 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
Leveraging the Third Dimension in Contrastive Learning
Jan 27, 2023



Self-Supervised Learning (SSL) methods operate on unlabeled data to learn robust representations useful for downstream tasks. Most SSL methods rely on augmentations obtained by transforming the 2D image pixel map. These augmentations ignore the fact that biological vision takes place in an immersive three-dimensional, temporally contiguous environment, and that low-level biological vision relies heavily on depth cues. Using a signal provided by a pretrained state-of-the-art monocular RGB-to-depth model (the \emph{Depth Prediction Transformer}, Ranftl et al., 2021), we explore two distinct approaches to incorporating depth signals into the SSL framework. First, we evaluate contrastive learning using an RGB+depth input representation. Second, we use the depth signal to generate novel views from slightly different camera positions, thereby producing a 3D augmentation for contrastive learning. We evaluate these two approaches on three different SSL methods -- BYOL, SimSiam, and SwAV -- using ImageNette (10 class subset of ImageNet), ImageNet-100 and ImageNet-1k datasets. We find that both approaches to incorporating depth signals improve the robustness and generalization of the baseline SSL methods, though the first approach (with depth-channel concatenation) is superior. For instance, BYOL with the additional depth channel leads to an increase in downstream classification accuracy from 85.3\% to 88.0\% on ImageNette and 84.1\% to 87.0\% on ImageNet-C.
Representation Learning in Deep RL via Discrete Information Bottleneck
Dec 28, 2022



Several self-supervised representation learning methods have been proposed for reinforcement learning (RL) with rich observations. For real-world applications of RL, recovering underlying latent states is crucial, particularly when sensory inputs contain irrelevant and exogenous information. In this work, we study how information bottlenecks can be used to construct latent states efficiently in the presence of task-irrelevant information. We propose architectures that utilize variational and discrete information bottlenecks, coined as RepDIB, to learn structured factorized representations. Exploiting the expressiveness bought by factorized representations, we introduce a simple, yet effective, bottleneck that can be integrated with any existing self-supervised objective for RL. We demonstrate this across several online and offline RL benchmarks, along with a real robot arm task, where we find that compressed representations with RepDIB can lead to strong performance improvements, as the learned bottlenecks help predict only the relevant state while ignoring irrelevant information.
Towards Data-Driven Offline Simulations for Online Reinforcement Learning
Nov 14, 2022



Modern decision-making systems, from robots to web recommendation engines, are expected to adapt: to user preferences, changing circumstances or even new tasks. Yet, it is still uncommon to deploy a dynamically learning agent (rather than a fixed policy) to a production system, as it's perceived as unsafe. Using historical data to reason about learning algorithms, similar to offline policy evaluation (OPE) applied to fixed policies, could help practitioners evaluate and ultimately deploy such adaptive agents to production. In this work, we formalize offline learner simulation (OLS) for reinforcement learning (RL) and propose a novel evaluation protocol that measures both fidelity and efficiency of the simulation. For environments with complex high-dimensional observations, we propose a semi-parametric approach that leverages recent advances in latent state discovery in order to achieve accurate and efficient offline simulations. In preliminary experiments, we show the advantage of our approach compared to fully non-parametric baselines. The code to reproduce these experiments will be made available at https://github.com/microsoft/rl-offline-simulation.
Neural Active Learning on Heteroskedastic Distributions
Nov 02, 2022



Models that can actively seek out the best quality training data hold the promise of more accurate, adaptable, and efficient machine learning. State-of-the-art active learning techniques tend to prefer examples that are the most difficult to classify. While this works well on homogeneous datasets, we find that it can lead to catastrophic failures when performed on multiple distributions with different degrees of label noise or heteroskedasticity. These active learning algorithms strongly prefer to draw from the distribution with more noise, even if their examples have no informative structure (such as solid color images with random labels). To this end, we demonstrate the catastrophic failure of these active learning algorithms on heteroskedastic distributions and propose a fine-tuning-based approach to mitigate these failures. Further, we propose a new algorithm that incorporates a model difference scoring function for each data point to filter out the noisy examples and sample clean examples that maximize accuracy, outperforming the existing active learning techniques on the heteroskedastic datasets. We hope these observations and techniques are immediately helpful to practitioners and can help to challenge common assumptions in the design of active learning algorithms.
