 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKubric: A scalable dataset generator
Mar 07, 2022

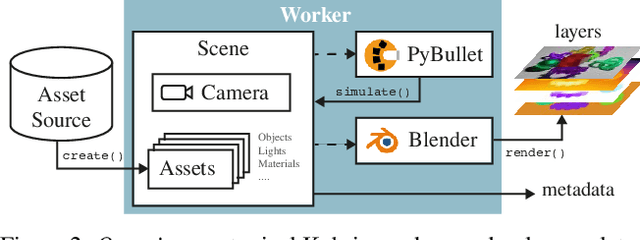
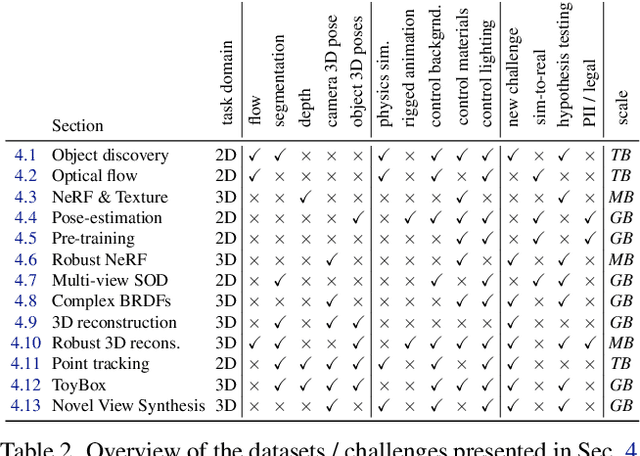
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Neural Dual Contouring
Feb 04, 2022
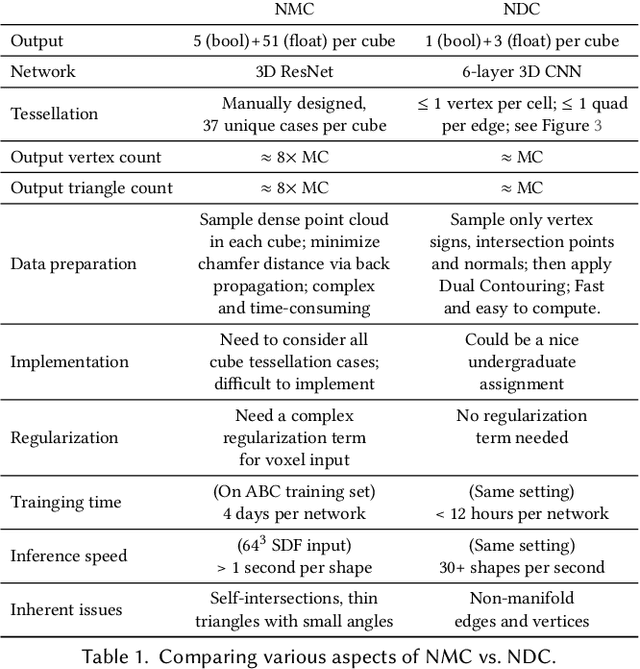
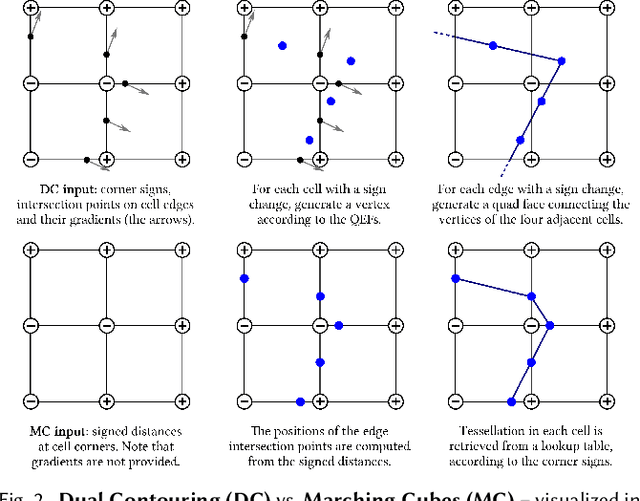
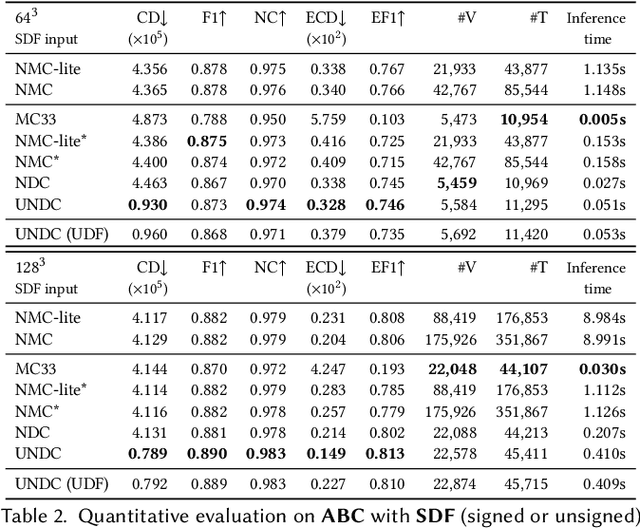
We introduce neural dual contouring (NDC), a new data-driven approach to mesh reconstruction based on dual contouring (DC). Like traditional DC, it produces exactly one vertex per grid cell and one quad for each grid edge intersection, a natural and efficient structure for reproducing sharp features. However, rather than computing vertex locations and edge crossings with hand-crafted functions that depend directly on difficult-to-obtain surface gradients, NDC uses a neural network to predict them. As a result, NDC can be trained to produce meshes from signed or unsigned distance fields, binary voxel grids, or point clouds (with or without normals); and it can produce open surfaces in cases where the input represents a sheet or partial surface. During experiments with five prominent datasets, we find that NDC, when trained on one of the datasets, generalizes well to the others. Furthermore, NDC provides better surface