 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Field Guide to Federated Optimization
Jul 14, 2021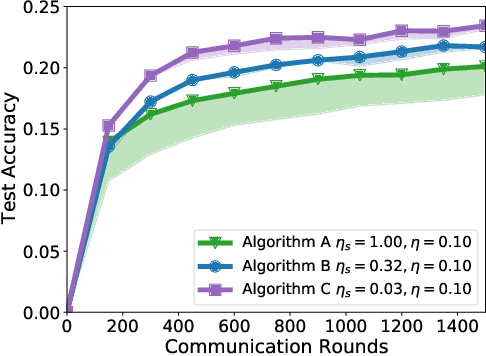


Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Federated Hyperparameter Tuning: Challenges, Baselines, and Connections to Weight-Sharing
Jun 08, 2021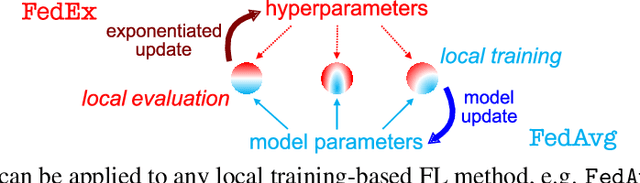
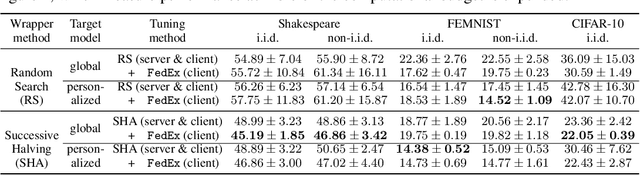
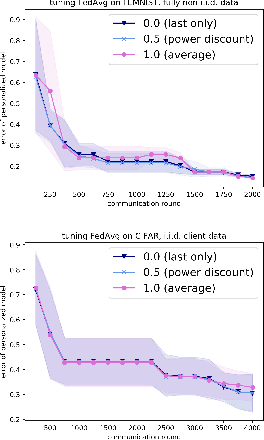

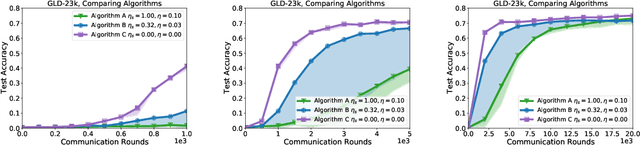
Tuning hyperparameters is a crucial but arduous part of the machine learning pipeline. Hyperparameter optimization is even more challenging in federated learning, where models are learned over a distributed network of heterogeneous devices; here, the need to keep data on device and perform local training makes it difficult to efficiently train and evaluate configurations. In this work, we investigate the problem of federated hyperparameter tuning. We first identify key challenges and show how standard approaches may be adapted to form baselines for the federated setting. Then, by making a novel connection to the neural architecture search technique of weight-sharing, we introduce a new method, FedEx, to accelerate federated hyperparameter tuning that is applicable to widely-used federated optimization methods such as FedAvg and recent variants. Theoretically, we show that a FedEx variant correctly tunes the on-device learning rate in the setting of online convex optimization across devices. Empirically, we show that FedEx can outperform natural baselines for federated hyperparameter tuning by several percentage points on the Shakespeare, FEMNIST, and CIFAR-10 benchmarks, obtaining higher accuracy using the same training budget.
Finding and Fixing Spurious Patterns with Explanations
Jun 03, 2021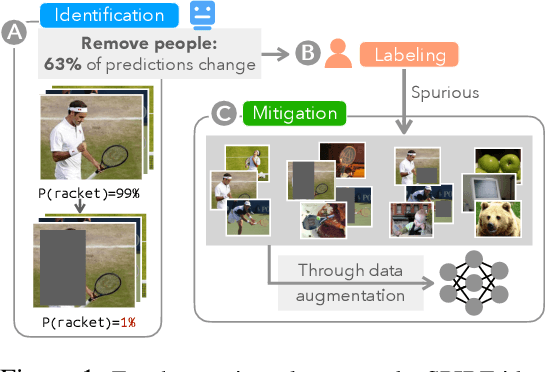

Machine learning models often use spurious patterns such as "relying on the presence of a person to detect a tennis racket," which do not generalize. In this work, we present an end-to-end pipeline for identifying and mitigating spurious patterns for image classifiers. We start by finding patterns such as "the model's prediction for tennis racket changes 63% of the time if we hide the people." Then, if a pattern is spurious, we mitigate it via a novel form of data augmentation. We demonstrate that this approach identifies a diverse set of spurious patterns and that it mitigates them by producing a model that is both more accurate on a distribution where the spurious pattern is not helpful and more robust to distribution shift.
