 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-Aimbots: Using Machine Learning for Cheating in First Person Shooters
May 14, 2022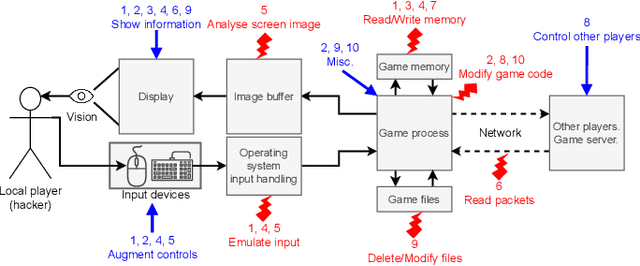
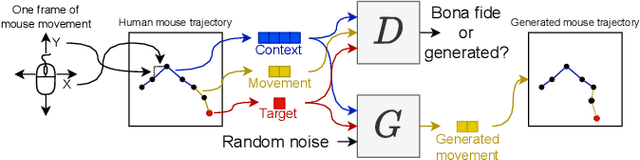
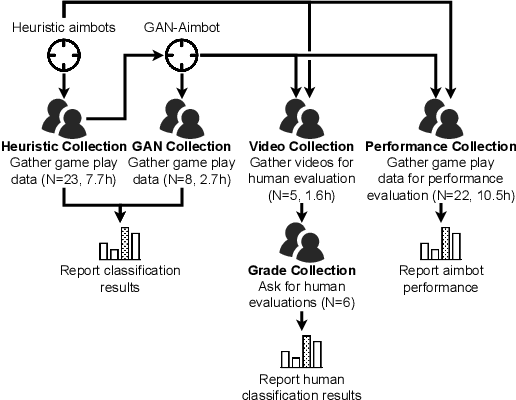
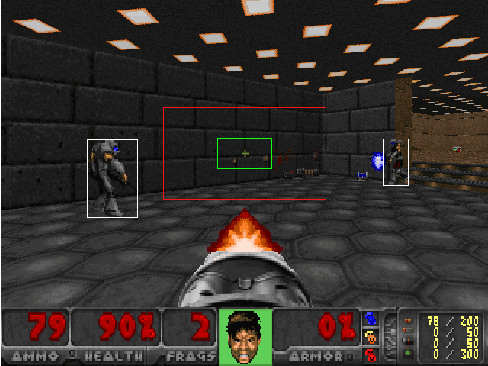
Playing games with cheaters is not fun, and in a multi-billion-dollar video game industry with hundreds of millions of players, game developers aim to improve the security and, consequently, the user experience of their games by preventing cheating. Both traditional software-based methods and statistical systems have been successful in protecting against cheating, but recent advances in the automatic generation of content, such as images or speech, threaten the video game industry; they could be used to generate artificial gameplay indistinguishable from that of legitimate human players. To better understand this threat, we begin by reviewing the current state of multiplayer video game cheating, and then proceed to build a proof-of-concept method, GAN-Aimbot. By gathering data from various players in a first-person shooter game we show that the method