 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Selection for Offline Reinforcement Learning
Jul 17, 2020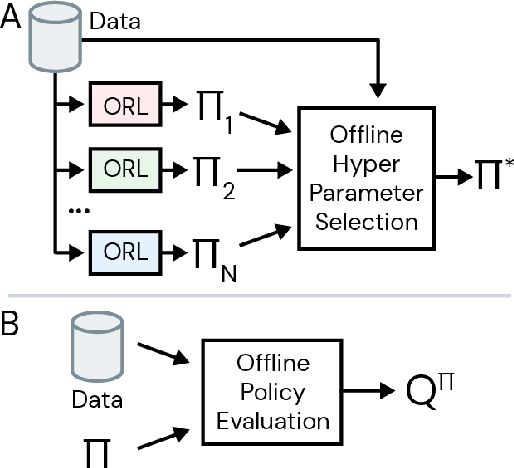
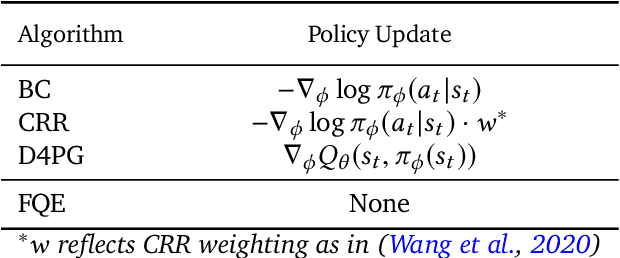
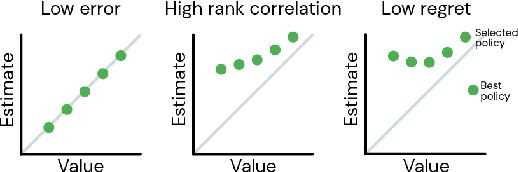
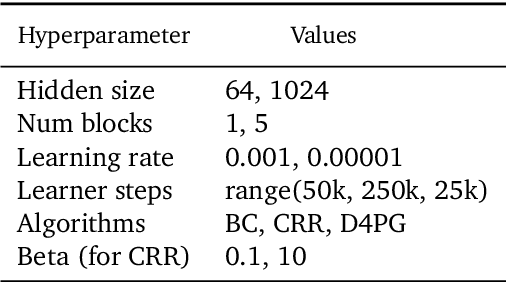
Offline reinforcement learning (RL purely from logged data) is an important avenue for deploying RL techniques in real-world scenarios. However, existing hyperparameter selection methods for offline RL break the offline assumption by evaluating policies corresponding to each hyperparameter setting in the environment. This online execution is often infeasible and hence undermines the main aim of offline RL. Therefore, in this work, we focus on \textit{offline hyperparameter selection}, i.e. methods for choosing the best policy from a set of many policies trained using different hyperparameters, given only logged data. Through large-scale empirical evaluation we show that: 1) offline RL algorithms are not robust to hyperparameter choices, 2) factors such as the offline RL algorithm and method for estimating Q values can have a big impact on hyperparameter selection, and 3) when we control those factors carefully, we can reliably rank policies across hyperparameter choices, and therefore choose policies which are close to the best policy in the set. Overall, our results present an optimistic view that offline hyperparameter selection is within reach, even in challenging tasks with pixel observations, high dimensional action spaces, and long horizon.
