 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extensible Interactive Interface for Agent Design
Jun 10, 2019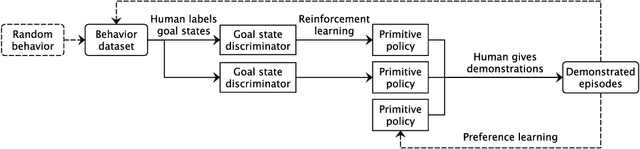
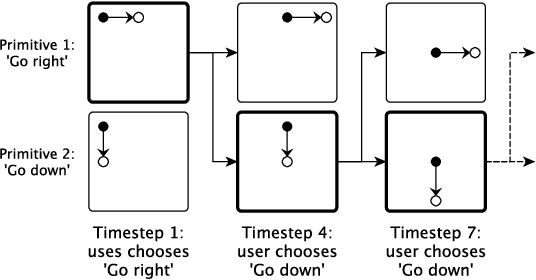
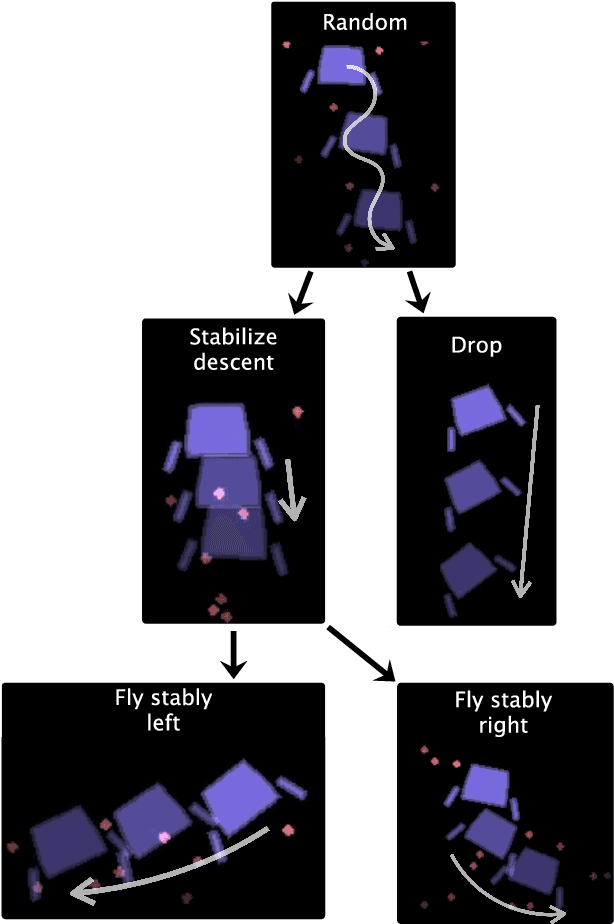
In artificial intelligence, we often specify tasks through a reward function. While this works well in some settings, many tasks are hard to specify this way. In deep reinforcement learning, for example, directly specifying a reward as a function of a high-dimensional observation is challenging. Instead, we present an interface for specifying tasks interactively using demonstrations. Our approach defines a set of increasingly complex policies. The interface allows the user to switch between these policies at fixed intervals to generate demonstrations of novel, more complex, tasks. We train new policies based on these demonstrations and repeat the process. We present a case study of our approach in the Lunar Lander domain, and show that this simple approach can quickly learn a successful landing policy and outperforms an existing comparison-based deep RL method.
