 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on Intellectual Property Resource Profile and Evolution Law
Apr 13, 2022In the era of big data, intellectual property-oriented scientific and technological resources show the trend of large data scale, high information density and low value density, which brings severe challenges to the effective use of intellectual property resources, and the demand for mining hidden information in intellectual property is increasing. This makes intellectual property-oriented science and technology resource portraits and analysis of evolution become the current research hotspot. This paper sorts out the construction method of intellectual property resource intellectual portrait and its pre-work property entity extraction and entity completion from the aspects of algorithm classification and general process, and directions for improvement of future methods.
Retrieval of Scientific and Technological Resources for Experts and Scholars
Apr 13, 2022Institutions of higher learning, research institutes and other scientific research units have abundant scientific and technological resources of experts and scholars, and these talents with great scientific and technological innovation ability are an important force to promote industrial upgrading. The scientific and technological resources of experts and scholars are mainly composed of basic attributes and scientific research achievements. The basic attributes include information such as research interests, institutions, and educational work experience. However, due to information asymmetry and other reasons, the scientific and technological resources of experts and scholars cannot be connected with the society in a timely manner, and social needs cannot be accurately matched with experts and scholars. Therefore, it is very necessary to build an expert and scholar information database and provide relevant expert and scholar retrieval services. This paper sorts out the related research work in this field from four aspects: text relation extraction, text knowledge representation learning, text vector retrieval and visualization system.
Knowledge Graph and Accurate Portrait Construction of Scientific and Technological Academic Conferences
Apr 11, 2022In recent years, with the continuous progress of science and technology, the number of scientific research achievements is increasing day by day, as the exchange platform and medium of scientific research achievements, the scientific and technological academic conferences have become more and more abundant. The convening of scientific and technological academic conferences will bring large number of academic papers, researchers, research institutions and other data, and the massive data brings difficulties for researchers to obtain valuable information. Therefore, it is of great significance to use deep learning technology to mine the core information in the data of scientific and technological academic conferences, and to realize a knowledge graph and accurate portrait system of scientific and technological academic conferences, so that researchers can obtain scientific research information faster.
Research on Cross-media Science and Technology Information Data Retrieval
Apr 11, 2022Since the era of big data, the Internet has been flooded with all kinds of information. Browsing information through the Internet has become an integral part of people's daily life. Unlike the news data and social data in the Internet, the cross-media technology information data has different characteristics. This data has become an important basis for researchers and scholars to track the current hot spots and explore the future direction of technology development. As the volume of science and technology information data becomes richer, the traditional science and technology information retrieval system, which only supports unimodal data retrieval and uses outdated data keyword matching model, can no longer meet the daily retrieval needs of science and technology scholars. Therefore, in view of the above research background, it is of profound practical significance to study the cross-media science and technology information data retrieval system based on deep semantic features, which is in line with the development trend of domestic and international technologies.
Accurate Portraits of Scientific Resources and Knowledge Service Components
Apr 11, 2022With the advent of the cloud computing era, the cost of creating, capturing and managing information has gradually decreased. The amount of data in the Internet is also showing explosive growth, and more and more scientific and technological resources are uploaded to the network. Different from news and social media data ubiquitous in the Internet, the main body of scientific and technological resources is composed of academic-style resources or entities such as papers, patents, authors, and research institutions. There is a rich relationship network between resources, from which a large amount of cutting-edge scientific and technological information can be mined. There are a large number of management and classification standards for existing scientific and technological resources, but these standards are difficult to completely cover all entities and associations of scientific and technological resources, and cannot accurately extract important information contained in scientific and technological resources. How to construct a complete and accurate representation of scientific and technological resources from structured and unstructured reports and texts in the network, and how to tap the potential value of scientific and technological resources is an urgent problem. The solution is to construct accurate portraits of scientific and technological resources in combination with knowledge graph related technologies.