reconstruction accuracy, feature preservation, output complexity, triangle quality, and inference time in comparison to previous learned (e.g., neural marching cubes, convolutional occupancy networks) and traditional (e.g., Poisson) methods.
Neural Descriptor Fields: SE(3)-Equivariant Object Representations for Manipulation
Dec 09, 2021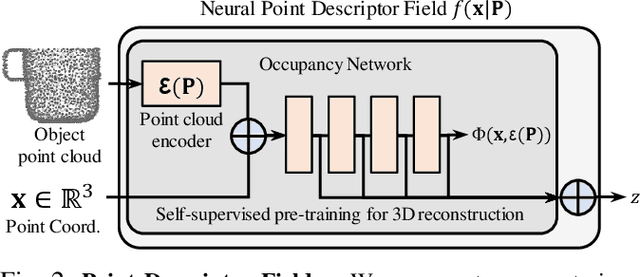
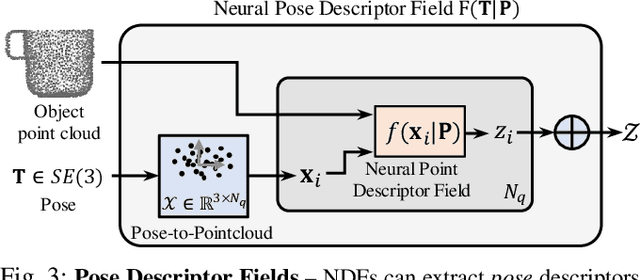
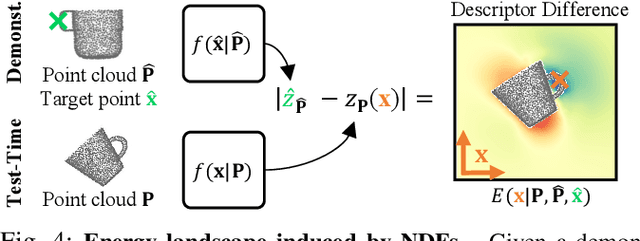
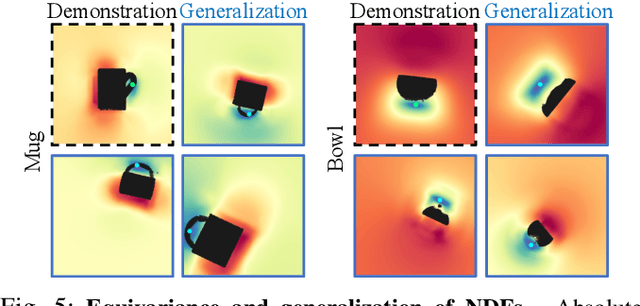
We present Neural Descriptor Fields (NDFs), an object representation that encodes both points and relative poses between an object and a target (such as a robot gripper or a rack used for hanging) via category-level descriptors. We employ this representation for object manipulation, where given a task demonstration, we want to repeat the same task on a new object instance from the same category. We propose to achieve this objective by searching (via optimization) for the pose whose descriptor matches that observed in the demonstration. NDFs are conveniently trained in a self-supervised fashion via a 3D auto-encoding task that does not rely on expert-labeled keypoints. Further, NDFs are SE(3)-equivariant, guaranteeing performance that generalizes across all possible 3D object translations and rotations. We demonstrate