Learning from Extrapolated Corrections
Mar 10, 2019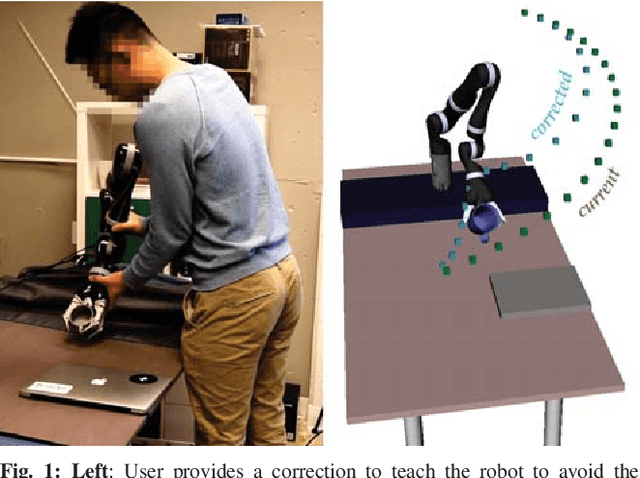
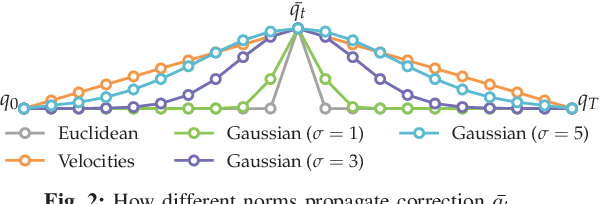
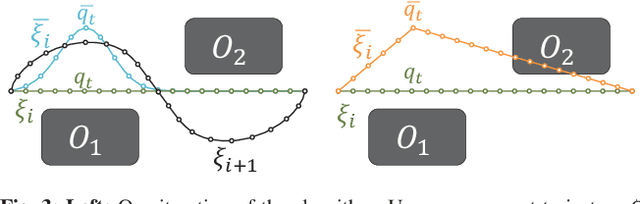
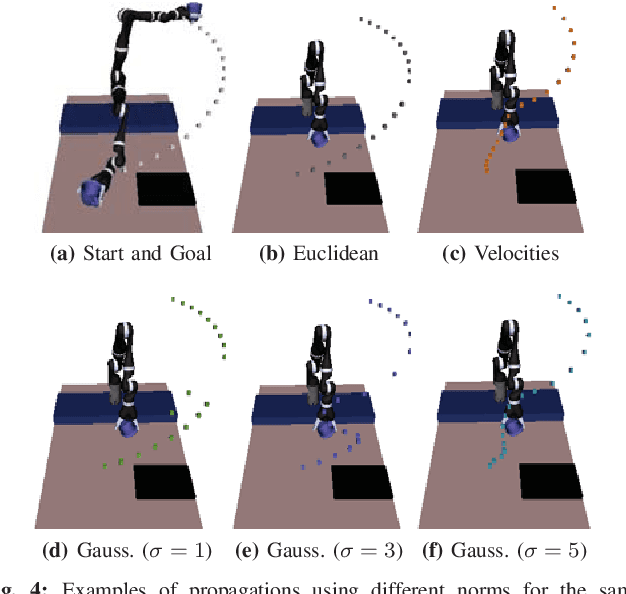
Our goal is to enable robots to learn cost functions from user guidance. Often it is difficult or impossible for users to provide full demonstrations, so corrections have emerged as an easier guidance channel. However, when robots learn cost functions from corrections rather than demonstrations, they have to extrapolate a small amount of information -- the change of a waypoint along the way -- to the rest of the trajectory. We cast this extrapolation problem as online function approximation, which exposes different ways in which the robot can interpret what trajectory the person intended, depending on the function space used for the approximation. Our simulation results and user study suggest that using function spaces with non-Euclidean norms can better capture what users intend, particularly if environments are uncluttered. This, in turn, can lead to the robot learning a more accurate cost function and improves the user's subjective perceptions of the robot.
