 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapture the Flag: Uncovering Data Insights with Large Language Models
Dec 21, 2023The extraction of a small number of relevant insights from vast amounts of data is a crucial component of data-driven decision-making. However, accomplishing this task requires considerable technical skills, domain expertise, and human labor. This study explores the potential of using Large Language Models (LLMs) to automate the discovery of insights in data, leveraging recent advances in reasoning and code generation techniques. We propose a new evaluation methodology based on a "capture the flag" principle, measuring the ability of such models to recognize meaningful and pertinent information (flags) in a dataset. We further propose two proof-of-concept agents, with different inner workings, and compare their ability to capture such flags in a real-world sales dataset. While the work reported here is preliminary, our results are sufficiently interesting to mandate future exploration by the community.
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023



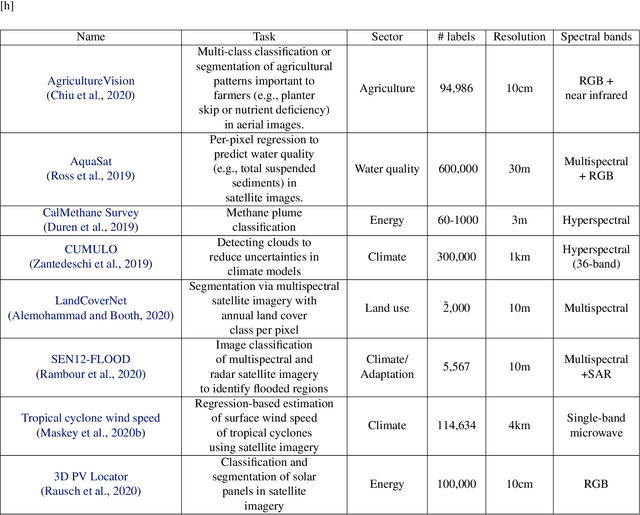
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
Choreographer: Learning and Adapting Skills in Imagination
Nov 23, 2022Unsupervised skill learning aims to learn a rich repertoire of behaviors without external supervision, providing artificial agents with the ability to control and influence the environment. However, without appropriate knowledge and exploration, skills may provide control only over a restricted area of the environment, limiting their applicability. Furthermore, it is unclear how to leverage the learned skill behaviors for adapting to downstream tasks in a data-efficient manner. We present Choreographer, a model-based agent that exploits its world model to learn and adapt skills in imagination. Our method decouples the exploration and skill learning processes, being able to discover skills in the latent state space of the model. During adaptation, the agent uses a meta-controller to evaluate and adapt the learned skills efficiently by deploying them in parallel in imagination. Choreographer is able to learn skills both from offline data, and by collecting data simultaneously with an exploration policy. The skills can be used to effectively adapt to downstream tasks, as we show in the URL benchmark, where we outperform previous approaches from both pixels and states inputs. The learned skills also explore the environment thoroughly, finding sparse rewards more frequently, as shown in goal-reaching tasks from the DMC Suite and Meta-World. Project website: https://skillchoreographer.github.io/
A General Purpose Neural Architecture for Geospatial Systems
Nov 04, 2022



Geospatial Information Systems are used by researchers and Humanitarian Assistance and Disaster Response (HADR) practitioners to support a wide variety of important applications. However, collaboration between these actors is difficult due to the heterogeneous nature of geospatial data modalities (e.g., multi-spectral images of various resolutions, timeseries, weather data) and diversity of tasks (e.g., regression of human activity indicators or detecting forest fires). In this work, we present a roadmap towards the construction of a general-purpose neural architecture (GPNA) with a geospatial inductive bias, pre-trained on large amounts of unlabelled earth observation data in a self-supervised manner. We envision how such a model may facilitate cooperation between members of the community. We show preliminary results on the first step of the roadmap, where we instantiate an architecture that can process a wide variety of geospatial data modalities and demonstrate that it can achieve competitive performance with domain-specific architectures on tasks relating to the U.N.'s Sustainable Development Goals.
