 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Guided Attention and Human Knowledge Insertion in Deep Convolutional Neural Networks
Oct 20, 2022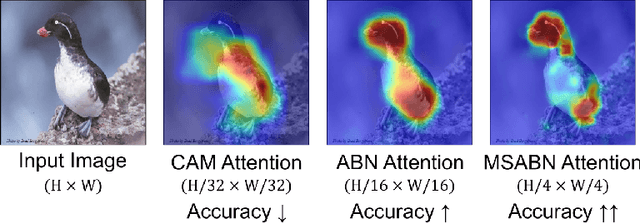

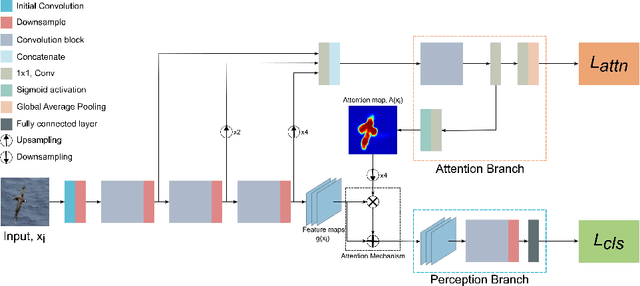
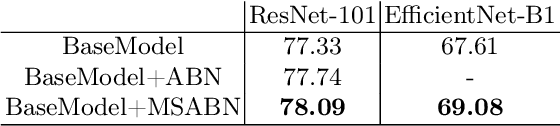
Attention Branch Networks (ABNs) have been shown to simultaneously provide visual explanation and improve the performance of deep convolutional neural networks (CNNs). In this work, we introduce Multi-Scale Attention Branch Networks (MSABN), which enhance the resolution of the generated attention maps, and improve the performance. We evaluate MSABN on benchmark image recognition and fine-grained recognition datasets where we observe MSABN outperforms ABN and baseline models. We also introduce a new data augmentation strategy utilizing the attention maps to incorporate human knowledge in the form of bounding box annotations of the objects of interest. We show that even with a limited number of edited samples, a significant performance gain can be achieved with this strategy.
Analyzing Transformers in Embedding Space
Sep 06, 2022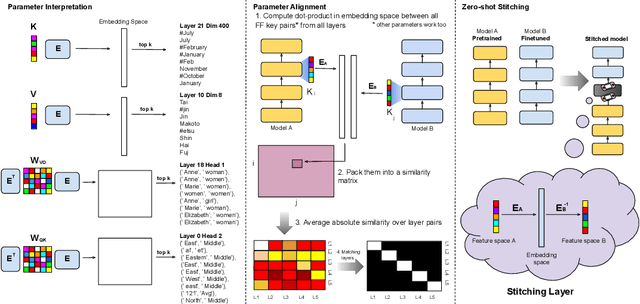
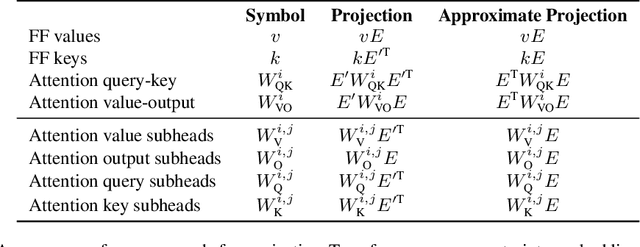
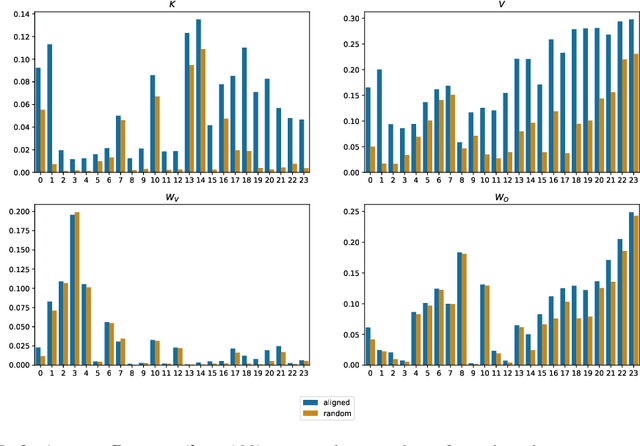
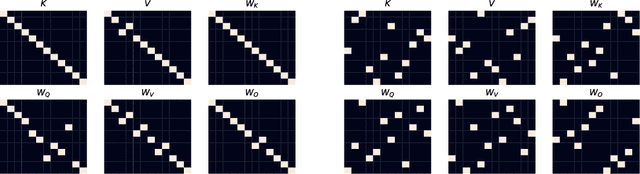
Understanding Transformer-based models has attracted significant attention, as they lie at the heart of recent technological advances across machine learning. While most interpretability methods rely on running models over inputs, recent work has shown that a zero-pass approach, where parameters are interpreted directly without a forward/backward pass is feasible for some Transformer parameters, and for two-layer attention networks. In this work, we present a theoretical analysis where all parameters of a trained