 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Attention: A Unified Framework for Visual Object Discovery through Dialogs and Queries
Nov 17, 2017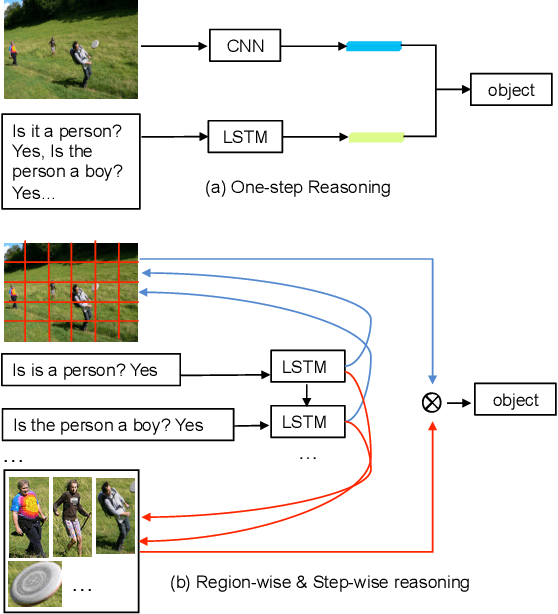
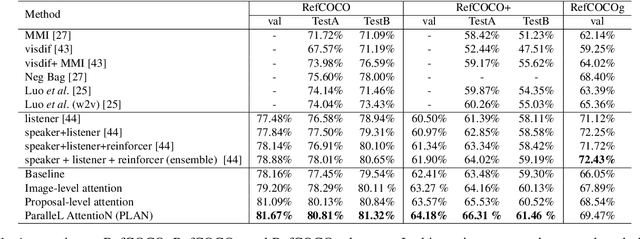
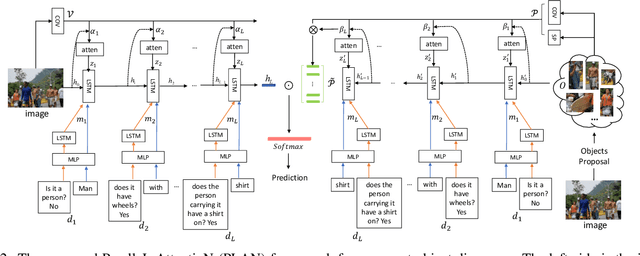
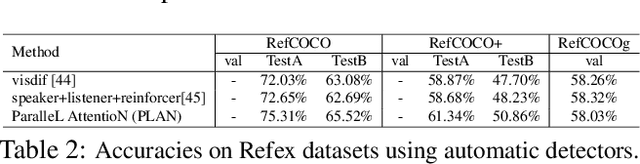
Recognising objects according to a pre-defined fixed set of class labels has been well studied in the Computer Vision. There are a great many practical applications where the subjects that may be of interest are not known beforehand, or so easily delineated, however. In many of these cases natural language dialog is a natural way to specify the subject of interest, and the task achieving this capability (a.k.a, Referring Expression Comprehension) has recently attracted attention. To this end we propose a unified framework, the ParalleL AttentioN (PLAN) network, to discover the object in an image that is being referred to in variable length natural expression descriptions, from short phrases query to long multi-round dialogs. The PLAN network has two attention mechanisms that relate parts of the expressions to both the global visual content and also directly to object candidates. Furthermore, the attention mechanisms are recurrent, making the referring process visualizable and explainable. The attended information from these dual sources are combined to reason about the referred object. These two attention mechanisms can be trained in parallel and we find the combined system outperforms the state-of-art on several benchmarked datasets with different length language input, such as RefCOCO, RefCOCO+ and GuessWhat?!.
