 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiering as a Stochastic Submodular Optimization Problem
May 16, 2020
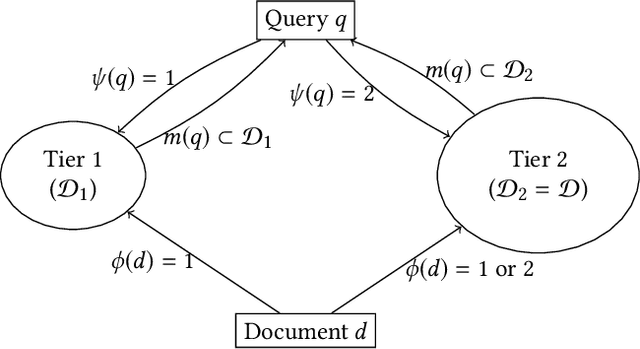
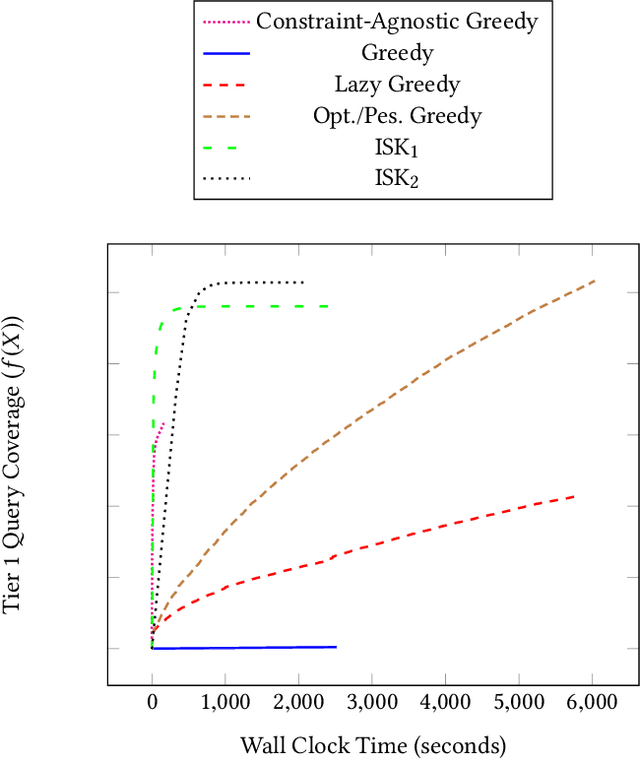
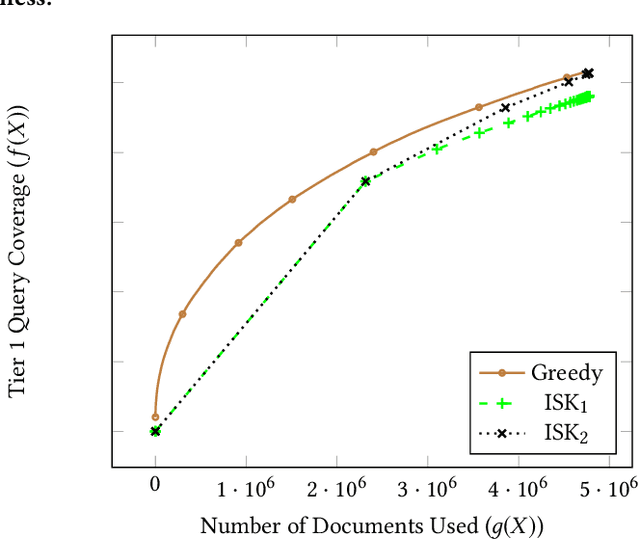
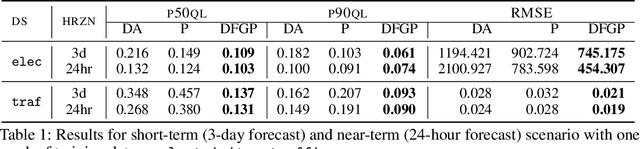
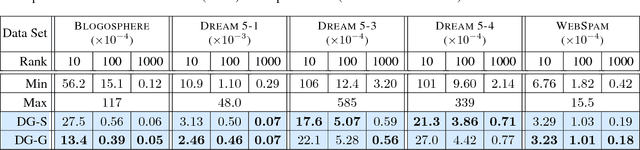
Tiering is an essential technique for building large-scale information retrieval systems. While the selection of documents for high priority tiers critically impacts the efficiency of tiering, past work focuses on optimizing it with respect to a static set of queries in the history, and generalizes poorly to the future traffic. Instead, we formulate the optimal tiering as a stochastic optimization problem, and follow the methodology of regularized empirical risk minimization to maximize the \emph{generalization performance} of the system. We also show that the optimization problem can be cast as a stochastic submodular optimization problem with a submodular knapsack constraint, and we develop efficient optimization algorithms by leveraging this connection.