learning of manipulation tasks from few (5-10) demonstrations both in simulation and on a real robot. Our performance generalizes across both object instances and 6-DoF object poses, and significantly outperforms a recent baseline that relies on 2D descriptors. Project website: https://yilundu.github.io/ndf/.
CoNeRF: Controllable Neural Radiance Fields
Dec 06, 2021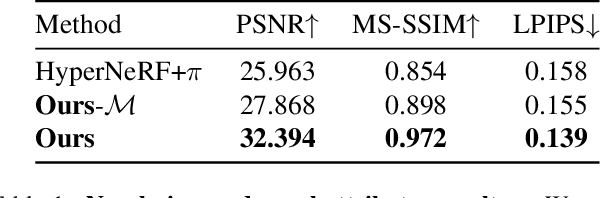

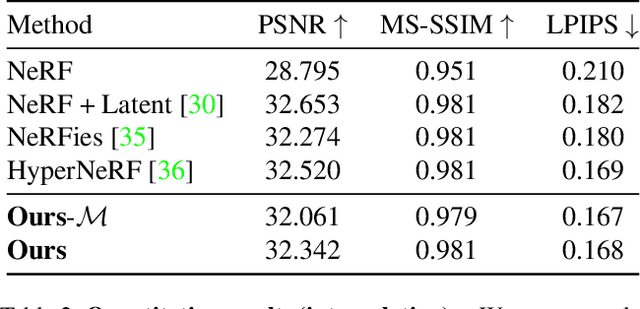

We extend neural 3D representations to allow for intuitive and interpretable user control beyond novel view rendering (i.e. camera control). We allow the user to annotate which part of the scene one wishes to control with just a small number of mask annotations in the training images. Our key idea is to treat the attributes as latent variables that are regressed by the neural network given the scene encoding. This leads to a few-shot learning framework, where attributes are discovered automatically by the framework, when annotations are not provided. We apply our method to various scenes with different types of controllable attributes (e.g. expression control on human faces, or state control in movement of inanimate objects). Overall, we demonstrate, to the best of our knowledge, for the first time novel view and novel attribute re-rendering of scenes from a single video.
