 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Response and Sentiment Prediction for Automatic Dialogue Evaluation
Nov 16, 2021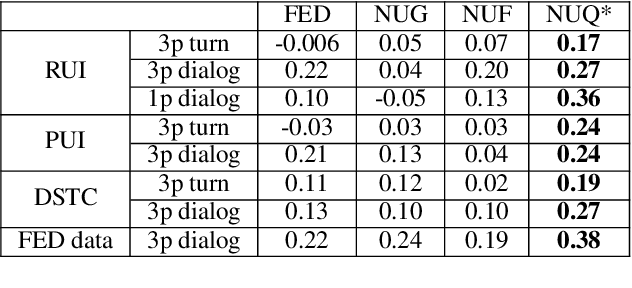
Automatic evaluation is beneficial for open-domain dialog system development. However, standard word-overlap metrics (BLEU, ROUGE) do not correlate well with human judgements of open-domain dialog systems. In this work we propose to use the sentiment of the next user utterance for turn or dialog level evaluation. Specifically we propose three methods: one that predicts the next sentiment directly, and two others that predict the next user utterance using an utterance or a feedback generator model and then classify its sentiment. Experiments show our model outperforming existing automatic evaluation metrics on both written and spoken open-domain dialogue datasets.
Training Conversational Agents with Generative Conversational Networks
Oct 15, 2021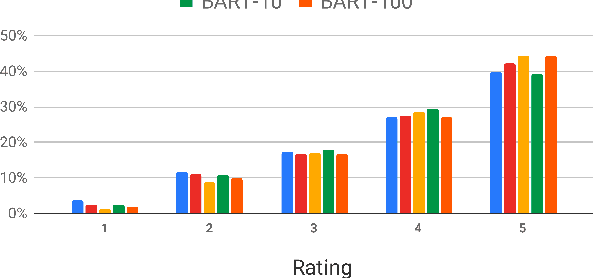

Rich, open-domain textual data available on the web resulted in great advancements for language processing. However, while that data may be suitable for language processing tasks, they are mostly non-conversational, lacking many phenomena that appear in human interactions and this is one of the reasons why we still have many unsolved challenges in conversational AI. In this work, we attempt to address this by using Generative Conversational Networks to automatically generate data and train social conversational agents. We evaluate our approach on TopicalChat with automatic metrics and human evaluators, showing that with 10% of seed data it performs close to the baseline that uses 100% of the data.
"How Robust r u?": Evaluating Task-Oriented Dialogue Systems on Spoken Conversations
Sep 28, 2021
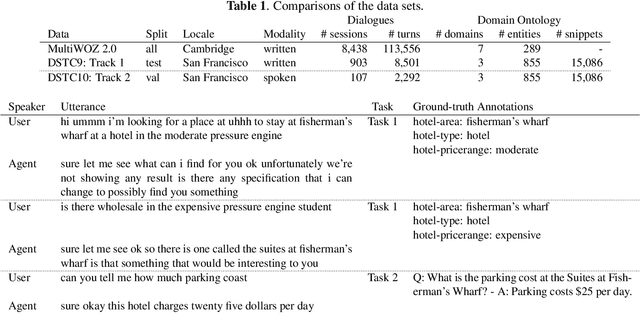
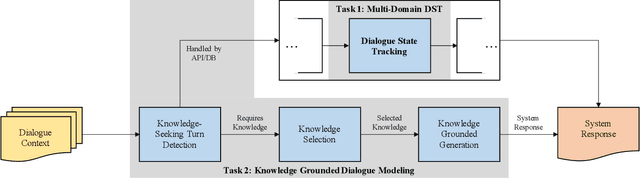

Most prior work in dialogue modeling has been on written conversations mostly because of existing data sets. However, written dialogues are not sufficient to fully capture the nature of spoken conversations as well as the potential speech recognition errors in practical spoken dialogue systems. This work presents a new benchmark on spoken task-oriented conversations, which is intended to study multi-domain dialogue state tracking and knowledge-grounded dialogue modeling. We report that the existing state-of-the-art models trained on written conversations are not performing well on our spoken data, as expected. Furthermore, we observe improvements in task performances when leveraging n-best speech recognition hypotheses such as by combining predictions based on individual hypotheses. Our data set enables speech-based benchmarking of task-oriented dialogue systems.
