 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoreDec: A Phase-preserving High-Fidelity Audio Codec with A Generalized Score-based Diffusion Post-filter
Jan 22, 2024Although recent mainstream waveform-domain end-to-end (E2E) neural audio codecs achieve impressive coded audio quality with a very low bitrate, the quality gap between the coded and natural audio is still significant. A generative adversarial network (GAN) training is usually required for these E2E neural codecs because of the difficulty of direct phase modeling. However, such adversarial learning hinders these codecs from preserving the original phase information. To achieve human-level naturalness with a reasonable bitrate, preserve the original phase, and get rid of the tricky and opaque GAN training, we develop a score-based diffusion post-filter (SPF) in the complex spectral domain and combine our previous AudioDec with the SPF to propose ScoreDec, which can be trained using only spectral and score-matching losses. Both the objective and subjective experimental results show that ScoreDec with a 24~kbps bitrate encodes and decodes full-band 48~kHz speech with human-level naturalness and well-preserved phase information.
From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
Jan 03, 2024



We present a framework for generating full-bodied photorealistic avatars that gesture according to the conversational dynamics of a dyadic interaction. Given speech audio, we output multiple possibilities of gestural motion for an individual, including face, body, and hands. The key behind our method is in combining the benefits of sample diversity from vector quantization with the high-frequency details obtained through diffusion to generate more dynamic, expressive motion. We visualize the generated motion using highly photorealistic avatars that can express crucial nuances in gestures (e.g. sneers and smirks). To facilitate this line of research, we introduce a first-of-its-kind multi-view conversational dataset that allows for photorealistic reconstruction. Experiments show our model generates appropriate and diverse gestures, outperforming both diffusion- and VQ-only methods. Furthermore, our perceptual evaluation highlights the importance of photorealism (vs. meshes) in accurately assessing subtle motion details in conversational gestures. Code and dataset available online.
Sounding Bodies: Modeling 3D Spatial Sound of Humans Using Body Pose and Audio
Nov 01, 2023



While 3D human body modeling has received much attention in computer vision, modeling the acoustic equivalent, i.e. modeling 3D spatial audio produced by body motion and speech, has fallen short in the community. To close this gap, we present a model that can generate accurate 3D spatial audio for full human bodies. The system consumes, as input, audio signals from headset microphones and body pose, and produces, as output, a 3D sound field surrounding the transmitter's body, from which spatial audio can be rendered at any arbitrary position in the 3D space. We collect a first-of-its-kind multimodal dataset of human bodies, recorded with multiple cameras and a spherical array of 345 microphones. In an empirical evaluation, we demonstrate that our model can produce accurate body-induced sound fields when trained with a suitable loss. Dataset and code are available online.
AudioDec: An Open-source Streaming High-fidelity Neural Audio Codec
May 26, 2023



A good audio codec for live applications such as telecommunication is characterized by three key properties: (1) compression, i.e.\ the bitrate that is required to transmit the signal should be as low as possible; (2) latency, i.e.\ encoding and decoding the signal needs to be fast enough to enable communication without or with only minimal noticeable delay; and (3) reconstruction quality of the signal. In this work, we propose an open-source, streamable, and real-time neural audio codec that achieves strong performance along all three axes: it can reconstruct highly natural sounding 48~kHz speech signals while operating at only 12~kbps and running with less than 6~ms (GPU)/10~ms (CPU) latency. An efficient training paradigm is also demonstrated for developing such neural audio codecs for real-world scenarios. Both objective and subjective evaluations using the VCTK corpus are provided. To sum up, AudioDec is a well-developed plug-and-play benchmark for audio codec applications.
Novel-View Acoustic Synthesis
Jan 23, 2023



