 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Informed Representation for Evolutionary Sieving in Integral and Module Lattices
May 27, 2026Traditional cryptography, rooted in problems, e.g., integer factorisation or discrete log, is inevitably vulnerable to a fully operational quantum computer. Although it remains an engineering frontier, the looming threat extends to encrypted data stored today, which could be decrypted in the future with quantum capabilities. To safeguard against this eventuality, the backbone of the modern quantum-safe cryptography is the Shortest Vector Problem (SVP). We enhance Laarhoven's treatment of Ajtai et al.'s sieving as a genetic algorithm (GA) for the SVP by incorporating domain-informed SVP representation and crossover while naturally extending application to the module lattices.
* Published (16 pages) in the proceedings of EvoApplications 2026. You may find the proceedings version here at https://link.springer.com/chapter/10.1007/978-3-032-23604-3_9
AgroFlux: A Spatial-Temporal Benchmark for Carbon and Nitrogen Flux Prediction in Agricultural Ecosystems
Feb 02, 2026Agroecosystem, which heavily influenced by human actions and accounts for a quarter of global greenhouse gas emissions (GHGs), plays a crucial role in mitigating global climate change and securing environmental sustainability. However, we can't manage what we can't measure. Accurately quantifying the pools and fluxes in the carbon, nutrient, and water nexus of the agroecosystem is therefore essential for understanding the underlying drivers of GHG and developing effective mitigation strategies. Conventional approaches like soil sampling, process-based models, and black-box machine learning models are facing challenges such as data sparsity, high spatiotemporal heterogeneity, and complex subsurface biogeochemical and physical processes. Developing new trustworthy approaches such as AI-empowered models, will require the AI-ready benchmark dataset and outlined protocols, which unfortunately do not exist. In this work, we introduce a first-of-its-kind spatial-temporal agroecosystem GHG benchmark dataset that integrates physics-based model simulations from Ecosys and DayCent with real-world observations from eddy covariance flux towers and controlled-environment facilities. We evaluate the performance of various sequential deep learning models on carbon and nitrogen flux prediction, including LSTM-based models, temporal CNN-based model, and Transformer-based models. Furthermore, we explored transfer learning to leverage simulated data to improve the generalization of deep learning models on real-world observations. Our benchmark dataset and evaluation framework contribute to the development of more accurate and scalable AI-driven agroecosystem models, advancing our understanding of ecosystem-climate interactions.
LLM-based Evaluation Policy Extraction for Ecological Modeling
May 20, 2025Evaluating ecological time series is critical for benchmarking model performance in many important applications, including predicting greenhouse gas fluxes, capturing carbon-nitrogen dynamics, and monitoring hydrological cycles. Traditional numerical metrics (e.g., R-squared, root mean square error) have been widely used to quantify the similarity between modeled and observed ecosystem variables, but they often fail to capture domain-specific temporal patterns critical to ecological processes. As a result, these methods are often accompanied by expert visual inspection, which requires substantial human labor and limits the applicability to large-scale evaluation. To address these challenges, we propose a novel framework that integrates metric learning with large language model (LLM)-based natural language policy extraction to develop interpretable evaluation criteria. The proposed method processes pairwise annotations and implements a policy optimization mechanism to generate and combine different assessment metrics. The results obtained on multiple datasets for evaluating the predictions of crop gross primary production and carbon dioxide flux have confirmed the effectiveness of the proposed method in capturing target assessment preferences, including both synthetically generated and expert-annotated model comparisons. The proposed framework bridges the gap between numerical metrics and expert knowledge while providing interpretable evaluation policies that accommodate the diverse needs of different ecosystem modeling studies.
Knowledge Guided Encoder-Decoder Framework: Integrating Multiple Physical Models for Agricultural Ecosystem Modeling
May 13, 2025



Agricultural monitoring is critical for ensuring food security, maintaining sustainable farming practices, informing policies on mitigating food shortage, and managing greenhouse gas emissions. Traditional process-based physical models are often designed and implemented for specific situations, and their parameters could also be highly uncertain. In contrast, data-driven models often use black-box structures and does not explicitly model the inter-dependence between different ecological variables. As a result, they require extensive training data and lack generalizability to different tasks with data distribution shifts and inconsistent observed variables. To address the need for more universal models, we propose a knowledge-guided encoder-decoder model, which can predict key crop variables by leveraging knowledge of underlying processes from multiple physical models. The proposed method also integrates a language model to process complex and inconsistent inputs and also utilizes it to implement a model selection mechanism for selectively combining the knowledge from different physical models. Our evaluations on predicting carbon and nitrogen fluxes for multiple sites demonstrate the effectiveness and robustness of the proposed model under various scenarios.
Learning Multimodal Cues of Children's Uncertainty
Oct 17, 2024



