 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleStream: Real-Time Zero-Shot Voice Style Conversion
Feb 23, 2026Voice style conversion aims to transform an input utterance to match a target speaker's timbre, accent, and emotion, with a central challenge being the disentanglement of linguistic content from style. While prior work has explored this problem, conversion quality remains limited, and real-time voice style conversion has not been addressed. We propose StyleStream, the first streamable zero-shot voice style conversion system that achieves state-of-the-art performance. StyleStream consists of two components: a Destylizer, which removes style attributes while preserving linguistic content, and a Stylizer, a diffusion transformer (DiT) that reintroduces target style conditioned on reference speech. Robust content-style disentanglement is enforced through text supervision and a highly constrained information bottleneck. This design enables a fully non-autoregressive architecture, achieving real-time voice style conversion with an end-to-end latency of 1 second. Samples and real-time demo: https://berkeley-speech-group.github.io/StyleStream/.
HuPER: A Human-Inspired Framework for Phonetic Perception
Feb 02, 2026We propose HuPER, a human-inspired framework that models phonetic perception as adaptive inference over acoustic-phonetics evidence and linguistic knowledge. With only 100 hours of training data, HuPER achieves state-of-the-art phonetic error rates on five English benchmarks and strong zero-shot transfer to 95 unseen languages. HuPER is also the first framework to enable adaptive, multi-path phonetic perception under diverse acoustic conditions. All training data, models, and code are open-sourced. Code and demo avaliable at https://github.com/HuPER29/HuPER.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Prompt-and-Check: Using Large Language Models to Evaluate Communication Protocol Compliance in Simulation-Based Training
Aug 12, 2025


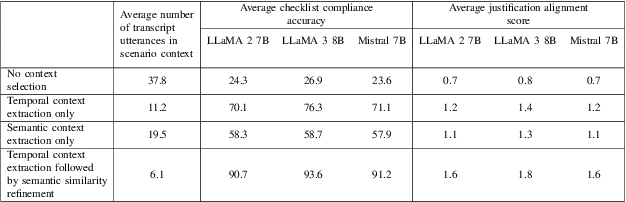
Accurate evaluation of procedural communication compliance is essential in simulation-based training, particularly in safety-critical domains where adherence to compliance checklists reflects operational competence. This paper explores a lightweight, deployable approach using prompt-based inference with open-source large language models (LLMs) that can run efficiently on consumer-grade GPUs. We present Prompt-and-Check, a method that uses context-rich prompts to evaluate whether each checklist item in a protocol has been fulfilled, solely based on transcribed verbal exchanges. We perform a case study in the maritime domain with participants performing an identical simulation task, and experiment with models such as LLama 2 7B, LLaMA 3 8B and Mistral 7B, running locally on an RTX 4070 GPU. For each checklist item, a prompt incorporating relevant transcript excerpts is fed into the model, which outputs a compliance judgment. We assess model outputs against expert-annotated ground truth using classification accuracy and agreement scores. Our findings demonstrate that prompting enables effective context-aware reasoning without task-specific training. This study highlights the practical utility of LLMs in augmenting debriefing, performance feedback, and automated assessment in training environments.
Enhancing Egocentric Object Detection in Static Environments using Graph-based Spatial Anomaly Detection and Correction
Aug 11, 2025In many real-world applications involving static environments, the spatial layout of objects remains consistent across instances. However, state-of-the-art object detection models often fail to leverage this spatial prior, resulting in inconsistent predictions, missed detections, or misclassifications, particularly in cluttered or occluded scenes. In this work, we propose a graph-based post-processing pipeline that explicitly models the spatial relationships between objects to correct detection anomalies in egocentric frames. Using a graph neural network (GNN) trained on manually annotated data, our model identifies invalid object class labels and predicts corrected class labels based on their neighbourhood context. We evaluate our approach both as a standalone anomaly detection and correction framework and as a post-processing module for standard object detectors such as YOLOv7 and RT-DETR. Experiments demonstrate that incorporating this spatial reasoning significantly improves detection performance, with mAP@50 gains of up to 4%. This method highlights the potential of leveraging the environment's spatial structure to improve reliability in object detection systems.
AI Meets Maritime Training: Precision Analytics for Enhanced Safety and Performance
Jul 02, 2025
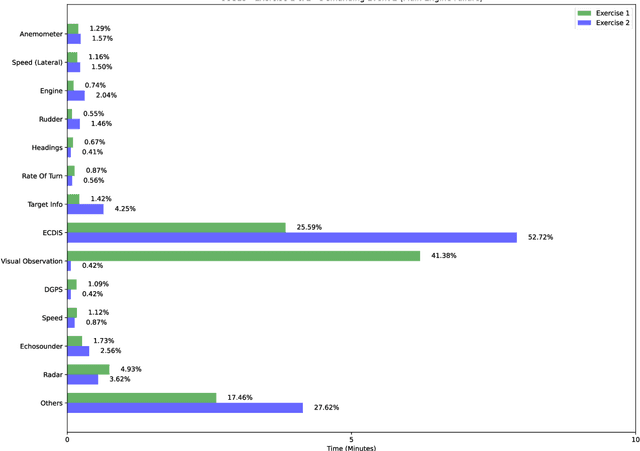


