 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Controllable Text Generation Techniques
May 04, 2020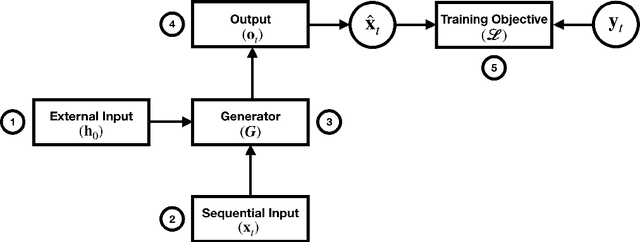
Neural controllable text generation is an important area gaining attention due to its plethora of applications. In this work, we provide a new schema of the pipeline of the generation process by classifying it into five modules. We present an overview of the various techniques used to modulate each of these five modules to provide with control of attributes in the generation process. We also provide an analysis on the advantages and disadvantages of these techniques and open paths to develop new architectures based on the combination of the modules described in this paper.
Politeness Transfer: A Tag and Generate Approach
May 01, 2020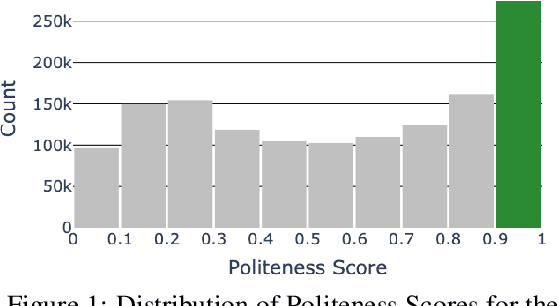
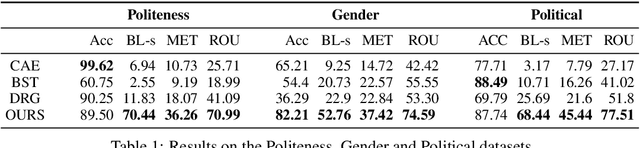
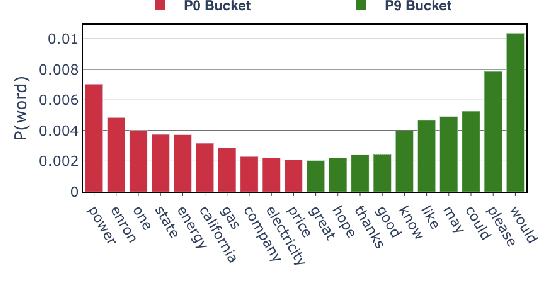

This paper introduces a new task of politeness transfer which involves converting non-polite sentences to polite sentences while preserving the meaning. We also provide a dataset of more than 1.39 instances automatically labeled for politeness to encourage benchmark evaluations on this new task. We design a tag and generate pipeline that identifies stylistic attributes and subsequently generates a sentence in the target style while preserving most of the source content. For politeness as well as five other transfer tasks, our model outperforms the state-of-the-art methods on automatic metrics for content preservation, with a comparable or better performance on style transfer accuracy. Additionally, our model surpasses existing methods on human evaluations for grammaticality, meaning preservation and transfer accuracy across all the six style transfer tasks. The data and code is located at https://github.com/tag-and-generate.