Sanity Simulations for Saliency Methods
May 13, 2021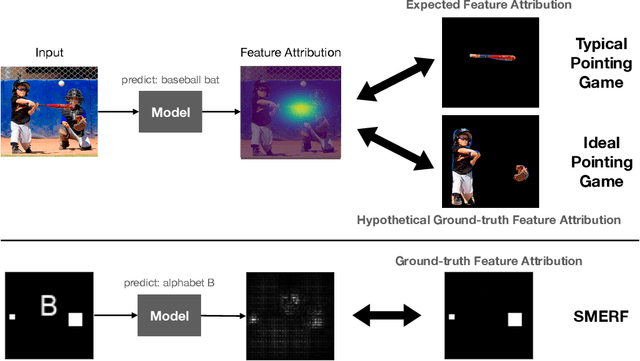
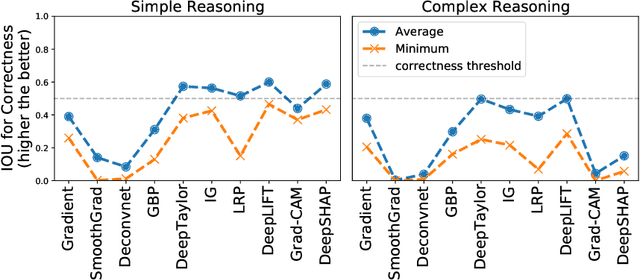
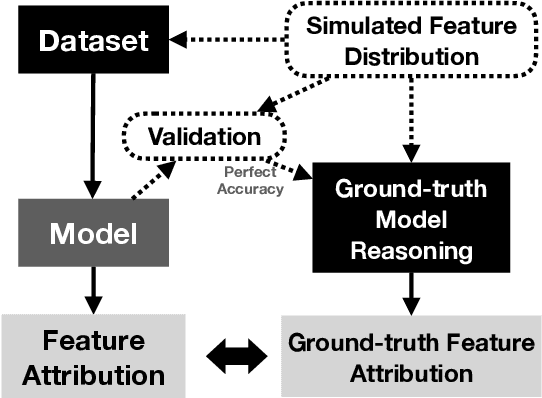
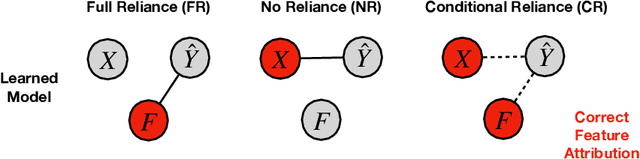
Saliency methods are a popular class of feature attribution tools that aim to capture a model's predictive reasoning by identifying "important" pixels in an input image. However, the development and adoption of saliency methods are currently hindered by the lack of access to underlying model reasoning, which prevents accurate method evaluation. In this work, we design a synthetic evaluation framework, SMERF, that allows us to perform ground-truth-based evaluation of saliency methods while controlling the underlying complexity of model reasoning. Experimental evaluations via SMERF reveal significant limitations in existing saliency methods, especially given the relative simplicity of SMERF's synthetic evaluation tasks. Moreover, the SMERF benchmarking suite represents a useful tool in the development of new saliency methods to potentially overcome these limitations.
