 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Representational Instruction Tuning
Feb 15, 2024



All text-based language problems can be reduced to either generation or embedding. Current models only perform well at one or the other. We introduce generative representational instruction tuning (GRIT) whereby a large language model is trained to handle both generative and embedding tasks by distinguishing between them through instructions. Compared to other open models, our resulting GritLM 7B sets a new state of the art on the Massive Text Embedding Benchmark (MTEB) and outperforms all models up to its size on a range of generative tasks. By scaling up further, GritLM 8x7B outperforms all open generative language models that we tried while still being among the best embedding models. Notably, we find that GRIT matches training on only generative or embedding data, thus we can unify both at no performance loss. Among other benefits, the unification via GRIT speeds up Retrieval-Augmented Generation (RAG) by > 60% for long documents, by no longer requiring separate retrieval and generation models. Models, code, etc. are freely available at https://github.com/ContextualAI/gritlm.
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Jun 28, 2023



We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
Jun 21, 2023



Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELISC dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
SciRepEval: A Multi-Format Benchmark for Scientific Document Representations
Nov 23, 2022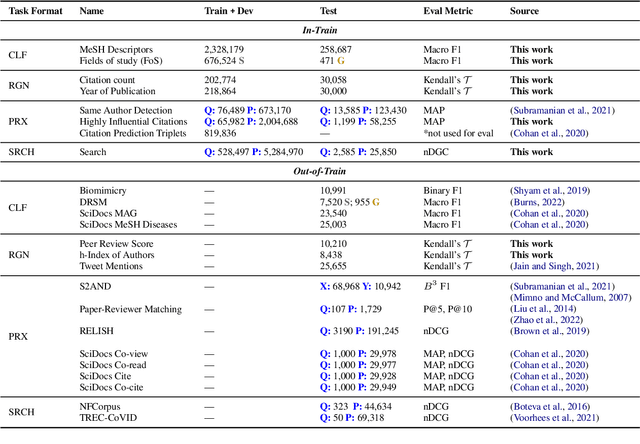
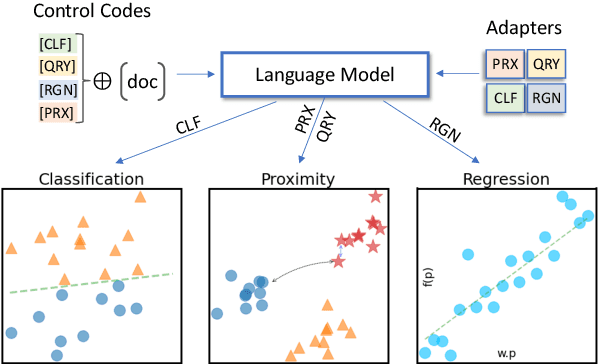
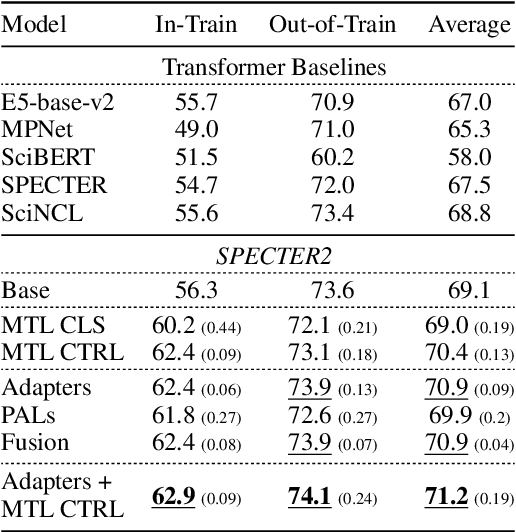
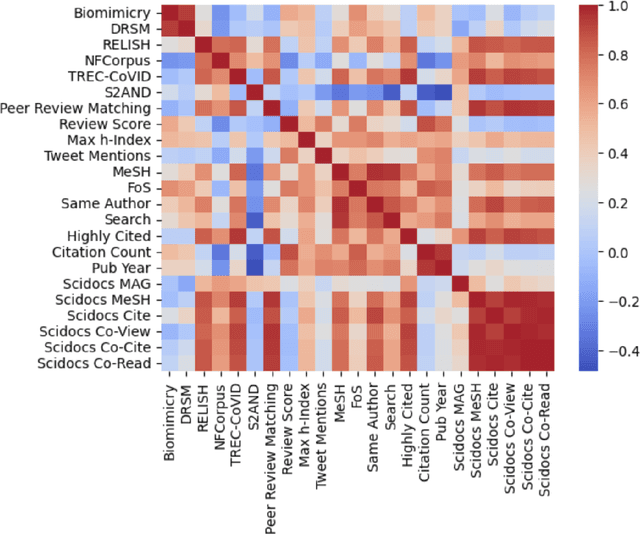
Learned representations of scientific documents can serve as valuable input features for downstream tasks, without the need for further fine-tuning. However, existing benchmarks for evaluating these representations fail to capture the diversity of relevant tasks. In response, we introduce SciRepEval, the first comprehensive benchmark for training and evaluating scientific document representations. It includes 25 challenging and realistic tasks, 11 of which are new, across four formats: classification, regression, ranking and search. We then use the benchmark to study and improve the generalization ability of scientific document representation models. We show how state-of-the-art models