Style Variation as a Vantage Point for Code-Switching
May 01, 2020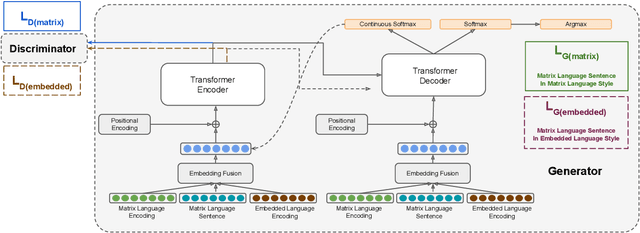
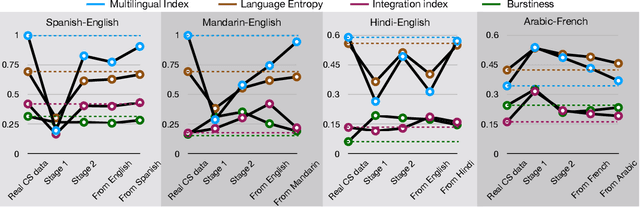
Code-Switching (CS) is a common phenomenon observed in several bilingual and multilingual communities, thereby attaining prevalence in digital and social media platforms. This increasing prominence demands the need to model CS languages for critical downstream tasks. A major problem in this domain is the dearth of annotated data and a substantial corpora to train large scale neural models. Generating vast amounts of quality text assists several down stream tasks that heavily rely on language modeling such as speech recognition, text-to-speech synthesis etc,. We present a novel vantage point of CS to be style variations between both the participating languages. Our approach does not need any external annotations such as lexical language ids. It mainly relies on easily obtainable monolingual corpora without any parallel alignment and a limited set of naturally CS sentences. We propose a two-stage generative adversarial training approach where the first stage generates competitive negative examples for CS and the second stage generates more realistic CS sentences. We present our experiments on the following pairs of languages: Spanish-English, Mandarin-English, Hindi-English and Arabic-French. We show that the trends in metrics for generated CS move closer to real CS data in each of the above language pairs through the dual stage training process. We believe this viewpoint of CS as style variations opens new perspectives for modeling various tasks in CS text.
Topological Sort for Sentence Ordering
May 01, 2020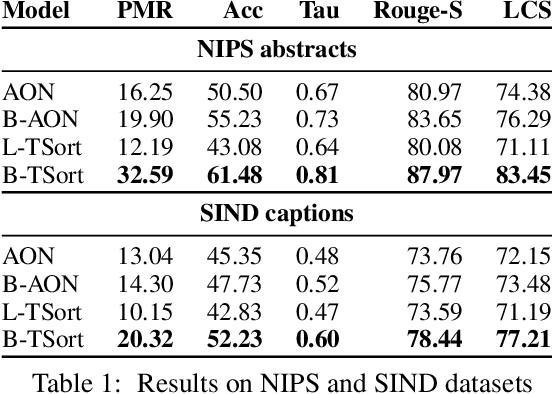
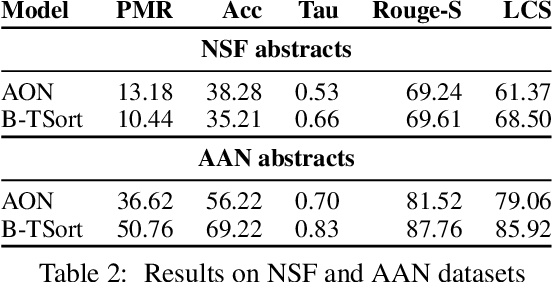
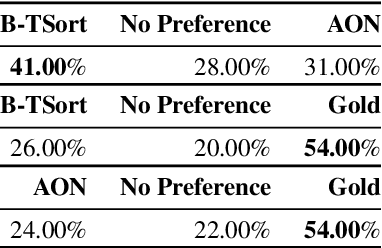
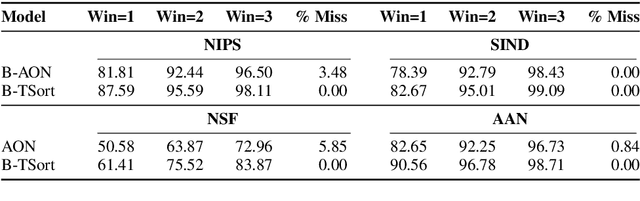
Sentence ordering is the task of arranging the sentences of a given text in the correct order. Recent work using deep neural networks for this task has framed it as a sequence prediction problem. In this paper, we propose a new framing of this task as a constraint solving problem and introduce a new technique to solve it. Additionally, we propose a human evaluation for this task. The results on both automatic and human metrics across four different datasets show that this new technique is better at capturing coherence in documents.