Generative Conversational Networks
Jun 15, 2021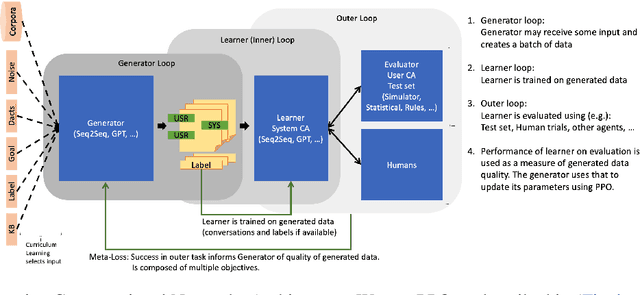
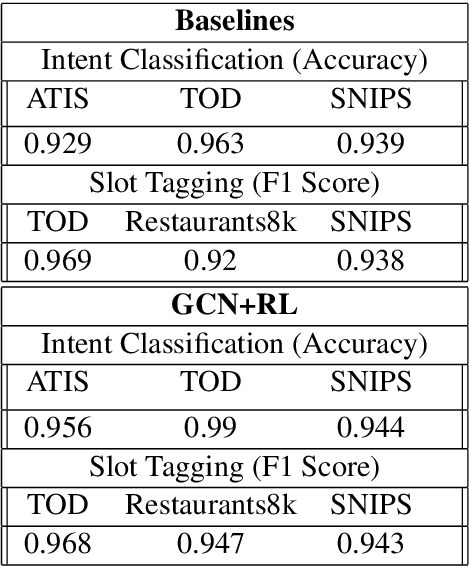
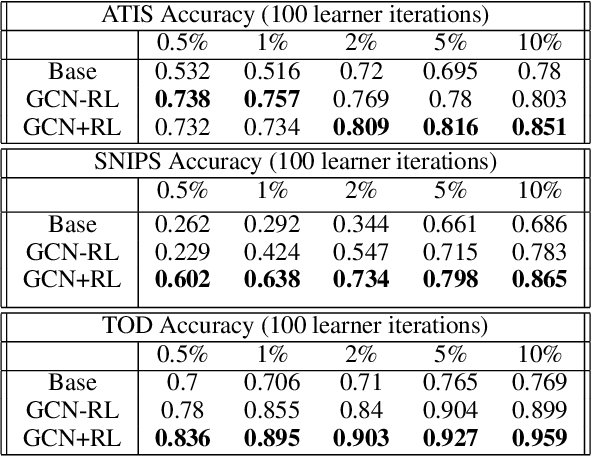
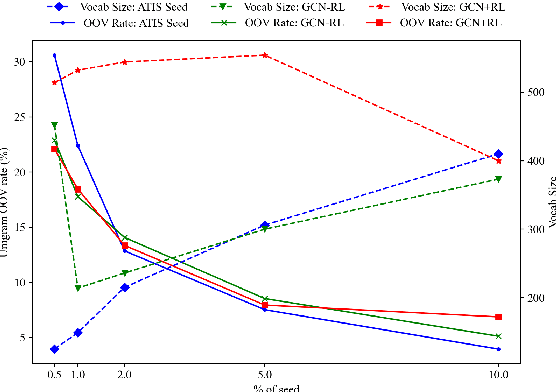
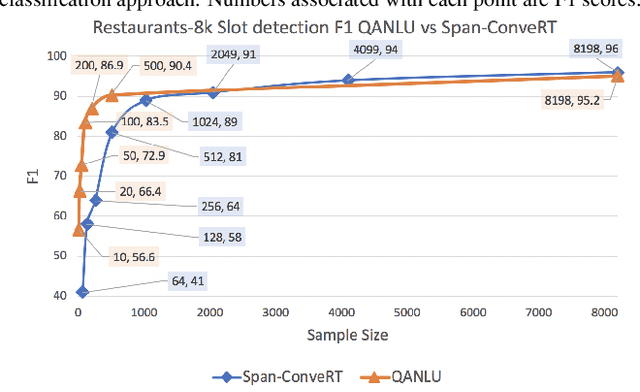
Inspired by recent work in meta-learning and generative teaching networks, we propose a framework called Generative Conversational Networks, in which conversational agents learn to generate their own labelled training data (given some seed data) and then train themselves from that data to perform a given task. We use reinforcement learning to optimize the data generation process where the reward signal is the agent's performance on the task. The task can be any language-related task, from intent detection to full task-oriented conversations. In this work, we show that our approach is able to generalise from seed data and performs well in limited data and limited computation settings, with significant gains for intent detection and slot tagging across multiple datasets: ATIS, TOD, SNIPS, and Restaurants8k. We show an average improvement of 35% in intent detection and 21% in slot tagging over a baseline model trained from the seed data. We also conduct an analysis of the novelty of the generated data and provide generated examples for intent detection, slot tagging, and non-goal oriented conversations.