Recognizing Variables from their Data via Deep Embeddings of Distributions
Sep 11, 2019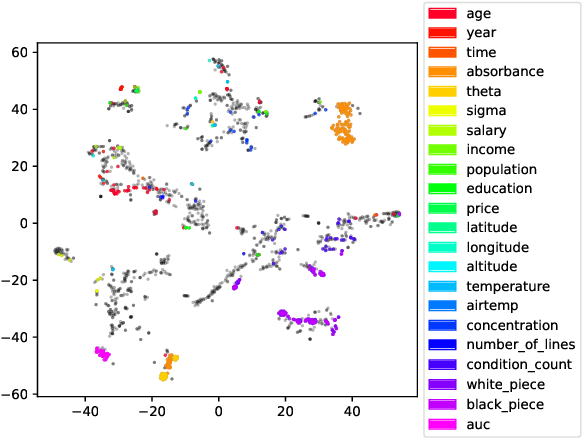
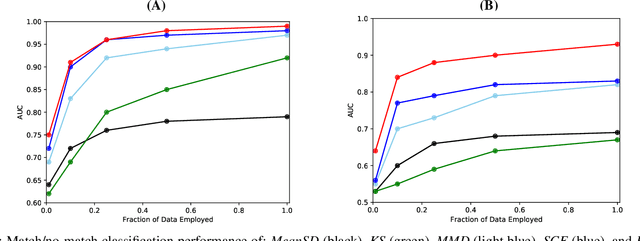
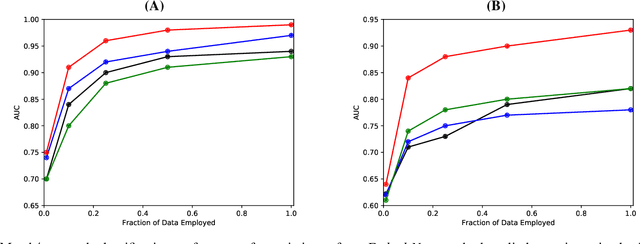
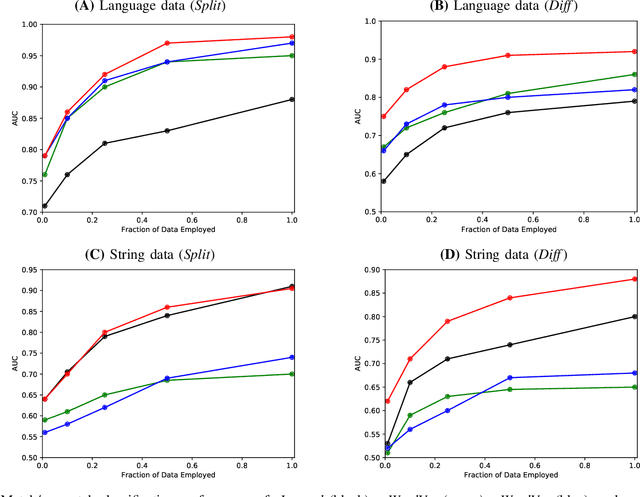
A key obstacle in automated analytics and meta-learning is the inability to recognize when different datasets contain measurements of the same variable. Because provided attribute labels are often uninformative in practice, this task may be more robustly addressed by leveraging the data values themselves rather than just relying on their arbitrarily selected variable names. Here, we present a computationally efficient method to identify high-confidence variable matches between a given set of data values and a large repository of previously encountered datasets. Our approach enjoys numerous advantages over distributional similarity based techniques because we leverage learned vector embeddings of datasets which adaptively account for natural forms of data variation encountered in practice. Based on the neural architecture of deep sets, our embeddings can be computed for both numeric and string data. In dataset search and schema matching tasks, our methods outperform standard statistical techniques and we find that the learned embeddings generalize well to new data sources.