Unsupervised Model-based Pre-training for Data-efficient Control from Pixels
Sep 24, 2022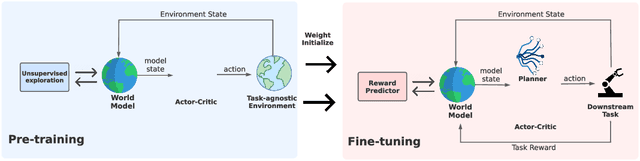
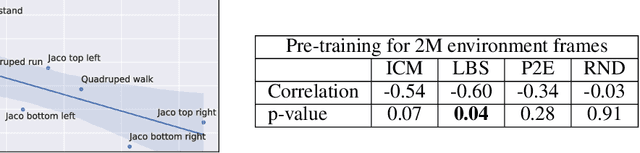
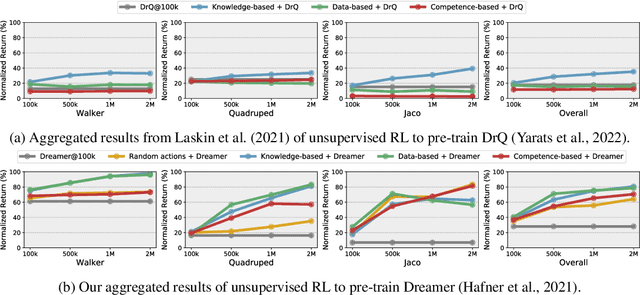
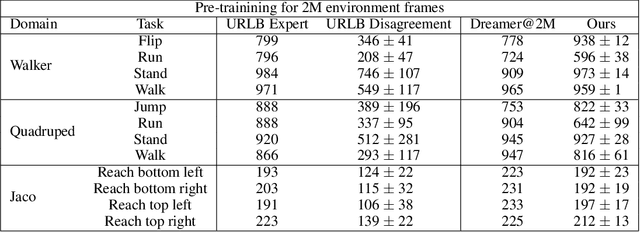
Controlling artificial agents from visual sensory data is an arduous task. Reinforcement learning (RL) algorithms can succeed in this but require large amounts of interactions between the agent and the environment. To alleviate the issue, unsupervised RL proposes to employ self-supervised interaction and learning, for adapting faster to future tasks. Yet, whether current unsupervised strategies improve generalization capabilities is still unclear, especially in visual control settings. In this work, we design an effective unsupervised RL strategy for data-efficient visual control. First, we show that world models pre-trained with data collected using unsupervised RL can facilitate adaptation for future tasks. Then, we analyze several design choices to adapt efficiently, effectively reusing the agents' pre-trained components, and learning and planning in imagination, with our hybrid planner, which we dub Dyna-MPC. By combining the findings of a large-scale empirical study, we establish an approach that strongly improves performance on the Unsupervised RL Benchmark, requiring 20$\times$ less data to match the performance of supervised methods. The approach also demonstrates robust performance on the Real-Word RL benchmark, hinting that the approach generalizes to noisy environments.
Toward Foundation Models for Earth Monitoring: Proposal for a Climate Change Benchmark
Dec 01, 2021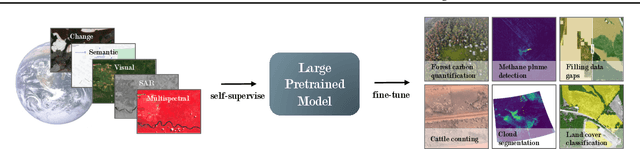
Recent progress in self-supervision shows that pre-training large neural networks on vast amounts of unsupervised data can lead to impressive increases in generalisation for downstream tasks. Such models, recently coined as foundation models, have been transformational to the field of natural language processing. While similar models have also been trained on large corpuses of images, they are not well suited for remote sensing data. To stimulate the development of foundation models for Earth monitoring, we propose to develop a new benchmark comprised of a variety of downstream tasks related to climate change. We believe that this can lead to substantial improvements in many existing applications and facilitate the development of new applications. This proposal is also a call for collaboration with the aim of developing a better evaluation process to mitigate potential downsides of foundation models for Earth monitoring.
