 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond
May 23, 2023



With the recent appearance of LLMs in practical settings, having methods that can effectively detect factual inconsistencies is crucial to reduce the propagation of misinformation and improve trust in model outputs. When testing on existing factual consistency benchmarks, we find that a few large language models (LLMs) perform competitively on classification benchmarks for factual inconsistency detection compared to traditional non-LLM methods. However, a closer analysis reveals that most LLMs fail on more complex formulations of the task and exposes issues with existing evaluation benchmarks, affecting evaluation precision. To address this, we propose a new protocol for inconsistency detection benchmark creation and implement it in a 10-domain benchmark called SummEdits. This new benchmark is 20 times more cost-effective per sample than previous benchmarks and highly reproducible, as we estimate inter-annotator agreement at about 0.9. Most LLMs struggle on SummEdits, with performance close to random chance. The best-performing model, GPT-4, is still 8\% below estimated human performance, highlighting the gaps in LLMs' ability to reason about facts and detect inconsistencies when they occur.
On Learning to Summarize with Large Language Models as References
May 23, 2023



Recent studies have found that summaries generated by large language models (LLMs) are favored by human annotators over the original reference summaries in commonly used summarization datasets. Therefore, we investigate a new learning paradigm of text summarization models that considers the LLMs as the reference or the gold-standard oracle on commonly used summarization datasets such as the CNN/DailyMail dataset. To examine the standard practices that are aligned with the new learning setting, we propose a novel training method that is based on contrastive learning with LLMs as a summarization quality evaluator. For this reward-based training method, we investigate two different methods of utilizing LLMs for summary quality evaluation, namely GPTScore and GPTRank. Our experiments on the CNN/DailyMail dataset demonstrate that smaller summarization models trained by our proposed method can achieve performance equal to or surpass that of the reference LLMs, as evaluated by the LLMs themselves. This underscores the efficacy of our proposed paradigm in enhancing model performance over the standard maximum likelihood estimation (MLE) training method, and its efficiency since it only requires a small budget to access the LLMs. We release the training scripts, model outputs, and LLM-based evaluation results to facilitate future studies.
Towards Interpretable and Efficient Automatic Reference-Based Summarization Evaluation
Mar 07, 2023Interpretability and efficiency are two important considerations for the adoption of neural automatic metrics. In this work, we develop strong-performing automatic metrics for reference-based summarization evaluation, based on a two-stage evaluation pipeline that first extracts basic information units from one text sequence and then checks the extracted units in another sequence. The metrics we developed include two-stage metrics that can provide high interpretability at both the fine-grained unit level and summary level, and one-stage metrics that achieve a balance between efficiency and interoperability. We make the developed tools publicly available through a Python package and GitHub.
Socratic Pretraining: Question-Driven Pretraining for Controllable Summarization
Dec 20, 2022In long document controllable summarization, where labeled data is scarce, pretrained models struggle to adapt to the task and effectively respond to user queries. In this paper, we introduce Socratic pretraining, a question-driven, unsupervised pretraining objective specifically designed to improve controllability in summarization tasks. By training a model to generate and answer relevant questions in a given context, Socratic pretraining enables the model to more effectively adhere to user-provided queries and identify relevant content to be summarized. We demonstrate the effectiveness of this approach through extensive experimentation on two summarization domains, short stories and dialogue, and multiple control strategies: keywords, questions, and factoid QA pairs. Our pretraining method relies only on unlabeled documents and a question generation system and outperforms pre-finetuning approaches that use additional supervised data. Furthermore, our results show that Socratic pretraining cuts task-specific labeled data requirements in half, is more faithful to user-provided queries, and achieves state-of-the-art performance on QMSum and SQuALITY.
Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation
Dec 15, 2022Human evaluation is the foundation upon which the evaluation of both summarization systems and automatic metrics rests. However, existing human evaluation protocols and benchmarks for summarization either exhibit low inter-annotator agreement or lack the scale needed to draw statistically significant conclusions, and an in-depth analysis of human evaluation is lacking. In this work, we address the shortcomings of existing summarization evaluation along the following axes: 1) We propose a modified summarization salience protocol, Atomic Content Units (ACUs), which relies on fine-grained semantic units and allows for high inter-annotator agreement. 2) We curate the Robust Summarization Evaluation (RoSE) benchmark, a large human evaluation dataset consisting of over 22k summary-level annotations over state-of-the-art systems on three datasets. 3) We compare our ACU protocol with three other human evaluation protocols, underscoring potential confounding factors in evaluation setups. 4) We evaluate existing automatic metrics using the collected human annotations across evaluation protocols and demonstrate how our benchmark leads to more statistically stable and significant results. Furthermore, our findings have important implications for evaluating large language models (LLMs), as we show that LLMs adjusted by human feedback (e.g., GPT-3.5) may overfit unconstrained human evaluation, which is affected by the annotators' prior, input-agnostic preferences, calling for more robust, targeted evaluation methods.
Zero-Shot Opinion Summarization with GPT-3
Nov 29, 2022