We introduce the novel-view acoustic synthesis (NVAS) task: given the sight and sound observed at a source viewpoint, can we synthesize the sound of that scene from an unseen target viewpoint? We propose a neural rendering approach: Visually-Guided Acoustic Synthesis (ViGAS) network that learns to synthesize the sound of an arbitrary point in space by analyzing the input audio-visual cues. To benchmark this task, we collect two first-of-their-kind large-scale multi-view audio-visual datasets, one synthetic and one real. We show that our model successfully reasons about the spatial cues and synthesizes faithful audio on both datasets. To our knowledge, this work represents the very first formulation, dataset, and approach to solve the novel-view acoustic synthesis task, which has exciting potential applications ranging from AR/VR to art and design. Unlocked by this work, we believe that the future of novel-view synthesis is in multi-modal learning from videos.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
End-to-End Binaural Speech Synthesis
Jul 08, 2022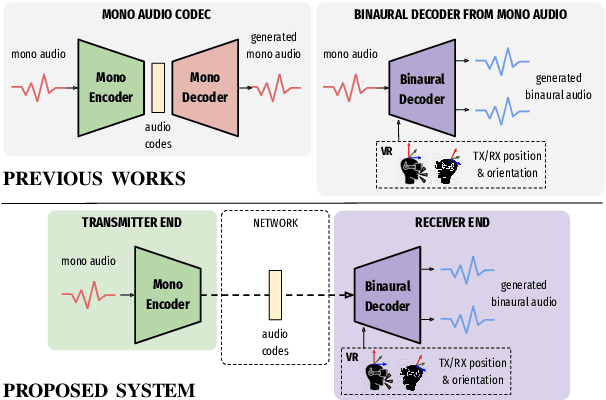
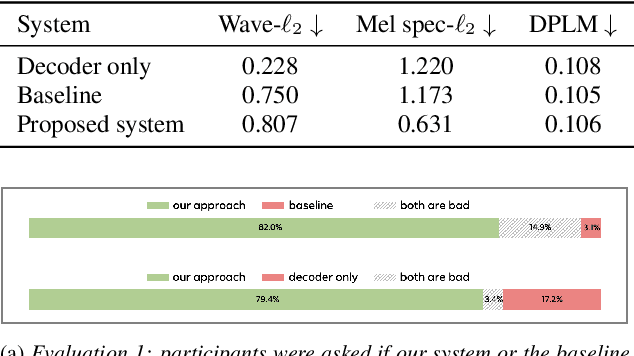
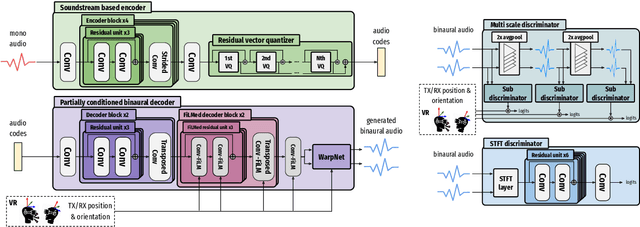