Literal or Pedagogic Human? Analyzing Human Model Misspecification in Objective Learning
Mar 09, 2019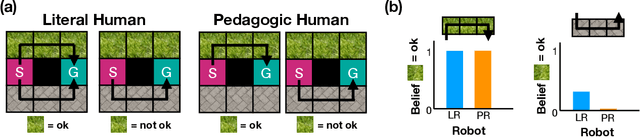
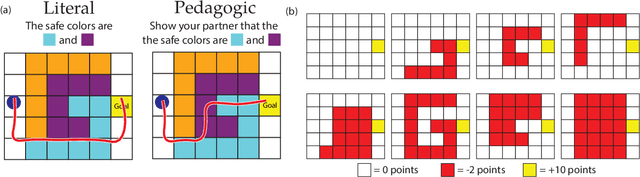
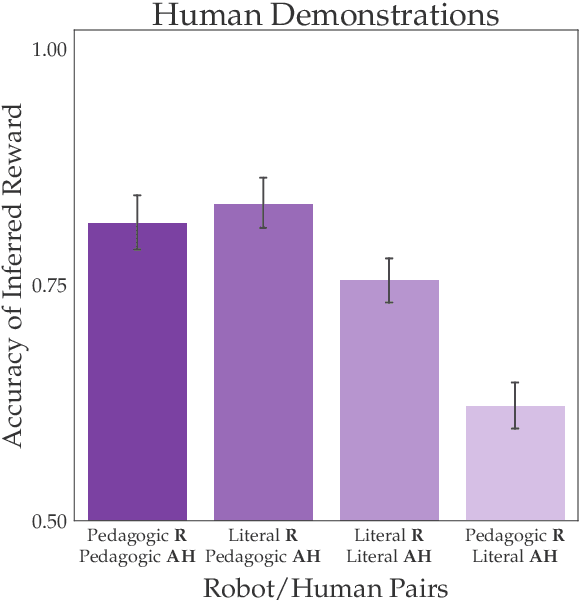
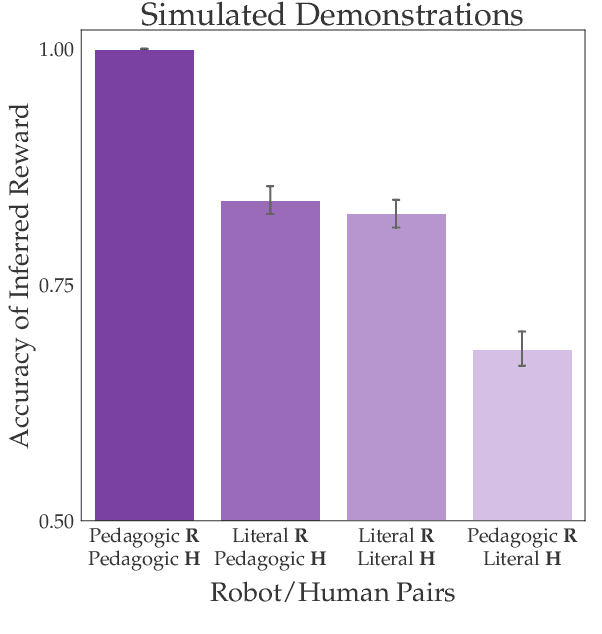
It is incredibly easy for a system designer to misspecify the objective for an autonomous system ("robot''), thus motivating the desire to have the robot learn the objective from human behavior instead. Recent work has suggested that people have an interest in the robot performing well, and will thus behave pedagogically, choosing actions that are informative to the robot. In turn, robots benefit from interpreting the behavior by accounting for this pedagogy. In this work, we focus on misspecification: we argue that robots might not know whether people are being pedagogic or literal and that it is important to ask which assumption is safer to make. We cast objective learning into the more general form of a common-payoff game between the robot and human, and prove that in any such game literal interpretation is more robust to misspecification. Experiments with human data support our theoretical results and point to the sensitivity of the pedagogic assumption.