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
Aug 09, 2017
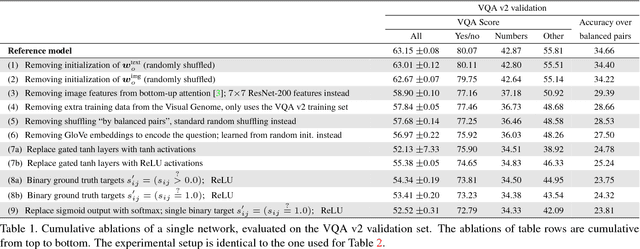

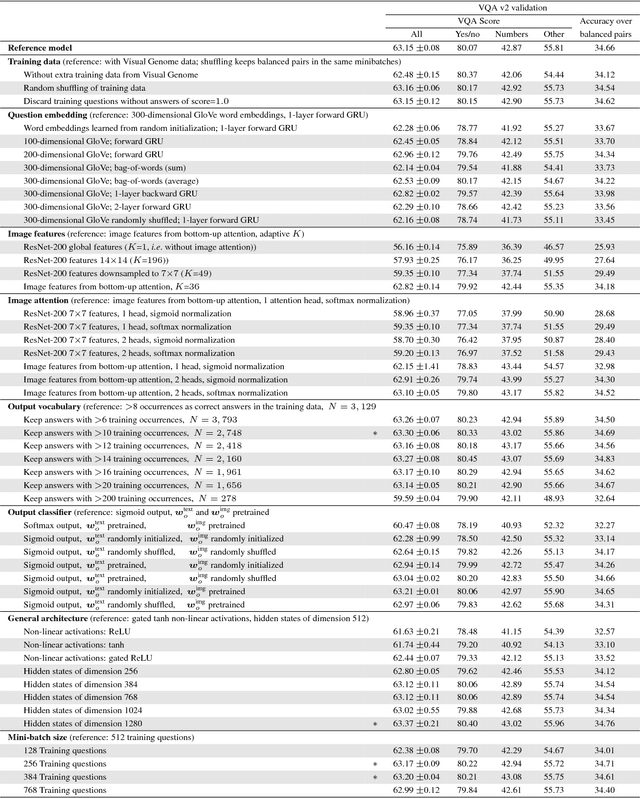
This paper presents a state-of-the-art model for visual question answering (VQA), which won the first place in the 2017 VQA Challenge. VQA is a task of significant importance for research in artificial intelligence, given its multimodal nature, clear evaluation protocol, and potential real-world applications. The performance of deep neural networks for VQA is very dependent on choices of architectures and hyperparameters. To help further research in the area, we describe in detail our high-performing, though relatively simple model. Through a massive exploration of architectures and hyperparameters representing more than 3,000 GPU-hours, we identified tips and tricks that lead to its success, namely: sigmoid outputs, soft training targets, image features from bottom-up attention, gated tanh activations, output embeddings initialized using GloVe and Google Images, large mini-batches, and smart shuffling of training data. We provide a detailed analysis of their impact on performance to assist others in making an appropriate selection.