Transformer are interpreted by projecting them into the embedding space, that is, the space of vocabulary items they operate on. We derive a simple theoretical framework to support our arguments and provide ample evidence for its validity. First, an empirical analysis showing that parameters of both pretrained and fine-tuned models can be interpreted in embedding space. Second, we present two applications of our framework: (a) aligning the parameters of different models that share a vocabulary, and (b) constructing a classifier without training by ``translating'' the parameters of a fine-tuned classifier to parameters of a different model that was only pretrained. Overall, our findings open the door to interpretation methods that, at least in part, abstract away from model specifics and operate in the embedding space only.
Long Range Language Modeling via Gated State Spaces
Jul 02, 2022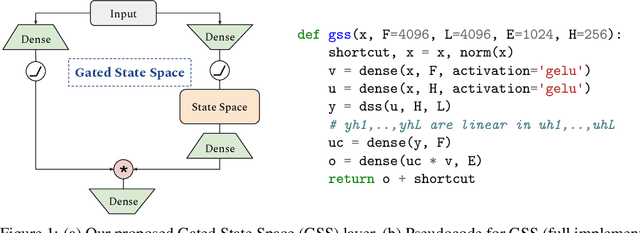
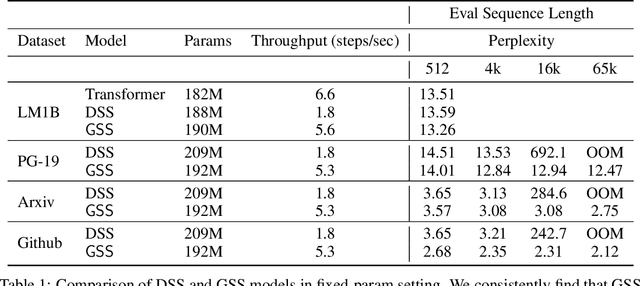
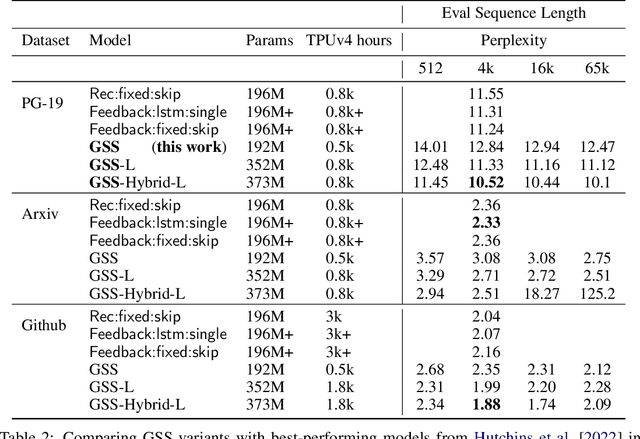
State space models have shown to be effective at modeling long range dependencies, specially on sequence classification tasks. In this work we focus on autoregressive sequence modeling over English books, Github source code and ArXiv mathematics articles. Based on recent developments around the effectiveness of gated activation functions, we propose a new layer named Gated State Space (GSS) and show that it trains significantly faster than the diagonal version of S4 (i.e. DSS) on TPUs, is fairly competitive with several well-tuned Transformer-based baselines and exhibits zero-shot generalization to longer inputs while being straightforward to implement. Finally, we show that leveraging self-attention to model local dependencies improves the performance of GSS even further.