Human-AI Learning Performance in Multi-Armed Bandits
Dec 21, 2018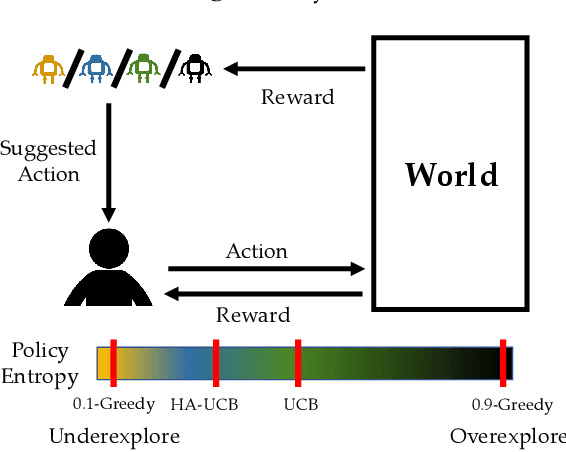
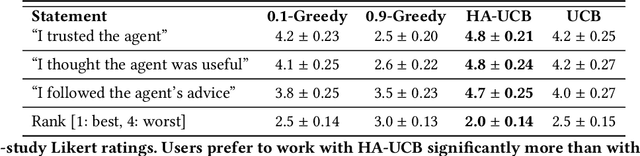
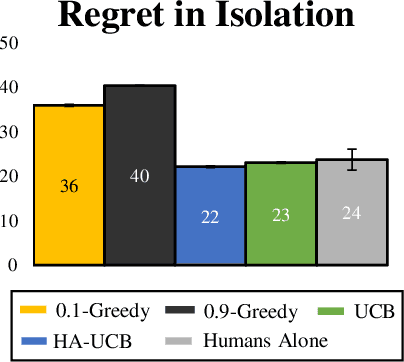
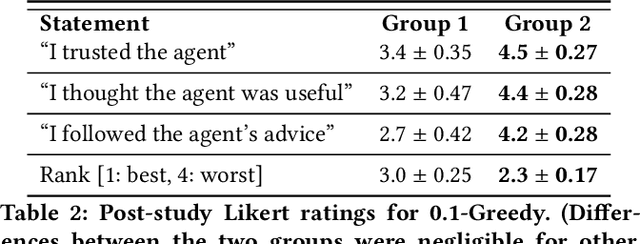
People frequently face challenging decision-making problems in which outcomes are uncertain or unknown. Artificial intelligence (AI) algorithms exist that can outperform humans at learning such tasks. Thus, there is an opportunity for AI agents to assist people in learning these tasks more effectively. In this work, we use a multi-armed bandit as a controlled setting in which to explore this direction. We pair humans with a selection of agents and observe how well each human-agent team performs. We find that team performance can beat both human and agent performance in isolation. Interestingly, we also find that an agent's performance in isolation does not necessarily correlate with the human-agent team's performance. A drop in agent performance can lead to a disproportionately large drop in team performance, or in some settings can even improve team performance. Pairing a human with an agent that performs slightly better than them can make them perform much better, while pairing them with an agent that performs the same can make them them perform much worse. Further, our results suggest that people have different exploration strategies and might perform better with agents that match their strategy. Overall, optimizing human-agent team performance requires going beyond optimizing agent performance, to understanding how the agent's suggestions will influence human decision-making.
A Scalable Framework For Real-Time Multi-Robot, Multi-Human Collision Avoidance
Nov 14, 2018
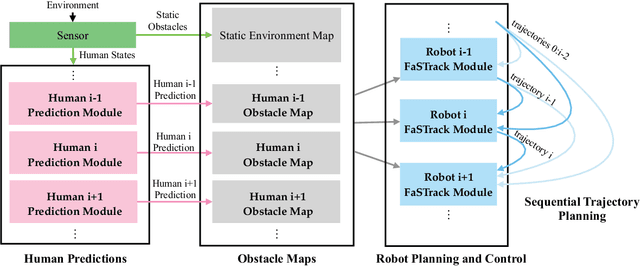
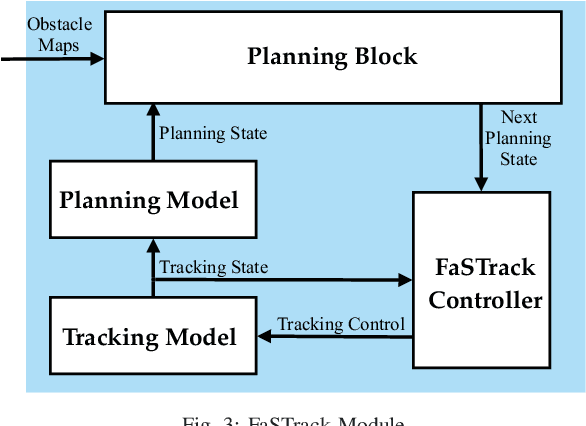
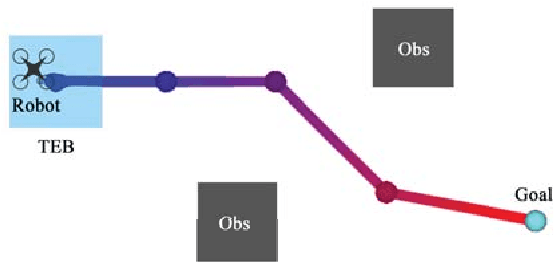
Robust motion planning is a well-studied problem in the robotics literature, yet current algorithms struggle to operate scalably and safely in the presence of other moving agents, such as humans. This paper introduces a novel framework for robot navigation that accounts for high-order system dynamics and maintains safety in the presence of external disturbances, other robots, and non-deterministic intentional agents. Our approach precomputes a tracking error margin for each robot, generates confidence-aware human motion predictions, and coordinates multiple robots with a sequential priority ordering, effectively enabling scalable safe trajectory planning and execution. We demonstrate our approach in hardware with two robots and two humans. We also showcase our work's scalability in a larger simulation.