Can You be More Social? Injecting Politeness and Positivity into Task-Oriented Conversational Agents
Dec 29, 2020
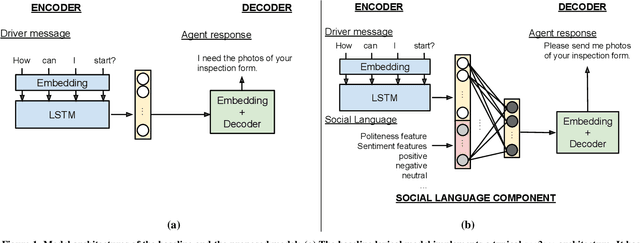


Goal-oriented conversational agents are becoming prevalent in our daily lives. For these systems to engage users and achieve their goals, they need to exhibit appropriate social behavior as well as provide informative replies that guide users through tasks. The first component of the research in this paper applies statistical modeling techniques to understand conversations between users and human agents for customer service. Analyses show that social language used by human agents is associated with greater users' responsiveness and task completion. The second component of the research is the construction of a conversational agent model capable of injecting social language into an agent's responses while still preserving content. The model uses a sequence-to-sequence deep learning architecture, extended with a social language understanding element. Evaluation in terms of content preservation and social language level using both human judgment and automatic linguistic measures shows that the model can generate responses that enable agents to address users' issues in a more socially appropriate way.
Language Model is All You Need: Natural Language Understanding as Question Answering
Nov 05, 2020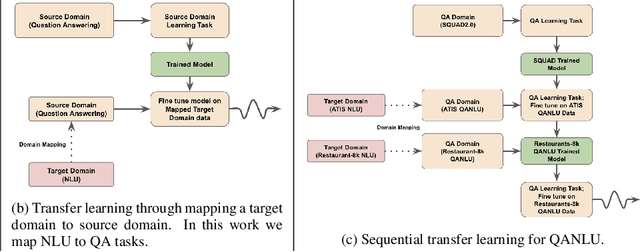
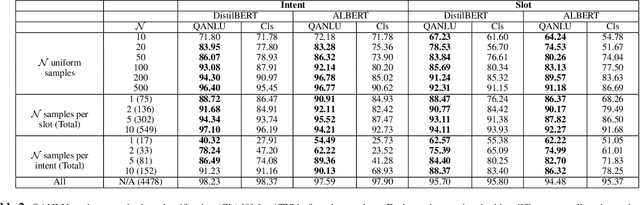
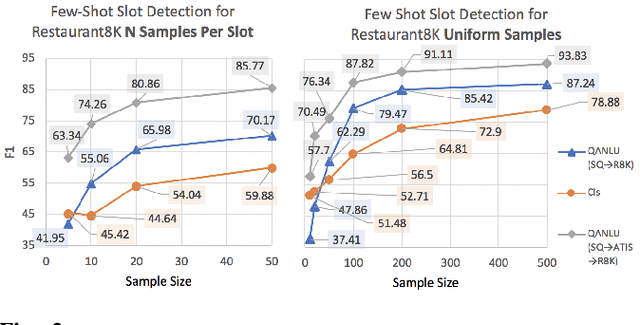
Different flavors of transfer learning have shown tremendous impact in advancing research and applications of machine learning. In this work we study the use of a specific family of transfer learning, where the target domain is mapped to the source domain. Specifically we map Natural Language Understanding (NLU) problems to QuestionAnswering (QA) problems and we show that in low data regimes this approach offers significant improvements compared to other approaches to NLU. Moreover we show that these gains could be increased through sequential transfer learning across NLU problems from different domains. We show that our approach could reduce the amount of required data for the same performance by up to a factor of 10.
