 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-level Sequence Labeling for Spoken Language Understanding using Compositional End-to-End Models
Oct 27, 2022End-to-end spoken language understanding (SLU) systems are gaining popularity over cascaded approaches due to their simplicity and ability to avoid error propagation. However, these systems model sequence labeling as a sequence prediction task causing a divergence from its well-established token-level tagging formulation. We build compositional end-to-end SLU systems that explicitly separate the added complexity of recognizing spoken mentions in SLU from the NLU task of sequence labeling. By relying on intermediate decoders trained for ASR, our end-to-end systems transform the input modality from speech to token-level representations that can be used in the traditional sequence labeling framework. This composition of ASR and NLU formulations in our end-to-end SLU system offers direct compatibility with pre-trained ASR and NLU systems, allows performance monitoring of individual components and enables the use of globally normalized losses like CRF, making them attractive in practical scenarios. Our models outperform both cascaded and direct end-to-end models on a labeling task of named entity recognition across SLU benchmarks.
A Fast and Accurate Pitch Estimation Algorithm Based on the Pseudo Wigner-Ville Distribution
Oct 27, 2022



Estimation of fundamental frequency (F0) in voiced segments of speech signals, also known as pitch tracking, plays a crucial role in pitch synchronous speech analysis, speech synthesis, and speech manipulation. In this paper, we capitalize on the high time and frequency resolution of the pseudo Wigner-Ville distribution (PWVD) and propose a new PWVD-based pitch estimation method. We devise an efficient algorithm to compute PWVD faster and use cepstrum-based pre-filtering to avoid cross-term interference. Evaluating our approach on a database with speech and electroglottograph (EGG) recordings yields a state-of-the-art mean absolute error (MAE) of around 4Hz. Our approach is also effective at voiced/unvoiced classification and handling sudden frequency changes.
CTC Alignments Improve Autoregressive Translation
Oct 11, 2022
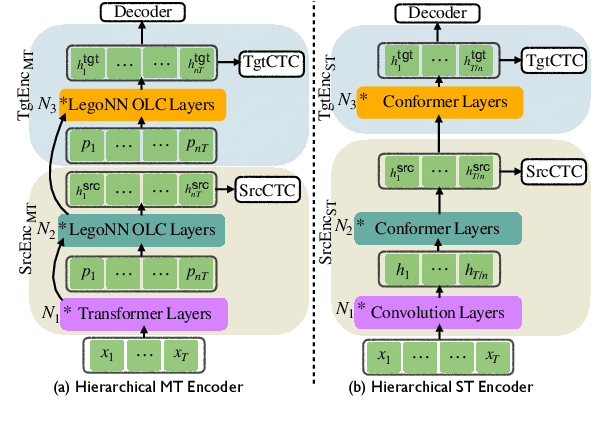

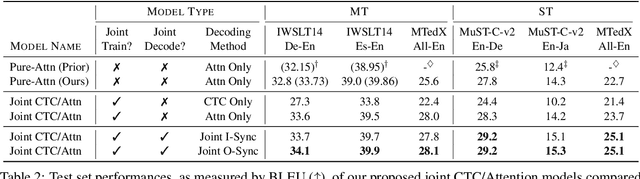