Universal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020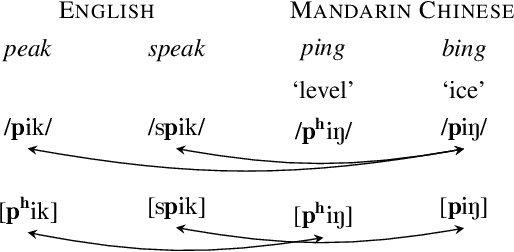

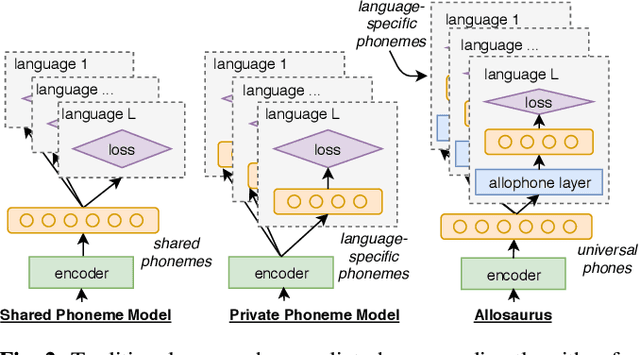

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.
Towards Zero-shot Learning for Automatic Phonemic Transcription
Feb 26, 2020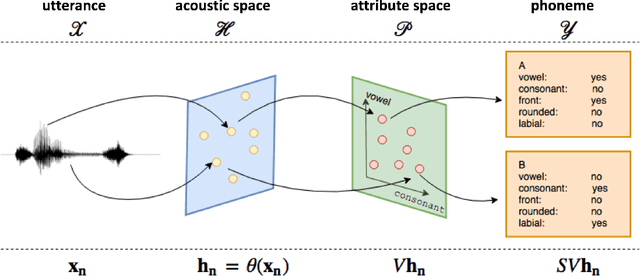
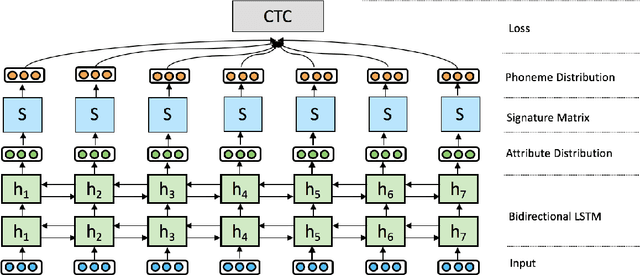
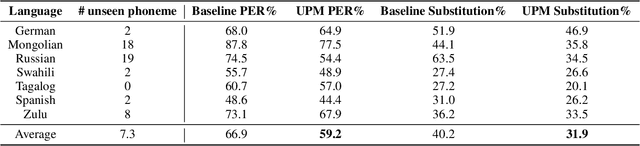
Automatic phonemic transcription tools are useful for low-resource language documentation. However, due to the lack of training sets, only a tiny fraction of languages have phonemic transcription tools. Fortunately, multilingual acoustic modeling provides a solution given limited audio training data. A more challenging problem is to build phonemic transcribers for languages with zero training data. The difficulty of this task is that phoneme inventories often differ between the training languages and the target language, making it infeasible to recognize unseen phonemes. In this work, we address this problem by adopting the idea of zero-shot learning. Our model is able to recognize unseen phonemes in the target language without any training data. In our model, we decompose phonemes into corresponding articulatory attributes such as vowel and consonant. Instead of predicting phonemes directly, we first predict distributions over articulatory attributes, and then compute phoneme distributions with a customized acoustic model. We evaluate our model by training it using 13 languages and testing it using 7 unseen languages. We find that it achieves 7.7% better phoneme error rate on average over a standard multilingual model.
