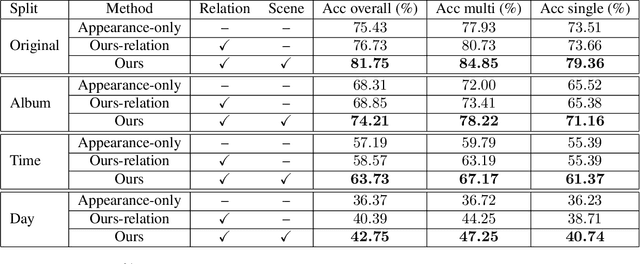
Recognizing the identities of people in everyday photos is still a very challenging problem for machine vision, due to non-frontal faces, changes in clothing, location, lighting and similar. Recent studies have shown that rich relational information between people in the same photo can help in recognizing their identities. In this work, we propose to model the relational information between people as a sequence prediction task. At the core of our work is a novel recurrent network architecture, in which relational information between instances' labels and appearance are modeled jointly. In addition to relational cues, scene context is incorporated in our sequence prediction model with no additional cost. In this sense, our approach is a unified framework for modeling both contextual cues and visual appearance of person instances. Our model is trained end-to-end with a sequence of annotated instances in a photo as inputs, and a sequence of corresponding labels as targets. We demonstrate that this simple but elegant formulation achieves state-of-the-art performance on the newly released People In Photo Albums (PIPA) dataset.
Infinite Variational Autoencoder for Semi-Supervised Learning
Nov 24, 2016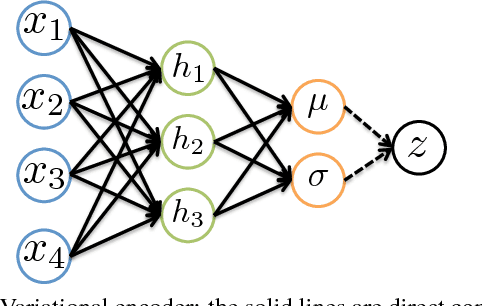
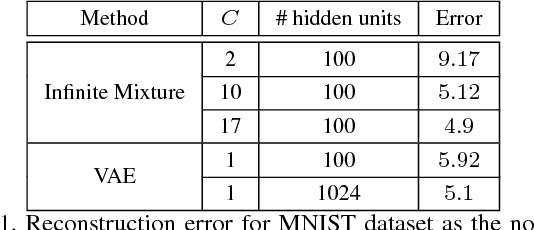
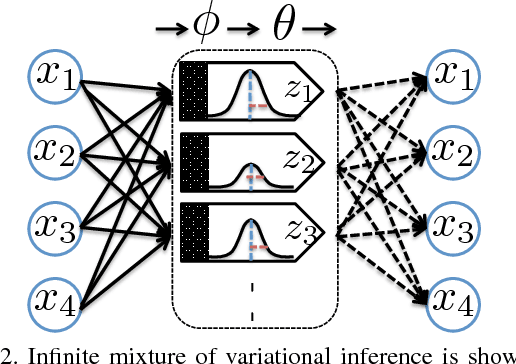
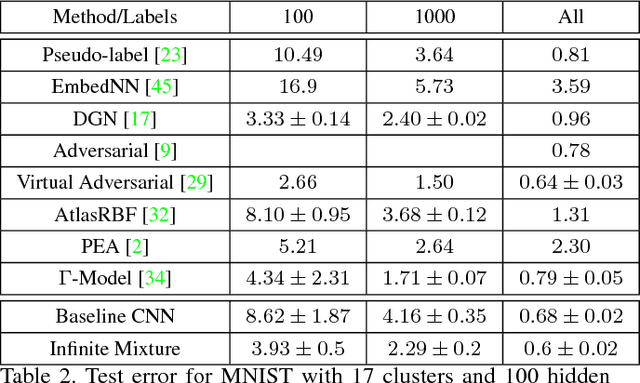
This paper presents an infinite variational autoencoder (VAE) whose capacity adapts to suit the input data. This is achieved using a mixture model where the mixing coefficients are modeled by a Dirichlet process, allowing us to integrate over the coefficients when performing inference. Critically, this then allows us to automatically vary the number of autoencoders in the mixture based on the data. Experiments show the flexibility of our method, particularly for semi-supervised learning, where only a small number of training samples are available.