FVQA: Fact-based Visual Question Answering
Aug 08, 2017
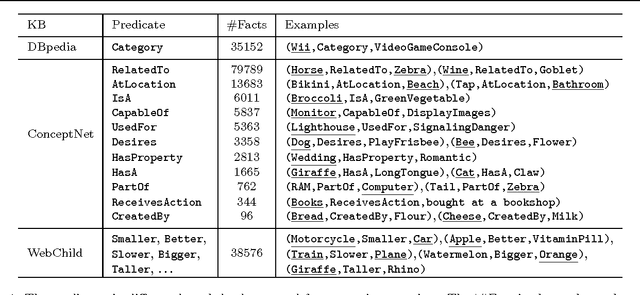
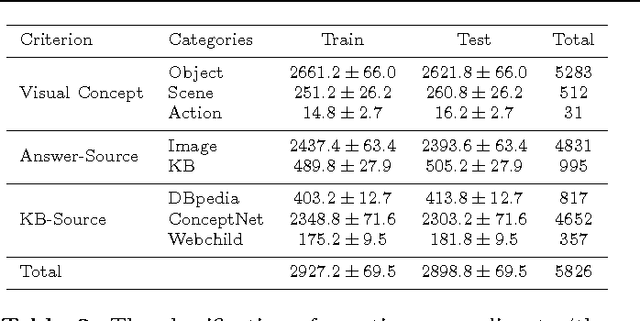
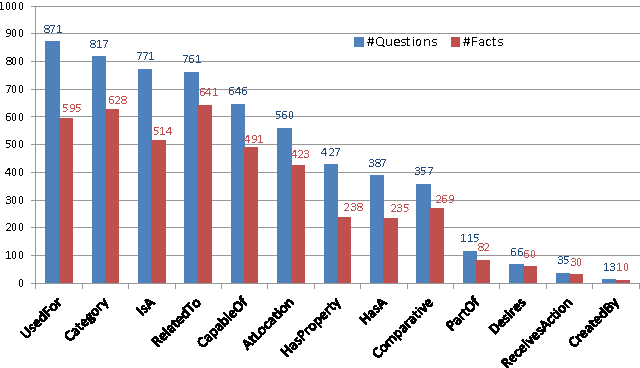
Visual Question Answering (VQA) has attracted a lot of attention in both Computer Vision and Natural Language Processing communities, not least because it offers insight into the relationships between two important sources of information. Current datasets, and the models built upon them, have focused on questions which are answerable by direct analysis of the question and image alone. The set of such questions that require no external information to answer is interesting, but very limited. It excludes questions which require common sense, or basic factual knowledge to answer, for example. Here we introduce FVQA, a VQA dataset which requires, and supports, much deeper reasoning. FVQA only contains questions which require external information to answer. We thus extend a conventional visual question answering dataset, which contains image-question-answerg triplets, through additional image-question-answer-supporting fact tuples. The supporting fact is represented as a structural triplet, such as <Cat,CapableOf,ClimbingTrees>. We evaluate several baseline models on the FVQA dataset, and describe a novel model which is capable of reasoning about an image on the basis of supporting facts.
Beyond Low Rank: A Data-Adaptive Tensor Completion Method
Aug 03, 2017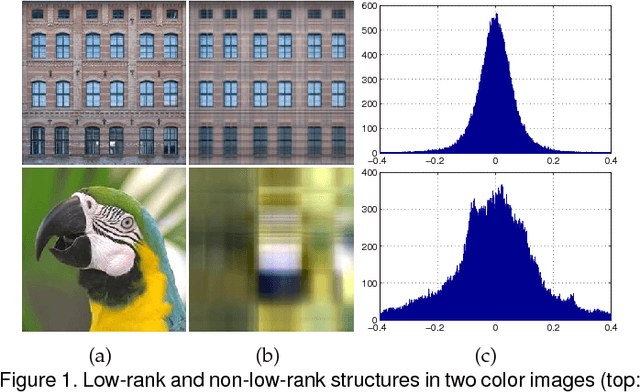
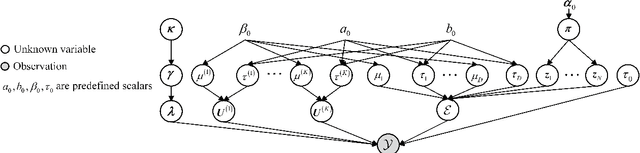
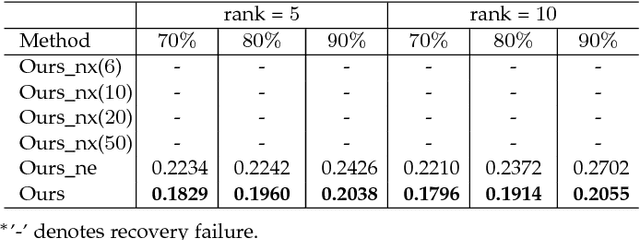
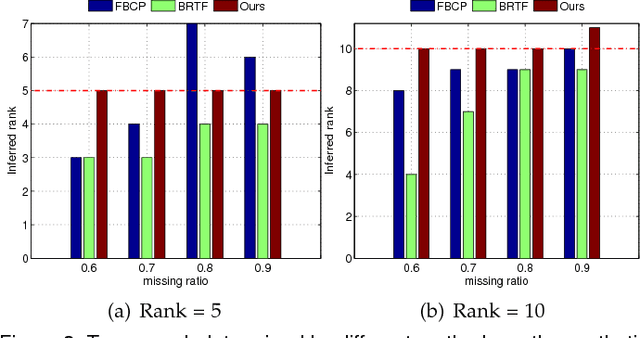
Low rank tensor representation underpins much of recent progress in tensor completion. In real applications, however, this approach is confronted with two challenging problems, namely (1) tensor rank determination; (2) handling real tensor data which only approximately fulfils the low-rank requirement. To address these two issues, we develop a data-adaptive tensor completion model which explicitly represents both the low-rank and non-low-rank structures in a latent tensor. Representing the non-low-rank structure separately from the low-rank one allows priors which capture the important distinctions between the two, thus enabling more accurate modelling, and ultimately, completion. Through defining a new tensor rank, we