Deep Factors for Forecasting
May 28, 2019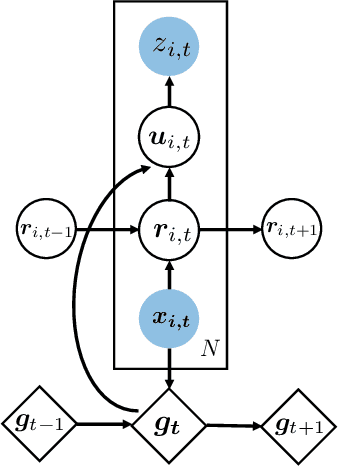
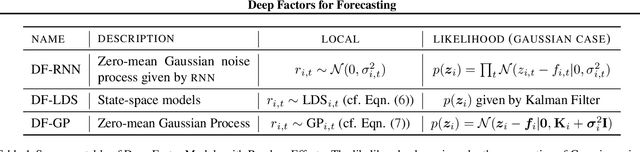
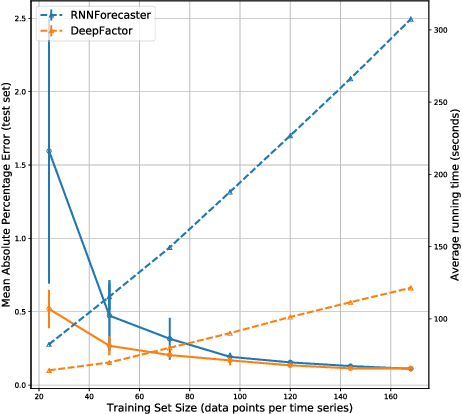
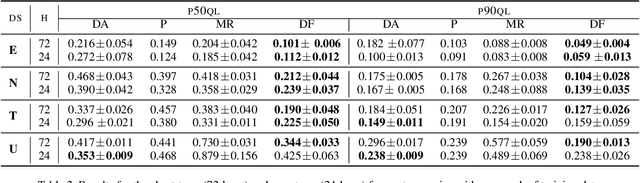
Producing probabilistic forecasts for large collections of similar and/or dependent time series is a practically relevant and challenging task. Classical time series models fail to capture complex patterns in the data, and multivariate techniques struggle to scale to large problem sizes. Their reliance on strong structural assumptions makes them data-efficient, and allows them to provide uncertainty estimates. The converse is true for models based on deep neural networks, which can learn complex patterns and dependencies given enough data. In this paper, we propose a hybrid model that incorporates the benefits of both approaches. Our new method is data-driven and scalable via a latent, global, deep component. It also handles uncertainty through a local classical model. We provide both theoretical and empirical evidence for the soundness of our approach through a necessary and sufficient decomposition of exchangeable time series into a global and a local part. Our experiments demonstrate the advantages of our model both in term of data efficiency, accuracy and computational complexity.
* http://proceedings.mlr.press/v97/wang19k/wang19k.pdf. arXiv admin note: substantial text overlap with arXiv:1812.00098
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Deep Factors with Gaussian Processes for Forecasting
Nov 30, 2018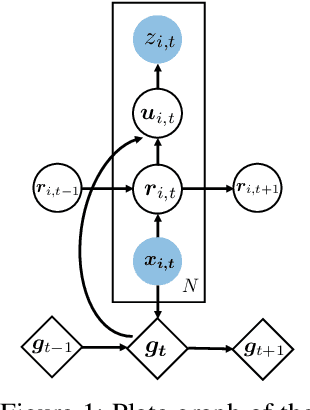
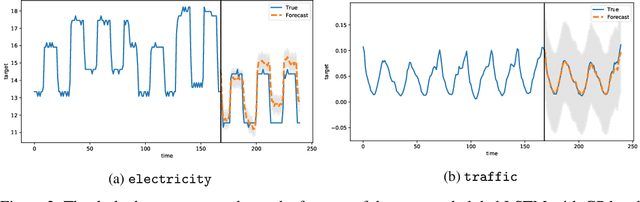
A large collection of time series poses significant challenges for classical and neural forecasting approaches. Classical time series models fail to fit data well and to scale to large problems, but succeed at providing uncertainty estimates. The converse is true for deep neural networks. In this paper, we propose a hybrid model that incorporates the benefits of both approaches. Our new method is data-driven and scalable via a latent, global, deep component. It also handles uncertainty through a local classical Gaussian Process model. Our experiments demonstrate that our method obtains higher accuracy than state-of-the-art methods.