Discrete Factorial Representations as an Abstraction for Goal Conditioned Reinforcement Learning
Nov 01, 2022Goal-conditioned reinforcement learning (RL) is a promising direction for training agents that are capable of solving multiple tasks and reach a diverse set of objectives. How to \textit{specify} and \textit{ground} these goals in such a way that we can both reliably reach goals during training as well as generalize to new goals during evaluation remains an open area of research. Defining goals in the space of noisy and high-dimensional sensory inputs poses a challenge for training goal-conditioned agents, or even for generalization to novel goals. We propose to address this by learning factorial representations of goals and processing the resulting representation via a discretization bottleneck, for coarser goal specification, through an approach we call DGRL. We show that applying a discretizing bottleneck can improve performance in goal-conditioned RL setups, by experimentally evaluating this method on tasks ranging from maze environments to complex robotic navigation and manipulation. Additionally, we prove a theorem lower-bounding the expected return on out-of-distribution goals, while still allowing for specifying goals with expressive combinatorial structure.
Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information
Oct 31, 2022Learning to control an agent from data collected offline in a rich pixel-based visual observation space is vital for real-world applications of reinforcement learning (RL). A major challenge in this setting is the presence of input information that is hard to model and irrelevant to controlling the agent. This problem has been approached by the theoretical RL community through the lens of exogenous information, i.e, any control-irrelevant information contained in observations. For example, a robot navigating in busy streets needs to ignore irrelevant information, such as other people walking in the background, textures of objects, or birds in the sky. In this paper, we focus on the setting with visually detailed exogenous information, and introduce new offline RL benchmarks offering the ability to study this problem. We find that contemporary representation learning techniques can fail on datasets where the noise is a complex and time dependent process, which is prevalent in practical applications. To address these, we propose to use multi-step inverse models, which have seen a great deal of interest in the RL theory community, to learn Agent-Controller Representations for Offline-RL (ACRO). Despite being simple and requiring no reward, we show theoretically and empirically that the representation created by this objective greatly outperforms baselines.
CNT : A new Algorithm for Leveraging Top-Down Feedback
Oct 18, 2022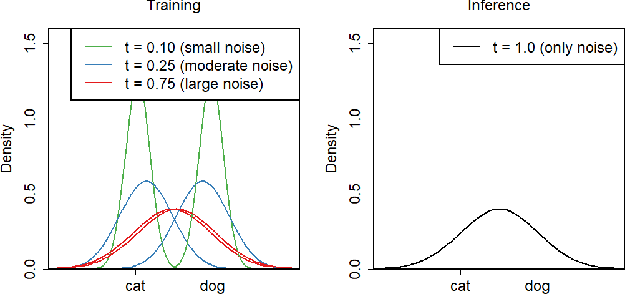
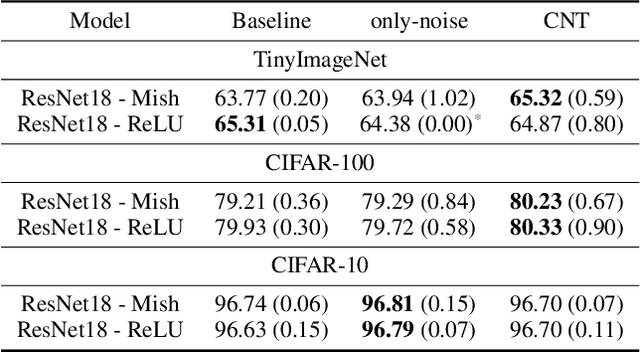
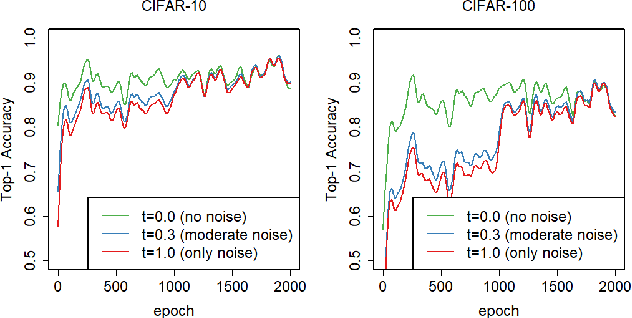
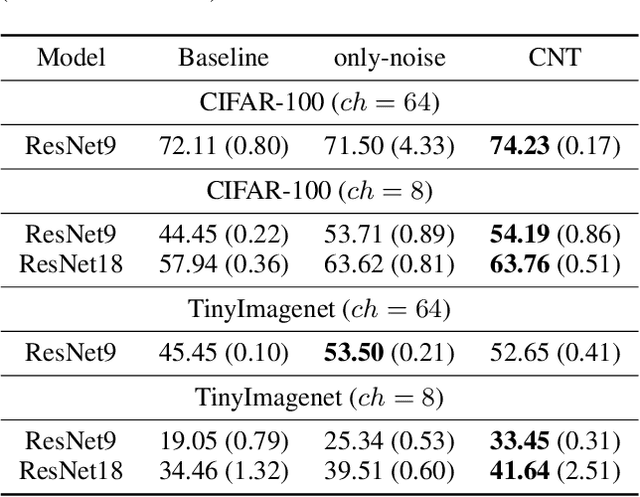
We propose a novel regularizer for supervised learning called Conditioning on Noisy Targets (CNT). This approach consists in conditioning the model on a noisy version of the target(s) (e.g., actions in imitation learning or labels in classification) at a random noise level (from small to large noise). At inference time, since we do not know the target, we run the network with only noise in place of the noisy target. CNT provides hints through the noisy label (with less noise, we can more easily infer the true target). This give two main benefits: 1) the top-down feedback allows the model to focus on simpler and more digestible sub-problems and 2) rather than learning to solve the task from scratch, the model will first learn to master easy examples (with less noise), while slowly progressing toward harder examples (with more noise).