develop a sparsity induced prior for the low-rank structure, with which the tensor rank can be automatically determined. The prior for the non-low-rank structure is established based on a mixture of Gaussians which is shown to be flexible enough, and powerful enough, to inform the completion process for a variety of real tensor data. With these two priors, we develop a Bayesian minimum mean squared error estimate (MMSE) framework for inference which provides the posterior mean of missing entries as well as their uncertainty. Compared with the state-of-the-art methods in various applications, the proposed model produces more accurate completion results.
When Unsupervised Domain Adaptation Meets Tensor Representations
Jul 19, 2017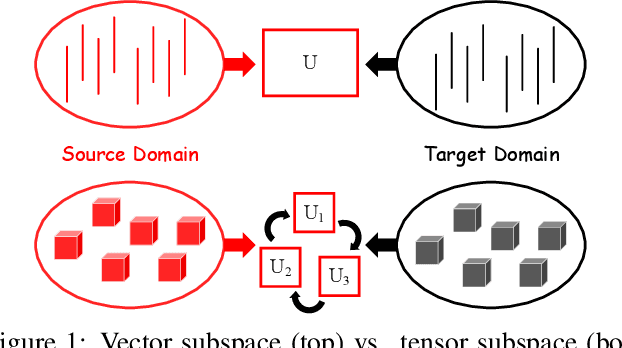
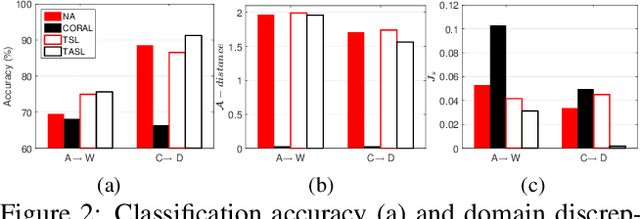
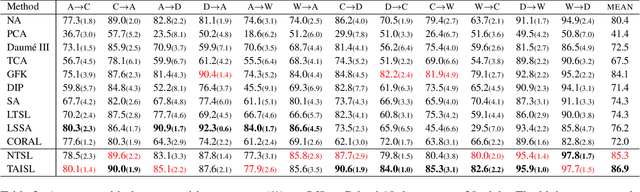
Domain adaption (DA) allows machine learning methods trained on data sampled from one distribution to be applied to data sampled from another. It is thus of great practical importance to the application of such methods. Despite the fact that tensor representations are widely used in Computer Vision to capture multi-linear relationships that affect the data, most existing DA methods are applicable to vectors only. This renders them incapable of reflecting and preserving important structure in many problems. We thus propose here a learning-based method to adapt the source and target tensor representations directly, without vectorization. In particular, a set of alignment matrices is introduced to align the tensor representations from both domains into the invariant tensor subspace. These alignment matrices and the tensor subspace are modeled as a joint optimization problem and can be learned adaptively from the data using the proposed alternative minimization scheme. Extensive experiments show that our approach is capable of preserving the discriminative power of the source domain, of resisting the effects of label noise, and works effectively for small sample sizes, and even one-shot DA. We show that our method outperforms the state-of-the-art on the task of cross-domain visual recognition in both efficacy and efficiency, and particularly that it outperforms all comparators when applied to DA of the convolutional activations of deep convolutional networks.