In this work, we present an end-to-end binaural speech synthesis system that combines a low-bitrate audio codec with a powerful binaural decoder that is capable of accurate speech binauralization while faithfully reconstructing environmental factors like ambient noise or reverb. The network is a modified vector-quantized variational autoencoder, trained with several carefully designed objectives, including an adversarial loss. We evaluate the proposed system on an internal binaural dataset with objective metrics and a perceptual study. Results show that the proposed approach matches the ground truth data more closely than previous methods. In particular, we demonstrate the capability of the adversarial loss in capturing environment effects needed to create an authentic auditory scene.
Implicit Neural Spatial Filtering for Multichannel Source Separation in the Waveform Domain
Jun 30, 2022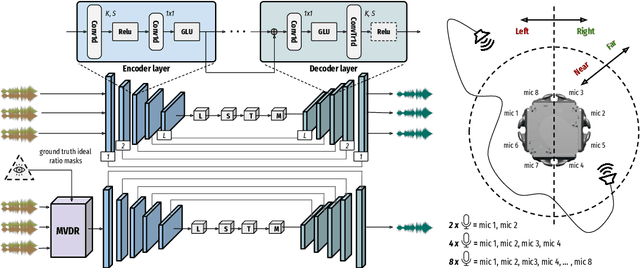
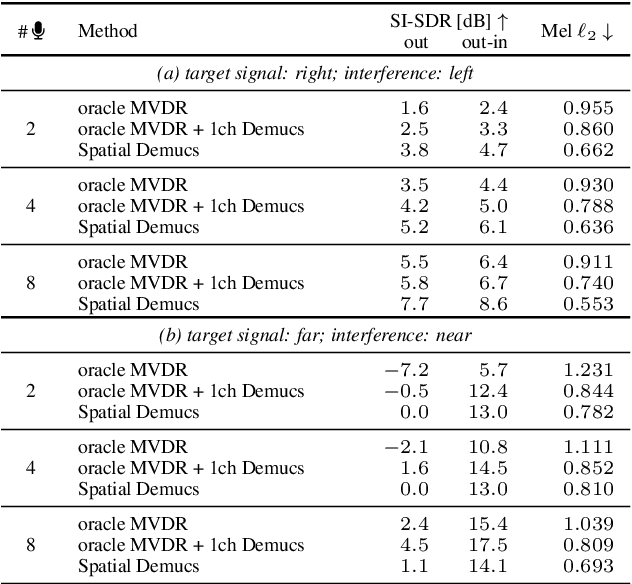
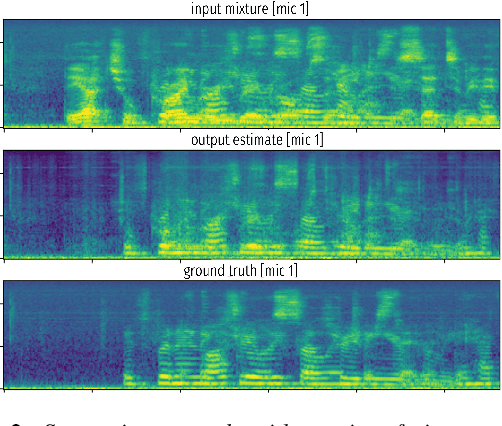
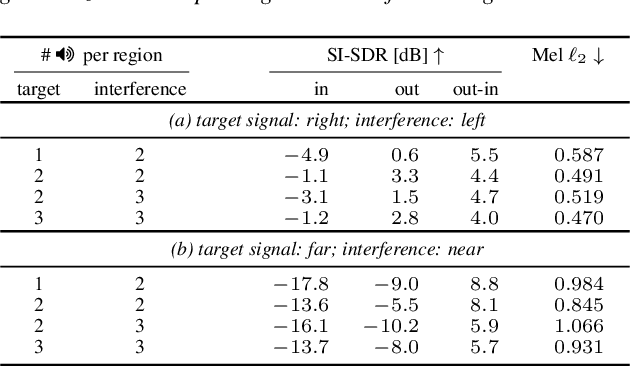
We present a single-stage casual waveform-to-waveform multichannel model that can separate moving sound sources based on their broad spatial locations in a dynamic acoustic scene. We divide the scene into two spatial regions containing, respectively, the target and the interfering sound sources. The model is trained end-to-end and performs spatial processing implicitly, without any components based on traditional processing or use of hand-crafted spatial features. We evaluate the proposed model on a real-world dataset and show that the model matches the performance of an oracle beamformer followed by a state-of-the-art single-channel enhancement network.
Audio-Visual Speech Codecs: Rethinking Audio-Visual Speech Enhancement by Re-Synthesis
Mar 31, 2022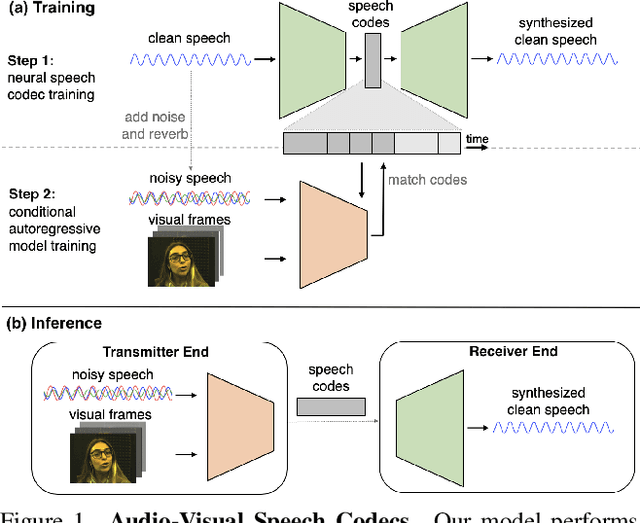
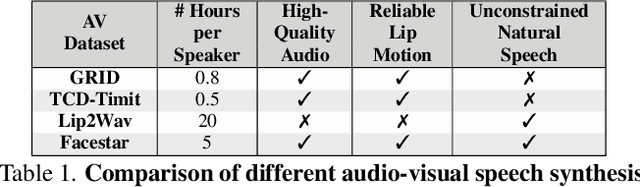
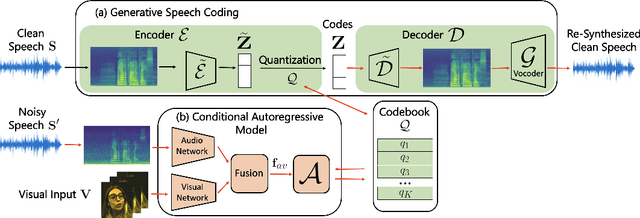