improves players' performance while remaining hidden from automatic and manual protection mechanisms. By sharing this work we hope to raise awareness on this issue and encourage further research into protecting the gaming communities.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022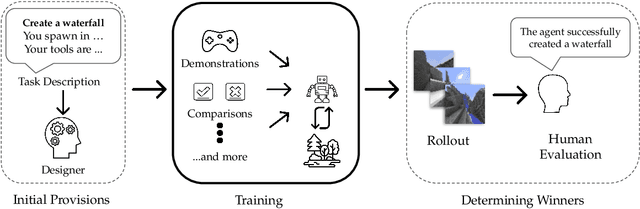
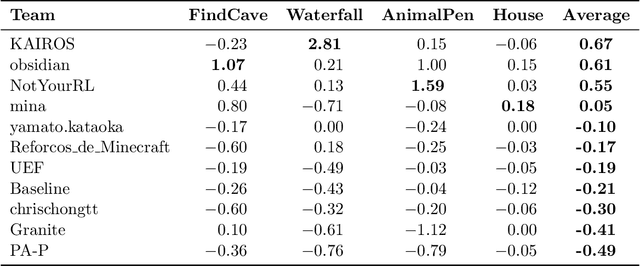
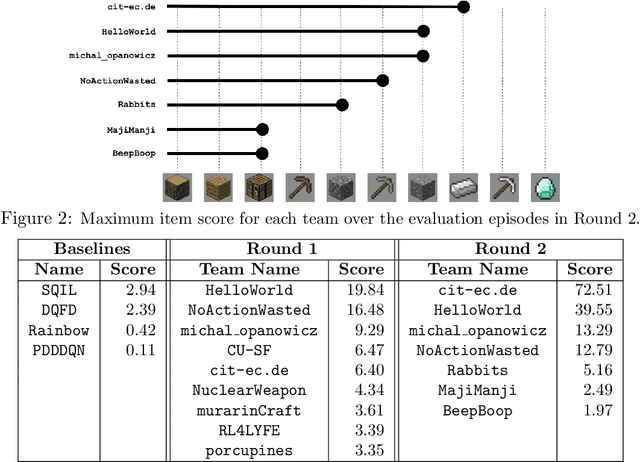
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022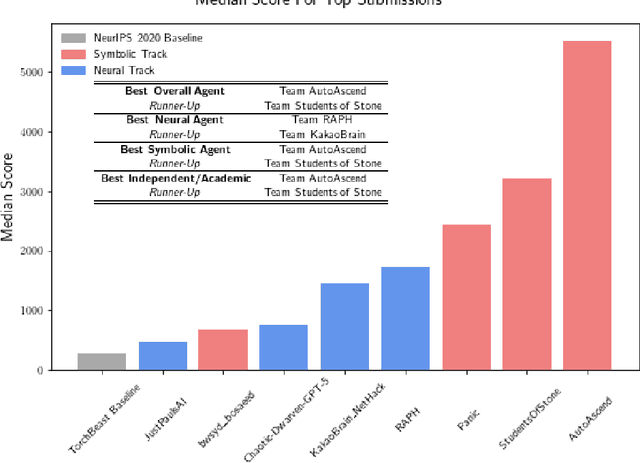

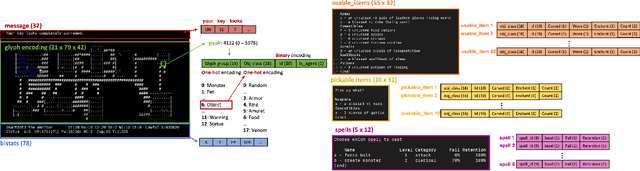
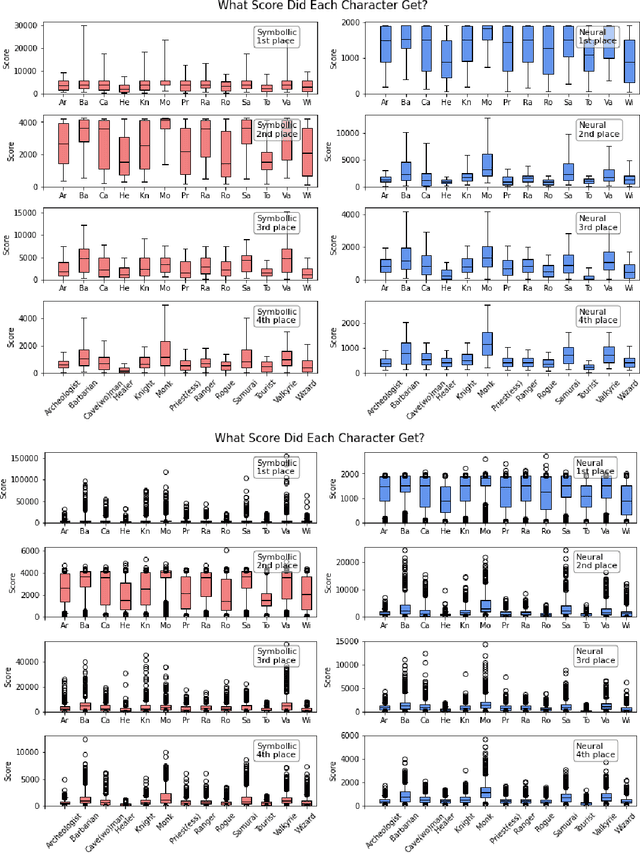
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022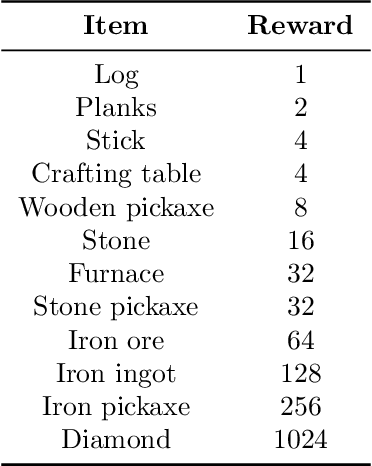
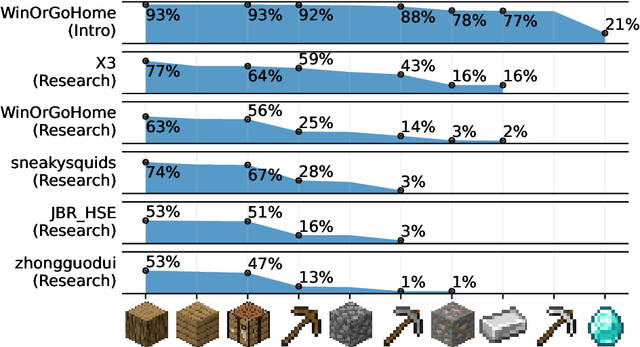
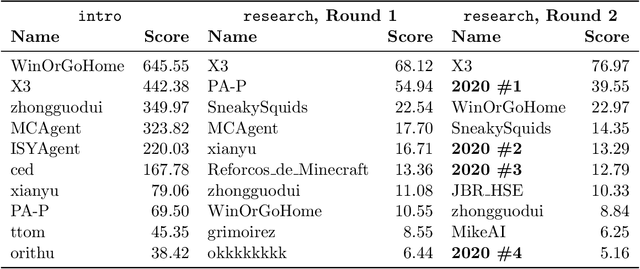
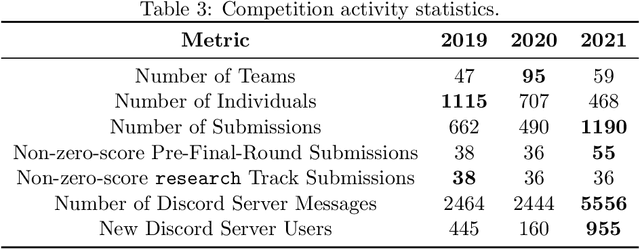
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Optimizing Tandem Speaker Verification and Anti-Spoofing Systems
Jan 24, 2022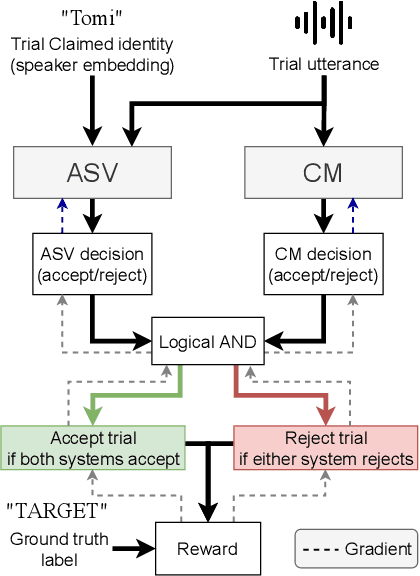
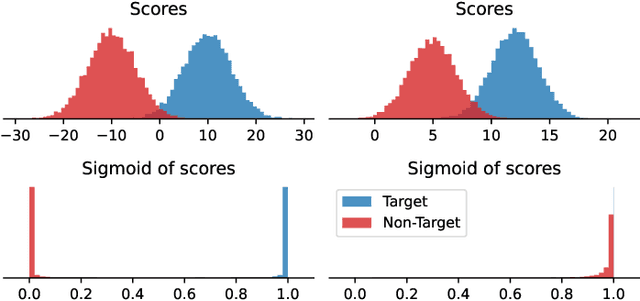
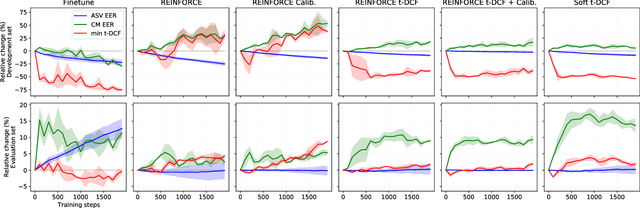

