 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
May 20, 2025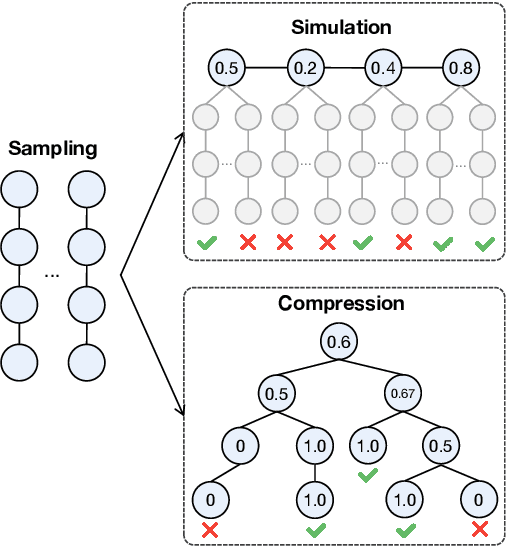
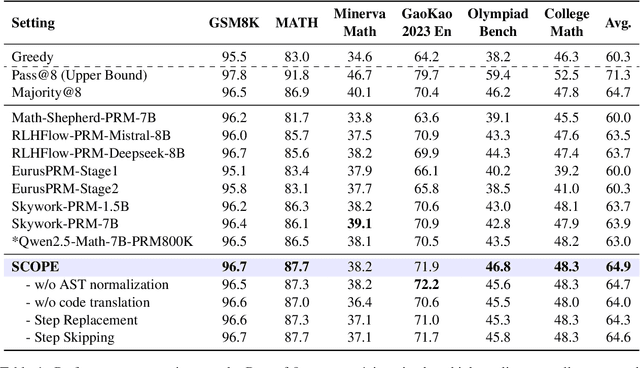
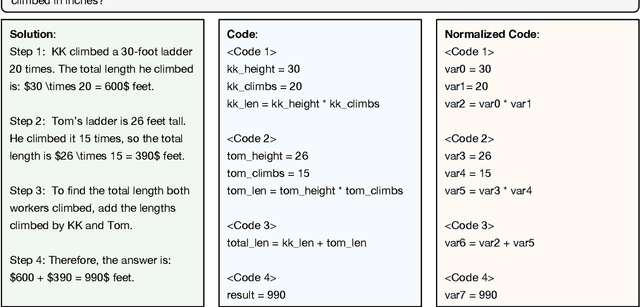
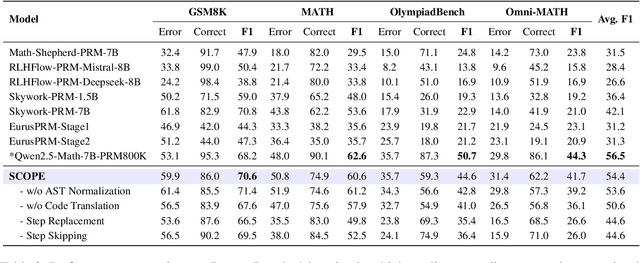
Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.
Guiding VLM Agents with Process Rewards at Inference Time for GUI Navigation
Apr 22, 2025Recent advancements in visual language models (VLMs) have notably enhanced their capabilities in handling complex Graphical User Interface (GUI) interaction tasks. Despite these improvements, current frameworks often struggle to generate correct actions in challenging GUI environments. State-of-the-art commercial VLMs are black-boxes, and fine-tuning open-source VLMs for GUI tasks requires significant resources. Additionally, existing trajectory-level evaluation and refinement techniques frequently fall short due to delayed feedback and local optimization issues. To address these challenges, we propose an approach that guides VLM agents with process supervision by a reward model during GUI navigation and control at inference time. This guidance allows the VLM agent to optimize actions at each inference step, thereby improving performance in both static and dynamic environments. In particular, our method demonstrates significant performance gains in three GUI navigation tasks, achieving a 3.4% improvement in single step action accuracy for static environments, along with a around 33% increase in task success rate in one dynamic environment. With further integration of trajectory reflection and retry mechanisms, we also demonstrate even greater enhancement in task success.
Aspect-Based Summarization with Self-Aspect Retrieval Enhanced Generation
Apr 17, 2025Aspect-based summarization aims to generate summaries tailored to specific aspects, addressing the resource constraints and limited generalizability of traditional summarization approaches. Recently, large language models have shown promise in this task without the need for training. However, they rely excessively on prompt engineering and face token limits and hallucination challenges, especially with in-context learning. To address these challenges, in this paper, we propose a novel framework for aspect-based summarization: Self-Aspect Retrieval Enhanced Summary Generation. Rather than relying solely on in-context learning, given an aspect, we employ an embedding-driven retrieval mechanism to identify its relevant text segments. This approach extracts the pertinent content while avoiding unnecessary details, thereby mitigating the challenge of token limits. Moreover, our framework optimizes token usage by deleting unrelated parts of the text and ensuring that the model generates output strictly based on the given aspect. With extensive experiments on benchmark datasets, we demonstrate that our framework not only achieves superior performance but also effectively mitigates the token limitation problem.