NeSF: Neural Semantic Fields for Generalizable Semantic Segmentation of 3D Scenes
Dec 03, 2021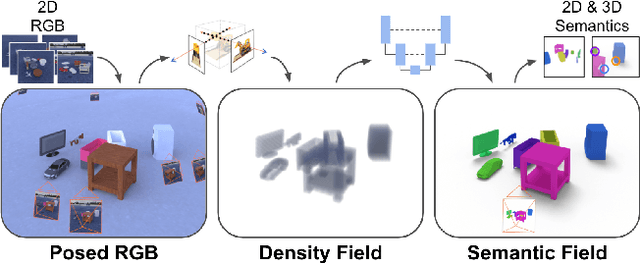
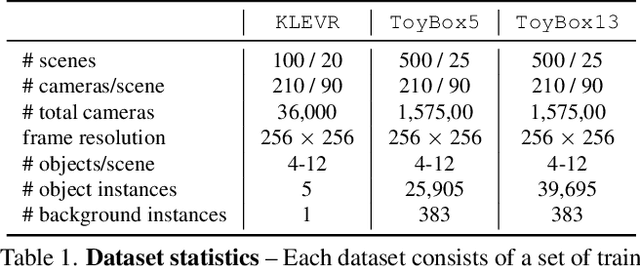

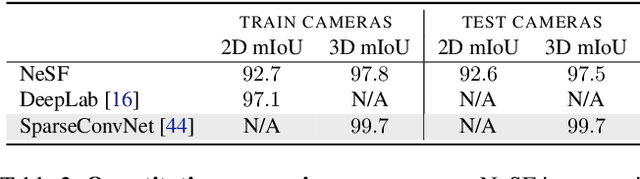
We present NeSF, a method for producing 3D semantic fields from posed RGB images alone. In place of classical 3D representations, our method builds on recent work in implicit neural scene representations wherein 3D structure is captured by point-wise functions. We leverage this methodology to recover 3D density fields upon which we then train a 3D semantic segmentation model supervised by posed 2D semantic maps. Despite being trained on 2D signals alone, our method is able to generate 3D-consistent semantic maps from novel camera poses and can be queried at arbitrary 3D points. Notably, NeSF is compatible with any method producing a density field, and its accuracy improves as the quality of the density field improves. Our empirical analysis demonstrates comparable quality to competitive 2D and 3D semantic segmentation baselines on complex, realistically rendered synthetic scenes. Our method is the first to offer truly dense 3D scene segmentations requiring only 2D supervision for training, and does not require any semantic input for inference on novel scenes. We encourage the readers to visit the project website.
Urban Radiance Fields
Nov 29, 2021
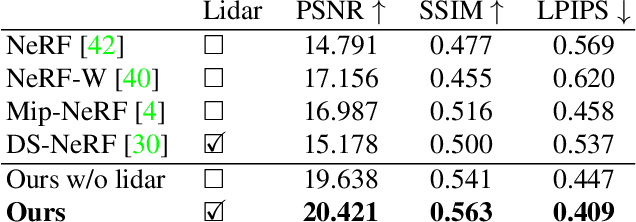


The goal of this work is to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., Street View). Given a sequence of posed RGB images and lidar sweeps acquired by cameras and scanners moving through an outdoor scene, we produce a model from which 3D surfaces can be extracted and novel RGB images can be synthesized. Our approach extends Neural Radiance Fields, which has been demonstrated to synthesize realistic novel images for small scenes in controlled settings, with new methods for leveraging asynchronously captured lidar data, for addressing exposure variation between captured images, and for leveraging predicted image segmentations to supervise densities on rays pointing at the sky. Each of these three extensions provides significant performance improvements in experiments on Street View data. Our system produces state-of-the-art 3D surface reconstructions and synthesizes higher quality novel views in comparison to both traditional methods (e.g.~COLMAP) and recent neural representations (e.g.~Mip-NeRF).