As automatic speaker verification (ASV) systems are vulnerable to spoofing attacks, they are typically used in conjunction with spoofing countermeasure (CM) systems to improve security. For example, the CM can first determine whether the input is human speech, then the ASV can determine whether this speech matches the speaker's identity. The performance of such a tandem system can be measured with a tandem detection cost function (t-DCF). However, ASV and CM systems are usually trained separately, using different metrics and data, which does not optimize their combined performance. In this work, we propose to optimize the tandem system directly by creating a differentiable version of t-DCF and employing techniques from reinforcement learning. The results indicate that these approaches offer better outcomes than finetuning, with our method providing a 20% relative improvement in the t-DCF in the ASVSpoof19 dataset in a constrained setting.
* Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing. Published version available at: https://ieeexplore.ieee.org/document/9664367
Agents that Listen: High-Throughput Reinforcement Learning with Multiple Sensory Systems
Jul 05, 2021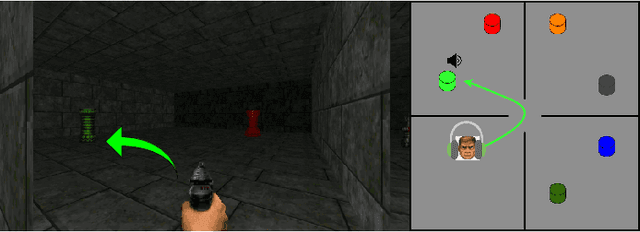
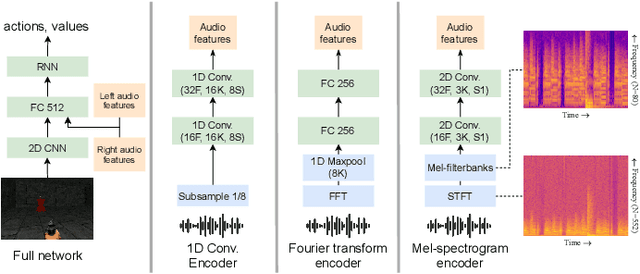