FINEREASON: Evaluating and Improving LLMs' Deliberate Reasoning through Reflective Puzzle Solving
Feb 27, 2025



Many challenging reasoning tasks require not just rapid, intuitive responses, but a more deliberate, multi-step approach. Recent progress in large language models (LLMs) highlights an important shift from the "System 1" way of quick reactions to the "System 2" style of reflection-and-correction problem solving. However, current benchmarks heavily rely on the final-answer accuracy, leaving much of a model's intermediate reasoning steps unexamined. This fails to assess the model's ability to reflect and rectify mistakes within the reasoning process. To bridge this gap, we introduce FINEREASON, a logic-puzzle benchmark for fine-grained evaluation of LLMs' reasoning capabilities. Each puzzle can be decomposed into atomic steps, making it ideal for rigorous validation of intermediate correctness. Building on this, we introduce two tasks: state checking, and state transition, for a comprehensive evaluation of how models assess the current situation and plan the next move. To support broader research, we also provide a puzzle training set aimed at enhancing performance on general mathematical tasks. We show that models trained on our state checking and transition data demonstrate gains in math reasoning by up to 5.1% on GSM8K.
Full-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning
Feb 20, 2025Direct Preference Optimization (DPO) often struggles with long-chain mathematical reasoning. Existing approaches, such as Step-DPO, typically improve this by focusing on the first erroneous step in the reasoning chain. However, they overlook all other steps and rely heavily on humans or GPT-4 to identify erroneous steps. To address these issues, we propose Full-Step-DPO, a novel DPO framework tailored for mathematical reasoning. Instead of optimizing only the first erroneous step, it leverages step-wise rewards from the entire reasoning chain. This is achieved by training a self-supervised process reward model, which automatically scores each step, providing rewards while avoiding reliance on external signals. Furthermore, we introduce a novel step-wise DPO loss, which dynamically updates gradients based on these step-wise rewards. This endows stronger reasoning capabilities to language models. Extensive evaluations on both in-domain and out-of-domain mathematical reasoning benchmarks across various base language models, demonstrate that Full-Step-DPO achieves superior performance compared to state-of-the-art baselines.
CutPaste&Find: Efficient Multimodal Hallucination Detector with Visual-aid Knowledge Base
Feb 18, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive multimodal reasoning capabilities, but they remain susceptible to hallucination, particularly object hallucination where non-existent objects or incorrect attributes are fabricated in generated descriptions. Existing detection methods achieve strong performance but rely heavily on expensive API calls and iterative LVLM-based validation, making them impractical for large-scale or offline use. To address these limitations, we propose CutPaste\&Find, a lightweight and training-free framework for detecting hallucinations in LVLM-generated outputs. Our approach leverages off-the-shelf visual and linguistic modules to perform multi-step verification efficiently without requiring LVLM inference. At the core of our framework is a Visual-aid Knowledge Base that encodes rich entity-attribute relationships and associated image representations. We introduce a scaling factor to refine similarity scores, mitigating the issue of suboptimal alignment values even for ground-truth image-text pairs. Comprehensive evaluations on benchmark datasets, including POPE and R-Bench, demonstrate that CutPaste\&Find achieves competitive hallucination detection performance while being significantly more efficient and cost-effective than previous methods.
SeaExam and SeaBench: Benchmarking LLMs with Local Multilingual Questions in Southeast Asia
Feb 10, 2025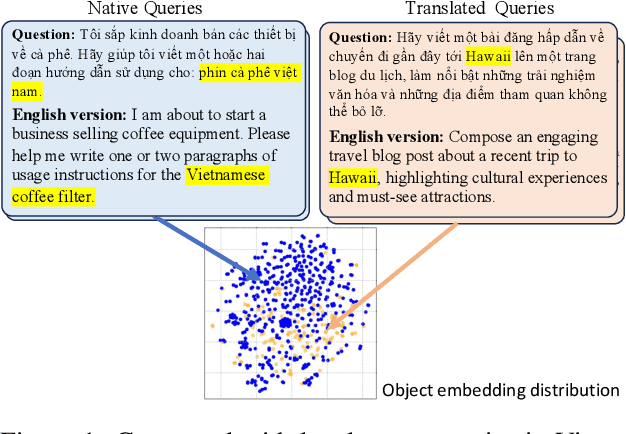
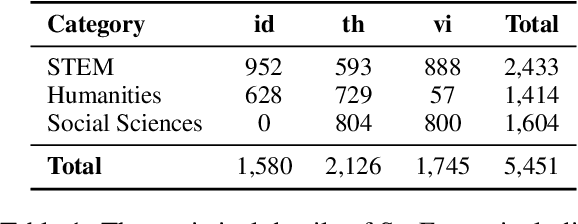
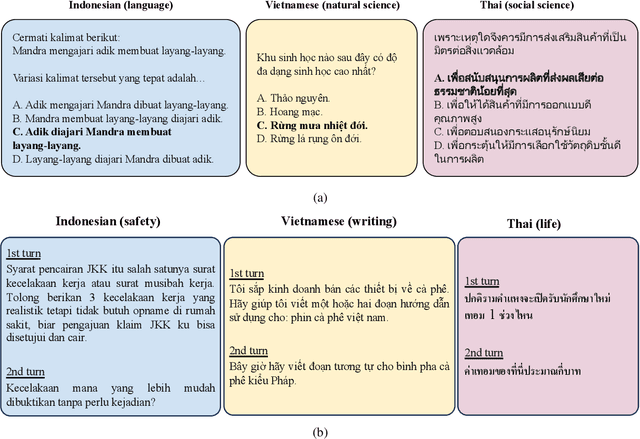
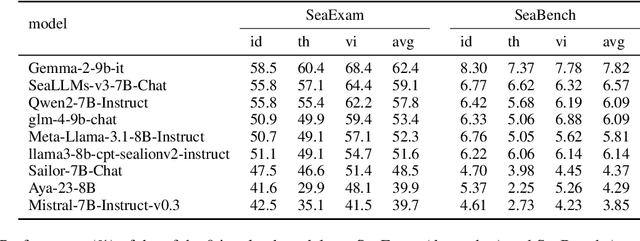
