 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormFace: L2 Hypersphere Embedding for Face Verification
Jul 26, 2017
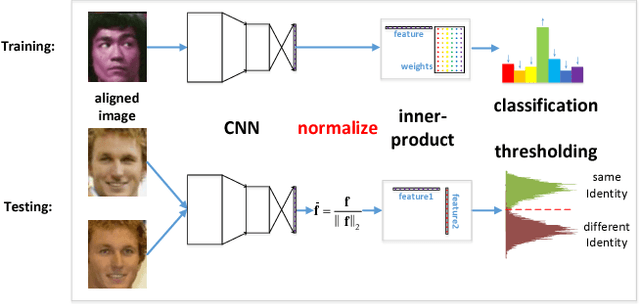
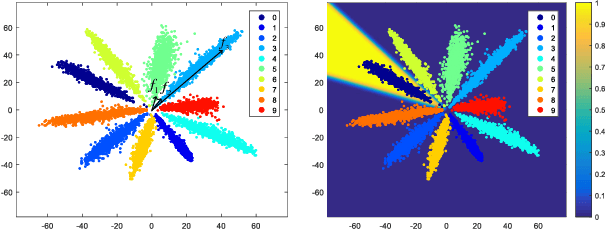
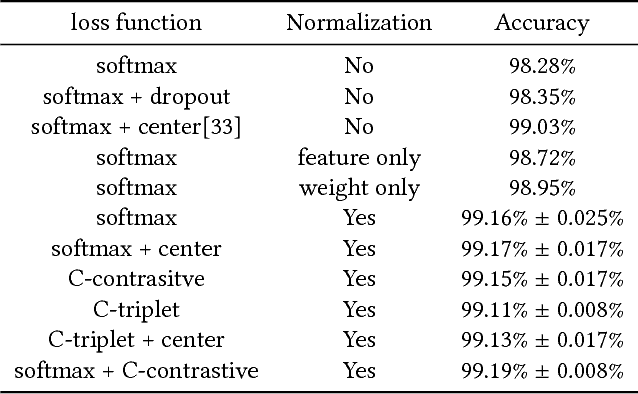
Thanks to the recent developments of Convolutional Neural Networks, the performance of face verification methods has increased rapidly. In a typical face verification method, feature normalization is a critical step for boosting performance. This motivates us to introduce and study the effect of normalization during training. But we find this is non-trivial, despite normalization being differentiable. We identify and study four issues related to normalization through mathematical analysis, which yields understanding and helps with parameter settings. Based on this analysis we propose two strategies for training using normalized features. The first is a modification of softmax loss, which optimizes cosine similarity instead of inner-product. The second is a reformulation of metric learning by introducing an agent vector for each class. We show that both strategies, and small variants, consistently improve performance by between 0.2% to 0.4% on the LFW dataset based on two models. This is significant because the performance of the two models on LFW dataset is close to saturation at over 98%. Codes and models are released on https://github.com/happynear/NormFace
Deep Supervision for Pancreatic Cyst Segmentation in Abdominal CT Scans
Jun 22, 2017
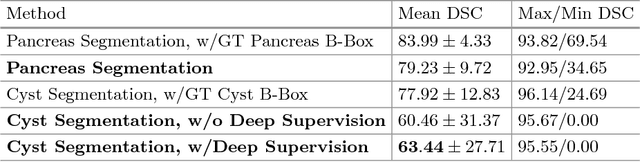
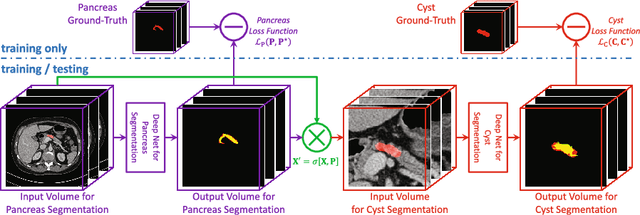
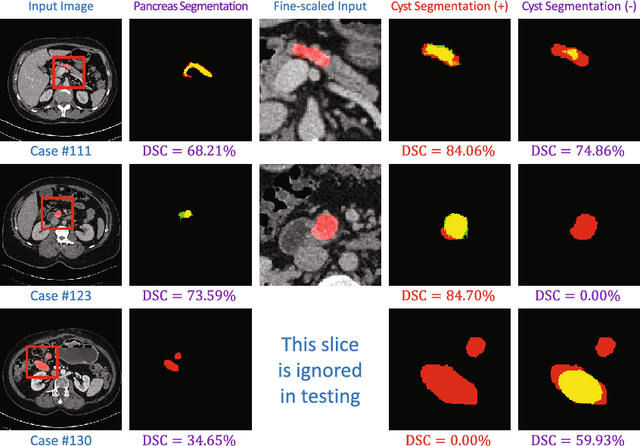
Automatic segmentation of an organ and its cystic region is a prerequisite of computer-aided diagnosis. In this paper, we focus on pancreatic cyst segmentation in abdominal CT scan. This task is important and very useful in clinical practice yet challenging due to the low contrast in boundary, the variability in location, shape and the different stages of the pancreatic cancer. Inspired by the high relevance between the location of a pancreas and its cystic region, we introduce extra deep supervision into the segmentation network, so that cyst segmentation can be improved with the help of relatively easier pancreas segmentation. Under a reasonable transformation function, our approach can be factorized into two stages, and each stage can be efficiently optimized via gradient back-propagation throughout the deep networks. We collect a new dataset with 131 pathological samples, which, to the best of our knowledge, is the largest set for pancreatic cyst segmentation. Without human assistance, our approach reports a 63.44% average accuracy, measured by the Dice-S{\o}rensen coefficient (DSC), which is higher than the number (60.46%) without deep supervision.