Learning under Misspecified Objective Spaces
Oct 26, 2018

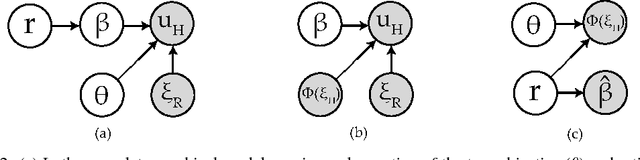
Learning robot objective functions from human input has become increasingly important, but state-of-the-art techniques assume that the human's desired objective lies within the robot's hypothesis space. When this is not true, even methods that keep track of uncertainty over the objective fail because they reason about which hypothesis might be correct, and not whether any of the hypotheses are correct. We focus specifically on learning from physical human corrections during the robot's task execution, where not having a rich enough hypothesis space leads to the robot updating its objective in ways that the person did not actually intend. We observe that such corrections appear irrelevant to the robot, because they are not the best way of achieving any of the candidate objectives. Instead of naively trusting and learning from every human interaction, we propose robots learn conservatively by reasoning in real time about how relevant the human's correction is for the robot's hypothesis space. We test our inference method in an experiment with human interaction data, and demonstrate that this alleviates unintended learning in an in-person user study with a 7DoF robot manipulator.
Where Do You Think You're Going?: Inferring Beliefs about Dynamics from Behavior
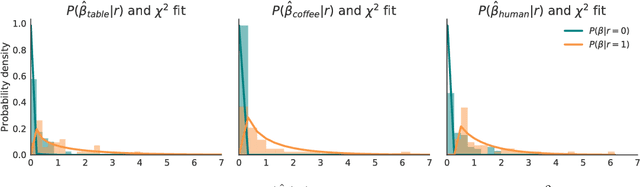
Oct 20, 2018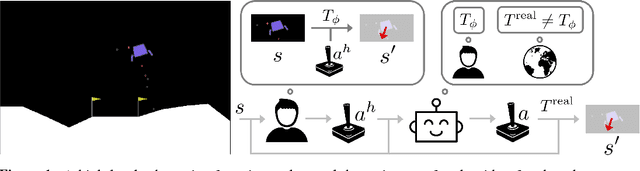

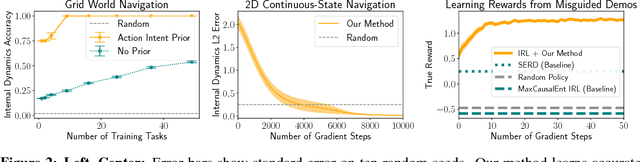
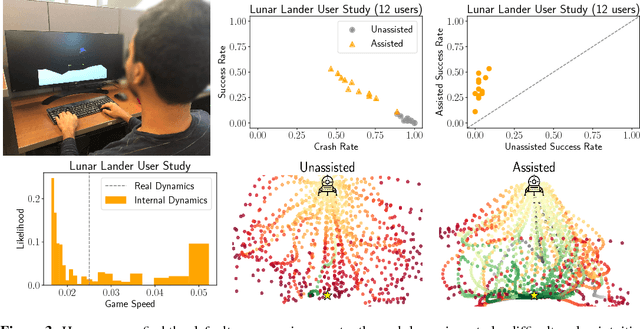
Inferring intent from observed behavior has been studied extensively within the frameworks of Bayesian inverse planning and inverse reinforcement learning. These methods infer a goal or reward function that best explains the actions of the observed agent, typically a human demonstrator. Another agent can use this inferred intent to predict, imitate, or assist the human user. However, a central assumption in inverse reinforcement learning is that the demonstrator is close to optimal. While models of suboptimal behavior exist, they typically assume that suboptimal actions are the result of some type of random noise or a known cognitive bias, like temporal inconsistency. In this paper, we take an alternative approach, and model suboptimal behavior as the result of internal model misspecification: the reason that user actions might deviate from near-optimal actions