Connectionist Temporal Classification (CTC) is a widely used approach for automatic speech recognition (ASR) that performs conditionally independent monotonic alignment. However for translation, CTC exhibits clear limitations due to the contextual and non-monotonic nature of the task and thus lags behind attentional decoder approaches in terms of translation quality. In this work, we argue that CTC does in fact make sense for translation if applied in a joint CTC/attention framework wherein CTC's core properties can counteract several key weaknesses of pure-attention models during training and decoding. To validate this conjecture, we modify the Hybrid CTC/Attention model originally proposed for ASR to support text-to-text translation (MT) and speech-to-text translation (ST). Our proposed joint CTC/attention models outperform pure-attention baselines across six benchmark translation tasks.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022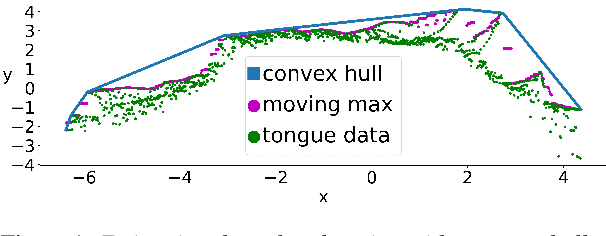

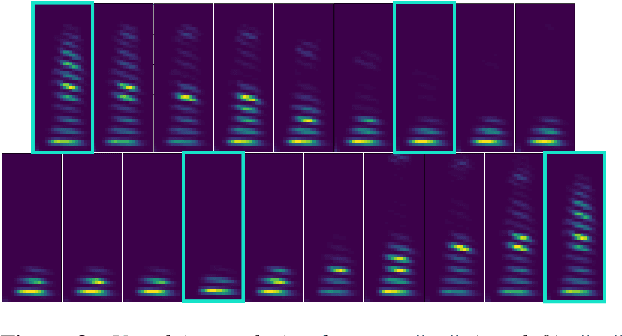
In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
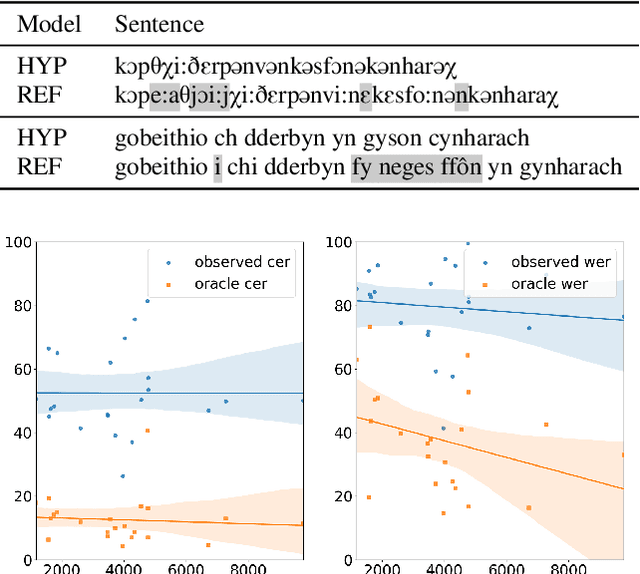
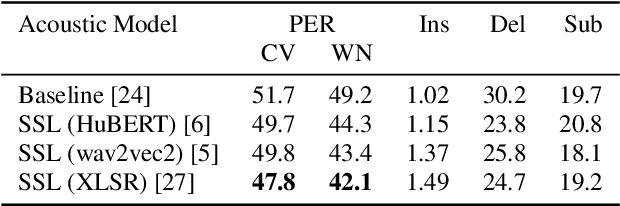
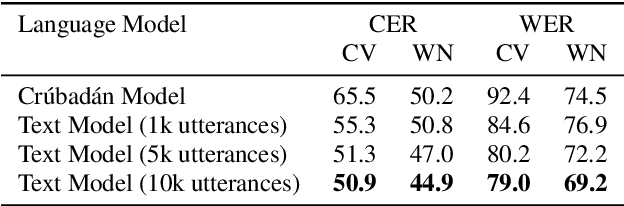
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
Building African Voices
Jul 01, 2022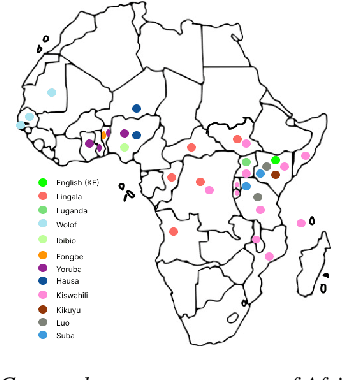
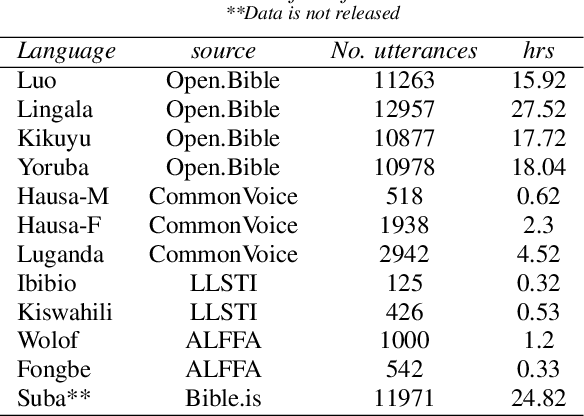
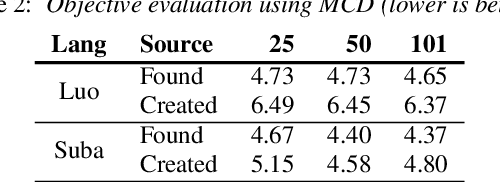
Modern speech synthesis techniques can produce natural-sounding speech given sufficient high-quality data and compute resources. However, such data is not readily available for many languages. This paper focuses on speech synthesis for low-resourced African languages, from corpus creation to sharing and deploying the Text-to-Speech (TTS) systems. We first create a set of general-purpose instructions on building speech synthesis systems with minimum technological resources and subject-matter expertise. Next, we create new datasets and curate datasets from "found" data (existing recordings) through a participatory approach while considering accessibility, quality, and breadth. We demonstrate that we can develop synthesizers that generate intelligible speech with 25 minutes of created speech, even when recorded in suboptimal environments. Finally, we release the speech data, code, and trained voices for 12 African languages to support researchers and developers.