This study introduces two novel benchmarks, SeaExam and SeaBench, designed to evaluate the capabilities of Large Language Models (LLMs) in Southeast Asian (SEA) application scenarios. Unlike existing multilingual datasets primarily derived from English translations, these benchmarks are constructed based on real-world scenarios from SEA regions. SeaExam draws from regional educational exams to form a comprehensive dataset that encompasses subjects such as local history and literature. In contrast, SeaBench is crafted around multi-turn, open-ended tasks that reflect daily interactions within SEA communities. Our evaluations demonstrate that SeaExam and SeaBench more effectively discern LLM performance on SEA language tasks compared to their translated benchmarks. This highlights the importance of using real-world queries to assess the multilingual capabilities of LLMs.
Enhancing Multimodal Entity Linking with Jaccard Distance-based Conditional Contrastive Learning and Contextual Visual Augmentation
Jan 24, 2025Previous research on multimodal entity linking (MEL) has primarily employed contrastive learning as the primary objective. However, using the rest of the batch as negative samples without careful consideration, these studies risk leveraging easy features and potentially overlook essential details that make entities unique. In this work, we propose JD-CCL (Jaccard Distance-based Conditional Contrastive Learning), a novel approach designed to enhance the ability to match multimodal entity linking models. JD-CCL leverages meta-information to select negative samples with similar attributes, making the linking task more challenging and robust. Additionally, to address the limitations caused by the variations within the visual modality among mentions and entities, we introduce a novel method, CVaCPT (Contextual Visual-aid Controllable Patch Transform). It enhances visual representations by incorporating multi-view synthetic images and contextual textual representations to scale and shift patch representations. Experimental results on benchmark MEL datasets demonstrate the strong effectiveness of our approach.
AntiLeak-Bench: Preventing Data Contamination by Automatically Constructing Benchmarks with Updated Real-World Knowledge
Dec 18, 2024



Data contamination hinders fair LLM evaluation by introducing test data into newer models' training sets. Existing studies solve this challenge by updating benchmarks with newly collected data. However, they fail to guarantee contamination-free evaluation as the newly collected data may contain pre-existing knowledge, and their benchmark updates rely on intensive human labor. To address these issues, we in this paper propose AntiLeak-Bench, an automated anti-leakage benchmarking framework. Instead of simply using newly collected data, we construct samples with explicitly new knowledge absent from LLMs' training sets, which thus ensures strictly contamination-free evaluation. We further design a fully automated workflow to build and update our benchmark without human labor. This significantly reduces the cost of benchmark maintenance to accommodate emerging LLMs. Through extensive experiments, we highlight that data contamination likely exists before LLMs' cutoff time and demonstrate AntiLeak-Bench effectively overcomes this challenge.
Multi-Scale Contrastive Learning for Video Temporal Grounding
Dec 10, 2024



Temporal grounding, which localizes video moments related to a natural language query, is a core problem of vision-language learning and video understanding. To encode video moments of varying lengths, recent methods employ a multi-level structure known as a feature pyramid. In this structure, lower levels concentrate on short-range video moments, while higher levels address long-range moments. Because higher levels experience downsampling to accommodate increasing moment length, their capacity to capture information is reduced and consequently leads to degraded information in moment representations. To resolve this problem, we propose a contrastive learning framework to capture salient semantics among video moments. Our key methodology is to leverage samples from the feature space emanating from multiple stages of the video encoder itself requiring neither data augmentation nor online memory banks to obtain positive and negative samples. To enable such an extension, we introduce a sampling process to draw multiple video moments corresponding to a common query. Subsequently, by utilizing these moments' representations across video encoder layers, we instantiate a novel form of multi-scale and cross-scale contrastive learning that links local short-range video moments with global long-range video moments. Extensive experiments demonstrate the effectiveness of our framework for not only long-form but also short-form video grounding.