is that the user has an incorrect set of beliefs about the rules -- the dynamics -- governing how actions affect the environment. Our insight is that while demonstrated actions may be suboptimal in the real world, they may actually be near-optimal with respect to the user's internal model of the dynamics. By estimating these internal beliefs from observed behavior, we arrive at a new method for inferring intent. We demonstrate in simulation and in a user study with 12 participants that this approach enables us to more accurately model human intent, and can be used in a variety of applications, including offering assistance in a shared autonomy framework and inferring human preferences.
Enabling Robots to Communicate their Objectives
Oct 18, 2018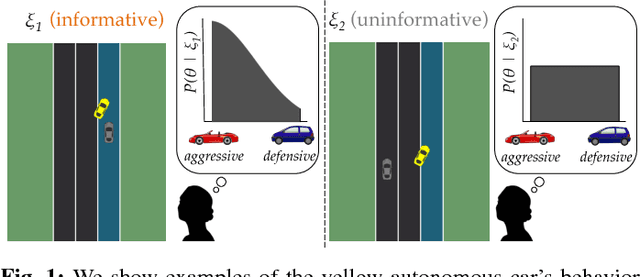

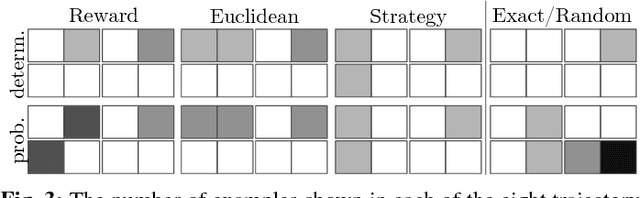
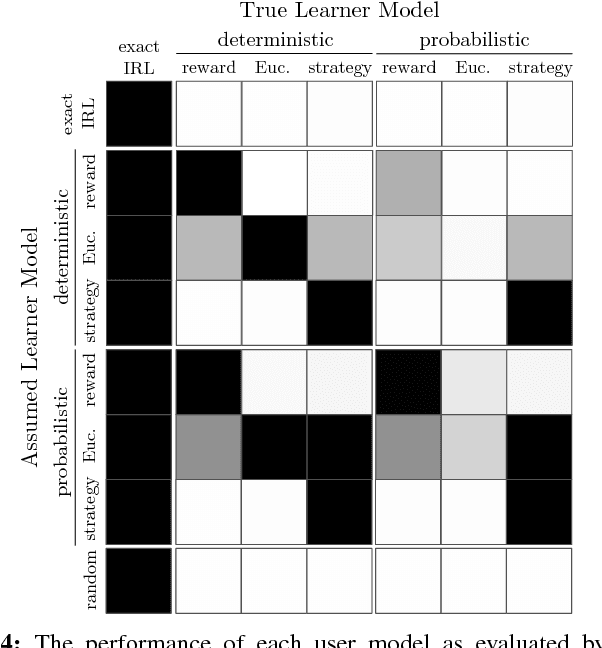
The overarching goal of this work is to efficiently enable end-users to correctly anticipate a robot's behavior in novel situations. Since a robot's behavior is often a direct result of its underlying objective function, our insight is that end-users need to have an accurate mental model of this objective function in order to understand and predict what the robot will do. While people naturally develop such a mental model over time through observing the robot act, this familiarization process may be lengthy. Our approach reduces this time by having the robot model how people infer objectives from observed behavior, and then it selects those behaviors that are maximally informative. The problem of computing a posterior over objectives from observed behavior is known as Inverse Reinforcement Learning (IRL), and has been applied to robots learning human objectives. We consider the problem where the roles of human and robot are swapped. Our main contribution is to recognize that unlike robots, humans will not be exact in their IRL inference. We thus introduce two factors to define candidate approximate-inference models for human learning in this setting, and analyze them in a user study in the autonomous driving domain. We show that certain approximate-inference models lead to the robot generating example behaviors that better enable users to anticipate what it will do in novel situations. Our results also suggest, however, that additional research is needed in modeling how humans extrapolate from examples of robot behavior.