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 29, 2021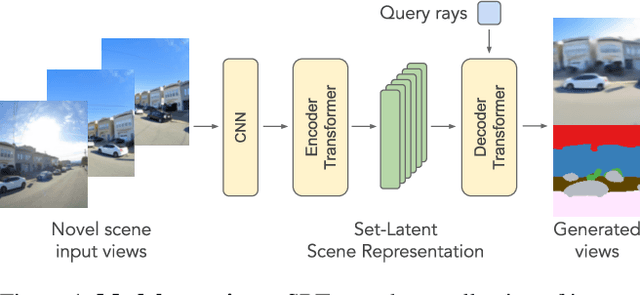

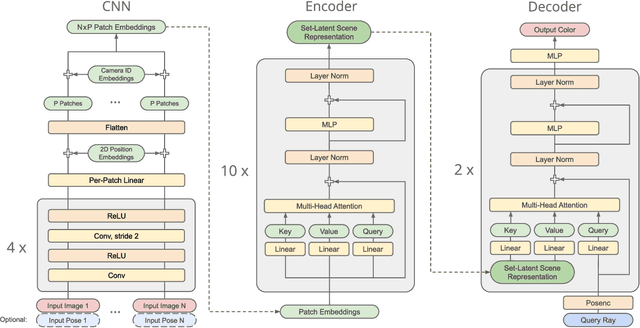
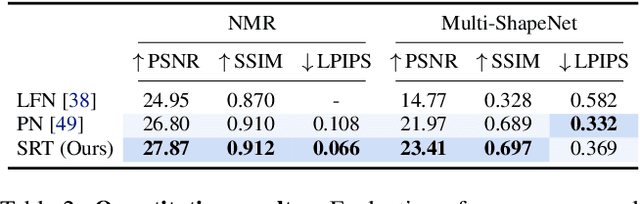
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
VaxNeRF: Revisiting the Classic for Voxel-Accelerated Neural Radiance Field
Nov 25, 2021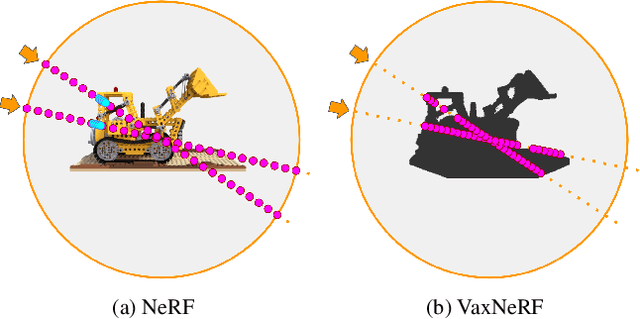
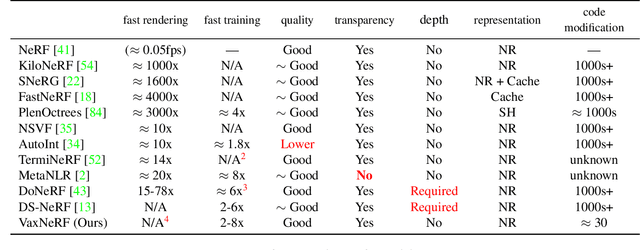

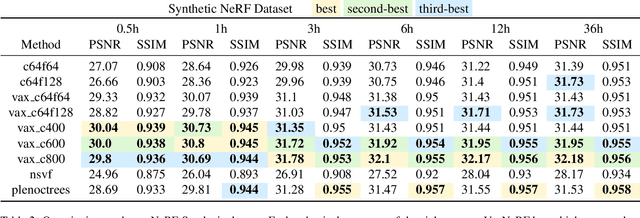
Neural Radiance Field (NeRF) is a popular method in data-driven 3D reconstruction. Given its simplicity and high quality rendering, many NeRF applications are being developed. However, NeRF's big limitation is its slow speed. Many attempts are made to speeding up NeRF training and inference, including intricate code-level optimization and caching, use of sophisticated data structures, and amortization through multi-task and meta learning. In this work, we revisit the basic building blocks of NeRF through the lens of classic techniques before NeRF. We propose Voxel-Accelearated NeRF (VaxNeRF), integrating NeRF with visual hull, a classic 3D reconstruction technique only requiring binary foreground-background pixel labels per image. Visual hull, which can be optimized in about 10 seconds, can provide coarse in-out field separation to omit substantial amounts of network evaluations in NeRF. We provide a clean fully-pythonic, JAX-based implementation on the popular JaxNeRF codebase, consisting of only about 30 lines of code changes and a modular visual hull subroutine, and achieve about 2-8x faster learning on top of the highly-performative JaxNeRF baseline with zero degradation in rendering quality. With sufficient compute, this effectively brings down full NeRF training from hours to 30 minutes. We hope VaxNeRF -- a careful combination of a classic technique with a deep method (that arguably replaced it) -- can empower and accelerate new NeRF extensions and applications, with its simplicity, portability, and reliable performance gains. Codes are available at https://github.com/naruya/VaxNeRF .