Guaranteed Discovery of Controllable Latent States with Multi-Step Inverse Models
Jul 17, 2022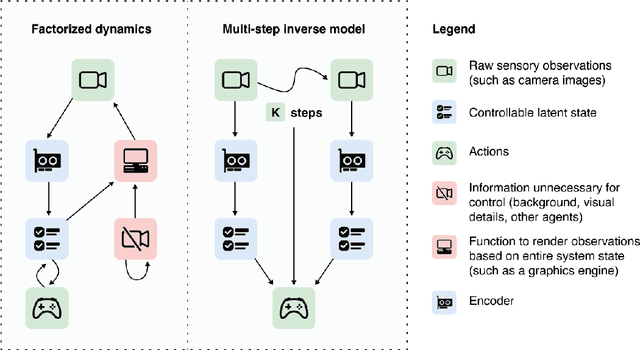
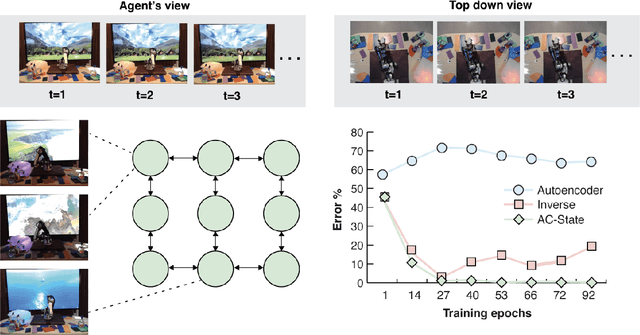
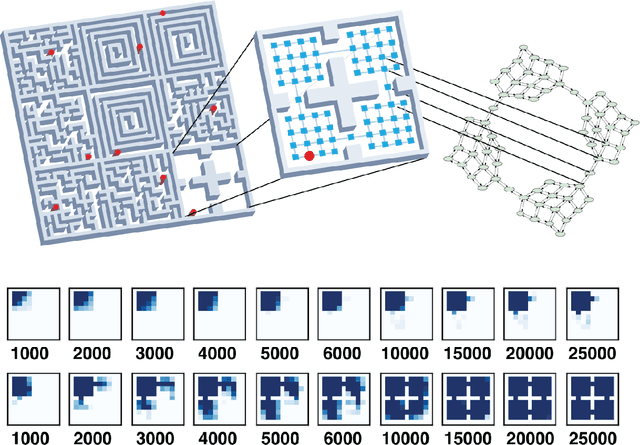
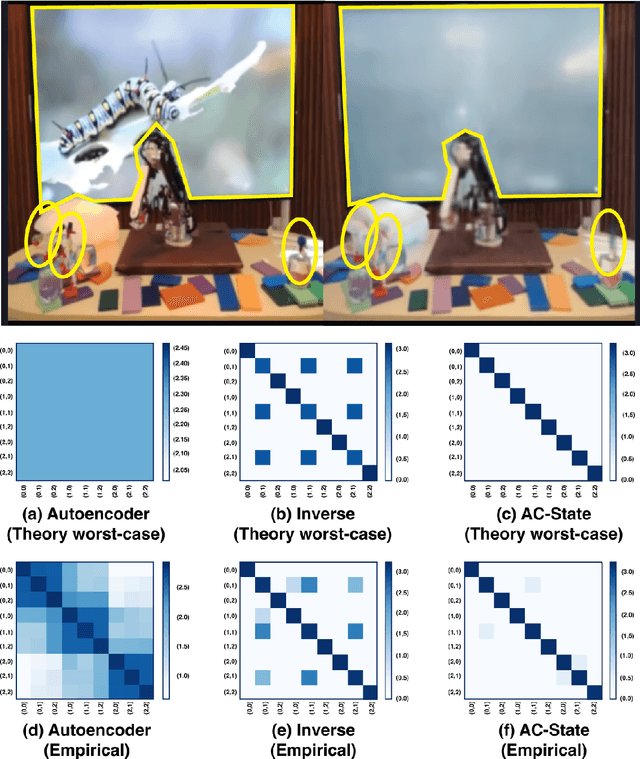
A person walking along a city street who tries to model all aspects of the world would quickly be overwhelmed by a multitude of shops, cars, and people moving in and out of view, following their own complex and inscrutable dynamics. Exploration and navigation in such an environment is an everyday task, requiring no vast exertion of mental resources. Is it possible to turn this fire hose of sensory information into a minimal latent state which is necessary and sufficient for an agent to successfully act in the world? We formulate this question concretely, and propose the Agent-Controllable State Discovery algorithm (AC-State), which has theoretical guarantees and is practically demonstrated to discover the \textit{minimal controllable latent state} which contains all of the information necessary for controlling the agent, while fully discarding all irrelevant information. This algorithm consists of a multi-step inverse model (predicting actions from distant observations) with an information bottleneck. AC-State enables localization, exploration, and navigation without reward or demonstrations. We demonstrate the discovery of controllable latent state in three domains: localizing a robot arm with distractions (e.g., changing lighting conditions and background), exploring in a maze alongside other agents, and navigating in the Matterport house simulator.