Visually Aligned Word Embeddings for Improving Zero-shot Learning
Jul 18, 2017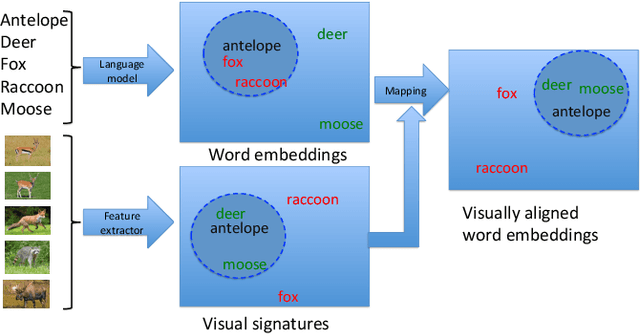
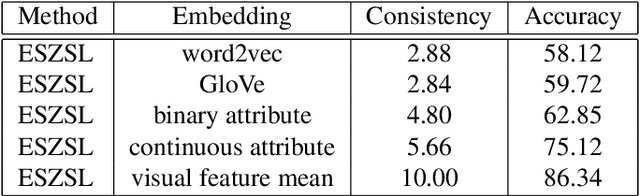
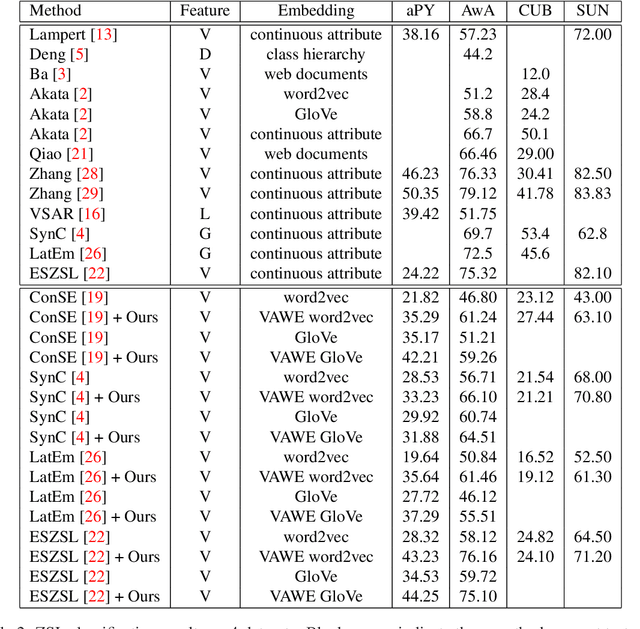
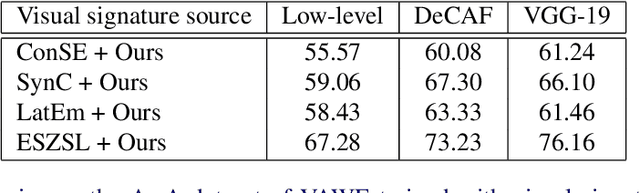
Zero-shot learning (ZSL) highly depends on a good semantic embedding to connect the seen and unseen classes. Recently, distributed word embeddings (DWE) pre-trained from large text corpus have become a popular choice to draw such a connection. Compared with human defined attributes, DWEs are more scalable and easier to obtain. However, they are designed to reflect semantic similarity rather than visual similarity and thus using them in ZSL often leads to inferior performance. To overcome this visual-semantic discrepancy, this work proposes an objective function to re-align the distributed word embeddings with visual information by learning a neural network to map it into a new representation called visually aligned word embedding (VAWE). Thus the neighbourhood structure of VAWEs becomes similar to that in the visual domain. Note that in this work we do not design a ZSL method that projects the visual features and semantic embeddings onto a shared space but just impose a requirement on the structure of the mapped word embeddings. This strategy allows the learned VAWE to generalize to various ZSL methods and visual features. As evaluated via four state-of-the-art ZSL methods on four benchmark datasets, the VAWE exhibit consistent performance improvement.