LOLNeRF: Learn from One Look
Nov 19, 2021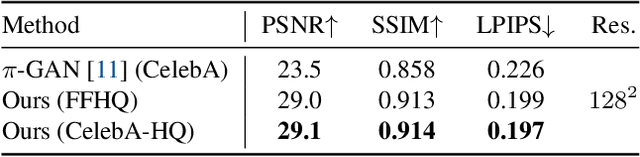
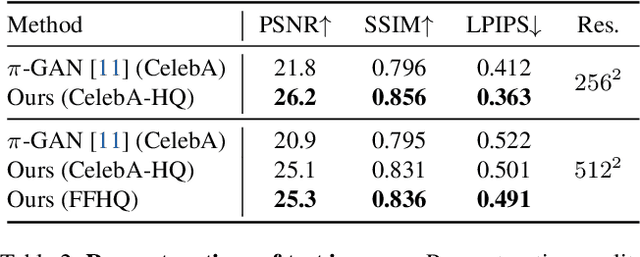

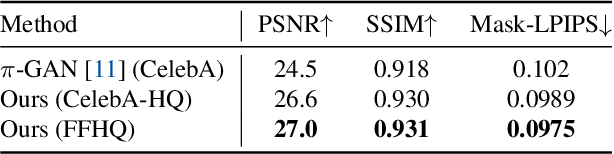
We present a method for learning a generative 3D model based on neural radiance fields, trained solely from data with only single views of each object. While generating realistic images is no longer a difficult task, producing the corresponding 3D structure such that they can be rendered from different views is non-trivial. We show that, unlike existing methods, one does not need multi-view data to achieve this goal. Specifically, we show that by reconstructing many images aligned to an approximate canonical pose with a single network conditioned on a shared latent space, you can learn a space of radiance fields that models shape and appearance for a class of objects. We demonstrate this by training models to reconstruct object categories using datasets that contain only one view of each subject without depth or geometry information. Our experiments show that we achieve state-of-the-art results in novel view synthesis and competitive results for monocular depth prediction.