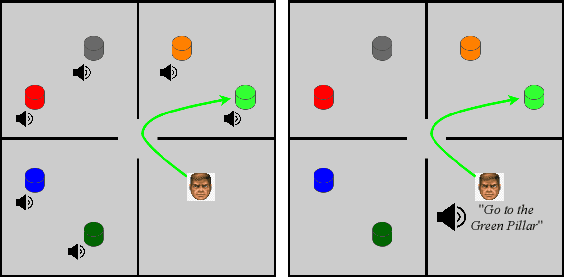
Humans and other intelligent animals evolved highly sophisticated perception systems that combine multiple sensory modalities. On the other hand, state-of-the-art artificial agents rely mostly on visual inputs or structured low-dimensional observations provided by instrumented environments. Learning to act based on combined visual and auditory inputs is still a new topic of research that has not been explored beyond simple scenarios. To facilitate progress in this area we introduce a new version of VizDoom simulator to create a highly efficient learning environment that provides raw audio observations. We study the performance of different model architectures in a series of tasks that require the agent to recognize sounds and execute instructions given in natural language. Finally, we train our agent to play the full game of Doom and find that it can consistently defeat a traditional vision-based adversary. We are currently in the process of merging the augmented simulator with the main ViZDoom code repository. Video demonstrations and experiment code can be found at https://sites.google.com/view/sound-rl.