Temporal Latent Bottleneck: Synthesis of Fast and Slow Processing Mechanisms in Sequence Learning
May 30, 2022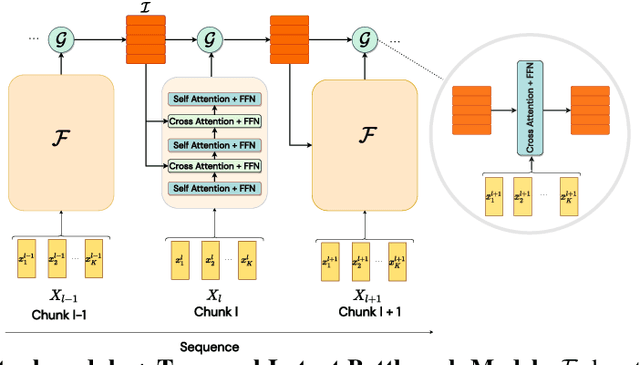
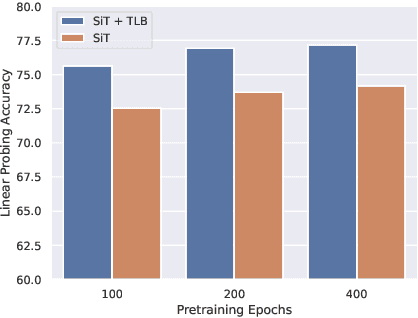
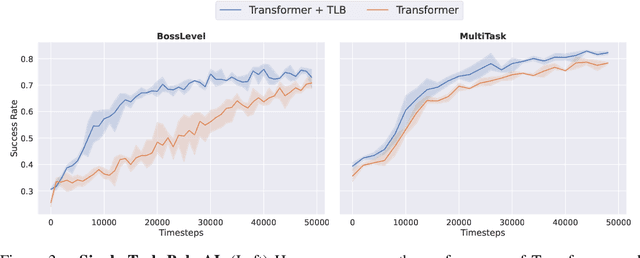
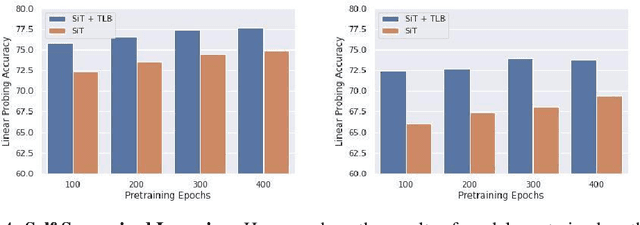
Recurrent neural networks have a strong inductive bias towards learning temporally compressed representations, as the entire history of a sequence is represented by a single vector. By contrast, Transformers have little inductive bias towards learning temporally compressed representations, as they allow for attention over all previously computed elements in a sequence. Having a more compressed representation of a sequence may be beneficial for generalization, as a high-level representation may be more easily re-used and re-purposed and will contain fewer irrelevant details. At the same time, excessive compression of representations comes at the cost of expressiveness. We propose a solution which divides computation into two streams. A slow stream that is recurrent in nature aims to learn a specialized and compressed representation, by forcing chunks of $K$ time steps into a single representation which is divided into multiple vectors. At the same time, a fast stream is parameterized as a Transformer to process chunks consisting of $K$ time-steps conditioned on the information in the slow-stream. In the proposed approach we hope to gain the expressiveness of the Transformer, while encouraging better compression and structuring of representations in the slow stream. We show the benefits of the proposed method in terms of improved sample efficiency and generalization performance as compared to various competitive baselines for visual perception and sequential decision making tasks.