Controllable Text Generation with Focused Variation
Sep 25, 2020
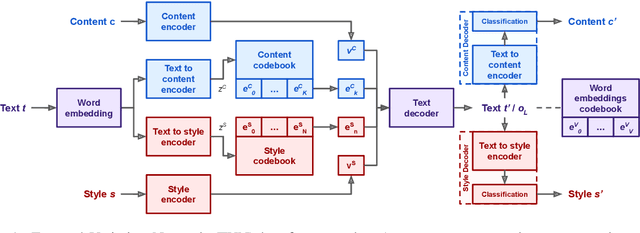
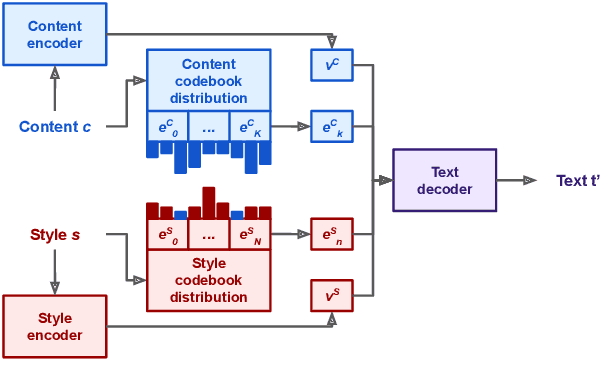
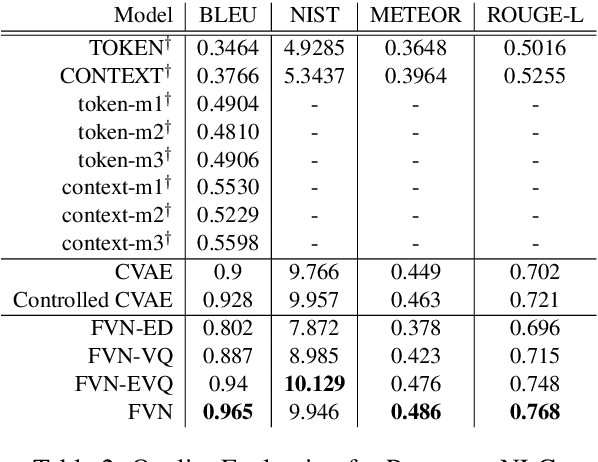
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
Joint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020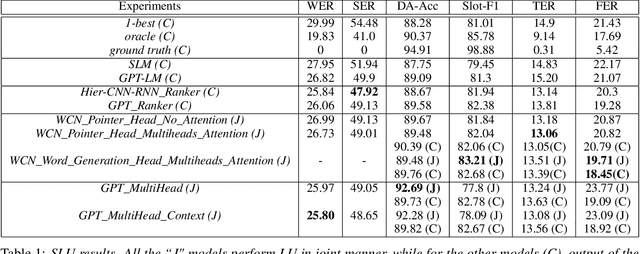
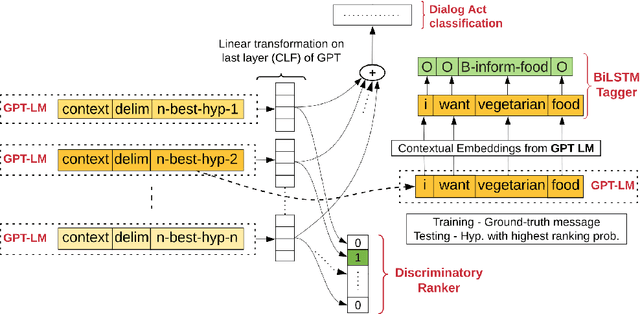
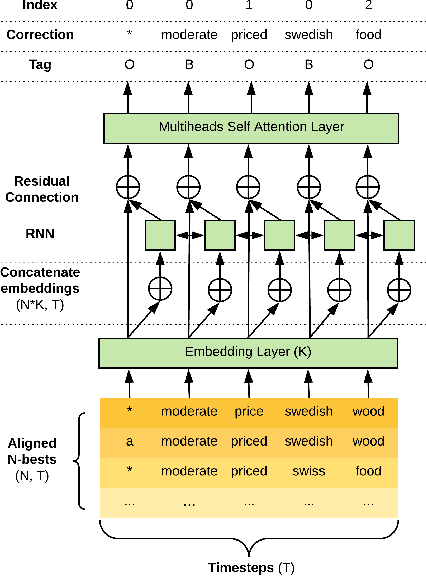
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

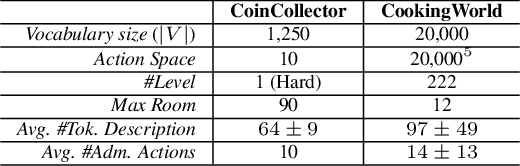
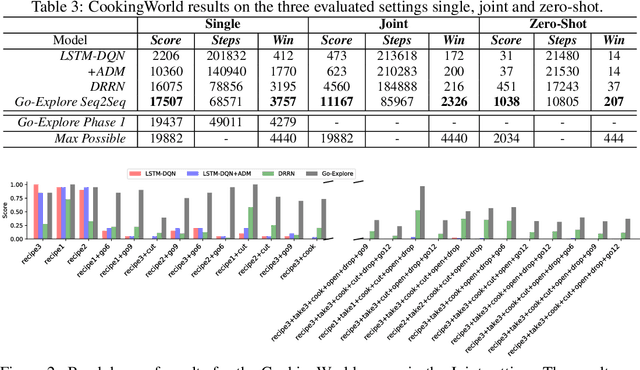
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Plato Dialogue System: A Flexible Conversational AI Research Platform
Jan 17, 2020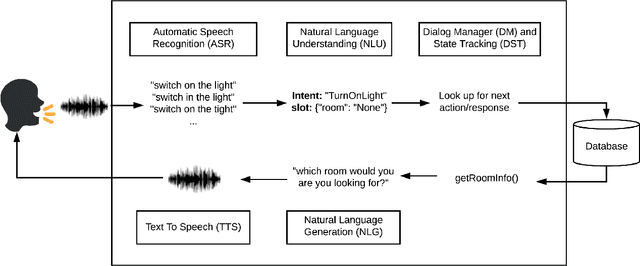

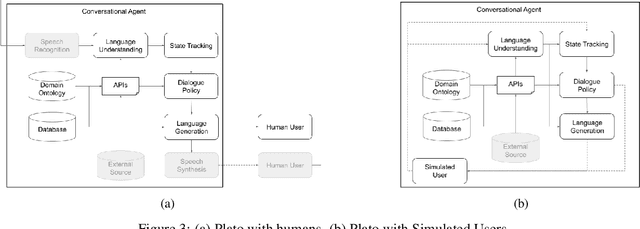