Understanding uncertainty plays a critical role in achieving common ground (Clark et al.,1983). This is especially important for multimodal AI systems that collaborate with users to solve a problem or guide the user through a challenging concept. In this work, for the first time, we present a dataset annotated in collaboration with developmental and cognitive psychologists for the purpose of studying nonverbal cues of uncertainty. We then present an analysis of the data, studying different roles of uncertainty and its relationship with task difficulty and performance. Lastly, we present a multimodal machine learning model that can predict uncertainty given a real-time video clip of a participant, which we find improves upon a baseline multimodal transformer model. This work informs research on cognitive coordination between human-human and human-AI and has broad implications for gesture understanding and generation. The anonymized version of our data and code will be publicly available upon the completion of the required consent forms and data sheets.
Every Answer Matters: Evaluating Commonsense with Probabilistic Measures
Jun 06, 2024



Large language models have demonstrated impressive performance on commonsense tasks; however, these tasks are often posed as multiple-choice questions, allowing models to exploit systematic biases. Commonsense is also inherently probabilistic with multiple correct answers. The purpose of "boiling water" could be making tea and cooking, but it also could be killing germs. Existing tasks do not capture the probabilistic nature of common sense. To this end, we present commonsense frame completion (CFC), a new generative task that evaluates common sense via multiple open-ended generations. We also propose a method of probabilistic evaluation that strongly correlates with human judgments. Humans drastically outperform strong language model baselines on our dataset, indicating this approach is both a challenging and useful evaluation of machine common sense.
Mixture Model Framework for Traumatic Brain Injury Prognosis Using Heterogeneous Clinical and Outcome Data
Dec 22, 2020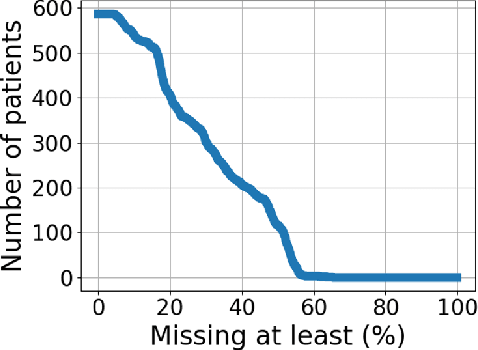
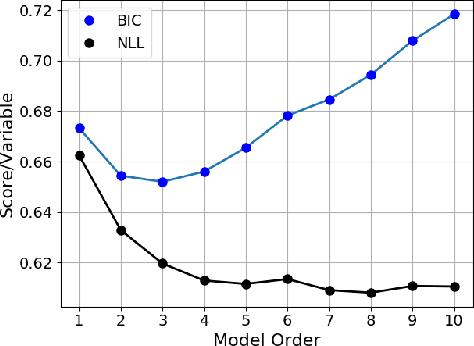
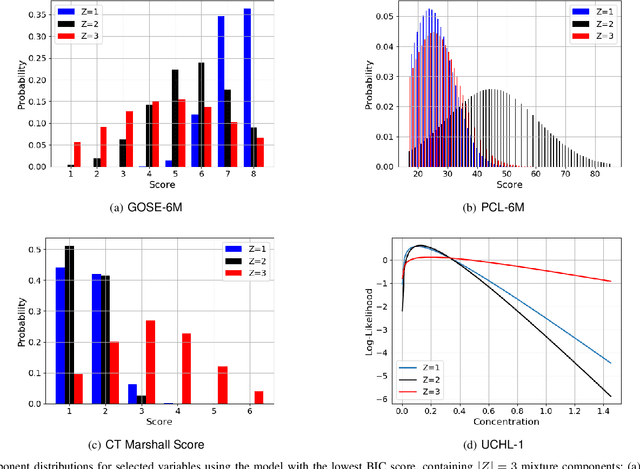
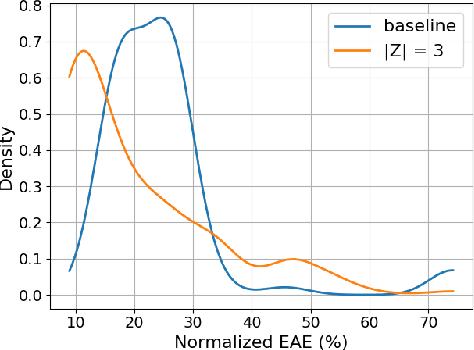
Prognoses of Traumatic Brain Injury (TBI) outcomes are neither easily nor accurately determined from clinical indicators. This is due in part to the heterogeneity of damage inflicted to the brain, ultimately resulting in diverse and complex outcomes. Using a data-driven approach on many distinct data elements may be necessary to describe this large set of outcomes and thereby robustly depict the nuanced differences among TBI patients' recovery. In this work, we develop a method for modeling large heterogeneous data types relevant to TBI. Our approach is geared toward the probabilistic representation of mixed continuous and discrete variables with missing values. The model is trained on a dataset encompassing a variety of data types, including demographics, blood-based biomarkers, and imaging findings. In addition, it includes a set of clinical outcome assessments at 3, 6, and 12 months post-injury. The model is used to stratify patients into distinct groups in an unsupervised learning setting. We use the model to infer outcomes using input data, and show that the collection of input data reduces uncertainty of outcomes over a baseline approach. In addition, we quantify the performance of a likelihood scoring technique that can be used to self-evaluate confidence in model fit and prediction.