RL Unplugged: Benchmarks for Offline Reinforcement Learning
Jul 02, 2020
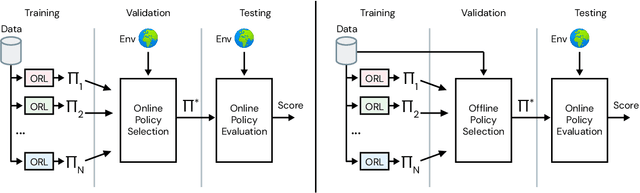
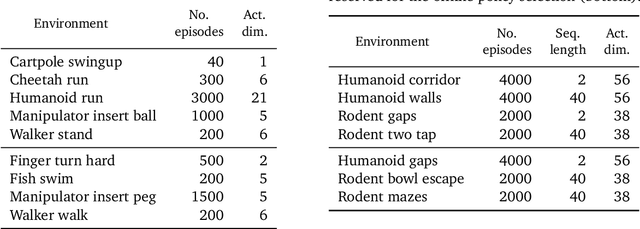
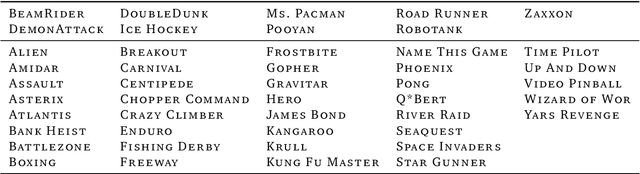
Offline methods for reinforcement learning have a potential to help bridge the gap between reinforcement learning research and real-world applications. They make it possible to learn policies from offline datasets, thus overcoming concerns associated with online data collection in the real-world, including cost, safety, or ethical concerns. In this paper, we propose a benchmark called RL Unplugged to evaluate and compare offline RL methods. RL Unplugged includes data from a diverse range of domains including games ({\em e.g.,} Atari benchmark) and simulated motor control problems ({\em e.g.,} DM Control Suite). The datasets include domains that are partially or fully observable, use continuous or discrete actions, and have stochastic vs. deterministic dynamics. We propose detailed evaluation protocols for each domain in RL Unplugged and provide an extensive analysis of supervised learning and offline RL methods using these protocols. We will release data for all our tasks and open-source all algorithms presented in this paper. We hope that our suite of benchmarks will increase the reproducibility of experiments and make it possible to study challenging tasks with a limited computational budget, thus making RL research both more systematic and more accessible across the community. Moving forward, we view RL Unplugged as a living benchmark suite that will evolve and grow with datasets contributed by the research community and ourselves. Our project page is available on github (https://git.io/JJUhd).
Critic Regularized Regression
Jun 26, 2020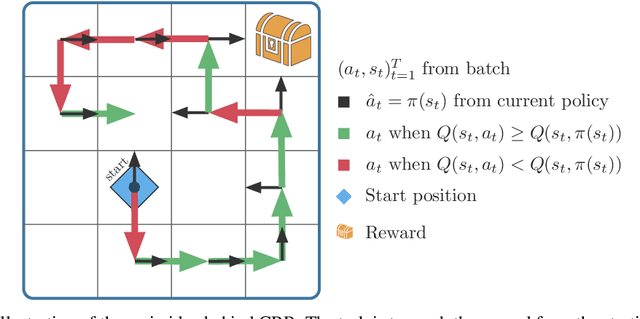


Offline reinforcement learning (RL), also known as batch RL, offers the prospect of policy optimization from large pre-recorded datasets without online environment interaction. It addresses challenges with regard to the cost of data collection and safety, both of which are particularly pertinent to real-world applications of RL. Unfortunately, most off-policy algorithms perform poorly when learning from a fixed dataset. In this paper, we propose a novel offline RL algorithm to learn policies from data using a form of critic-regularized regression (CRR). We find that CRR performs surprisingly well and scales to tasks with high-dimensional state and action spaces -- outperforming several state-of-the-art offline RL algorithms by a significant margin on a wide range of benchmark tasks.
Task-Relevant Adversarial Imitation Learning
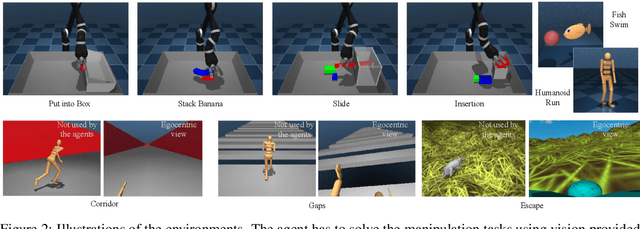
Oct 02, 2019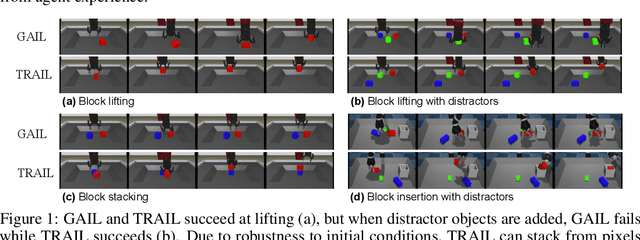
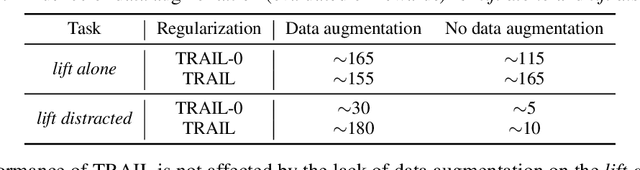


We show that a critical problem in adversarial imitation from high-dimensional sensory data is the tendency of discriminator networks to distinguish agent and expert behaviour using task-irrelevant features beyond the control of the agent. We analyze this problem in detail and propose a solution as well as several baselines that outperform standard Generative Adversarial Imitation Learning (GAIL). Our proposed solution, Task-Relevant Adversarial Imitation Learning (TRAIL), uses a constrained optimization objective to overcome task-irrelevant features. Comprehensive experiments show that TRAIL can solve challenging manipulation tasks from pixels by imitating human operators, where other agents such as behaviour cloning (BC), standard GAIL, improved GAIL variants including our newly proposed baselines, and Deterministic Policy Gradients from Demonstrations (DPGfD) fail to find solutions, even when the other agents have access to task reward.