The MineRL BASALT Competition on Learning from Human Feedback
Jul 05, 2021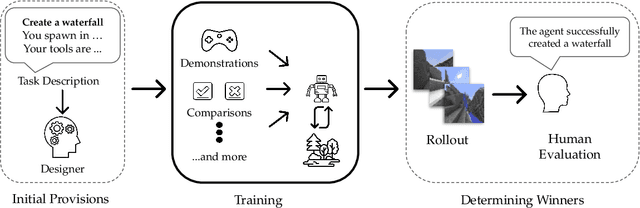

The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. Our hope is that this competition will improve our ability to build AI systems that do what their designers intend them to do, even when the intent cannot be easily formalized. Besides allowing AI to solve more tasks, this can also enable more effective regulation of AI systems, as well as making progress on the value alignment problem.
Distilling Reinforcement Learning Tricks for Video Games
Jul 01, 2021

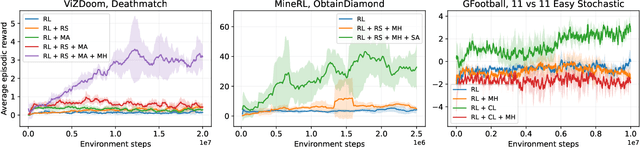

Reinforcement learning (RL) research focuses on general solutions that can be applied across different domains. This results in methods that RL practitioners can use in almost any domain. However, recent studies often lack the engineering steps ("tricks") which may be needed to effectively use RL, such as reward shaping, curriculum learning, and splitting a large task into smaller chunks. Such tricks are common, if not necessary, to achieve state-of-the-art results and win RL competitions. To ease the engineering efforts, we distill descriptions of tricks from state-of-the-art results and study how well these tricks can improve a standard deep Q-learning agent. The long-term goal of this work is to enable combining proven RL methods with domain-specific tricks by providing a unified software framework and accompanying insights in multiple domains.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021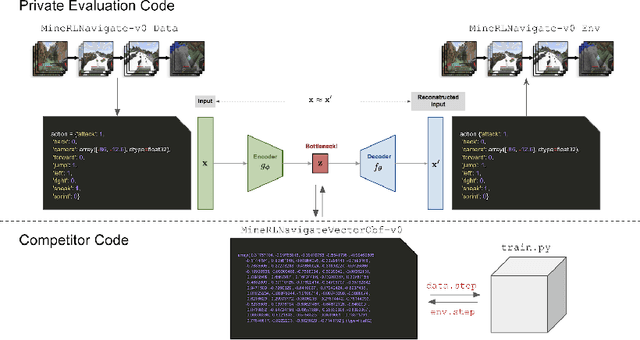