Information-theoretic Online Memory Selection for Continual Learning
Apr 10, 2022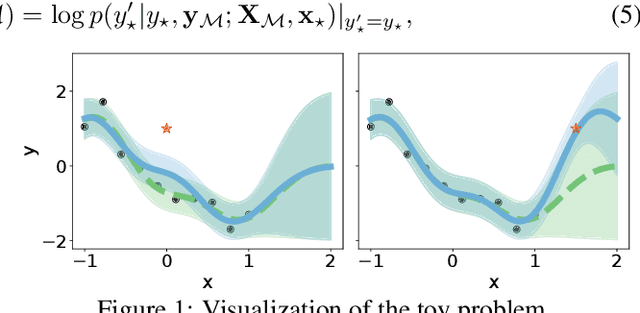
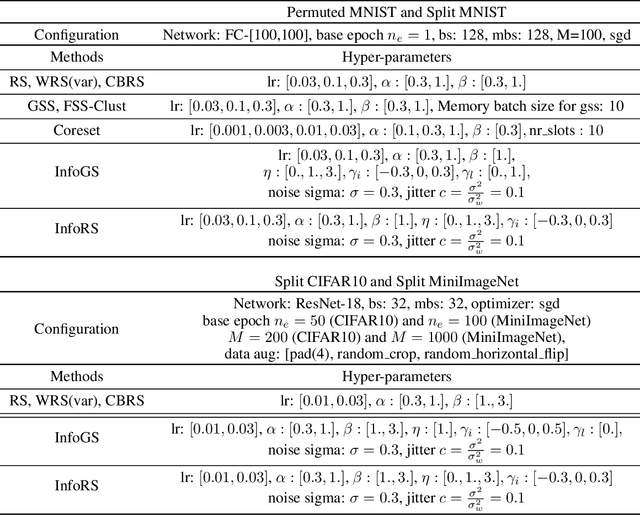
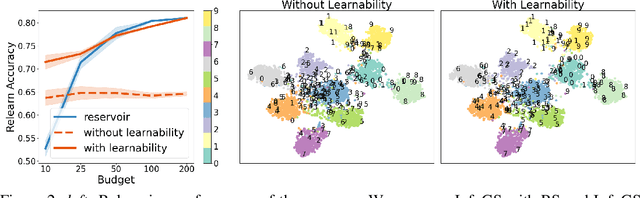
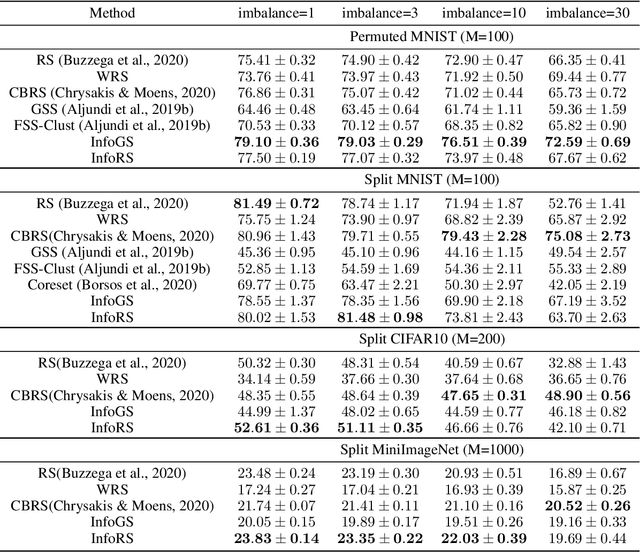
A challenging problem in task-free continual learning is the online selection of a representative replay memory from data streams. In this work, we investigate the online memory selection problem from an information-theoretic perspective. To gather the most information, we propose the \textit{surprise} and the \textit{learnability} criteria to pick informative points and to avoid outliers. We present a Bayesian model to compute the criteria efficiently by exploiting rank-one matrix structures. We demonstrate that these criteria encourage selecting informative points in a greedy algorithm for online memory selection. Furthermore, by identifying the importance of \textit{the timing to update the memory}, we introduce a stochastic information-theoretic reservoir sampler (InfoRS), which conducts sampling among selective points with high information. Compared to reservoir sampling, InfoRS demonstrates improved robustness against data imbalance. Finally, empirical performances over continual learning benchmarks manifest its efficiency and efficacy.