struggle to generalize across task formats, and that simple multi-task training fails to improve them. However, a new approach that learns multiple embeddings per document, each tailored to a different format, can improve performance. We experiment with task-format-specific control codes and adapters in a multi-task setting and find that they outperform the existing single-embedding state-of-the-art by up to 1.5 points absolute.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
FeedLens: Polymorphic Lenses for Personalizing Exploratory Search over Knowledge Graphs
Aug 16, 2022
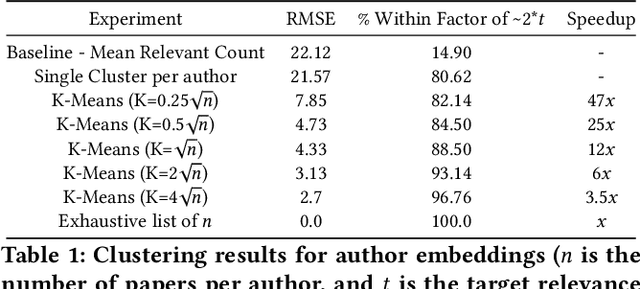

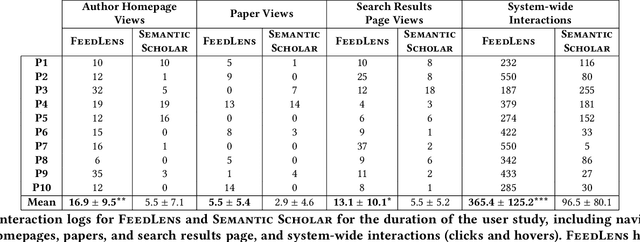
The vast scale and open-ended nature of knowledge graphs (KGs) make exploratory search over them cognitively demanding for users. We introduce a new technique, polymorphic lenses, that improves exploratory search over a KG by obtaining new leverage from the existing preference models that KG-based systems maintain for recommending content. The approach is based on a simple but powerful observation: in a KG, preference models can be re-targeted to recommend not only entities of a single base entity type (e.g., papers in the scientific literature KG, products in an e-commerce KG), but also all other types (e.g., authors, conferences, institutions; sellers, buyers). We implement our technique in a novel system, FeedLens, which is built over Semantic Scholar, a production system for navigating the scientific literature KG. FeedLens reuses the existing preference models on Semantic Scholar -- people's curated research feeds -- as lenses for exploratory search. Semantic Scholar users can curate multiple feeds/lenses for different topics of interest, e.g., one for human-centered AI and another for document embeddings. Although these lenses are defined in terms of papers, FeedLens re-purposes them to also guide search over authors, institutions, venues, etc. Our system design is based on feedback from intended users via two pilot surveys (n=17 and n=13, respectively). We compare FeedLens and Semantic Scholar via a third (within-subjects) user study (n=15) and find that FeedLens increases user engagement while reducing the cognitive effort required to complete a short literature review task. Our qualitative results also highlight people's preference for this more effective exploratory search experience enabled by FeedLens.
