 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Sampling in the Dual Divergence Space: A Data-efficient & Interpretative Approach for Generative AI
Apr 10, 2024



Building on the remarkable achievements in generative sampling of natural images, we propose an innovative challenge, potentially overly ambitious, which involves generating samples of entire multivariate time series that resemble images. However, the statistical challenge lies in the small sample size, sometimes consisting of a few hundred subjects. This issue is especially problematic for deep generative models that follow the conventional approach of generating samples from a canonical distribution and then decoding or denoising them to match the true data distribution. In contrast, our method is grounded in information theory and aims to implicitly characterize the distribution of images, particularly the (global and local) dependency structure between pixels. We achieve this by empirically estimating its KL-divergence in the dual form with respect to the respective marginal distribution. This enables us to perform generative sampling directly in the optimized 1-D dual divergence space. Specifically, in the dual space, training samples representing the data distribution are embedded in the form of various clusters between two end points. In theory, any sample embedded between those two end points is in-distribution w.r.t. the data distribution. Our key idea for generating novel samples of images is to interpolate between the clusters via a walk as per gradients of the dual function w.r.t. the data dimensions. In addition to the data efficiency gained from direct sampling, we propose an algorithm that offers a significant reduction in sample complexity for estimating the divergence of the data distribution with respect to the marginal distribution. We provide strong theoretical guarantees along with an extensive empirical evaluation using many real-world datasets from diverse domains, establishing the superiority of our approach w.r.t. state-of-the-art deep learning methods.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024



Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.
Ranking Large Language Models without Ground Truth
Feb 21, 2024



Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
Trust Regions for Explanations via Black-Box Probabilistic Certification
Feb 21, 2024



Given the black box nature of machine learning models, a plethora of explainability methods have been developed to decipher the factors behind individual decisions. In this paper, we introduce a novel problem of black box (probabilistic) explanation certification. We ask the question: Given a black box model with only query access, an explanation for an example and a quality metric (viz. fidelity, stability), can we find the largest hypercube (i.e., $\ell_{\infty}$ ball) centered at the example such that when the explanation is applied to all examples within the hypercube, (with high probability) a quality criterion is met (viz. fidelity greater than some value)? Being able to efficiently find such a \emph{trust region} has multiple benefits: i) insight into model behavior in a \emph{region}, with a \emph{guarantee}; ii) ascertained \emph{stability} of the explanation; iii) \emph{explanation reuse}, which can save time, energy and money by not having to find explanations for every example; and iv) a possible \emph{meta-metric} to compare explanation methods. Our contributions include formalizing this problem, proposing solutions, providing theoretical guarantees for these solutions that are computable, and experimentally showing their efficacy on synthetic and real data.
Spectral Adversarial MixUp for Few-Shot Unsupervised Domain Adaptation
Sep 03, 2023Domain shift is a common problem in clinical applications, where the training images (source domain) and the test images (target domain) are under different distributions. Unsupervised Domain Adaptation (UDA) techniques have been proposed to adapt models trained in the source domain to the target domain. However, those methods require a large number of images from the target domain for model training. In this paper, we propose a novel method for Few-Shot Unsupervised Domain Adaptation (FSUDA), where only a limited number of unlabeled target domain samples are available for training. To accomplish this challenging task, first, a spectral sensitivity map is introduced to characterize the generalization weaknesses of models in the frequency domain. We then developed a Sensitivity-guided Spectral Adversarial MixUp (SAMix) method to generate target-style images to effectively suppresses the model sensitivity, which leads to improved model generalizability in the target domain. We demonstrated the proposed method and rigorously evaluated its performance on multiple tasks using several public datasets.
When Neural Networks Fail to Generalize? A Model Sensitivity Perspective
Dec 01, 2022Domain generalization (DG) aims to train a model to perform well in unseen domains under different distributions. This paper considers a more realistic yet more challenging scenario,namely Single Domain Generalization (Single-DG), where only a single source domain is available for training. To tackle this challenge, we first try to understand when neural networks fail to generalize? We empirically ascertain a property of a model that correlates strongly with its generalization that we coin as "model sensitivity". Based on our analysis, we propose a novel strategy of Spectral Adversarial Data Augmentation (SADA) to generate augmented images targeted at the highly sensitive frequencies. Models trained with these hard-to-learn samples can effectively suppress the sensitivity in the frequency space, which leads to improved generalization performance. Extensive experiments on multiple public datasets demonstrate the superiority of our approach, which surpasses the state-of-the-art single-DG methods.
On the Safety of Interpretable Machine Learning: A Maximum Deviation Approach
Nov 02, 2022