Establishing Appropriate Trust via Critical States
Oct 18, 2018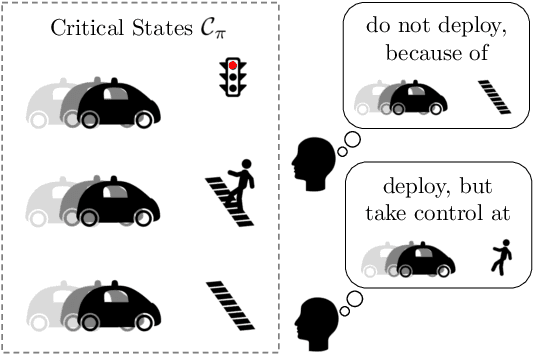
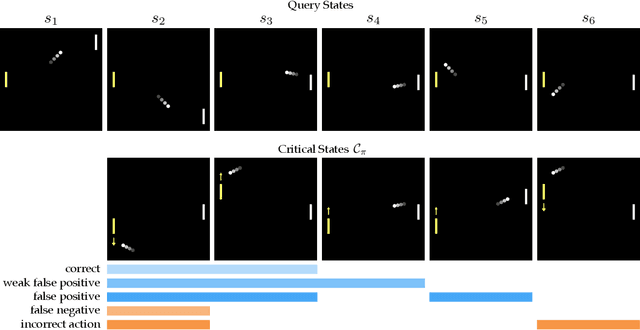
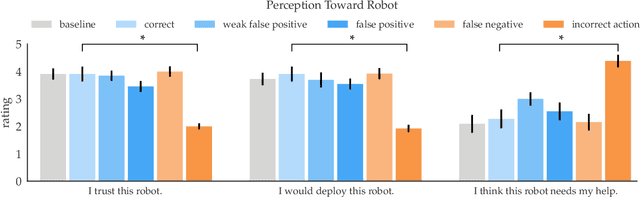
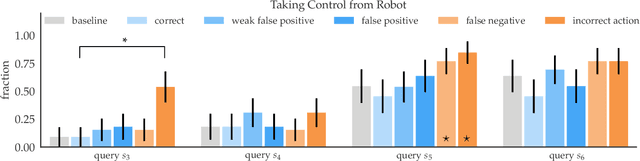
In order to effectively interact with or supervise a robot, humans need to have an accurate mental model of its capabilities and how it acts. Learned neural network policies make that particularly challenging. We propose an approach for helping end-users build a mental model of such policies. Our key observation is that for most tasks, the essence of the policy is captured in a few critical states: states in which it is very important to take a certain action. Our user studies show that if the robot shows a human what its understanding of the task's critical states is, then the human can make a more informed decision about whether to deploy the policy, and if she does deploy it, when she needs to take control from it at execution time.