Efficient Multitask Feature and Relationship Learning
Sep 16, 2018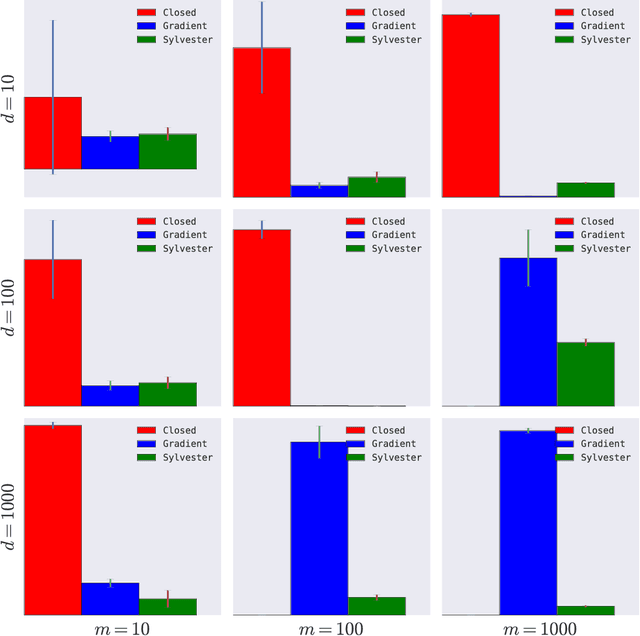

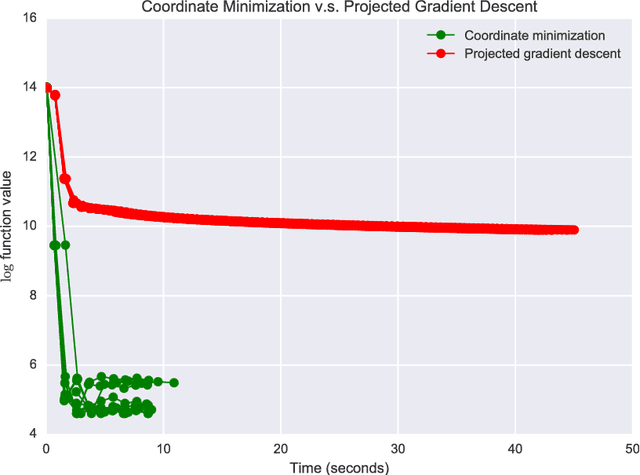
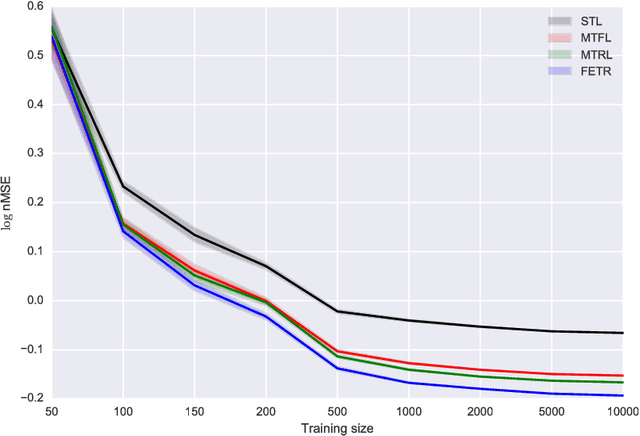
We consider a multitask learning problem, in which several predictors are learned jointly. Prior research has shown that learning the relations between tasks, and between the input features, together with the predictor, can lead to better generalization and interpretability, which proved to be useful for applications in many domains. In this paper, we consider a formulation of multitask learning that learns the relationships both between tasks and between features, represented through a task covariance and a feature covariance matrix, respectively. First, we demonstrate that existing methods proposed for this problem present an issue that may lead to ill-posed optimization. We then propose an alternative formulation, as well as an efficient algorithm to optimize it. Using ideas from optimization and graph theory, we propose an efficient coordinate-wise minimization algorithm that has a closed form solution for each block subproblem. Our experiments show that the proposed optimization method is orders of magnitude faster than its competitors. We also provide a nonlinear extension that is able to achieve better generalization than existing methods.