Rethinking Neural Operations for Diverse Tasks
Mar 29, 2021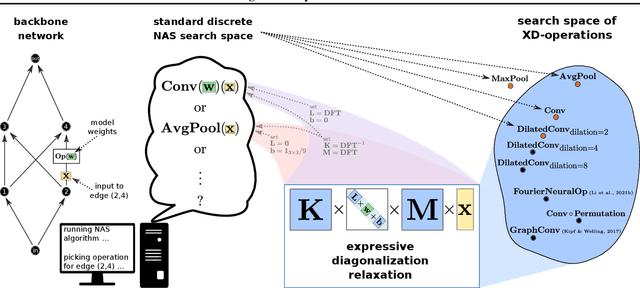
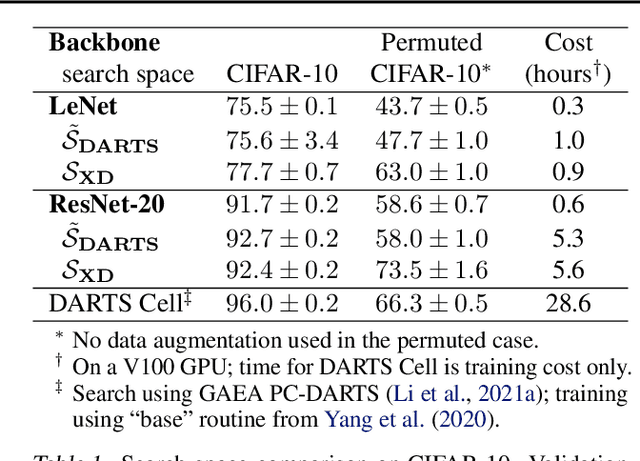
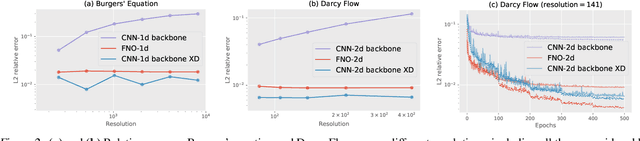

An important goal of neural architecture search (NAS) is to automate-away the design of neural networks on new tasks in under-explored domains. Motivated by this broader vision for NAS, we study the problem of enabling users to discover the right neural operations given data from their specific domain. We introduce a search space of neural operations called XD-Operations that mimic the inductive bias of standard multichannel convolutions while being much more expressive: we prove that XD-operations include many named operations across several application areas. Starting with any standard backbone network such as LeNet or ResNet, we show how to transform it into an architecture search space over XD-operations and how to traverse the space using a simple weight-sharing scheme. On a diverse set of applications--image classification, solving partial differential equations (PDEs), and sequence modeling--our approach consistently yields models with lower error than baseline networks and sometimes even lower error than expert-designed domain-specific approaches.
Towards Connecting Use Cases and Methods in Interpretable Machine Learning
Mar 10, 2021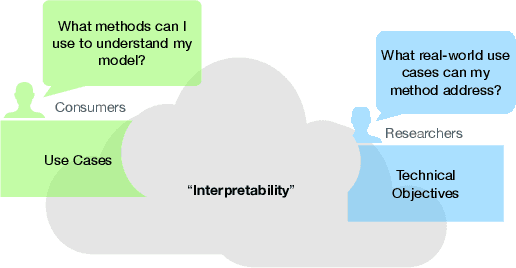

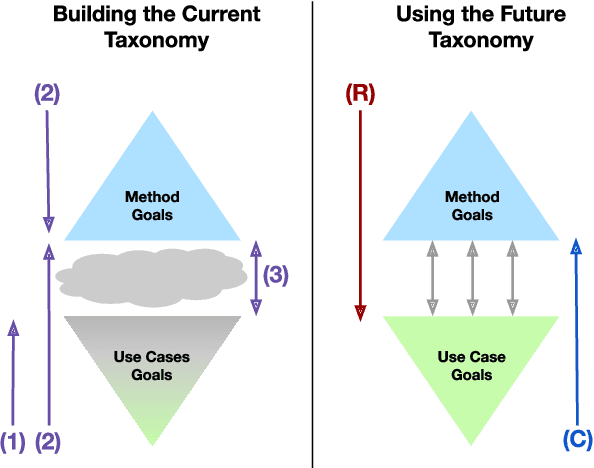
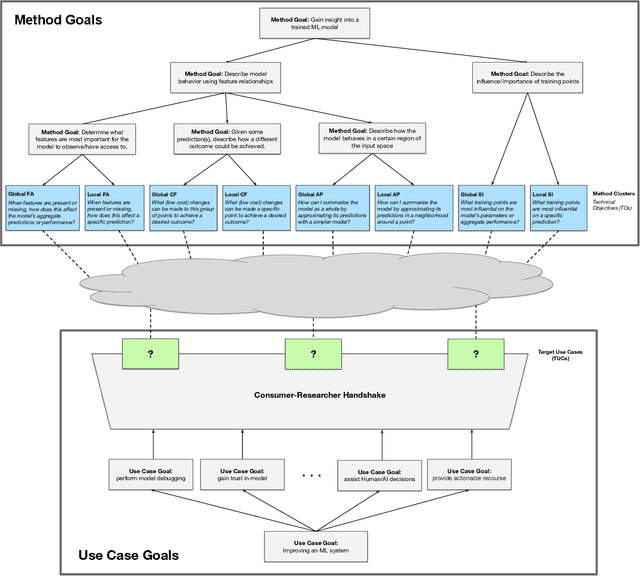