A Fixed-Point Model for Pancreas Segmentation in Abdominal CT Scans
Jun 21, 2017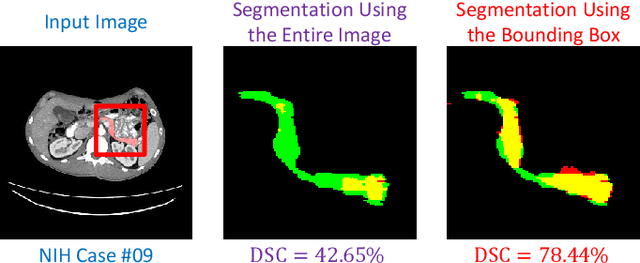
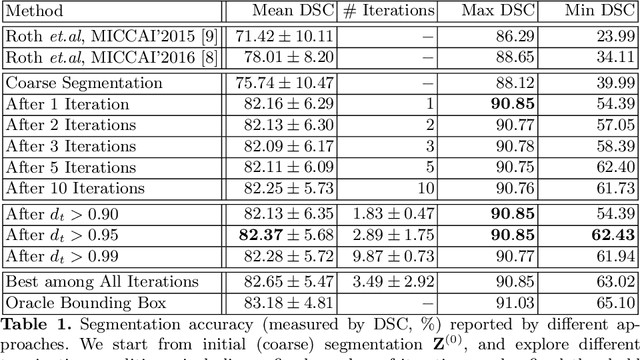
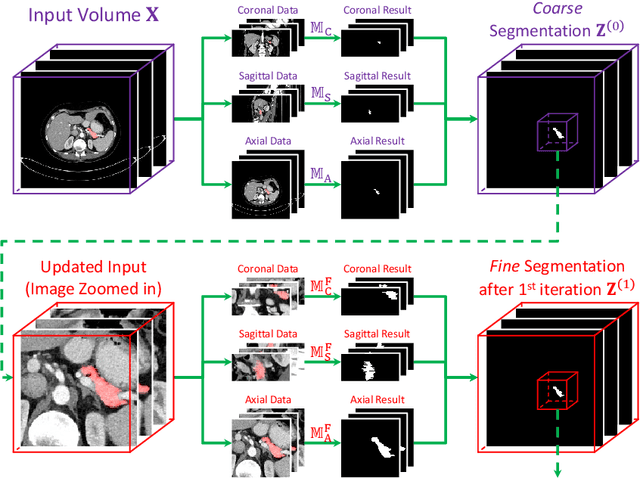
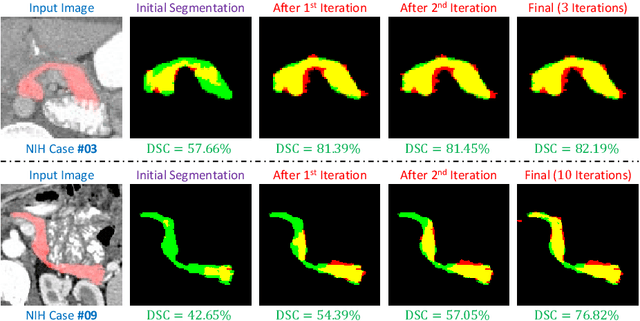
Deep neural networks have been widely adopted for automatic organ segmentation from abdominal CT scans. However, the segmentation accuracy of some small organs (e.g., the pancreas) is sometimes below satisfaction, arguably because deep networks are easily disrupted by the complex and variable background regions which occupies a large fraction of the input volume. In this paper, we formulate this problem into a fixed-point model which uses a predicted segmentation mask to shrink the input region. This is motivated by the fact that a smaller input region often leads to more accurate segmentation. In the training process, we use the ground-truth annotation to generate accurate input regions and optimize network weights. On the testing stage, we fix the network parameters and update the segmentation results in an iterative manner. We evaluate our approach on the NIH pancreas segmentation dataset, and outperform the state-of-the-art by more than 4%, measured by the average Dice-S{\o}rensen Coefficient (DSC). In addition, we report 62.43% DSC in the worst case, which guarantees the reliability of our approach in clinical applications.