A Framework for Data-Driven Robotics
Sep 26, 2019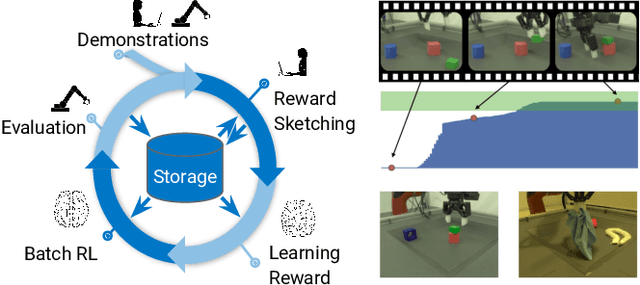
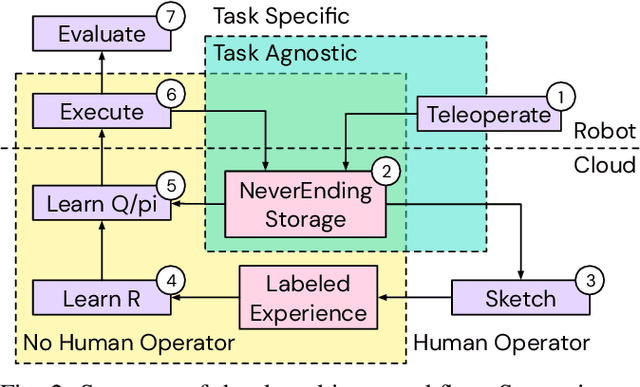
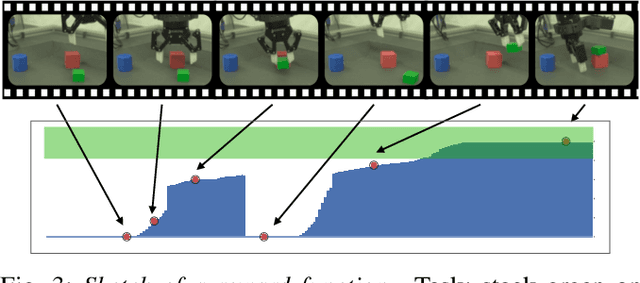
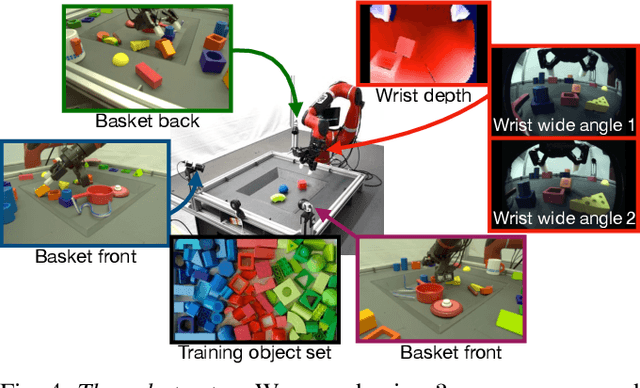
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
Expressive power of recurrent neural networks
Feb 07, 2018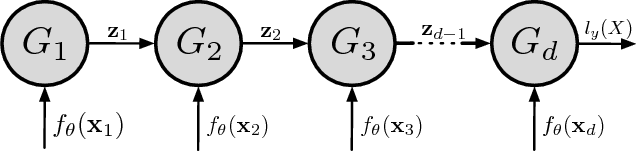

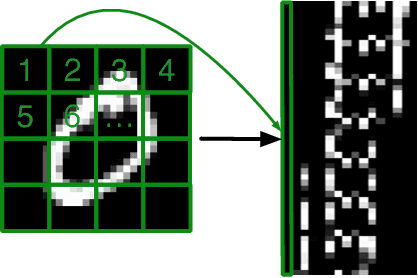
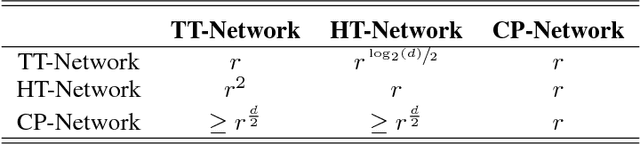
Deep neural networks are surprisingly efficient at solving practical tasks, but the theory behind this phenomenon is only starting to catch up with the practice. Numerous works show that depth is the key to this efficiency. A certain class of deep convolutional networks -- namely those that correspond to the Hierarchical Tucker (HT) tensor decomposition -- has been proven to have exponentially higher expressive power than shallow networks. I.e. a shallow network of exponential width is required to realize the same score function as computed by the deep architecture. In this paper, we prove the expressive power theorem (an exponential lower bound on the width of the equivalent shallow network) for a class of recurrent neural networks -- ones that correspond to the Tensor Train (TT) decomposition. This means that even processing an image patch by patch with an RNN can be exponentially more efficient than a (shallow) convolutional network with one hidden layer. Using theoretical results on the relation between the tensor decompositions we compare expressive powers of the HT- and TT-Networks. We also implement the recurrent TT-Networks and provide numerical evidence of their expressivity.