Interpretable and explainable machine learning has seen a recent surge of interest. We focus on safety as a key motivation behind the surge and make the relationship between interpretability and safety more quantitative. Toward assessing safety, we introduce the concept of maximum deviation via an optimization problem to find the largest deviation of a supervised learning model from a reference model regarded as safe. We then show how interpretability facilitates this safety assessment. For models including decision trees, generalized linear and additive models, the maximum deviation can be computed exactly and efficiently. For tree ensembles, which are not regarded as interpretable, discrete optimization techniques can still provide informative bounds. For a broader class of piecewise Lipschitz functions, we leverage the multi-armed bandit literature to show that interpretability produces tighter (regret) bounds on the maximum deviation. We present case studies, including one on mortgage approval, to illustrate our methods and the insights about models that may be obtained from deviation maximization.
PainPoints: A Framework for Language-based Detection of Chronic Pain and Expert-Collaborative Text-Summarization
Sep 14, 2022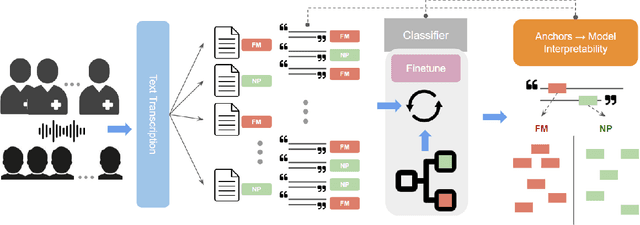