Embedding Recycling for Language Models
Jul 11, 2022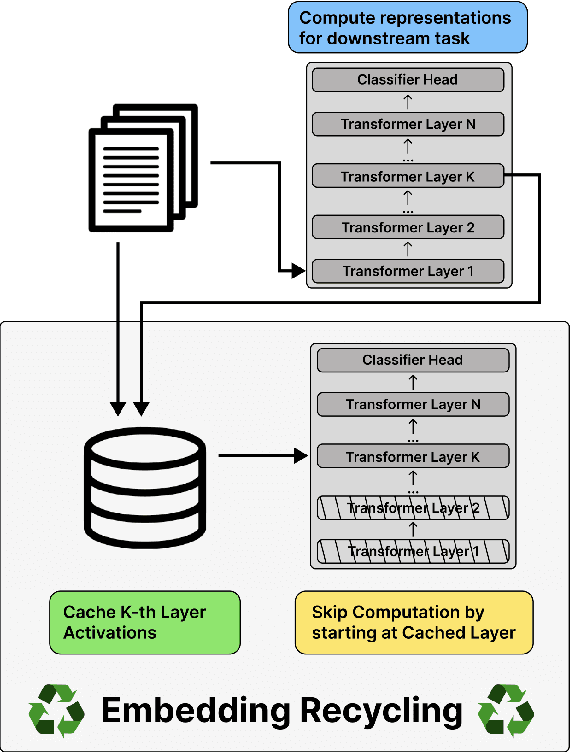
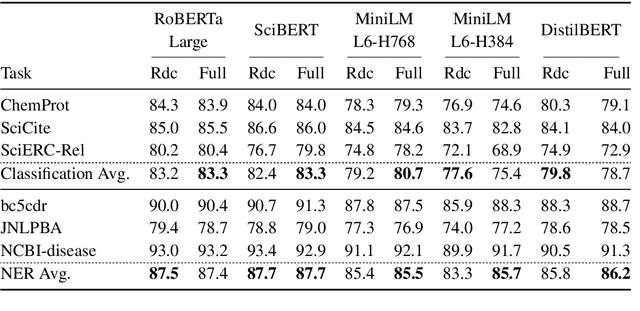
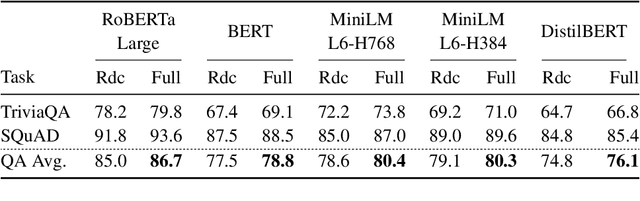
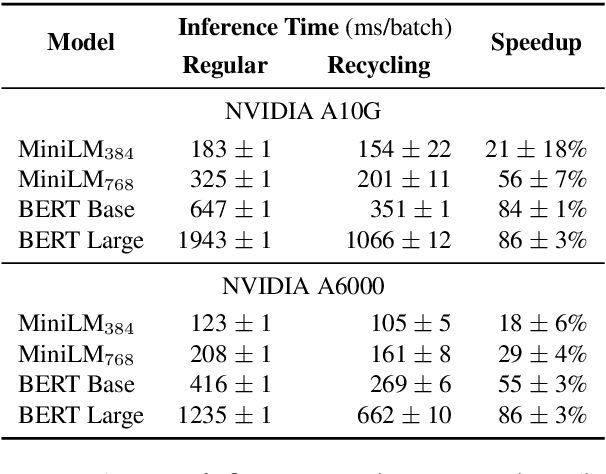
Training and inference with large neural models is expensive. However, for many application domains, while new tasks and models arise frequently, the underlying documents being modeled remain mostly unchanged. We study how to decrease computational cost in such settings through embedding recycling (ER): re-using activations from previous model runs when performing training or inference. In contrast to prior work focusing on freezing small classification heads for finetuning which often leads to notable drops in performance, we propose caching an intermediate layer's output from a pretrained model and finetuning the remaining layers for new tasks. We show that our method provides a 100% speedup during training and a 55-86% speedup for inference, and has negligible impacts on accuracy for text classification and entity recognition tasks in the scientific domain. For general-domain question answering tasks, ER offers a similar speedup and lowers accuracy by a small amount. Finally, we identify several open challenges and future directions for ER.
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
Apr 07, 2022
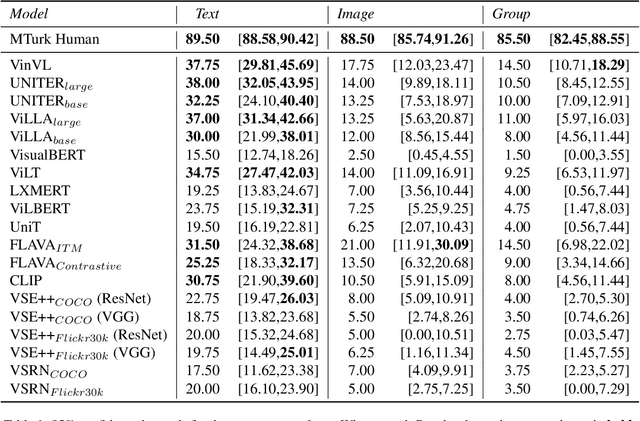
We present a novel task and dataset for evaluating the ability of vision and language models to conduct visio-linguistic compositional reasoning, which we call Winoground. Given two images and two captions, the goal is to match them correctly - but crucially, both captions contain a completely identical set of words, only in a different order. The dataset was carefully hand-curated by expert annotators and is labeled with a rich set of fine-grained tags to assist in analyzing model performance. We probe a diverse range of state-of-the-art vision and language models and find that, surprisingly, none of them do much better than chance. Evidently, these models are not as skilled at visio-linguistic compositional reasoning as we might have hoped. We perform an extensive analysis to obtain insights into how future work might try to mitigate these models' shortcomings. We aim for Winoground to serve as a useful evaluation set for advancing the state of the art and driving further progress in the field. The dataset is available at https://huggingface.co/datasets/facebook/winoground.
Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment
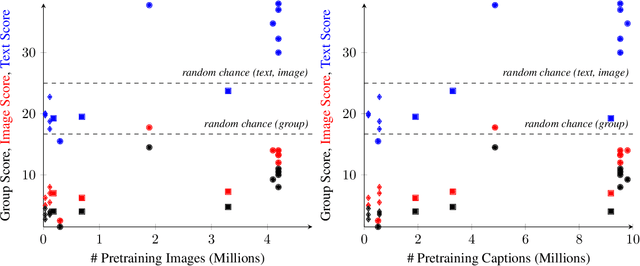
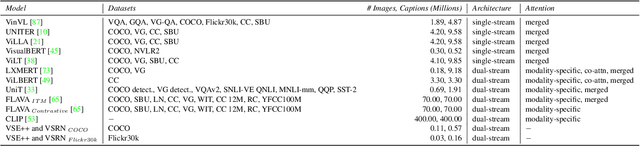
Mar 01, 2022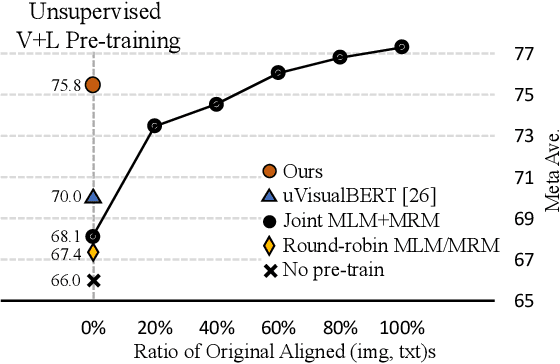
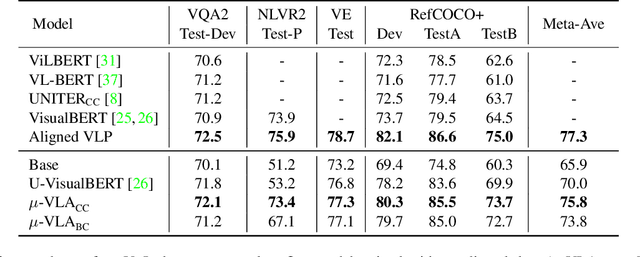
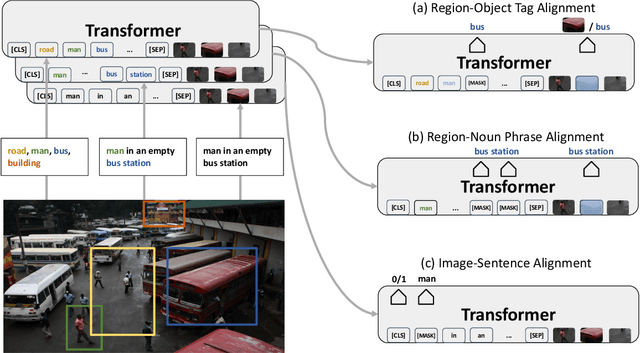
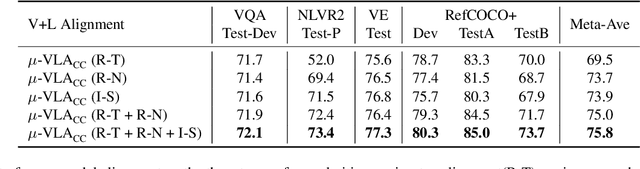
Vision-and-Language (V+L) pre-training models have achieved tremendous success in recent years on various multi-modal benchmarks. However, the majority of existing models require pre-training on a large set of parallel image-text data, which is costly to collect, compared to image-only or text-only data. In this paper, we explore unsupervised Vision-and-Language pre-training (UVLP) to learn the cross-modal representation from non-parallel image and text datasets. We found two key factors that lead to good unsupervised V+L pre-training without parallel data: (i) joint image-and-text input (ii) overall image-text alignment (even for non-parallel data). Accordingly, we propose a novel unsupervised V+L pre-training curriculum for non-parallel texts and images. We first construct a weakly aligned image-text corpus via a retrieval-based approach, then apply a set of multi-granular alignment pre-training tasks, including region-to-tag, region-to-phrase, and image-to-sentence alignment, to bridge the gap between the two modalities. A comprehensive ablation study shows each granularity is helpful to learn a stronger pre-trained model. We adapt our pre-trained model to a set of V+L downstream tasks, including VQA, NLVR2, Visual Entailment, and RefCOCO+. Our model achieves the state-of-art performance in all these tasks under the unsupervised setting.