Typing assumptions improve identification in causal discovery
Jul 22, 2021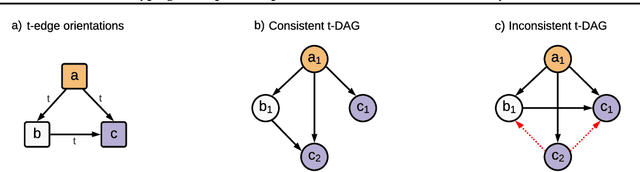
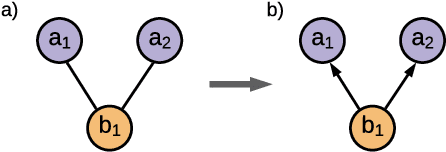
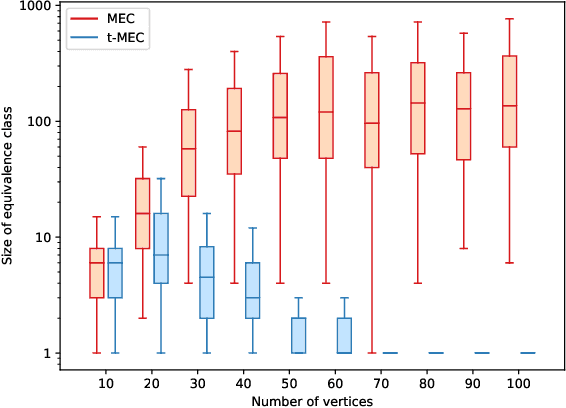
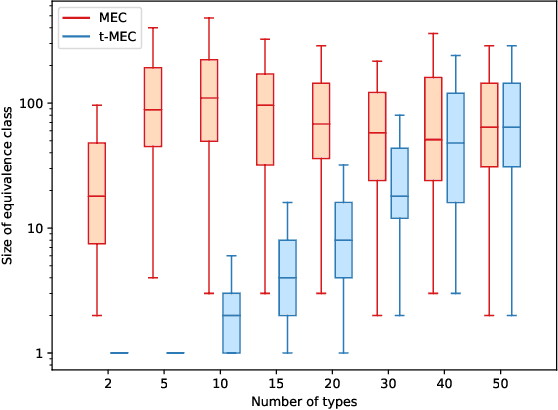
Causal discovery from observational data is a challenging task to which an exact solution cannot always be identified. Under assumptions about the data-generative process, the causal graph can often be identified up to an equivalence class. Proposing new realistic assumptions to circumscribe such equivalence classes is an active field of research. In this work, we propose a new set of assumptions that constrain possible causal relationships based on the nature of the variables. We thus introduce typed directed acyclic graphs, in which variable types are used to determine the validity of causal relationships. We demonstrate, both theoretically and empirically, that the proposed assumptions can result in significant gains in the identification of the causal graph.