Zero-Shot Visual Question Answering
Nov 20, 2016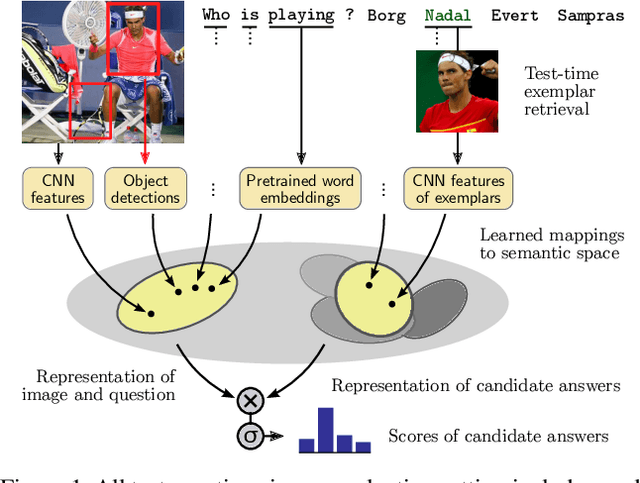
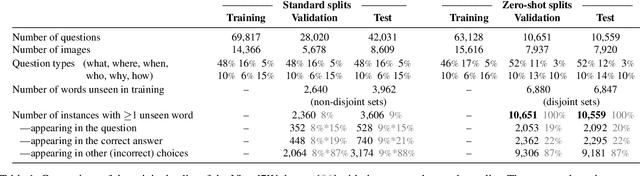
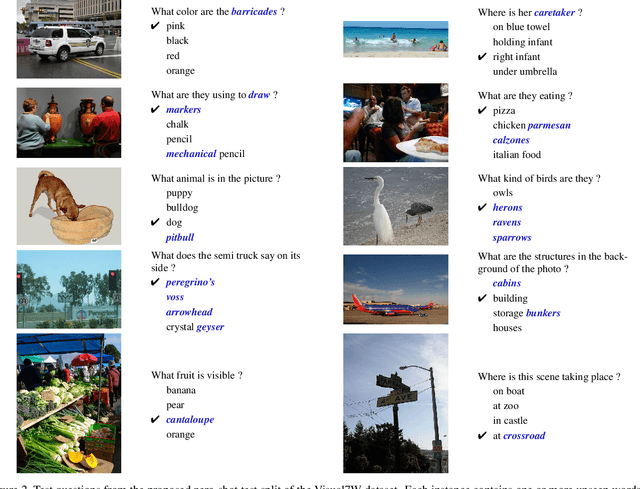
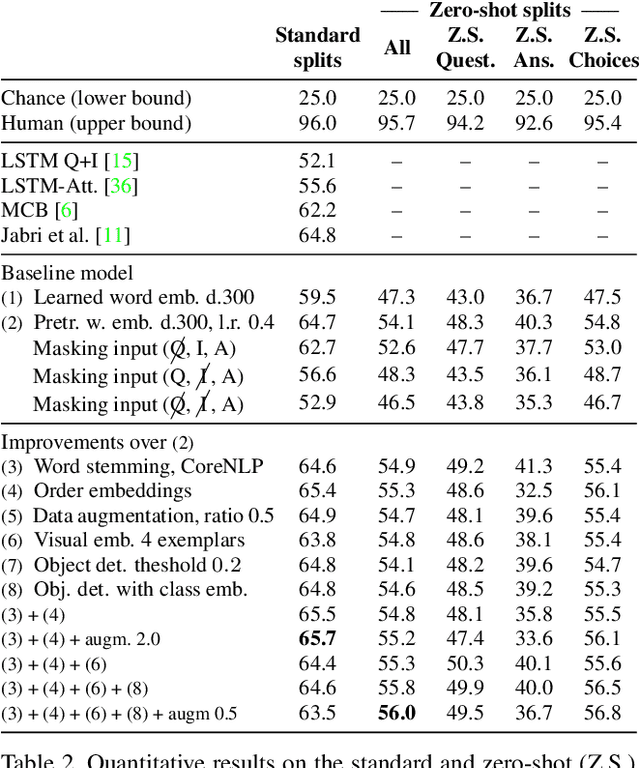
Part of the appeal of Visual Question Answering (VQA) is its promise to answer new questions about previously unseen images. Most current methods demand training questions that illustrate every possible concept, and will therefore never achieve this capability, since the volume of required training data would be prohibitive. Answering general questions about images requires methods capable of Zero-Shot VQA, that is, methods able to answer questions beyond the scope of the training questions. We propose a new evaluation protocol for VQA methods which measures their ability to perform Zero-Shot VQA, and in doing so highlights significant practical deficiencies of current approaches, some of which are masked by the biases in current datasets. We propose and evaluate several strategies for achieving Zero-Shot VQA, including methods based on pretrained word embeddings, object classifiers with semantic embeddings, and test-time retrieval of example images. Our extensive experiments are intended to serve as baselines for Zero-Shot VQA, and they also achieve state-of-the-art performance in the standard VQA evaluation setting.