FastMapSVM: Classifying Complex Objects Using the FastMap Algorithm and Support-Vector Machines
Apr 07, 2022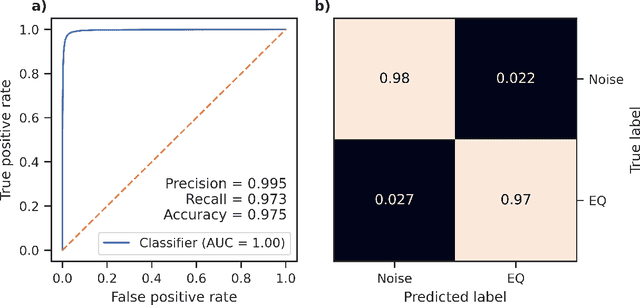

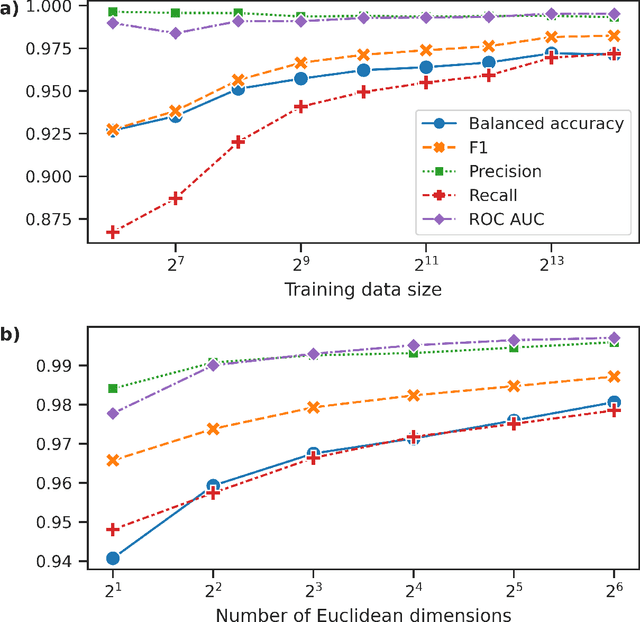
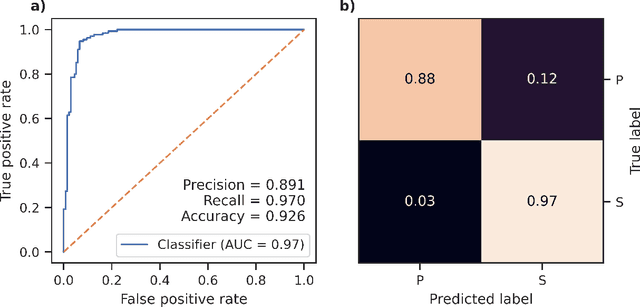
Neural Networks and related Deep Learning methods are currently at the leading edge of technologies used for classifying objects. However, they generally demand large amounts of time and data for model training; and their learned models can sometimes be difficult to interpret. In this paper, we present FastMapSVM, a novel interpretable Machine Learning framework for classifying complex objects. FastMapSVM combines the strengths of FastMap and Support-Vector Machines. FastMap is an efficient linear-time algorithm that maps complex objects to points in a Euclidean space, while preserving pairwise non-Euclidean distances between them. We demonstrate the efficiency and effectiveness of FastMapSVM in the context of classifying seismograms. We show that its performance, in terms of precision, recall, and accuracy, is comparable to that of other state-of-the-art methods. However, compared to other methods, FastMapSVM uses significantly smaller amounts of time and data for model training. It also provides a perspicuous visualization of the objects and the classification boundaries between them. We expect FastMapSVM to be viable for classification tasks in many other real-world domains.