Discovering Latent Causal Variables via Mechanism Sparsity: A New Principle for Nonlinear ICA
Jul 21, 2021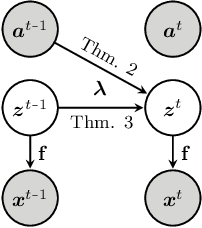
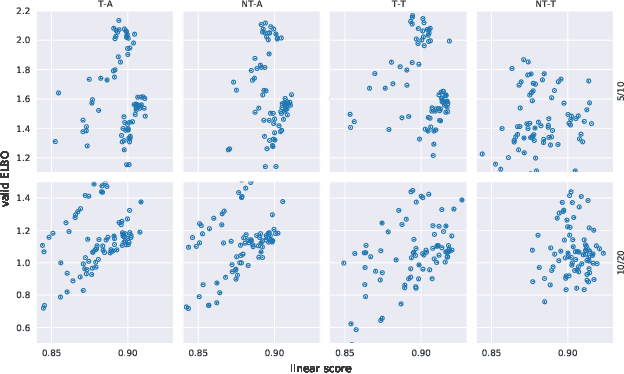
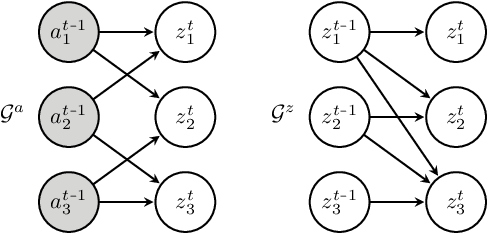
It can be argued that finding an interpretable low-dimensional representation of a potentially high-dimensional phenomenon is central to the scientific enterprise. Independent component analysis (ICA) refers to an ensemble of methods which formalize this goal and provide estimation procedure for practical application. This work proposes mechanism sparsity regularization as a new principle to achieve nonlinear ICA when latent factors depend sparsely on observed auxiliary variables and/or past latent factors. We show that the latent variables can be recovered up to a permutation if one regularizes the latent mechanisms to be sparse and if some graphical criterion is satisfied by the data generating process. As a special case, our framework shows how one can leverage unknown-target interventions on the latent factors to disentangle them, thus drawing further connections between ICA and causality. We validate our theoretical results with toy experiments.
Variational Causal Networks: Approximate Bayesian Inference over Causal Structures
Jun 14, 2021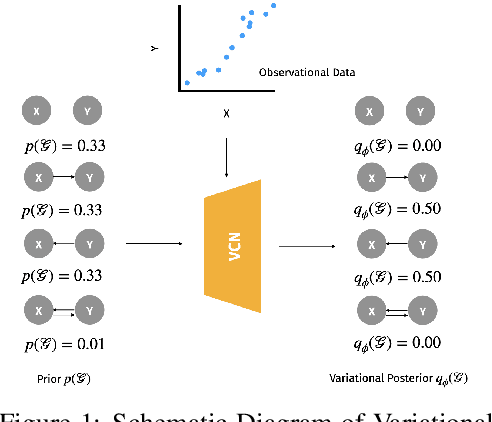
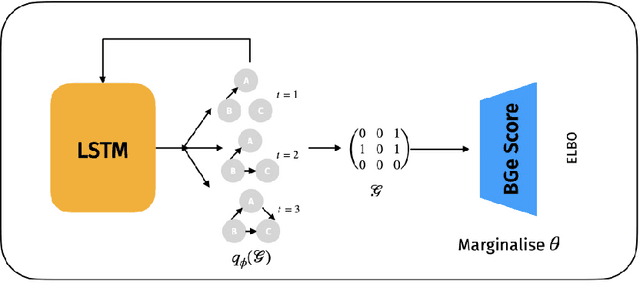
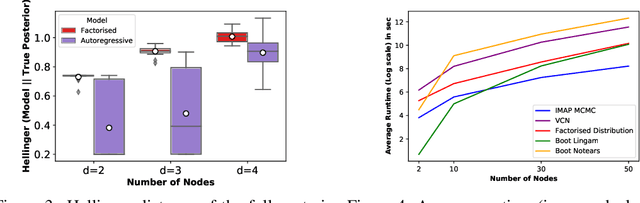
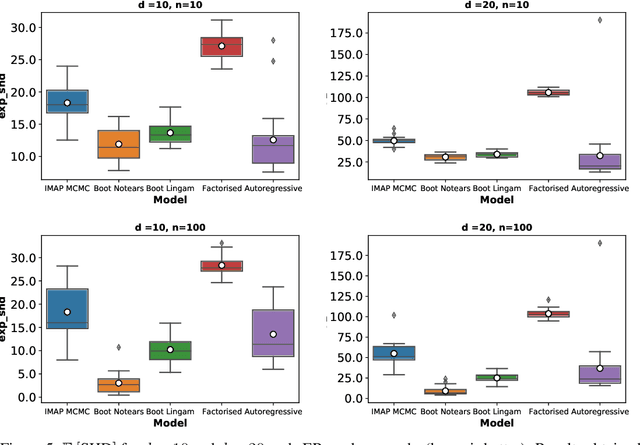
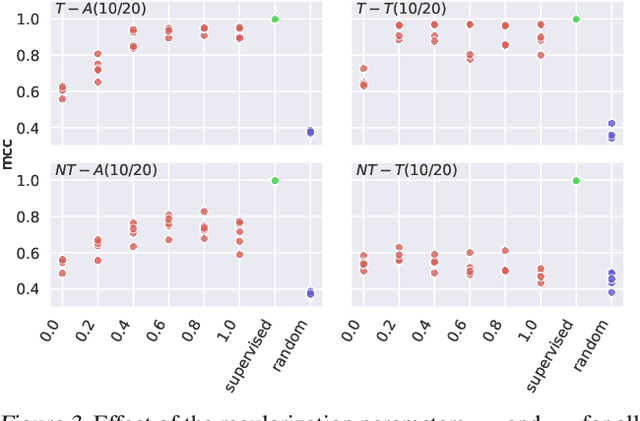
Learning the causal structure that underlies data is a crucial step towards robust real-world decision making. The majority of existing work in causal inference focuses on determining a single directed acyclic graph (DAG) or a Markov equivalence class thereof. However, a crucial aspect to acting intelligently upon the knowledge about causal structure which has been inferred from finite data demands reasoning about its uncertainty. For instance, planning interventions to find out more about the causal mechanisms that