Detecting and Correcting for Label Shift with Black Box Predictors
Jul 26, 2018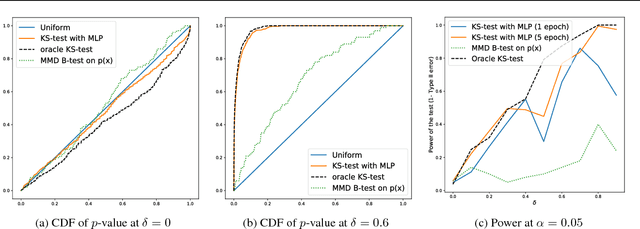
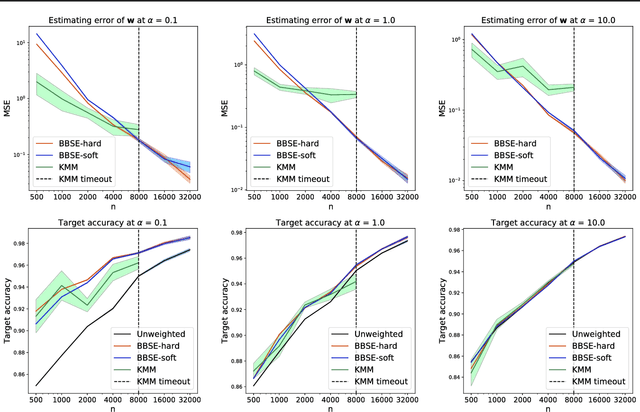
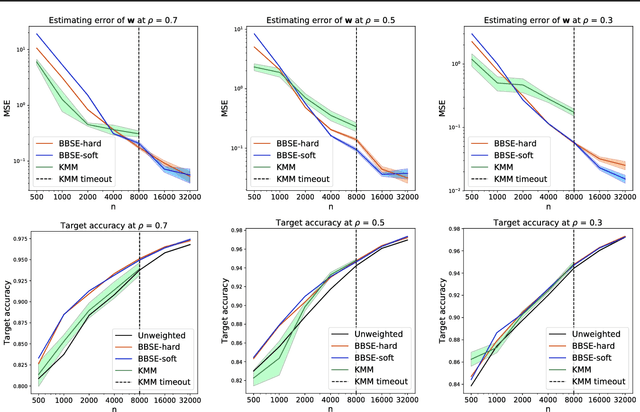
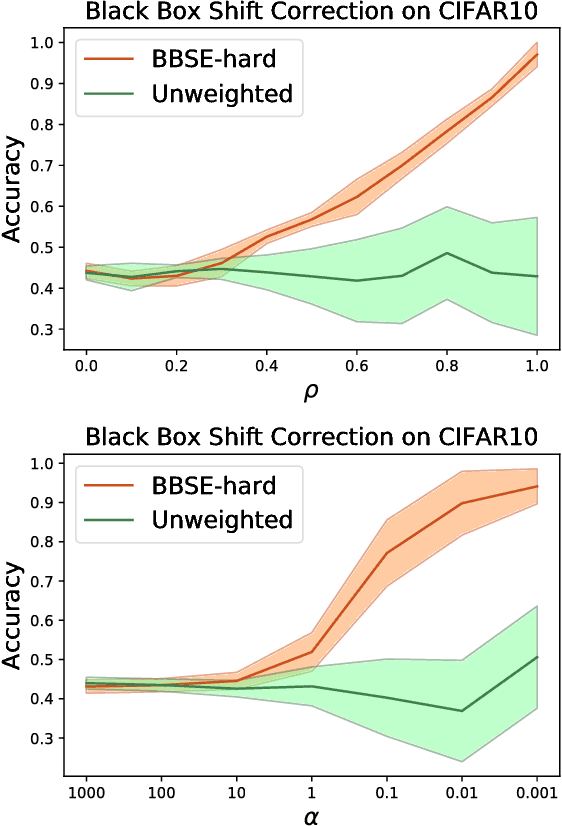
Faced with distribution shift between training and test set, we wish to detect and quantify the shift, and to correct our classifiers without test set labels. Motivated by medical diagnosis, where diseases (targets) cause symptoms (observations), we focus on label shift, where the label marginal $p(y)$ changes but the conditional $p(x| y)$ does not. We propose Black Box Shift Estimation (BBSE) to estimate the test distribution $p(y)$. BBSE exploits arbitrary black box predictors to reduce dimensionality prior to shift correction. While better predictors give tighter estimates, BBSE works even when predictors are biased, inaccurate, or uncalibrated, so long as their confusion matrices are invertible. We prove BBSE's consistency, bound its error, and introduce a statistical test that uses BBSE to detect shift. We also leverage BBSE to correct classifiers. Experiments demonstrate accurate estimates and improved prediction, even on high-dimensional datasets of natural images.