Scientific and Technological Text Knowledge Extraction Method of based on Word Mixing and GRU
Mar 31, 2022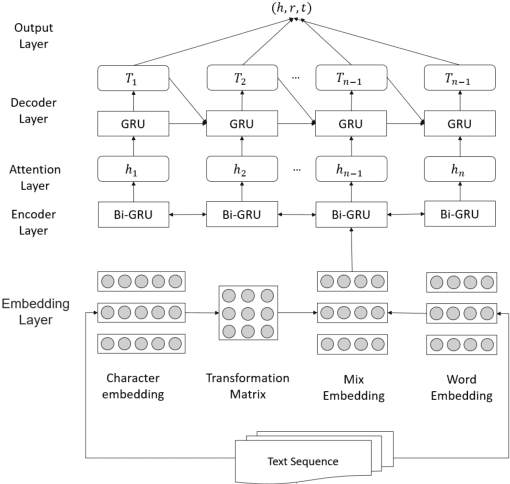
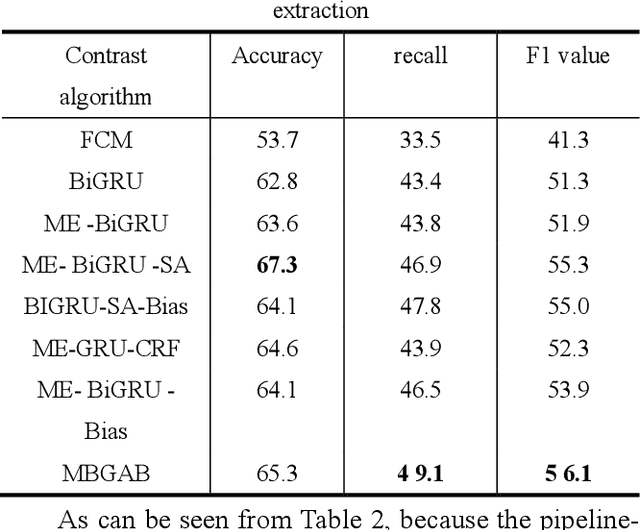
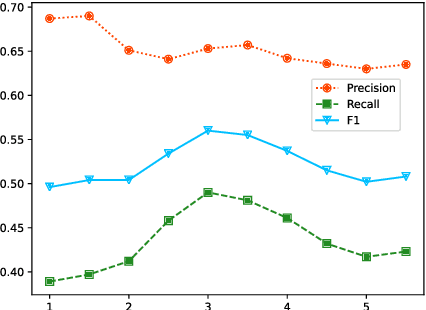

The knowledge extraction task is to extract triple relations (head entity-relation-tail entity) from unstructured text data. The existing knowledge extraction methods are divided into "pipeline" method and joint extraction method. The "pipeline" method is to separate named entity recognition and entity relationship extraction and use their own modules to extract them. Although this method has better flexibility, the training speed is slow. The learning model of joint extraction is an end-to-end model implemented by neural network to realize entity recognition and relationship extraction at the same time, which can well preserve the association between entities and relationships, and convert the joint extraction of entities and relationships into a sequence annotation problem. In this paper, we propose a knowledge extraction method for scientific and technological resources based on word mixture and GRU, combined with word mixture vector mapping method and self-attention mechanism, to effectively improve the effect of text relationship extraction for Chinese scientific and technological resources.
Towards Collaborative Intelligence: Routability Estimation based on Decentralized Private Data
Mar 30, 2022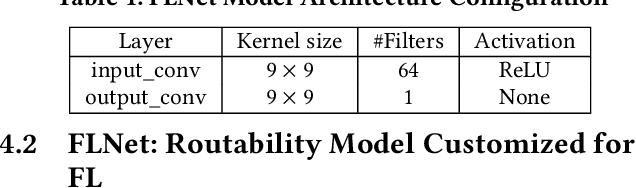
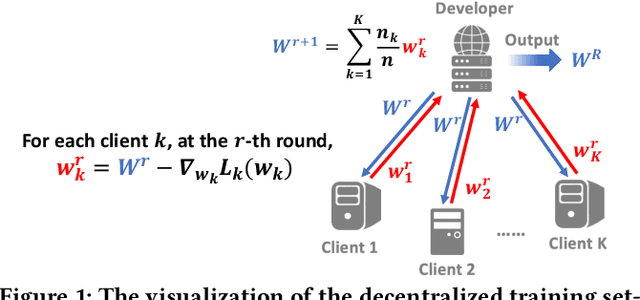
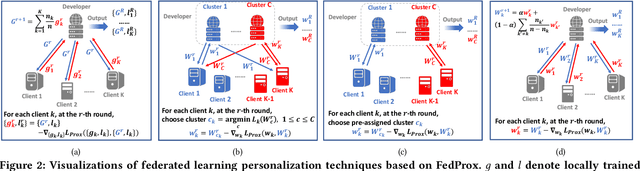
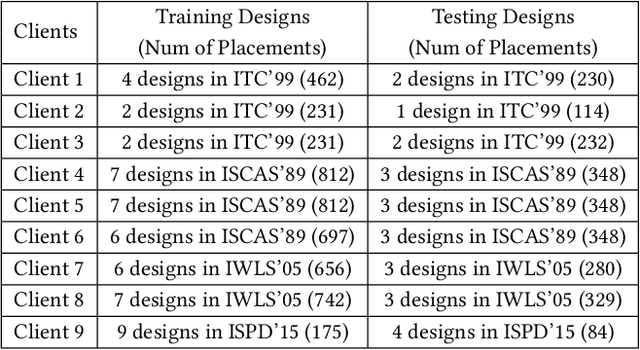
Applying machine learning (ML) in design flow is a popular trend in EDA with various applications from design quality predictions to optimizations. Despite its promise, which has been demonstrated in both academic researches and industrial tools, its effectiveness largely hinges on the availability of a large amount of high-quality training data. In reality, EDA developers have very limited access to the latest design data, which is owned by design companies and mostly confidential. Although one can commission ML model training to a design company, the data of a single company might be still inadequate or biased, especially for small companies. Such data availability problem is becoming the limiting constraint on future growth of ML for chip