On the Parameterization and Initialization of Diagonal State Space Models
Jun 23, 2022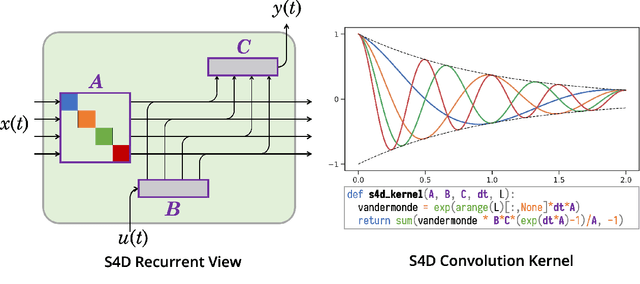

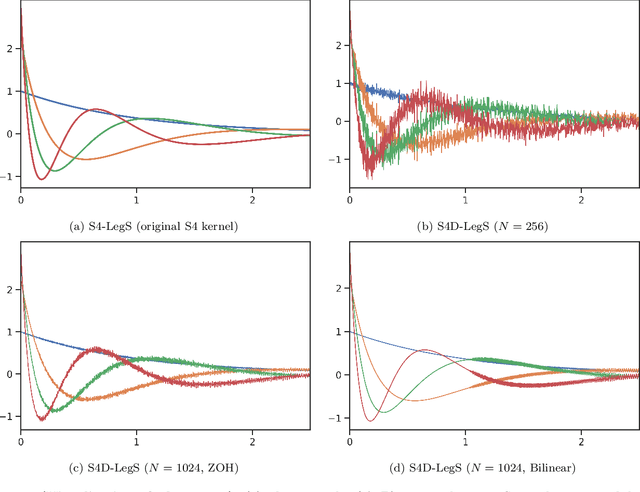

State space models (SSM) have recently been shown to be very effective as a deep learning layer as a promising alternative to sequence models such as RNNs, CNNs, or Transformers. The first version to show this potential was the S4 model, which is particularly effective on tasks involving long-range dependencies by using a prescribed state matrix called the HiPPO matrix. While this has an interpretable mathematical mechanism for modeling long dependencies, it introduces a custom representation and algorithm that can be difficult to implement. On the other hand, a recent variant of S4 called DSS showed that restricting the state matrix to be fully diagonal can still preserve the performance of the original model when using a specific initialization based on approximating S4's matrix. This work seeks to systematically understand how to parameterize and initialize such diagonal state space models. While it follows from classical results that almost all SSMs have an equivalent diagonal form, we show that the initialization is critical for performance. We explain why DSS works mathematically, by showing that the diagonal restriction of S4's matrix surprisingly recovers the same kernel in the limit of infinite state dimension. We also systematically describe various design choices in parameterizing and computing diagonal SSMs, and perform a controlled empirical study ablating the effects of these choices. Our final model S4D is a simple diagonal version of S4 whose kernel computation requires just 2 lines of code and performs comparably to S4 in almost all settings, with state-of-the-art results for image, audio, and medical time-series domains, and averaging 85\% on the Long Range Arena benchmark.