Towards Minimal Supervision BERT-based Grammar Error Correction
Jan 10, 2020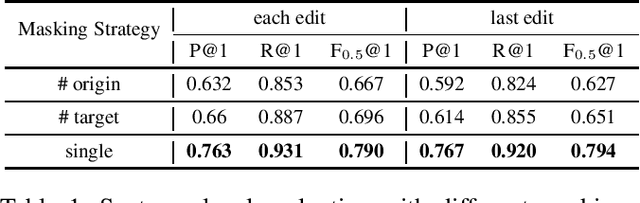
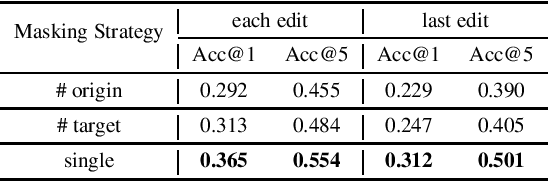

Current grammatical error correction (GEC) models typically consider the task as sequence generation, which requires large amounts of annotated data and limit the applications in data-limited settings. We try to incorporate contextual information from pre-trained language model to leverage annotation and benefit multilingual scenarios. Results show strong potential of Bidirectional Encoder Representations from Transformers (BERT) in grammatical error correction task.
A Resource for Computational Experiments on Mapudungun
Dec 04, 2019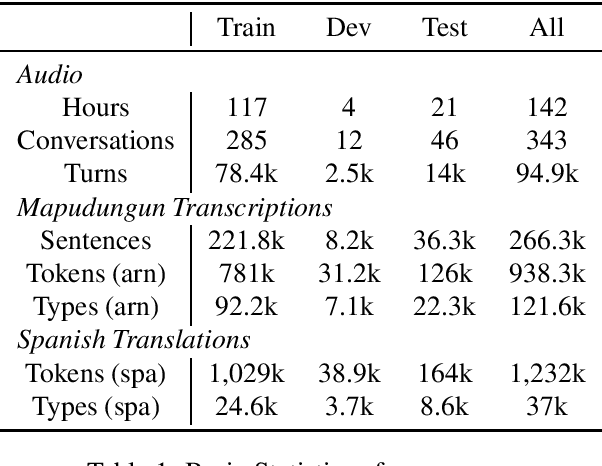

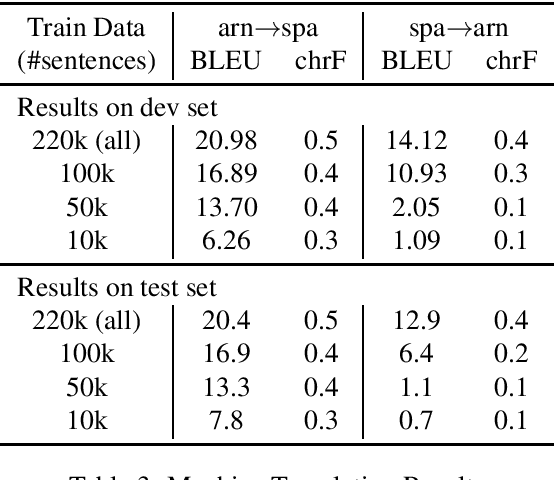
We present a resource for computational experiments on Mapudungun, a polysynthetic indigenous language spoken in Chile with upwards of 200 thousand speakers. We provide 142 hours of culturally significant conversations in the domain of medical treatment. The conversations are fully transcribed and translated into Spanish. The transcriptions also include annotations for code-switching and non-standard pronunciations. We also provide baseline results on three core NLP tasks: speech recognition, speech synthesis, and machine translation between Spanish and Mapudungun. We further explore other applications for which the corpus will be suitable, including the study of code-switching, historical orthography change, linguistic structure, and sociological and anthropological studies.