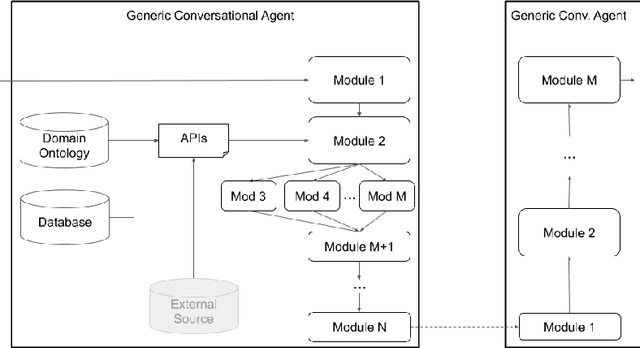
As the field of Spoken Dialogue Systems and Conversational AI grows, so does the need for tools and environments that abstract away implementation details in order to expedite the development process, lower the barrier of entry to the field, and offer a common test-bed for new ideas. In this paper, we present Plato, a flexible Conversational AI platform written in Python that supports any kind of conversational agent architecture, from standard architectures to architectures with jointly-trained components, single- or multi-party interactions, and offline or online training of any conversational agent component. Plato has been designed to be easy to understand and debug and is agnostic to the underlying learning frameworks that train each component.