Bayesian Conditional Generative Adverserial Networks
Jun 17, 2017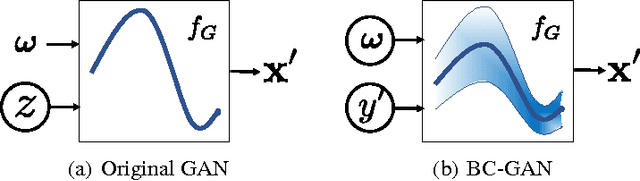
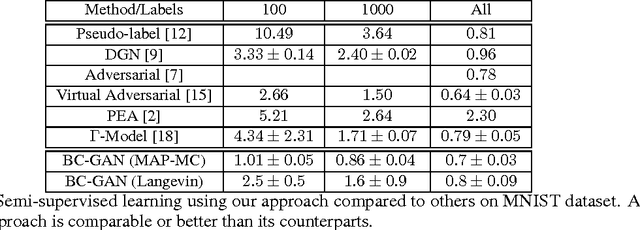
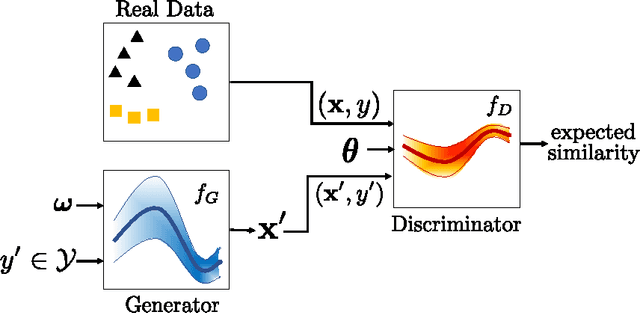
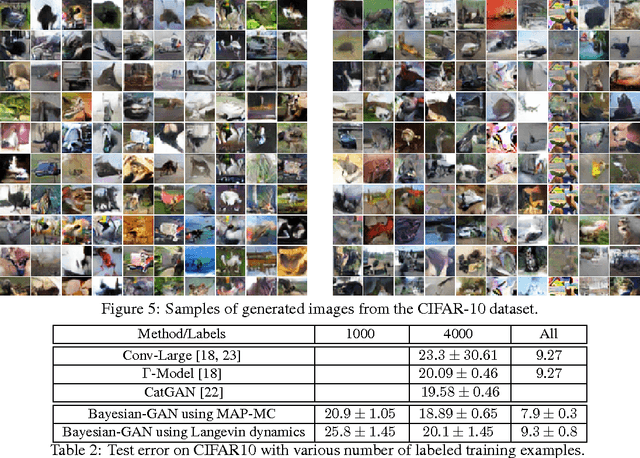
Traditional GANs use a deterministic generator function (typically a neural network) to transform a random noise input $z$ to a sample $\mathbf{x}$ that the discriminator seeks to distinguish. We propose a new GAN called Bayesian Conditional Generative Adversarial Networks (BC-GANs) that use a random generator function to transform a deterministic input $y'$ to a sample $\mathbf{x}$. Our BC-GANs extend traditional GANs to a Bayesian framework, and naturally handle unsupervised learning, supervised learning, and semi-supervised learning problems. Experiments show that the proposed BC-GANs outperforms the state-of-the-arts.