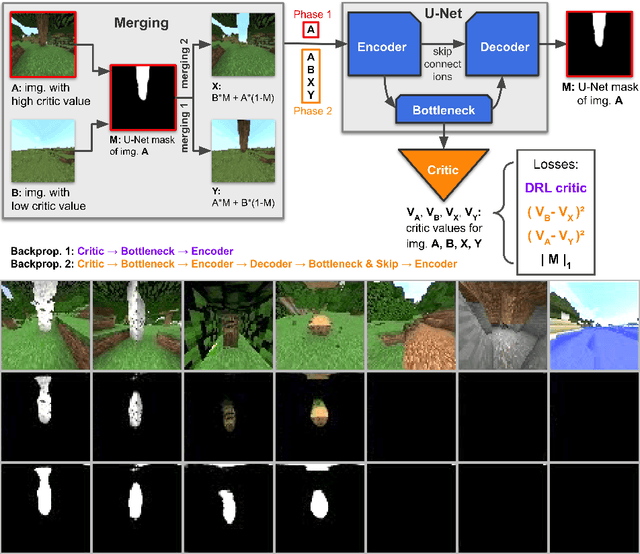
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Multi-task Learning with Attention for End-to-end Autonomous Driving
Apr 21, 2021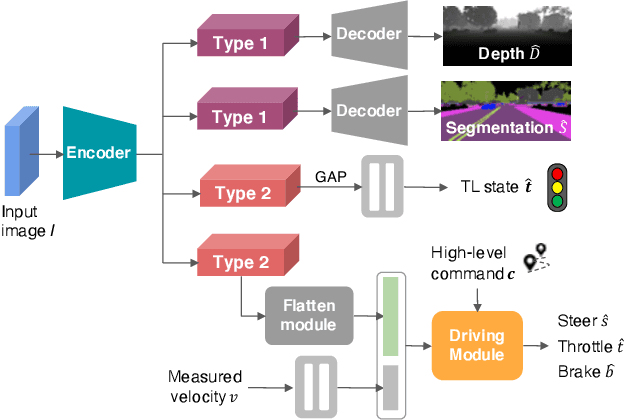
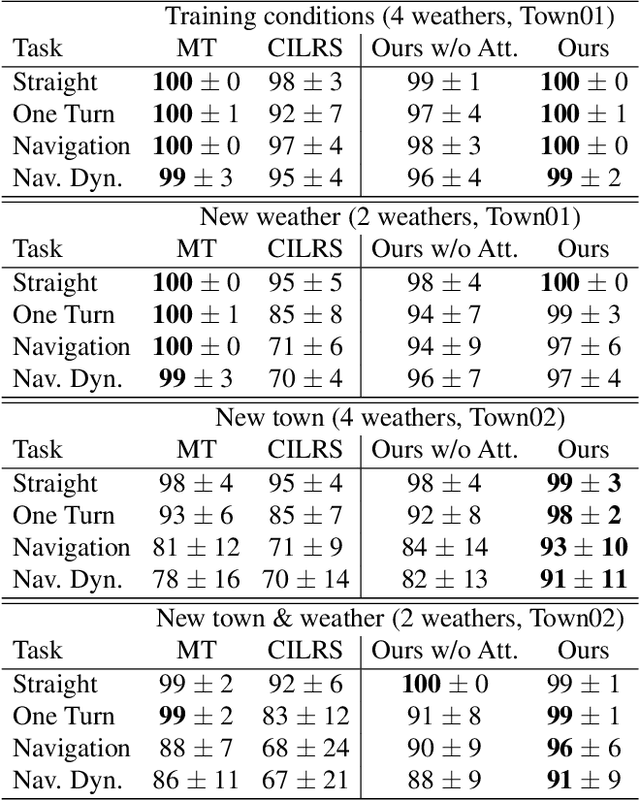
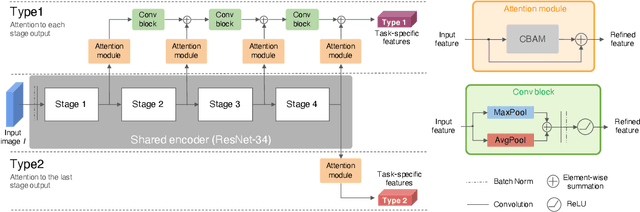
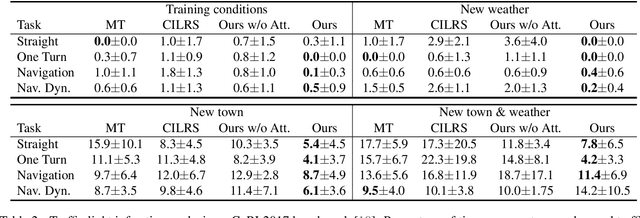
Autonomous driving systems need to handle complex scenarios such as lane following, avoiding collisions, taking turns, and responding to traffic signals. In recent years, approaches based on end-to-end behavioral cloning have demonstrated remarkable performance in point-to-point navigational scenarios, using a realistic simulator and standard benchmarks. Offline imitation learning is readily available, as it does not require expensive hand annotation or interaction with the target environment, but it is difficult to obtain a reliable system. In addition, existing methods have not specifically addressed the learning of reaction for traffic lights, which are a rare occurrence in the training datasets. Inspired by the previous work on multi-task learning and attention modeling, we propose a novel multi-task attention-aware network in the conditional imitation learning (CIL) framework. This does not only improve the success rate of standard benchmarks, but also the ability to react to traffic lights, which we show with standard benchmarks.