Expressing Robot Incapability
Oct 18, 2018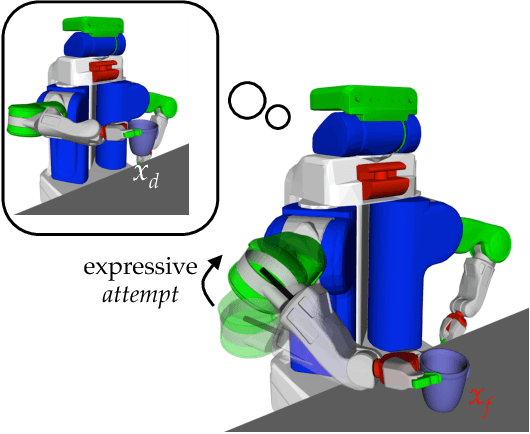
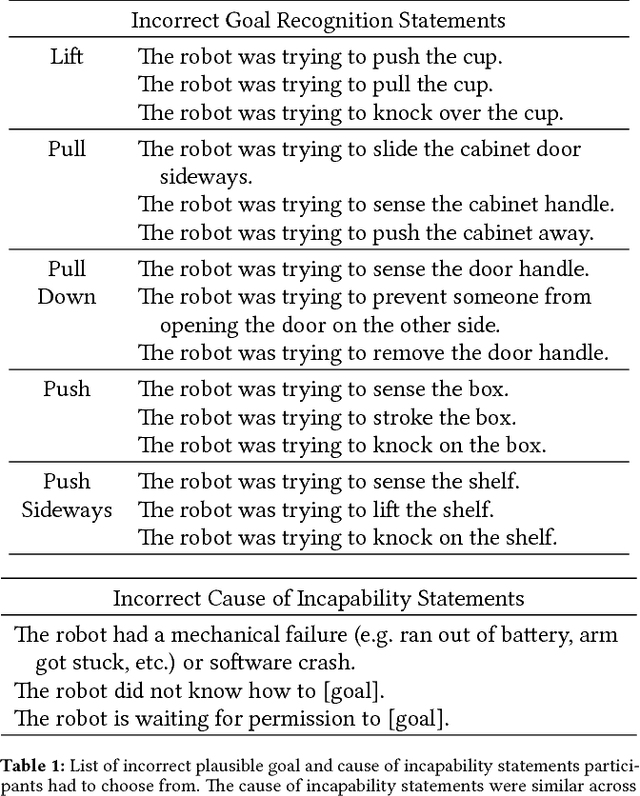
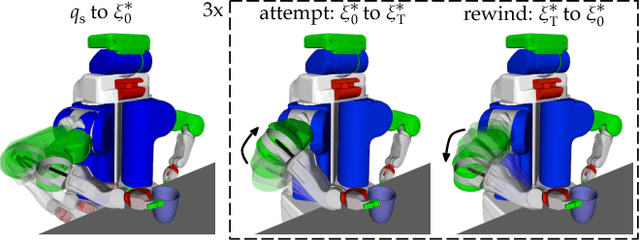
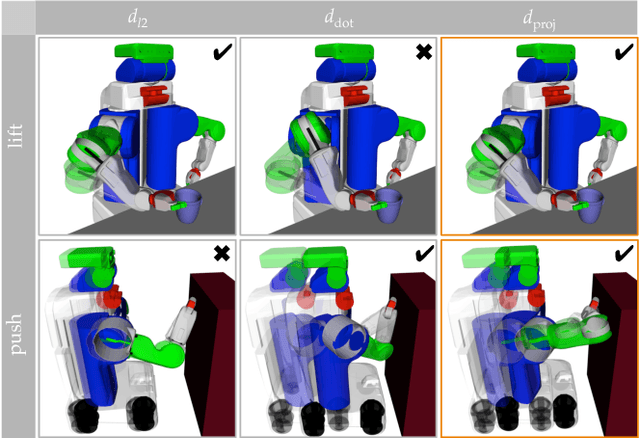
Our goal is to enable robots to express their incapability, and to do so in a way that communicates both what they are trying to accomplish and why they are unable to accomplish it. We frame this as a trajectory optimization problem: maximize the similarity between the motion expressing incapability and what would amount to successful task execution, while obeying the physical limits of the robot. We introduce and evaluate candidate similarity measures, and show that one in particular generalizes to a range of tasks, while producing expressive motions that are tailored to each task. Our user study supports that our approach automatically generates motions expressing incapability that communicate both what and why to end-users, and improve their overall perception of the robot and willingness to collaborate with it in the future.