Diagonal State Spaces are as Effective as Structured State Spaces
Mar 27, 2022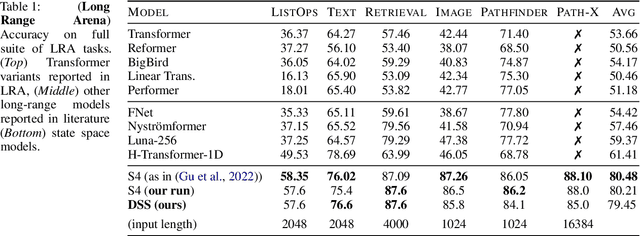
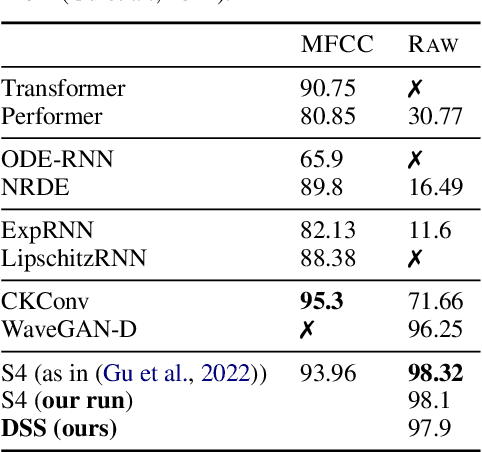

Modeling long range dependencies in sequential data is a fundamental step towards attaining human-level performance in many modalities such as text, vision and audio. While attention-based models are a popular and effective choice in modeling short-range interactions, their performance on tasks requiring long range reasoning has been largely inadequate. In a breakthrough result, Gu et al. (2022) proposed the $\textit{Structured State Space}$ (S4) architecture delivering large gains over state-of-the-art models on several long-range tasks across various modalities. The core proposition of S4 is the parameterization of state matrices via a diagonal plus low rank structure, allowing efficient computation. In this work, we show that one can match the performance of S4 even without the low rank correction and thus assuming the state matrices to be diagonal. Our $\textit{Diagonal State Space}$ (DSS) model matches the performance of S4 on Long Range Arena tasks, speech classification on Speech Commands dataset, while being conceptually simpler and straightforward to implement.
Machine Learning-based Urban Canyon Path Loss Prediction using 28 GHz Manhattan Measurements
Feb 10, 2022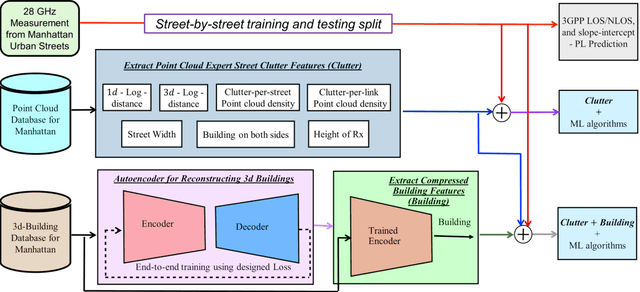
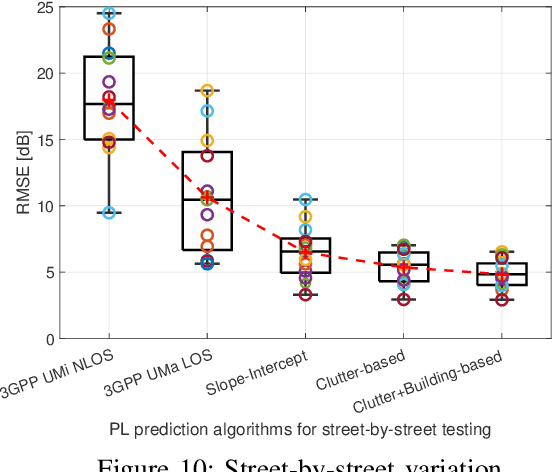
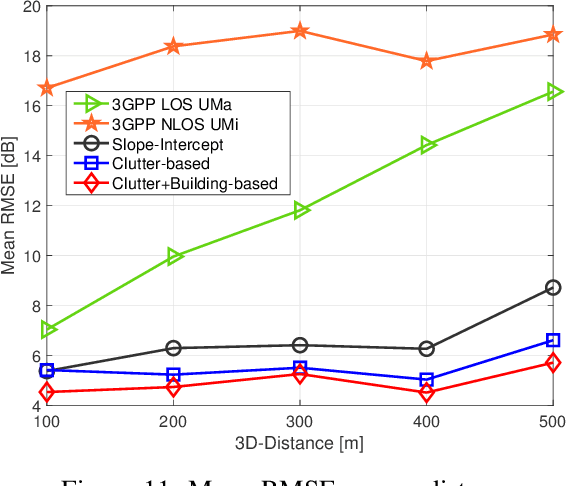
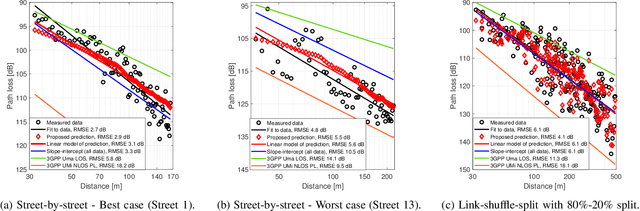