Deep Graphs
Jun 04, 2018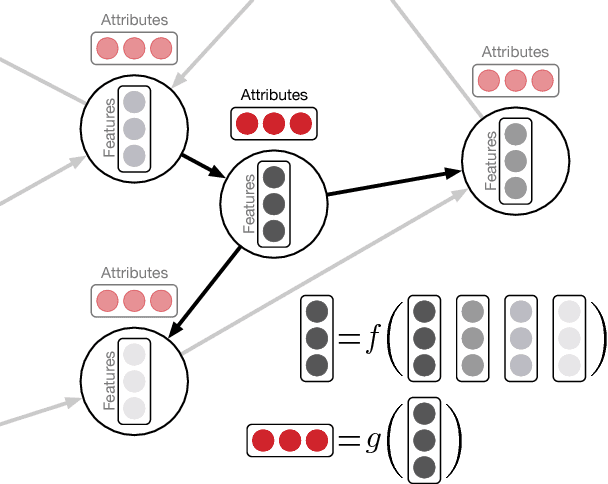
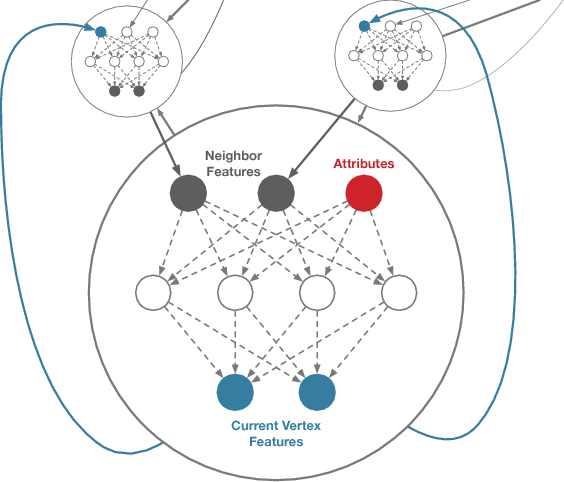
We propose an algorithm for deep learning on networks and graphs. It relies on the notion that many graph algorithms, such as PageRank, Weisfeiler-Lehman, or Message Passing can be expressed as iterative vertex updates. Unlike previous methods which rely on the ingenuity of the designer, Deep Graphs are adaptive to the estimation problem. Training and deployment are both efficient, since the cost is $O(|E| + |V|)$, where $E$ and $V$ are the sets of edges and vertices respectively. In short, we learn the recurrent update functions rather than positing their specific functional form. This yields an algorithm that achieves excellent accuracy on both graph labeling and regression tasks.
Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning
Nov 15, 2017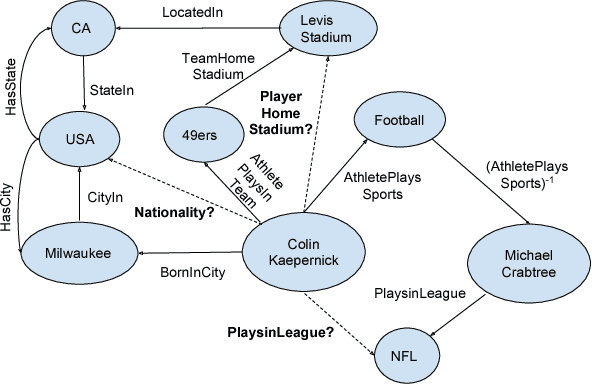
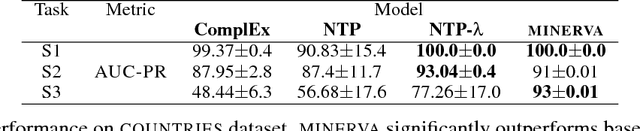
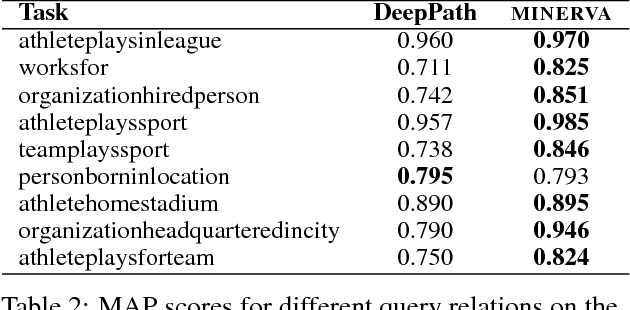
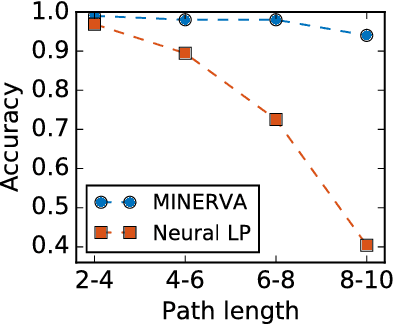
Knowledge bases (KB), both automatically and manually constructed, are often incomplete --- many valid facts can be inferred from the KB by synthesizing existing information. A popular approach to KB completion is to infer new relations by combinatory reasoning over the information found along other paths connecting a pair of entities. Given the enormous size of KBs and the exponential number of paths, previous path-based models have considered only the problem of predicting a missing relation given two entities or evaluating the truth of a proposed triple. Additionally, these methods have traditionally used random paths between fixed entity pairs or more recently learned to pick paths between them. We propose a new algorithm MINERVA, which addresses the much more difficult and practical task of answering questions where the relation is known, but only one entity. Since random walks are impractical in a setting with combinatorially many destinations from a start node, we present a neural reinforcement learning approach which learns how to navigate the graph conditioned on the input query to find predictive paths. Empirically, this approach obtains state-of-the-art results on several datasets, significantly outperforming prior methods.
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy
Feb 10, 2017
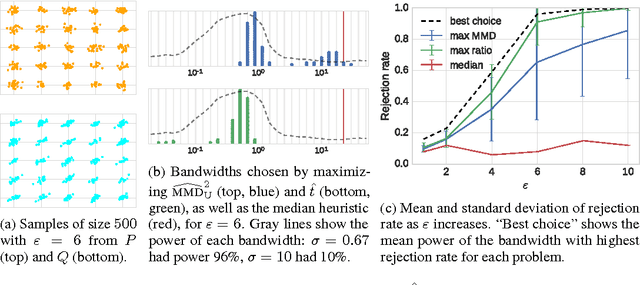
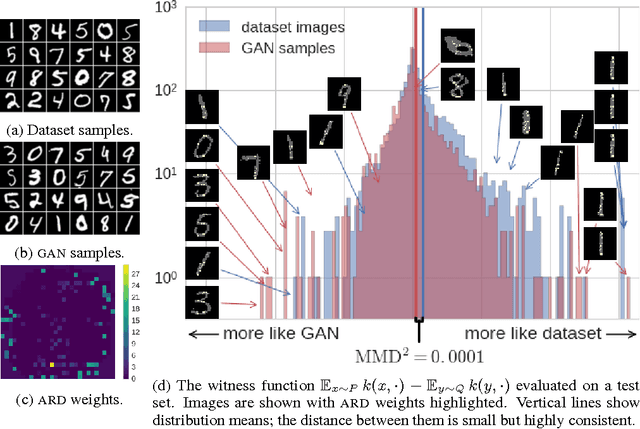

We propose a method to optimize the representation and distinguishability of samples from two probability distributions, by maximizing the estimated power of a statistical test based on the maximum mean discrepancy (MMD). This optimized MMD is applied to the setting of unsupervised learning by generative adversarial networks (GAN), in which a model attempts to generate realistic samples, and a discriminator attempts to tell these apart from data samples. In this context, the MMD may be used in two roles: first, as a discriminator, either directly on the samples, or on features of the samples. Second, the MMD can be used to evaluate the performance of a generative model, by testing the model's samples against a reference data set. In the latter role, the optimized MMD is particularly helpful, as it gives an interpretable indication of how the model and data distributions differ, even in cases where individual model samples are not easily distinguished either by eye or by classifier.