Despite increasing interest in the field of Interpretable Machine Learning (IML), a significant gap persists between the technical objectives targeted by researchers' methods and the high-level goals of consumers' use cases. In this work, we synthesize foundational work on IML methods and evaluation into an actionable taxonomy. This taxonomy serves as a tool to conceptualize the gap between researchers and consumers, illustrated by the lack of connections between its methods and use cases components. It also provides the foundation from which we describe a three-step workflow to better enable researchers and consumers to work together to discover what types of methods are useful for what use cases. Eventually, by building on the results generated from this workflow, a more complete version of the taxonomy will increasingly allow consumers to find relevant methods for their target use cases and researchers to identify applicable use cases for their proposed methods.
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
Feb 26, 2021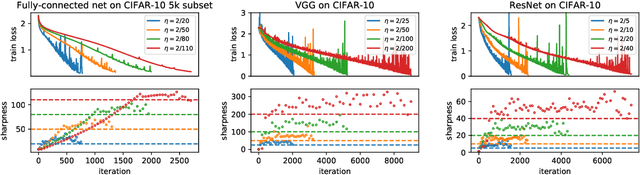
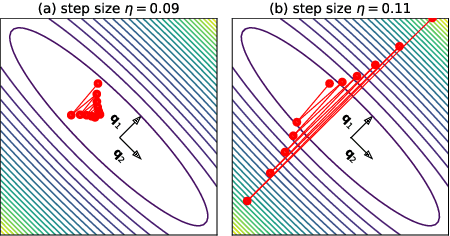

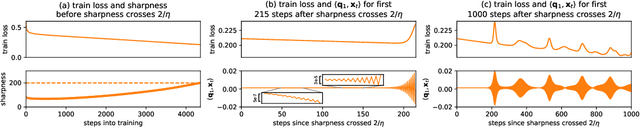
We empirically demonstrate that full-batch gradient descent on neural network training objectives typically operates in a regime we call the Edge of Stability. In this regime, the maximum eigenvalue of the training loss Hessian hovers just above the numerical value $2 / \text{(step size)}$, and the training loss behaves non-monotonically over short timescales, yet consistently decreases over long timescales. Since this behavior is inconsistent with several widespread presumptions in the field of optimization, our findings raise questions as to whether these presumptions are relevant to neural network training. We hope that our findings will inspire future efforts aimed at rigorously understanding optimization at the Edge of Stability. Code is available at https://github.com/locuslab/edge-of-stability.