Very large language models such as GPT-3 have shown impressive performance across a wide variety of tasks, including text summarization. In this paper, we show that this strong performance extends to opinion summarization. We explore several pipeline methods for applying GPT-3 to summarize a large collection of user reviews in a zero-shot fashion, notably approaches based on recursive summarization and selecting salient content to summarize through supervised clustering or extraction. On two datasets, an aspect-oriented summarization dataset of hotel reviews and a generic summarization dataset of Amazon and Yelp reviews, we show that the GPT-3 models achieve very strong performance in human evaluation. We argue that standard evaluation metrics do not reflect this, and evaluate against several new measures targeting faithfulness, factuality, and genericity to contrast these different methods.
Improving Factual Consistency in Summarization with Compression-Based Post-Editing
Nov 11, 2022State-of-the-art summarization models still struggle to be factually consistent with the input text. A model-agnostic way to address this problem is post-editing the generated summaries. However, existing approaches typically fail to remove entity errors if a suitable input entity replacement is not available or may insert erroneous content. In our work, we focus on removing extrinsic entity errors, or entities not in the source, to improve consistency while retaining the summary's essential information and form. We propose to use sentence-compression data to train the post-editing model to take a summary with extrinsic entity errors marked with special tokens and output a compressed, well-formed summary with those errors removed. We show that this model improves factual consistency while maintaining ROUGE, improving entity precision by up to 30% on XSum, and that this model can be applied on top of another post-editor, improving entity precision by up to a total of 38%. We perform an extensive comparison of post-editing approaches that demonstrate trade-offs between factual consistency, informativeness, and grammaticality, and we analyze settings where post-editors show the largest improvements.
CREATIVESUMM: Shared Task on Automatic Summarization for Creative Writing
Nov 10, 2022This paper introduces the shared task of summarizing documents in several creative domains, namely literary texts, movie scripts, and television scripts. Summarizing these creative documents requires making complex literary interpretations, as well as understanding non-trivial temporal dependencies in texts containing varied styles of plot development and narrative structure. This poses unique challenges and is yet underexplored for text summarization systems. In this shared task, we introduce four sub-tasks and their corresponding datasets, focusing on summarizing books, movie scripts, primetime television scripts, and daytime soap opera scripts. We detail the process of curating these datasets for the task, as well as the metrics used for the evaluation of the submissions. As part of the CREATIVESUMM workshop at COLING 2022, the shared task attracted 18 submissions in total. We discuss the submissions and the baselines for each sub-task in this paper, along with directions for facilitating future work in the field.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
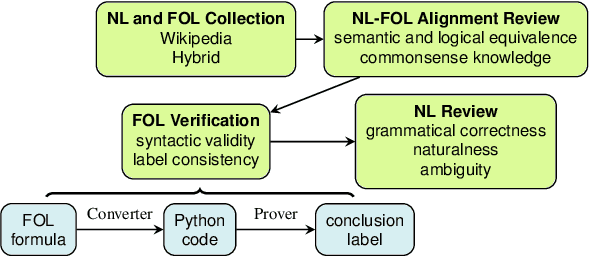
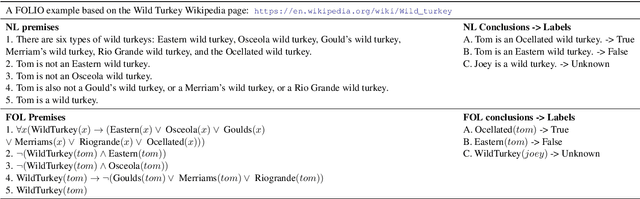
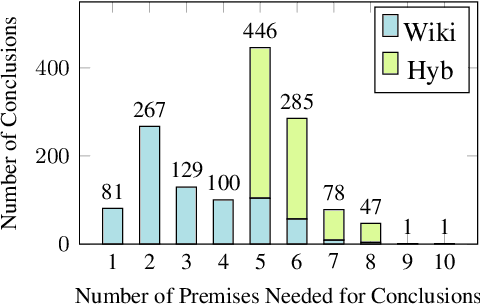
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
May 25, 2022
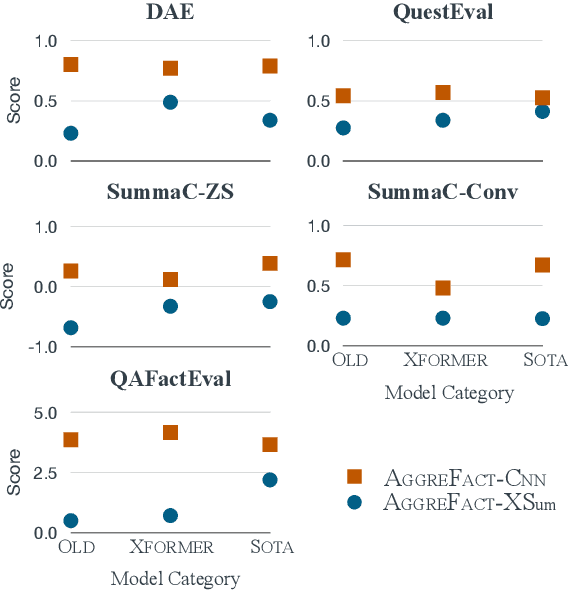
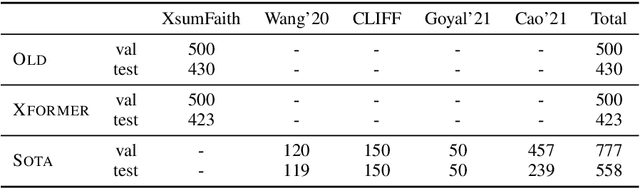
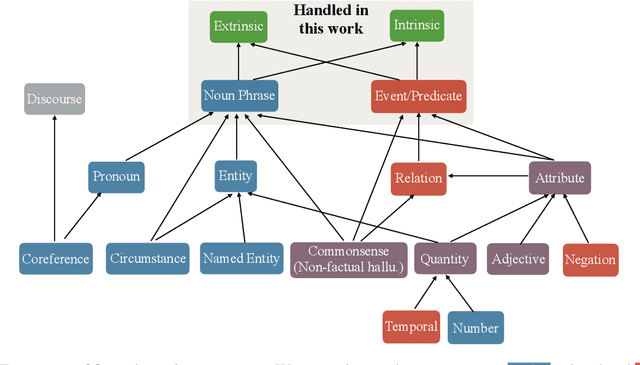
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.