Since facial actions such as lip movements contain significant information about speech content, it is not surprising that audio-visual speech enhancement methods are more accurate than their audio-only counterparts. Yet, state-of-the-art approaches still struggle to generate clean, realistic speech without noise artifacts and unnatural distortions in challenging acoustic environments. In this paper, we propose a novel audio-visual speech enhancement framework for high-fidelity telecommunications in AR/VR. Our approach leverages audio-visual speech cues to generate the codes of a neural speech codec, enabling efficient synthesis of clean, realistic speech from noisy signals. Given the importance of speaker-specific cues in speech, we focus on developing personalized models that work well for individual speakers. We demonstrate the efficacy of our approach on a new audio-visual speech dataset collected in an unconstrained, large vocabulary setting, as well as existing audio-visual datasets, outperforming speech enhancement baselines on both quantitative metrics and human evaluation studies. Please see the supplemental video for qualitative results at https://github.com/facebookresearch/facestar/releases/download/paper_materials/video.mp4.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022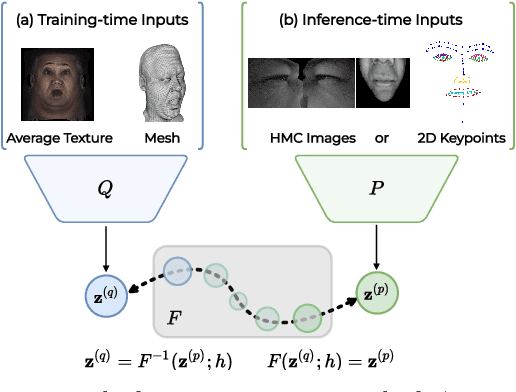
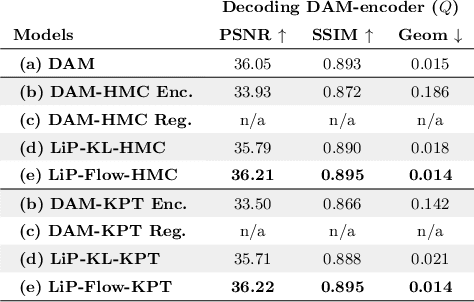

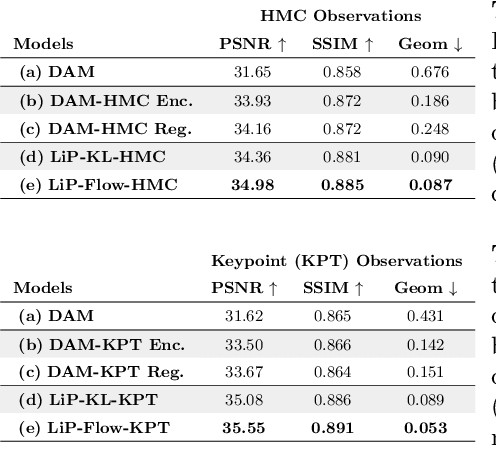
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.