On Data Efficiency of Meta-learning
Jan 30, 2021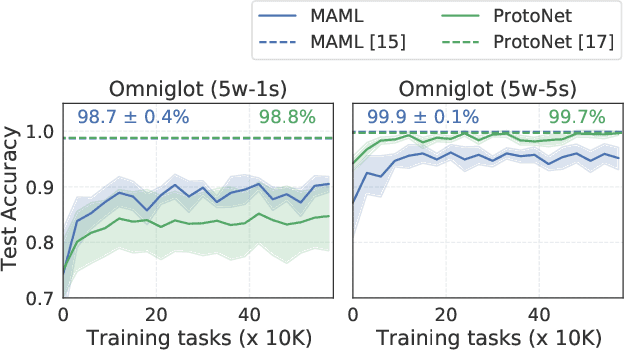
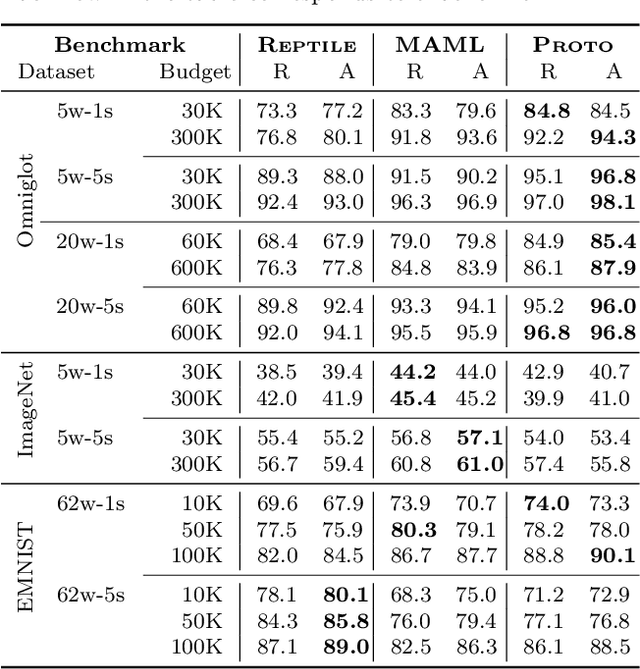

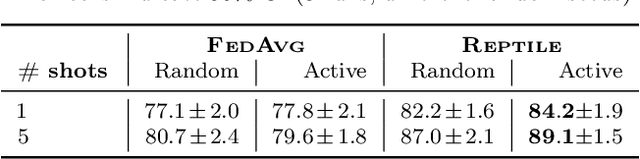
Meta-learning has enabled learning statistical models that can be quickly adapted to new prediction tasks. Motivated by use-cases in personalized federated learning, we study the often overlooked aspect of the modern meta-learning algorithms -- their data efficiency. To shed more light on which methods are more efficient, we use techniques from algorithmic stability to derive bounds on the transfer risk that have important practical implications, indicating how much supervision is needed and how it must be allocated for each method to attain the desired level of generalization. Further, we introduce a new simple framework for evaluating meta-learning methods under a limit on the available supervision, conduct an empirical study of MAML, Reptile, and Protonets, and demonstrate the differences in the behavior of these methods on few-shot and federated learning benchmarks. Finally, we propose active meta-learning, which incorporates active data selection into learning-to-learn, leading to better performance of all methods in the limited supervision regime.
A Learning Theoretic Perspective on Local Explainability
Nov 02, 2020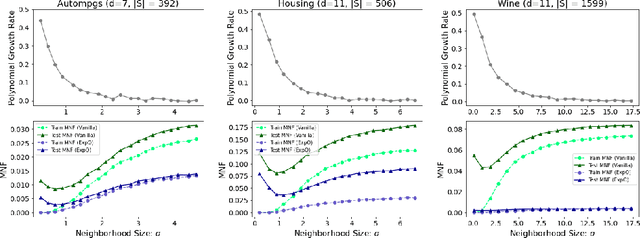
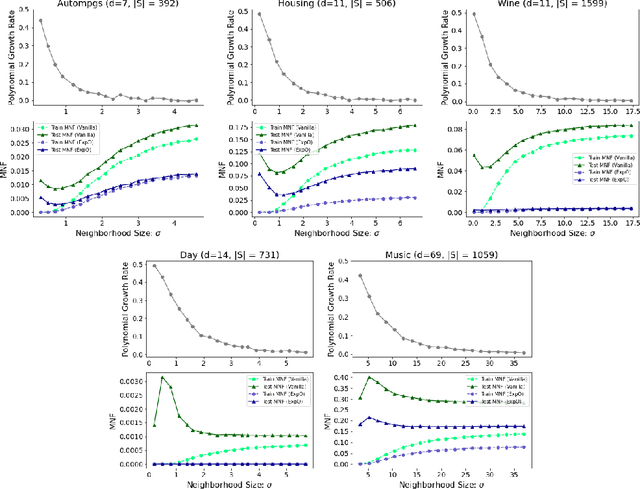
In this paper, we explore connections between interpretable machine learning and learning theory through the lens of local approximation explanations. First, we tackle the traditional problem of performance generalization and bound the test-time accuracy of a model using a notion of how locally explainable it is. Second, we explore the novel problem of explanation generalization which is an important concern for a growing class of finite sample-based local approximation explanations. Finally, we validate our theoretical results empirically and show that they reflect what can be seen in practice.