Large bandwidth at mm-wave is crucial for 5G and beyond but the high path loss (PL) requires highly accurate PL prediction for network planning and optimization. Statistical models with slope-intercept fit fall short in capturing large variations seen in urban canyons, whereas ray-tracing, capable of characterizing site-specific features, faces challenges in describing foliage and street clutter and associated reflection/diffraction ray calculation. Machine learning (ML) is promising but faces three key challenges in PL prediction: 1) insufficient measurement data; 2) lack of extrapolation to new streets; 3) overwhelmingly complex features/models. We propose an ML-based urban canyon PL prediction model based on extensive 28 GHz measurements from Manhattan where street clutters are modeled via a LiDAR point cloud dataset and buildings by a mesh-grid building dataset. We extract expert knowledge-driven street clutter features from the point cloud and aggressively compress 3D-building information using convolutional-autoencoder. Using a new street-by-street training and testing procedure to improve generalizability, the proposed model using both clutter and building features achieves a prediction error (RMSE) of $4.8 \pm 1.1$ dB compared to $10.6 \pm 4.4$ dB and $6.5 \pm 2.0$ dB for 3GPP LOS and slope-intercept prediction, respectively, where the standard deviation indicates street-by-street variation. By only using four most influential clutter features, RMSE of $5.5\pm 1.1$ dB is achieved.
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022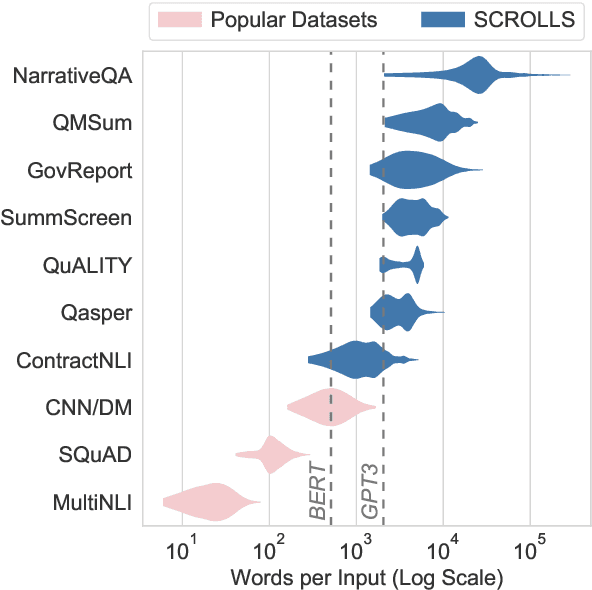
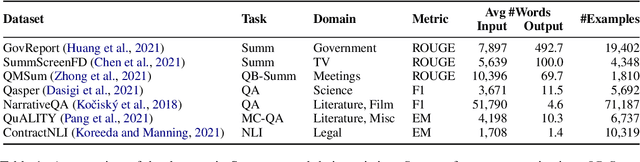

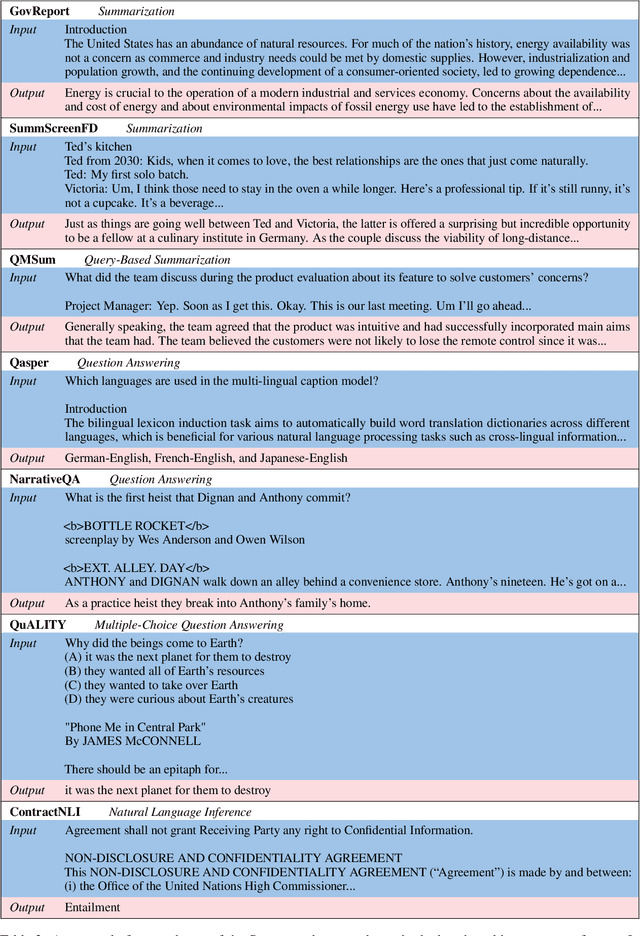
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.