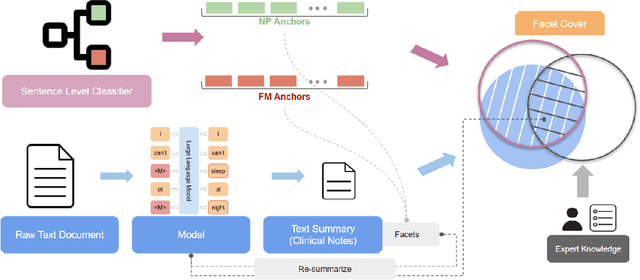
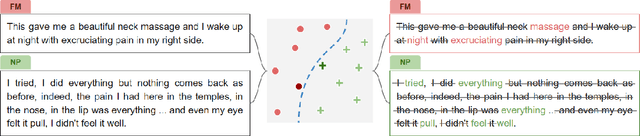
Chronic pain is a pervasive disorder which is often very disabling and is associated with comorbidities such as depression and anxiety. Neuropathic Pain (NP) is a common sub-type which is often caused due to nerve damage and has a known pathophysiology. Another common sub-type is Fibromyalgia (FM) which is described as musculoskeletal, diffuse pain that is widespread through the body. The pathophysiology of FM is poorly understood, making it very hard to diagnose. Standard medications and treatments for FM and NP differ from one another and if misdiagnosed it can cause an increase in symptom severity. To overcome this difficulty, we propose a novel framework, PainPoints, which accurately detects the sub-type of pain and generates clinical notes via summarizing the patient interviews. Specifically, PainPoints makes use of large language models to perform sentence-level classification of the text obtained from interviews of FM and NP patients with a reliable AUC of 0.83. Using a sufficiency-based interpretability approach, we explain how the fine-tuned model accurately picks up on the nuances that patients use to describe their pain. Finally, we generate summaries of these interviews via expert interventions by introducing a novel facet-based approach. PainPoints thus enables practitioners to add/drop facets and generate a custom summary based on the notion of "facet-coverage" which is also introduced in this work.
Atomist or Holist? A Diagnosis and Vision for More Productive Interdisciplinary AI Ethics Dialogue
Sep 01, 2022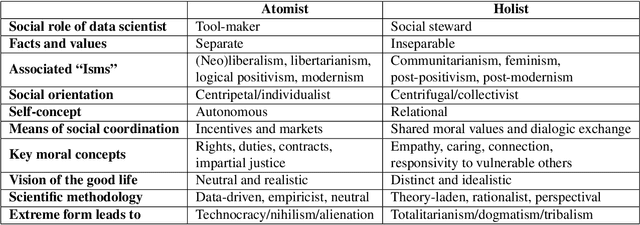
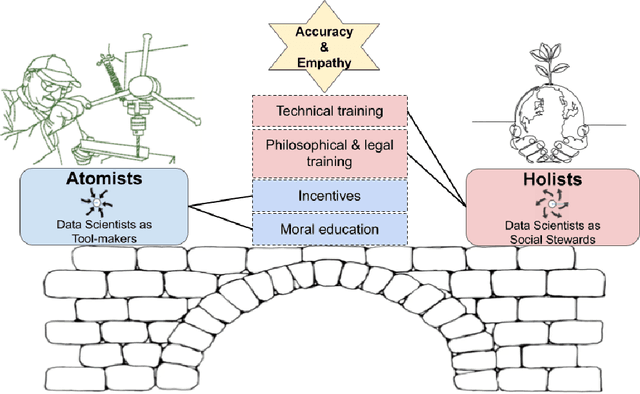
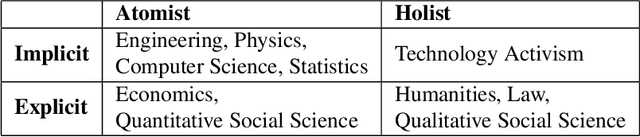
In response to growing recognition of the social, legal, and ethical impacts of new AI-based technologies, major AI and ML conferences and journals now encourage or require submitted papers to include ethics impact statements and undergo ethics reviews. This move has sparked heated debate concerning the role of ethics in AI and data science research, at times devolving into counter-productive name-calling and threats of "cancellation." We diagnose this deep ideological conflict as one between atomists and holists. Among other things, atomists espouse the idea that facts are and should be kept separate from values, while holists believe facts and values are and should be inextricable from one another. With the goals of encouraging civil discourse across disciplines and reducing disciplinary polarization, we draw on a variety of historical sources ranging from philosophy and law, to social theory and humanistic psychology, to describe each ideology's beliefs and assumptions. Finally, we call on atomists and holists within the data science community to exhibit greater empathy during ethical disagreements and propose four targeted strategies to ensure data science research benefits society.
Anomaly Attribution with Likelihood Compensation
Aug 23, 2022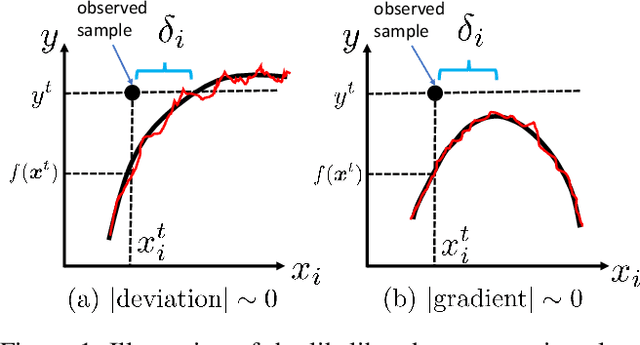
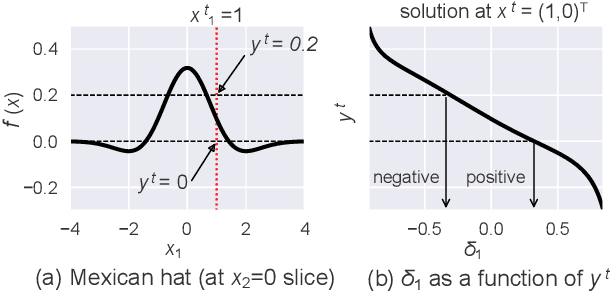
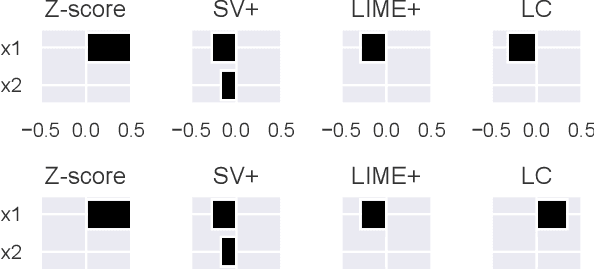
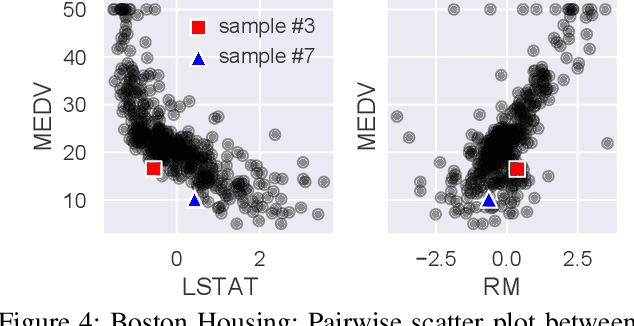
This paper addresses the task of explaining anomalous predictions of a black-box regression model. When using a black-box model, such as one to predict building energy consumption from many sensor measurements, we often have a situation where some observed samples may significantly deviate from their prediction. It may be due to a sub-optimal black-box model, or simply because those samples are outliers. In either case, one would ideally want to compute a ``responsibility score'' indicative of the extent to which an input variable is responsible for the anomalous output. In this work, we formalize this task as a statistical inverse problem: Given model deviation from the expected value, infer the responsibility score of each of the input variables. We propose a new method called likelihood compensation (LC), which is founded on the likelihood principle and computes a correction to each input variable. To the best of our knowledge, this is the first principled framework that computes a responsibility score for real valued anomalous model deviations. We apply our approach to a real-world building energy prediction task and confirm its utility based on expert feedback.