Scalable Gaussian Processes with Billions of Inducing Inputs via Tensor Train Decomposition
Jan 17, 2018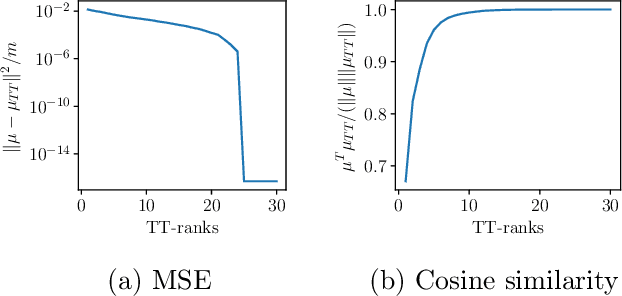
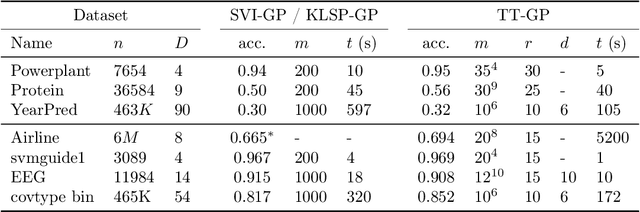
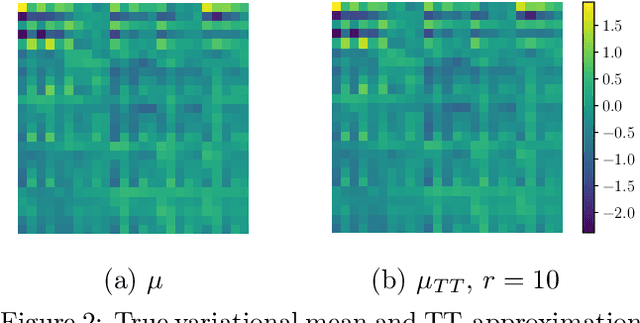

We propose a method (TT-GP) for approximate inference in Gaussian Process (GP) models. We build on previous scalable GP research including stochastic variational inference based on inducing inputs, kernel interpolation, and structure exploiting algebra. The key idea of our method is to use Tensor Train decomposition for variational parameters, which allows us to train GPs with billions of inducing inputs and achieve state-of-the-art results on several benchmarks. Further, our approach allows for training kernels based on deep neural networks without any modifications to the underlying GP model. A neural network learns a multidimensional embedding for the data, which is used by the GP to make the final prediction. We train GP and neural network parameters end-to-end without pretraining, through maximization of GP marginal likelihood. We show the efficiency of the proposed approach on several regression and classification benchmark datasets including MNIST, CIFAR-10, and Airline.