Image Co-localization by Mimicking a Good Detector's Confidence Score Distribution
Jul 23, 2016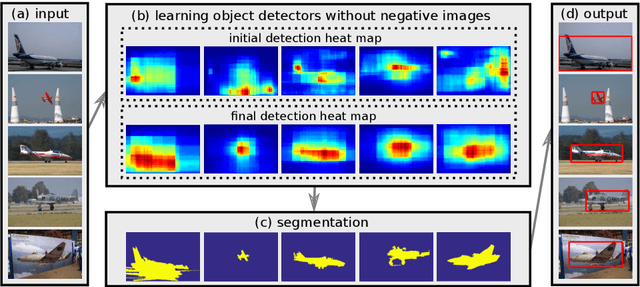

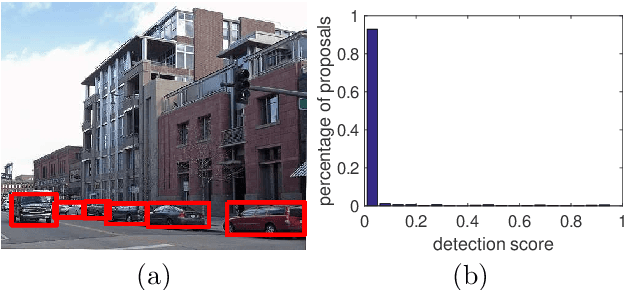
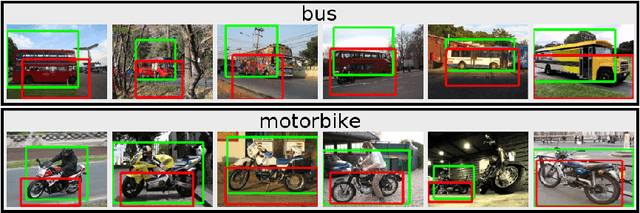
Given a set of images containing objects from the same category, the task of image co-localization is to identify and localize each instance. This paper shows that this problem can be solved by a simple but intriguing idea, that is, a common object detector can be learnt by making its detection confidence scores distributed like those of a strongly supervised detector. More specifically, we observe that given a set of object proposals extracted from an image that contains the object of interest, an accurate strongly supervised object detector should give high scores to only a small minority of proposals, and low scores to most of them. Thus, we devise an entropy-based objective function to enforce the above property when learning the common object detector. Once the detector is learnt, we resort to a segmentation approach to refine the localization. We show that despite its simplicity, our approach outperforms state-of-the-art methods.