MetaPose: Fast 3D Pose from Multiple Views without 3D Supervision
Aug 10, 2021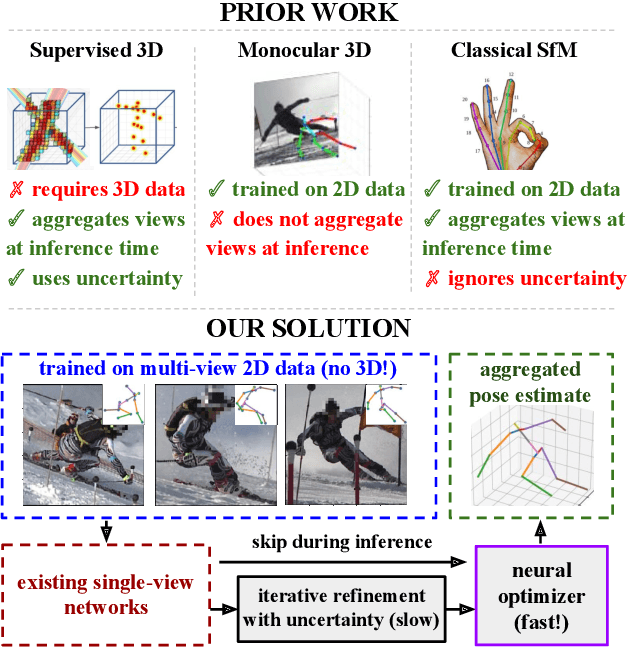
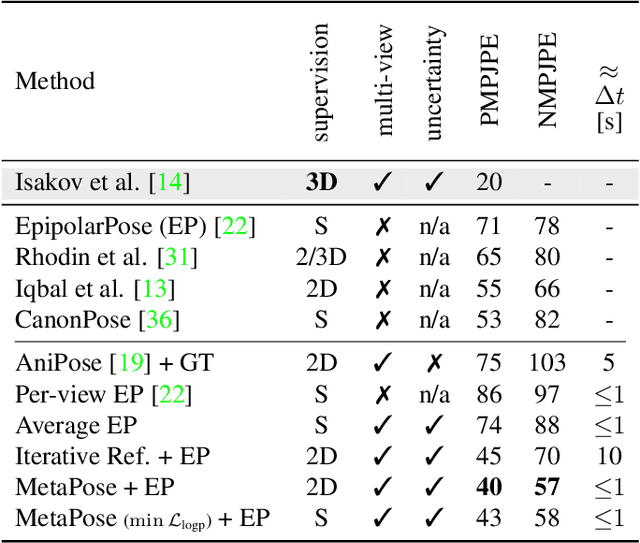
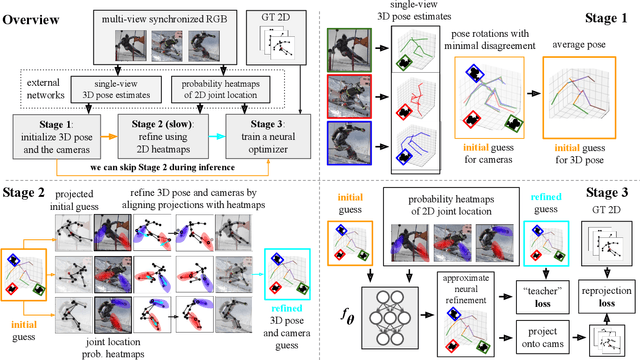
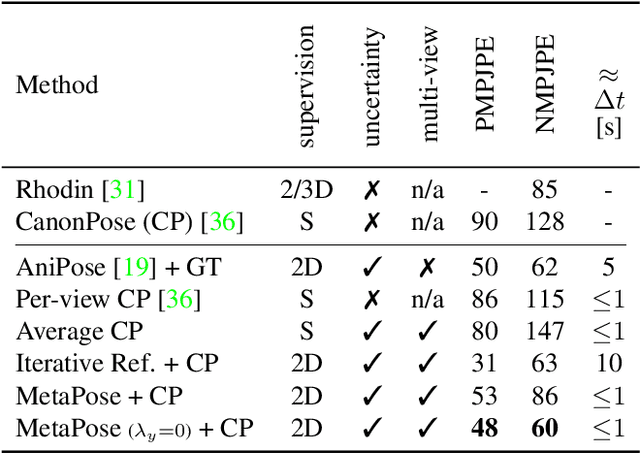
Recently, huge strides were made in monocular and multi-view pose estimation with known camera parameters, whereas pose estimation from multiple cameras with unknown positions and orientations received much less attention. In this paper, we show how to train a neural model that can perform accurate 3D pose and camera estimation, takes into account joint location uncertainty due occlusion from multiple views, and requires only 2D keypoint data for training. Our method outperforms both classical bundle adjustment and weakly-supervised monocular 3D baselines on the well-established Human3.6M dataset, as well as the more challenging in-the-wild Ski-Pose PTZ dataset with moving cameras. We provide an extensive ablation study separating the error due to the camera model, number of cameras, initialization, and image-space joint localization from the additional error introduced by our model.