On Advances in Text Generation from Images Beyond Captioning: A Case Study in Self-Rationalization
May 24, 2022


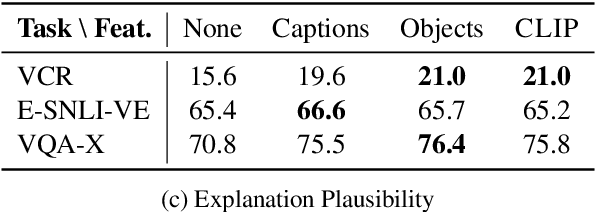
Integrating vision and language has gained notable attention following the success of pretrained language models. Despite that, a fraction of emerging multimodal models is suitable for text generation conditioned on images. This minority is typically developed and evaluated for image captioning, a text generation task conditioned solely on images with the goal to describe what is explicitly visible in an image. In this paper, we take a step back and ask: How do these models work for more complex generative tasks, conditioned on both text and images? Are models based on joint multimodal pretraining, visually adapted pretrained language models, or models that combine these two approaches, more promising for such tasks? We address these questions in the context of self-rationalization (jointly generating task labels/answers and free-text explanations) of three tasks: (i) visual question answering in VQA-X, (ii) visual commonsense reasoning in VCR, and (iii) visual-textual entailment in E-SNLI-VE. We show that recent advances in each modality, CLIP image representations and scaling of language models, do not consistently improve multimodal self-rationalization of tasks with multimodal inputs. We also observe that no model type works universally the best across tasks/datasets and finetuning data sizes. Our findings call for a backbone modelling approach that can be built on to advance text generation from images and text beyond image captioning.
Deep Neural Convolutive Matrix Factorization for Articulatory Representation Decomposition
Apr 08, 2022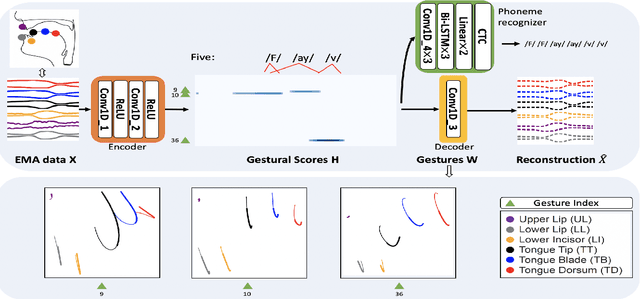
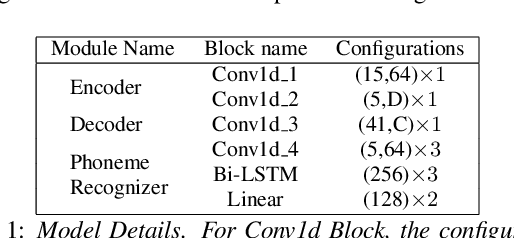
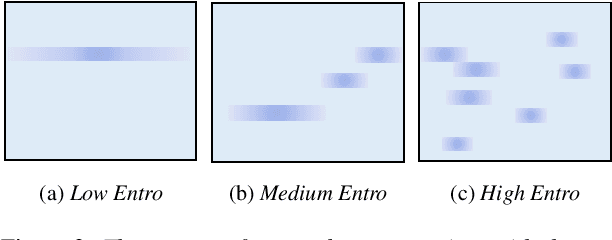
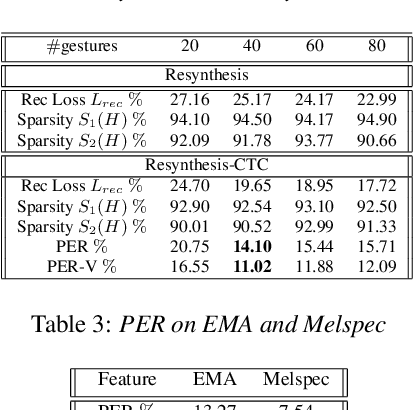
Most of the research on data-driven speech representation learning has focused on raw audios in an end-to-end manner, paying little attention to their internal phonological or gestural structure. This work, investigating the speech representations derived from articulatory kinematics signals, uses a neural implementation of convolutive sparse matrix factorization to decompose the articulatory data into interpretable gestures and gestural scores. By applying sparse constraints, the gestural scores leverage the discrete combinatorial properties of phonological gestures. Phoneme recognition experiments were additionally performed to show that gestural scores indeed code phonological information successfully. The proposed work thus makes a bridge between articulatory phonology and deep neural networks to leverage informative, intelligible, interpretable,and efficient speech representations.
ESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021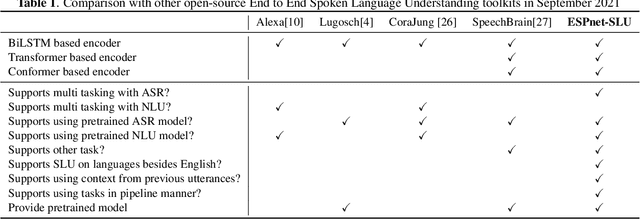
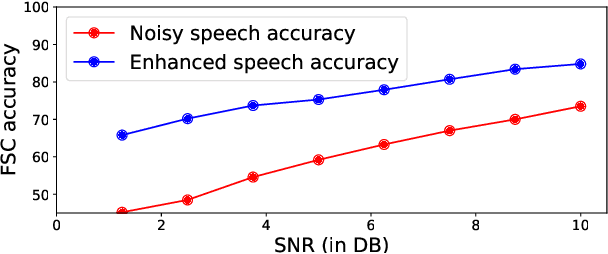
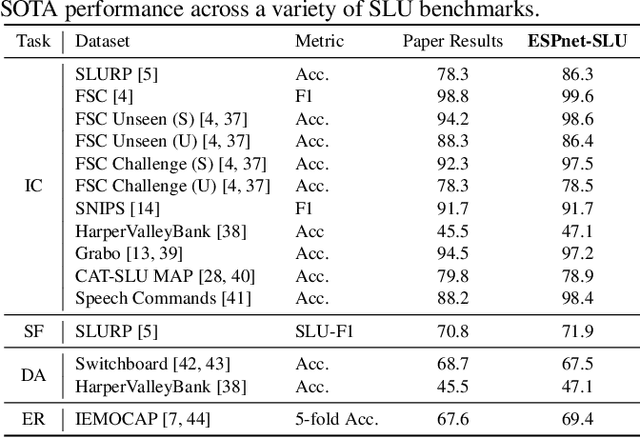

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity
Nov 02, 2021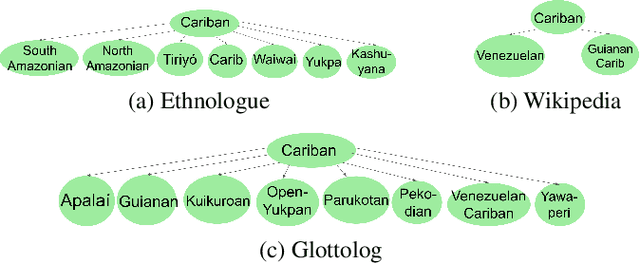
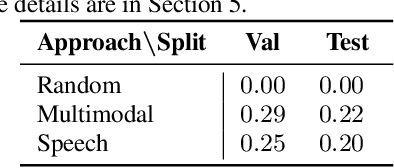
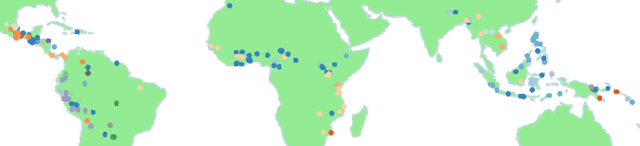
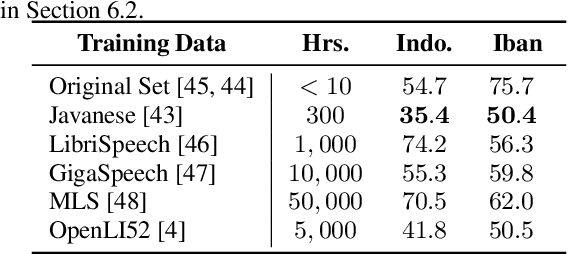
Speech processing systems currently do not support the vast majority of languages, in part due to the lack of data in low-resource languages. Cross-lingual transfer offers a compelling way to help bridge this digital divide by incorporating high-resource data into low-resource systems. Current cross-lingual algorithms have shown success in text-based tasks and speech-related tasks over some low-resource languages. However, scaling up speech systems to support hundreds of low-resource languages remains unsolved. To help bridge this gap, we propose a language similarity approach that can efficiently identify acoustic cross-lingual transfer pairs across hundreds of languages. We demonstrate the effectiveness of our approach in language family classification, speech recognition, and speech synthesis tasks.