Geometry-Aware Gradient Algorithms for Neural Architecture Search
Apr 16, 2020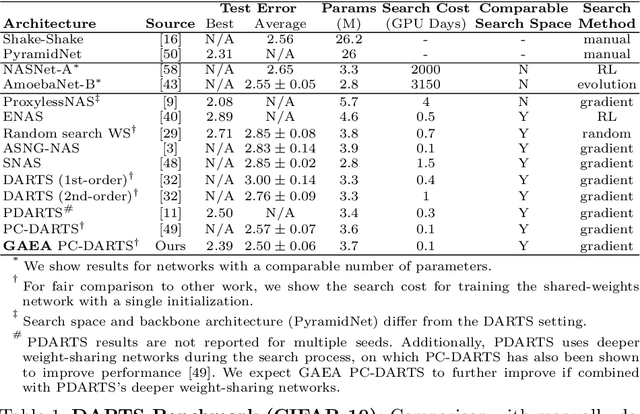
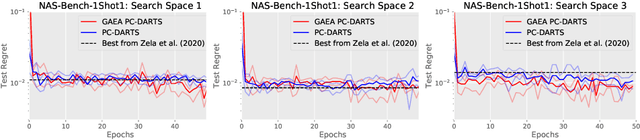
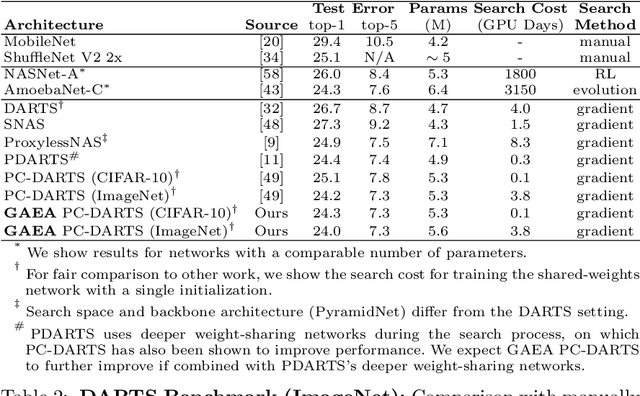
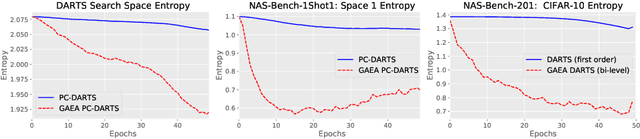
Many recent state-of-the-art methods for neural architecture search (NAS) relax the NAS problem into a joint continuous optimization over architecture parameters and their shared-weights, enabling the application of standard gradient-based optimizers. However, this training process remains poorly understood, as evidenced by the multitude of gradient-based heuristics that have been recently proposed. Invoking the theory of mirror descent, we present a unifying framework for designing and analyzing gradient-based NAS methods that exploit the underlying problem structure to quickly find high-performance architectures. Our geometry-aware framework leads to simple yet novel algorithms that (1) enjoy faster convergence guarantees than existing gradient-based methods and (2) achieve state-of-the-art accuracy on the latest NAS benchmarks in computer vision. Notably, we exceed the best published results for both CIFAR and ImageNet on both the DARTS search space and NAS-Bench-201; on the latter benchmark we achieve close to oracle-optimal performance on CIFAR-10 and CIFAR-100. Together, our theory and experiments demonstrate a principled way to co-design optimizers and continuous parameterizations of discrete NAS search spaces.