Memory-efficient Transformers via Top-$k$ Attention
Jun 13, 2021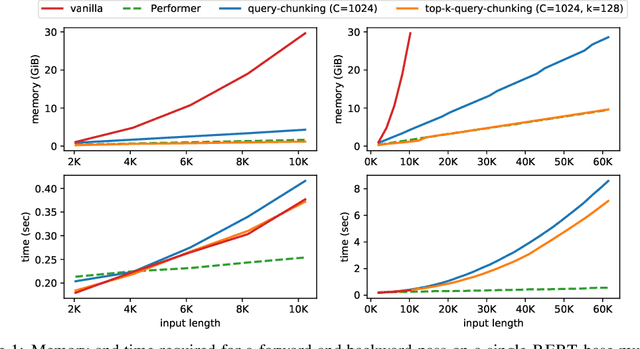
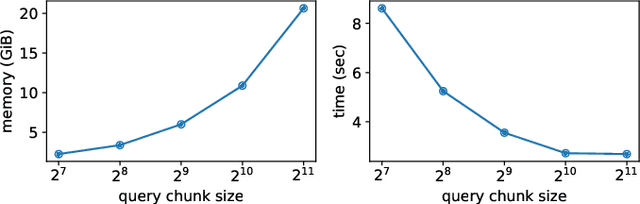
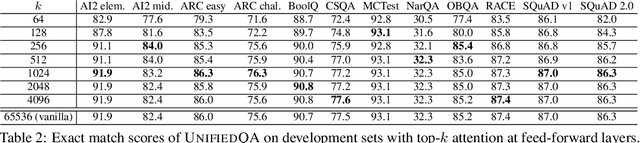
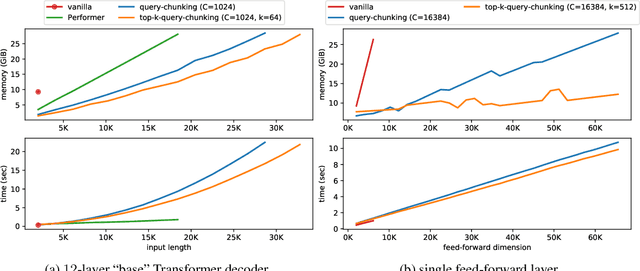
Following the success of dot-product attention in Transformers, numerous approximations have been recently proposed to address its quadratic complexity with respect to the input length. While these variants are memory and compute efficient, it is not possible to directly use them with popular pre-trained language models trained using vanilla attention, without an expensive corrective pre-training stage. In this work, we propose a simple yet highly accurate approximation for vanilla attention. We process the queries in chunks, and for each query, compute the top-$k$ scores with respect to the keys. Our approach offers several advantages: (a) its memory usage is linear in the input size, similar to linear attention variants, such as Performer and RFA (b) it is a drop-in replacement for vanilla attention that does not require any corrective pre-training, and (c) it can also lead to significant memory savings in the feed-forward layers after casting them into the familiar query-key-value framework. We evaluate the quality of top-$k$ approximation for multi-head attention layers on the Long Range Arena Benchmark, and for feed-forward layers of T5 and UnifiedQA on multiple QA datasets. We show our approach leads to accuracy that is nearly-identical to vanilla attention in multiple setups including training from scratch, fine-tuning, and zero-shot inference.