design. In this work, we propose an Federated-Learning based approach for well-studied ML applications in EDA. Our approach allows an ML model to be collaboratively trained with data from multiple clients but without explicit access to the data for respecting their data privacy. To further strengthen the results, we co-design a customized ML model FLNet and its personalization under the decentralized training scenario. Experiments on a comprehensive dataset show that collaborative training improves accuracy by 11% compared with individual local models, and our customized model FLNet significantly outperforms the best of previous routability estimators in this collaborative training flow.
BNS-GCN: Efficient Full-Graph Training of Graph Convolutional Networks with Partition-Parallelism and Random Boundary Node Sampling
Mar 26, 2022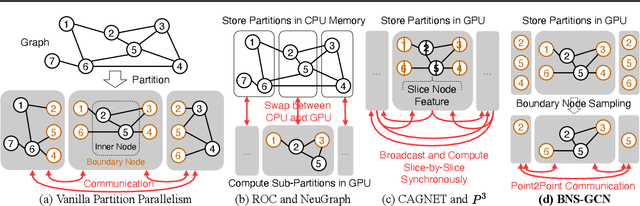

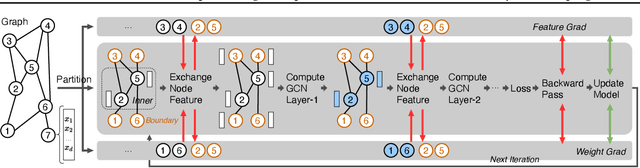

Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art method for graph-based learning tasks. However, training GCNs at scale is still challenging, hindering both the exploration of more sophisticated GCN architectures and their applications to real-world large graphs. While it might be natural to consider graph partition and distributed training for tackling this challenge, this direction has only been slightly scratched the surface in the previous works due to the limitations of existing designs. In this work, we first analyze why distributed GCN training is ineffective and identify the underlying cause to be the excessive number of boundary nodes of each partitioned subgraph, which easily explodes the memory and communication costs for GCN training. Furthermore, we propose a simple yet effective method dubbed BNS-GCN that adopts random Boundary-Node-Sampling to enable efficient and scalable distributed GCN training. Experiments and ablation studies consistently validate the effectiveness of BNS-GCN, e.g., boosting the throughput by up to 16.2x and reducing the memory usage by up to 58%, while maintaining a full-graph accuracy. Furthermore, both theoretical and empirical analysis show that BNS-GCN enjoys a better convergence than existing sampling-based methods. We believe that our BNS-GCN has opened up a new paradigm for enabling GCN training at scale. The code is available at https://github.com/RICE-EIC/BNS-GCN.