Question Answering for Privacy Policies: Combining Computational and Legal Perspectives
Nov 03, 2019
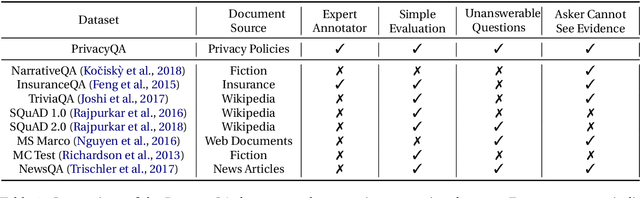

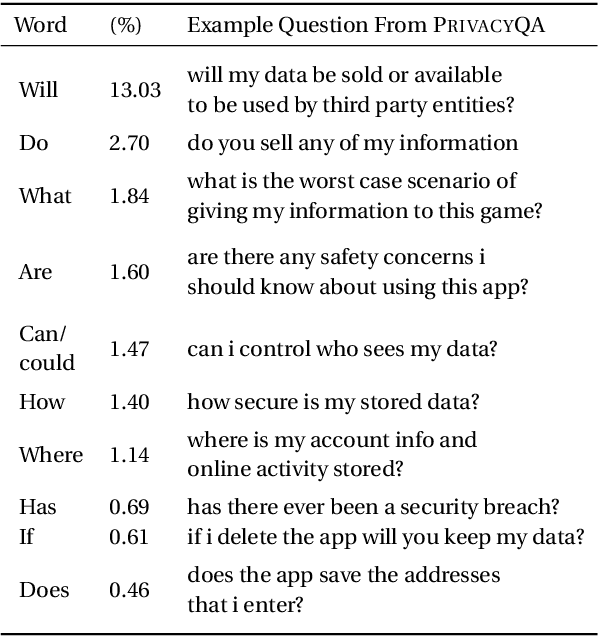
Privacy policies are long and complex documents that are difficult for users to read and understand, and yet, they have legal effects on how user data is collected, managed and used. Ideally, we would like to empower users to inform themselves about issues that matter to them, and enable them to selectively explore those issues. We present PrivacyQA, a corpus consisting of 1750 questions about the privacy policies of mobile applications, and over 3500 expert annotations of relevant answers. We observe that a strong neural baseline underperforms human performance by almost 0.3 F1 on PrivacyQA, suggesting considerable room for improvement for future systems. Further, we use this dataset to shed light on challenges to question answerability, with domain-general implications for any question answering system. The PrivacyQA corpus offers a challenging corpus for question answering, with genuine real-world utility.
A Dynamic Strategy Coach for Effective Negotiation
Sep 30, 2019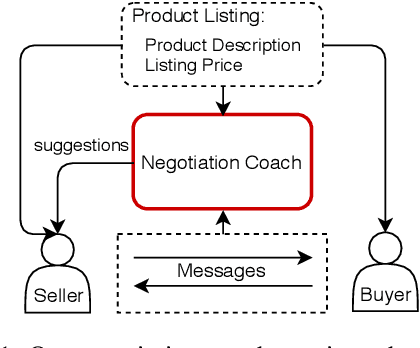
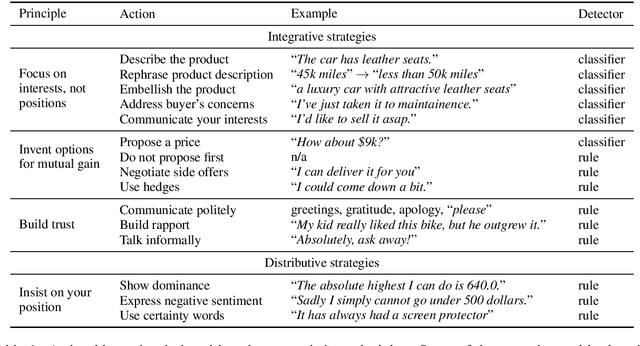


Negotiation is a complex activity involving strategic reasoning, persuasion, and psychology. An average person is often far from an expert in negotiation. Our goal is to assist humans to become better negotiators through a machine-in-the-loop approach that combines machine's advantage at data-driven decision-making and human's language generation ability. We consider a bargaining scenario where a seller and a buyer negotiate the price of an item for sale through a text-based dialog. Our negotiation coach monitors messages between them and recommends tactics in real time to the seller to get a better deal (e.g., "reject the proposal and propose a price", "talk about your personal experience with the product"). The best strategy and tactics largely depend on the context (e.g., the current price, the buyer's attitude). Therefore, we first identify a set of negotiation tactics, then learn to predict the best strategy and tactics in a given dialog context from a set of human-human bargaining dialogs. Evaluation on human-human dialogs shows that our coach increases the profits of the seller by almost 60%.