Value-aware Approximate Attention
Mar 17, 2021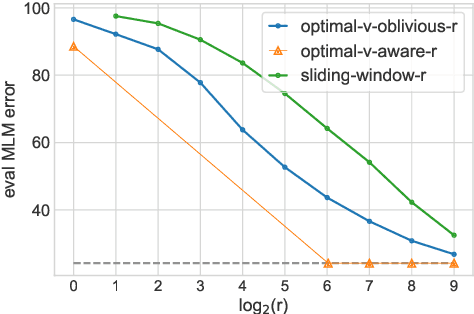

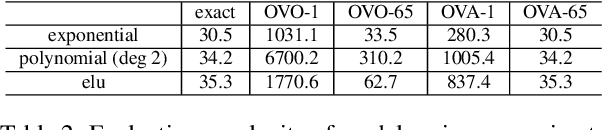
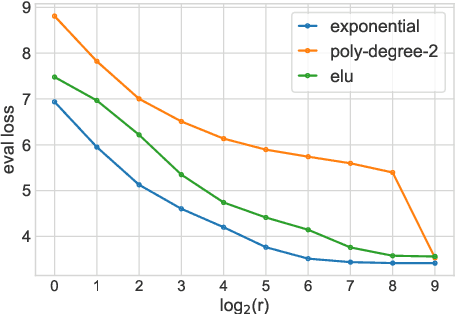
Following the success of dot-product attention in Transformers, numerous approximations have been recently proposed to address its quadratic complexity with respect to the input length. However, all approximations thus far have ignored the contribution of the $\textit{value vectors}$ to the quality of approximation. In this work, we argue that research efforts should be directed towards approximating the true output of the attention sub-layer, which includes the value vectors. We propose a value-aware objective, and show theoretically and empirically that an optimal approximation of a value-aware objective substantially outperforms an optimal approximation that ignores values, in the context of language modeling. Moreover, we show that the choice of kernel function for computing attention similarity can substantially affect the quality of sparse approximations, where kernel functions that are less skewed are more affected by the value vectors.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020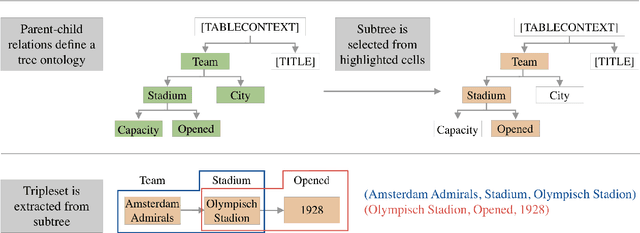
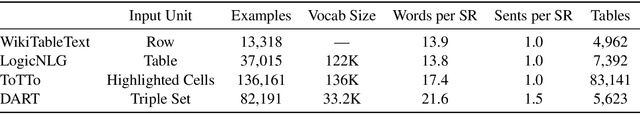
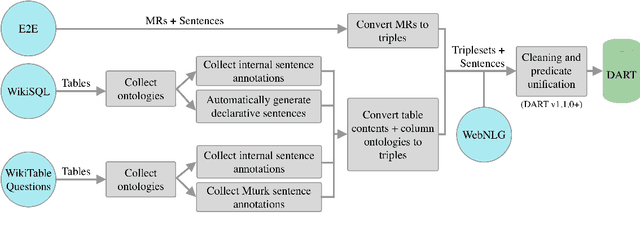
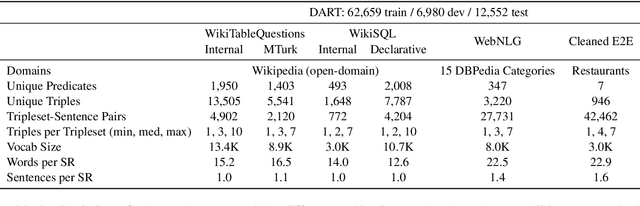
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.