Care about you: towards large-scale human-centric visual relationship detection
May 28, 2017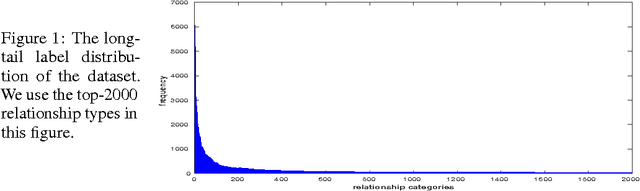
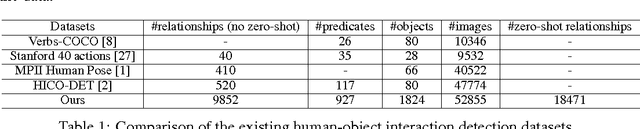
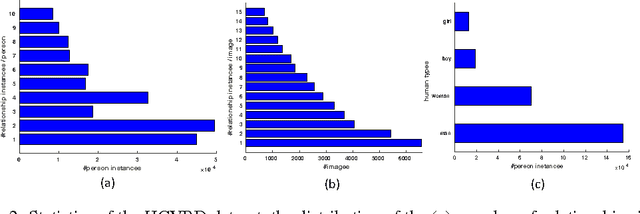

Visual relationship detection aims to capture interactions between pairs of objects in images. Relationships between objects and humans represent a particularly important subset of this problem, with implications for challenges such as understanding human behaviour, and identifying affordances, amongst others. In addressing this problem we first construct a large-scale human-centric visual relationship detection dataset (HCVRD), which provides many more types of relationship annotation (nearly 10K categories) than the previous released datasets. This large label space better reflects the reality of human-object interactions, but gives rise to a long-tail distribution problem, which in turn demands a zero-shot approach to labels appearing only in the test set. This is the first time this issue has been addressed. We propose a webly-supervised approach to these problems and demonstrate that the proposed model provides a strong baseline on our HCVRD dataset.
Exploring Context with Deep Structured models for Semantic Segmentation
May 02, 2017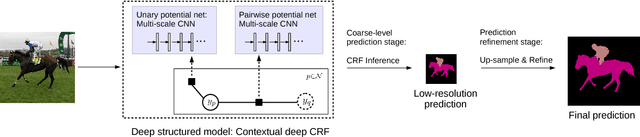
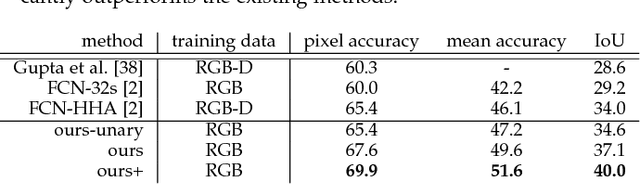

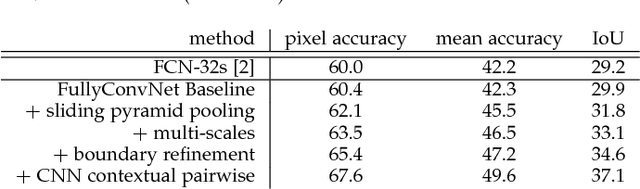
State-of-the-art semantic image segmentation methods are mostly based on training deep convolutional neural networks (CNNs). In this work, we proffer to improve semantic segmentation with the use of contextual information. In particular, we explore `patch-patch' context and `patch-background' context in deep CNNs. We formulate deep structured models by combining CNNs and Conditional Random Fields (CRFs) for learning the patch-patch context between image regions. Specifically, we formulate CNN-based pairwise potential functions to capture semantic correlations between neighboring patches. Efficient piecewise training of the proposed deep structured model is then applied in order to avoid repeated expensive CRF inference during the course of back propagation. For capturing the patch-background context, we show that a network design with traditional multi-scale image inputs and sliding pyramid pooling is very effective for improving performance. We perform comprehensive evaluation of the proposed method. We achieve new state-of-the-art performance on a number of challenging semantic segmentation datasets including $NYUDv2$, $PASCAL$-$VOC2012$, $Cityscapes$, $PASCAL$-$Context$, $SUN$-$RGBD$, $SIFT$-$flow$, and $KITTI$ datasets. Particularly, we report an intersection-over-union score of $77.8$ on the $PASCAL$-$VOC2012$ dataset.