Exponential Machines
Dec 08, 2017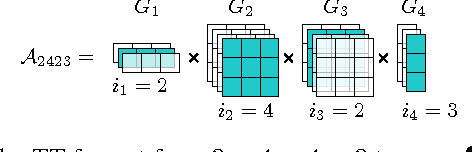
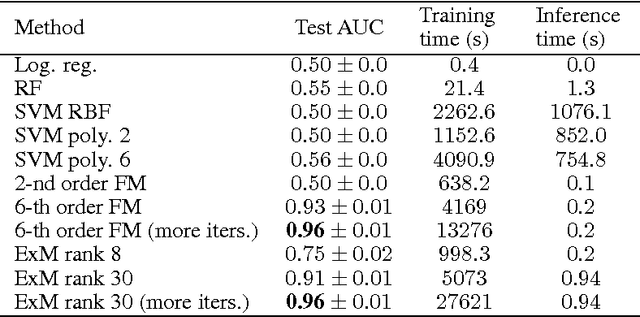
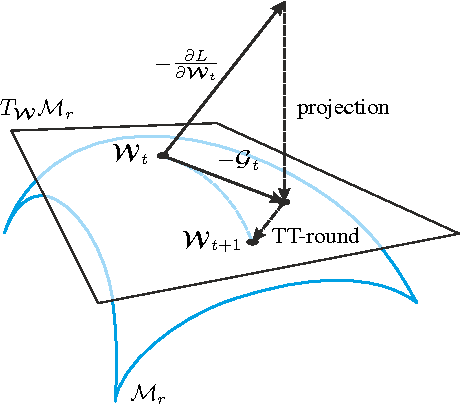

Modeling interactions between features improves the performance of machine learning solutions in many domains (e.g. recommender systems or sentiment analysis). In this paper, we introduce Exponential Machines (ExM), a predictor that models all interactions of every order. The key idea is to represent an exponentially large tensor of parameters in a factorized format called Tensor Train (TT). The Tensor Train format regularizes the model and lets you control the number of underlying parameters. To train the model, we develop a stochastic Riemannian optimization procedure, which allows us to fit tensors with 2^160 entries. We show that the model achieves state-of-the-art performance on synthetic data with high-order interactions and that it works on par with high-order factorization machines on a recommender system dataset MovieLens 100K.
Ultimate tensorization: compressing convolutional and FC layers alike
Nov 10, 2016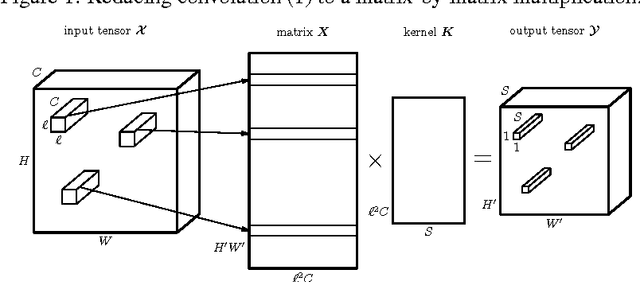

Convolutional neural networks excel in image recognition tasks, but this comes at the cost of high computational and memory complexity. To tackle this problem, [1] developed a tensor factorization framework to compress fully-connected layers. In this paper, we focus on compressing convolutional layers. We show that while the direct application of the tensor framework [1] to the 4-dimensional kernel of convolution does compress the layer, we can do better. We reshape the convolutional kernel into a tensor of higher order and factorize it. We combine the proposed approach with the previous work to compress both convolutional and fully-connected layers of a network and achieve 80x network compression rate with 1.1% accuracy drop on the CIFAR-10 dataset.
Tensorizing Neural Networks
Dec 20, 2015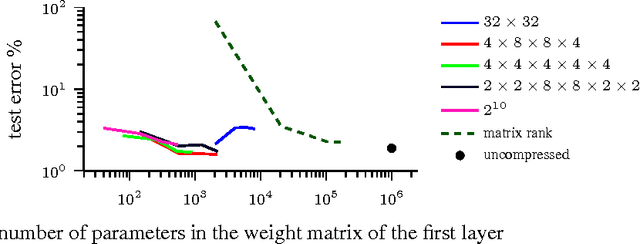
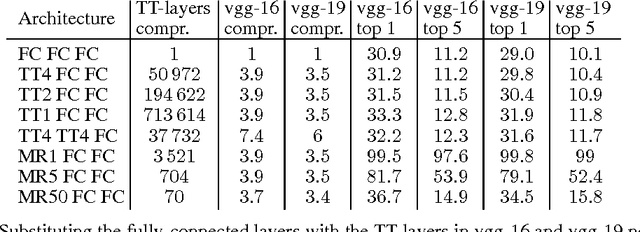
Deep neural networks currently demonstrate state-of-the-art performance in several domains. At the same time, models of this class are very demanding in terms of computational resources. In particular, a large amount of memory is required by commonly used fully-connected layers, making it hard to use the models on low-end devices and stopping the further increase of the model size. In this paper we convert the dense weight matrices of the fully-connected layers to the Tensor Train format such that the number of parameters is reduced by a huge factor and at the same time the expressive power of the layer is preserved. In particular, for the Very Deep VGG networks we report the compression factor of the dense weight matrix of a fully-connected layer up to 200000 times leading to the compression factor of the whole network up to 7 times.