Traditional simulator-based training for maritime professionals is critical for ensuring safety at sea but often depends on subjective trainer assessments of technical skills, behavioral focus, communication, and body language, posing challenges such as subjectivity, difficulty in measuring key features, and cognitive limitations. Addressing these issues, this study develops an AI-driven framework to enhance maritime training by objectively assessing trainee performance through visual focus tracking, speech recognition, and stress detection, improving readiness for high-risk scenarios. The system integrates AI techniques, including visual focus determination using eye tracking, pupil dilation analysis, and computer vision; communication analysis through a maritime-specific speech-to-text model and natural language processing; communication correctness using large language models; and mental stress detection via vocal pitch. Models were evaluated on data from simulated maritime scenarios with seafarers exposed to controlled high-stress events. The AI algorithms achieved high accuracy, with ~92% for visual detection, ~91% for maritime speech recognition, and ~90% for stress detection, surpassing existing benchmarks. The system provides insights into visual attention, adherence to communication checklists, and stress levels under demanding conditions. This study demonstrates how AI can transform maritime training by delivering objective performance analytics, enabling personalized feedback, and improving preparedness for real-world operational challenges.
RT-VC: Real-Time Zero-Shot Voice Conversion with Speech Articulatory Coding
Jun 12, 2025



Voice conversion has emerged as a pivotal technology in numerous applications ranging from assistive communication to entertainment. In this paper, we present RT-VC, a zero-shot real-time voice conversion system that delivers ultra-low latency and high-quality performance. Our approach leverages an articulatory feature space to naturally disentangle content and speaker characteristics, facilitating more robust and interpretable voice transformations. Additionally, the integration of differentiable digital signal processing (DDSP) enables efficient vocoding directly from articulatory features, significantly reducing conversion latency. Experimental evaluations demonstrate that, while maintaining synthesis quality comparable to the current state-of-the-art (SOTA) method, RT-VC achieves a CPU latency of 61.4 ms, representing a 13.3\% reduction in latency.
Contextual Biasing to Improve Domain-specific Custom Vocabulary Audio Transcription without Explicit Fine-Tuning of Whisper Model
Oct 24, 2024



OpenAI's Whisper Automated Speech Recognition model excels in generalizing across diverse datasets and domains. However, this broad adaptability can lead to diminished performance in tasks requiring recognition of specific vocabularies. Addressing this challenge typically involves fine-tuning the model, which demands extensive labeled audio data that is often difficult to acquire and unavailable for specific domains. In this study, we propose a method to enhance transcription accuracy without explicit fine-tuning or altering model parameters, using a relatively small training dataset. Our method leverages contextual biasing, to direct Whisper model's output towards a specific vocabulary by integrating a neural-symbolic prefix tree structure to guide the model's transcription output. To validate our approach, we conducted experiments using a validation dataset comprising maritime data collected within a simulated training environment. A comparison between the original Whisper models of varying parameter sizes and our biased model revealed a notable reduction in transcription word error rate and enhanced performance of downstream applications. Our findings suggest that this methodology holds promise for improving speech-to-text translation performance in domains characterized by limited vocabularies.
Fast, High-Quality and Parameter-Efficient Articulatory Synthesis using Differentiable DSP
Sep 04, 2024



Articulatory trajectories like electromagnetic articulography (EMA) provide a low-dimensional representation of the vocal tract filter and have been used as natural, grounded features for speech synthesis. Differentiable digital signal processing (DDSP) is a parameter-efficient framework for audio synthesis. Therefore, integrating low-dimensional EMA features with DDSP can significantly enhance the computational efficiency of speech synthesis. In this paper, we propose a fast, high-quality, and parameter-efficient DDSP articulatory vocoder that can synthesize speech from EMA, F0, and loudness. We incorporate several techniques to solve the harmonics / noise imbalance problem, and add a multi-resolution adversarial loss for better synthesis quality. Our model achieves a transcription word error rate (WER) of 6.67% and a mean opinion score (MOS) of 3.74, with an improvement of 1.63% and 0.16 compared to the state-of-the-art (SOTA) baseline. Our DDSP vocoder is 4.9x faster than the baseline on CPU during inference, and can generate speech of comparable quality with only 0.4M parameters, in contrast to the 9M parameters required by the SOTA.
Taxonomic analysis of asteroids with artificial neural networks
Nov 18, 2023We study the surface composition of asteroids with visible and/or infrared spectroscopy. For example, asteroid taxonomy is based on the spectral features or multiple color indices in visible and near-infrared wavelengths. The composition of asteroids gives key information to understand their origin and evolution. However, we lack compositional information for faint asteroids due to limits of ground-based observational instruments. In the near future, the Chinese Space Survey telescope (CSST) will provide multiple colors and spectroscopic data for asteroids of apparent magnitude brighter than 25 mag and 23 mag, respectively. For the aim of analysis of the CSST spectroscopic data, we applied an algorithm using artificial neural networks (ANNs) to establish a preliminary classification model for asteroid taxonomy according to the design of the survey module of CSST. Using the SMASS II spectra and the Bus-Binzel taxonomy system, our ANN classification tool composed of 5 individual ANNs is constructed, and the accuracy of this classification system is higher than 92 %. As the first application of our ANN tool, 64 spectra of 42 asteroids obtained in 2006 and 2007 by us with the 2.16-m telescope in the Xinglong station (Observatory Code 327) of National Astronomical Observatory of China are analyzed. The predicted labels of these spectra using our ANN tool are found to be reasonable when compared to their known taxonomic labels. Considering the accuracy and stability, our ANN tool can be applied to analyse the CSST asteroid spectra in the future.