Graph-Structured Representations for Visual Question Answering
Mar 30, 2017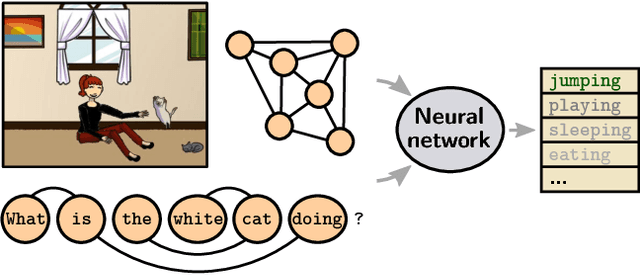
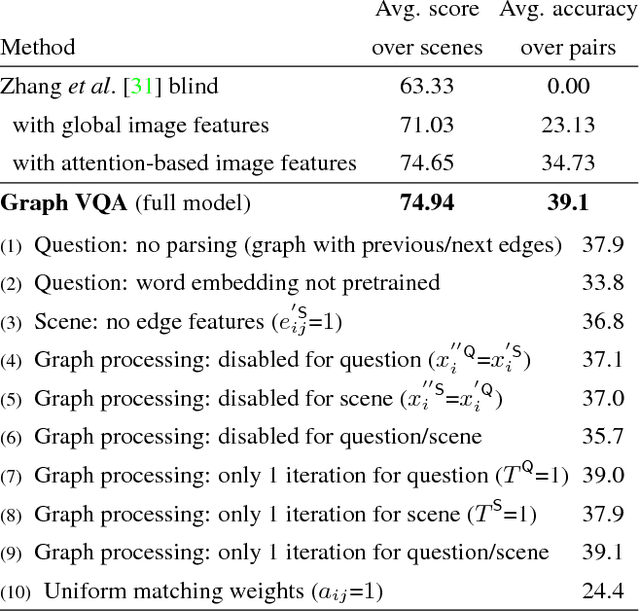
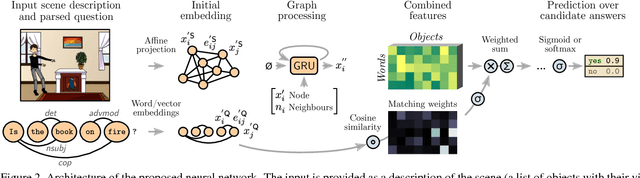
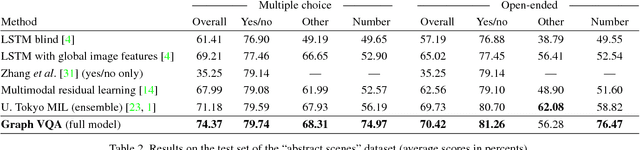
This paper proposes to improve visual question answering (VQA) with structured representations of both scene contents and questions. A key challenge in VQA is to require joint reasoning over the visual and text domains. The predominant CNN/LSTM-based approach to VQA is limited by monolithic vector representations that largely ignore structure in the scene and in the form of the question. CNN feature vectors cannot effectively capture situations as simple as multiple object instances, and LSTMs process questions as series of words, which does not reflect the true complexity of language structure. We instead propose to build graphs over the scene objects and over the question words, and we describe a deep neural network that exploits the structure in these representations. This shows significant benefit over the sequential processing of LSTMs. The overall efficacy of our approach is demonstrated by significant improvements over the state-of-the-art, from 71.2% to 74.4% in accuracy on the "abstract scenes" multiple-choice benchmark, and from 34.7% to 39.1% in accuracy over pairs of "balanced" scenes, i.e. images with fine-grained differences and opposite yes/no answers to a same question.