govern our data requires quantifying epistemic uncertainty over DAGs. While Bayesian causal inference allows to do so, the posterior over DAGs becomes intractable even for a small number of variables. Aiming to overcome this issue, we propose a form of variational inference over the graphs of Structural Causal Models (SCMs). To this end, we introduce a parametric variational family modelled by an autoregressive distribution over the space of discrete DAGs. Its number of parameters does not grow exponentially with the number of variables and can be tractably learned by maximising an Evidence Lower Bound (ELBO). In our experiments, we demonstrate that the proposed variational posterior is able to provide a good approximation of the true posterior.
Can Active Learning Preemptively Mitigate Fairness Issues?
Apr 14, 2021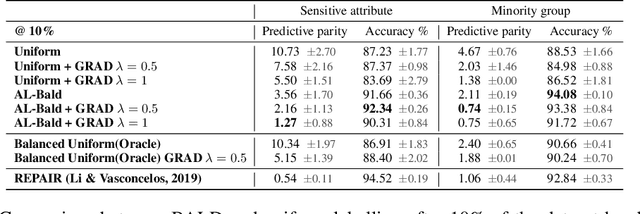
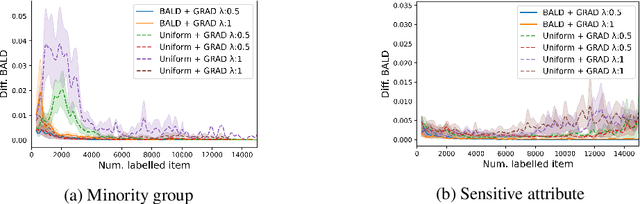


Dataset bias is one of the prevailing causes of unfairness in machine learning. Addressing fairness at the data collection and dataset preparation stages therefore becomes an essential part of training fairer algorithms. In particular, active learning (AL) algorithms show promise for the task by drawing importance to the most informative training samples. However, the effect and interaction between existing AL algorithms and algorithmic fairness remain under-explored. In this paper, we study whether models trained with uncertainty-based AL heuristics such as BALD are fairer in their decisions with respect to a protected class than those trained with identically independently distributed (i.i.d.) sampling. We found a significant improvement on predictive parity when using BALD, while also improving accuracy compared to i.i.d. sampling. We also explore the interaction of algorithmic fairness methods such as gradient reversal (GRAD) and BALD. We found that, while addressing different fairness issues, their interaction further improves the results on most benchmarks and metrics we explored.