Regularizing Face Verification Nets For Pain Intensity Regression
Jun 01, 2017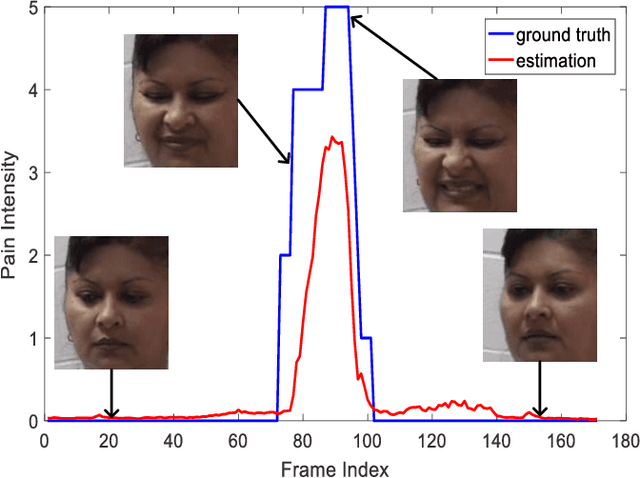
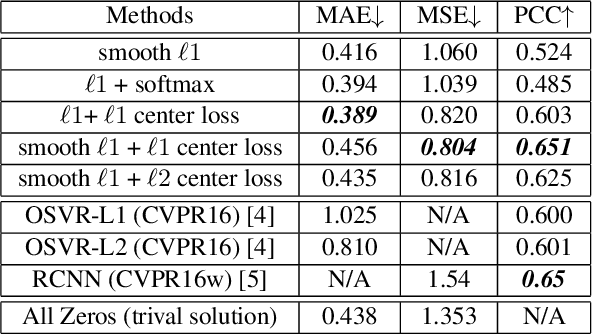
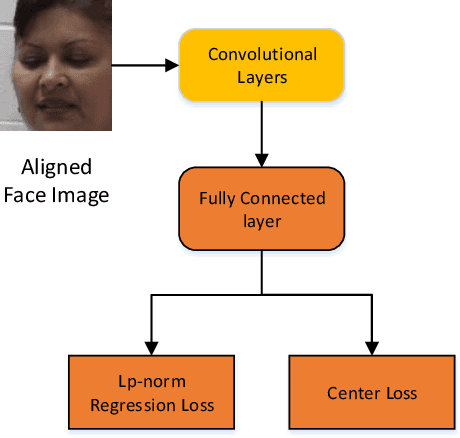
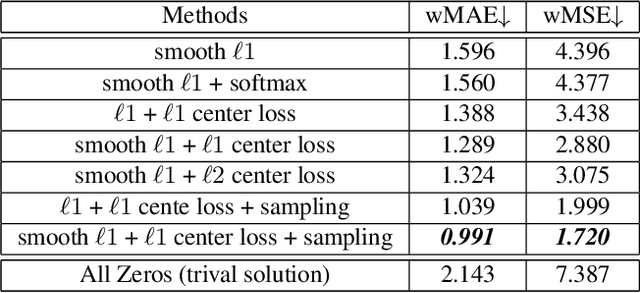
Limited labeled data are available for the research of estimating facial expression intensities. For instance, the ability to train deep networks for automated pain assessment is limited by small datasets with labels of patient-reported pain intensities. Fortunately, fine-tuning from a data-extensive pre-trained domain, such as face verification, can alleviate this problem. In this paper, we propose a network that fine-tunes a state-of-the-art face verification network using a regularized regression loss and additional data with expression labels. In this way, the expression intensity regression task can benefit from the rich feature representations trained on a huge amount of data for face verification. The proposed regularized deep regressor is applied to estimate the pain expression intensity and verified on the widely-used UNBC-McMaster Shoulder-Pain dataset, achieving the state-of-the-art performance. A weighted evaluation metric is also proposed to address the imbalance issue of different pain intensities.
Object Recognition with and without Objects
May 25, 2017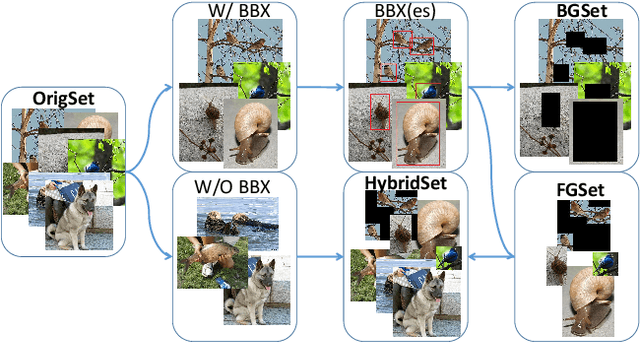

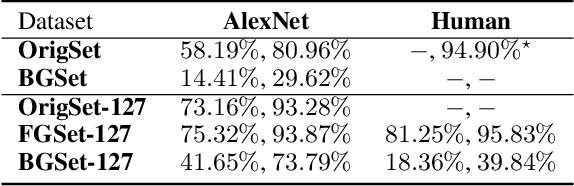
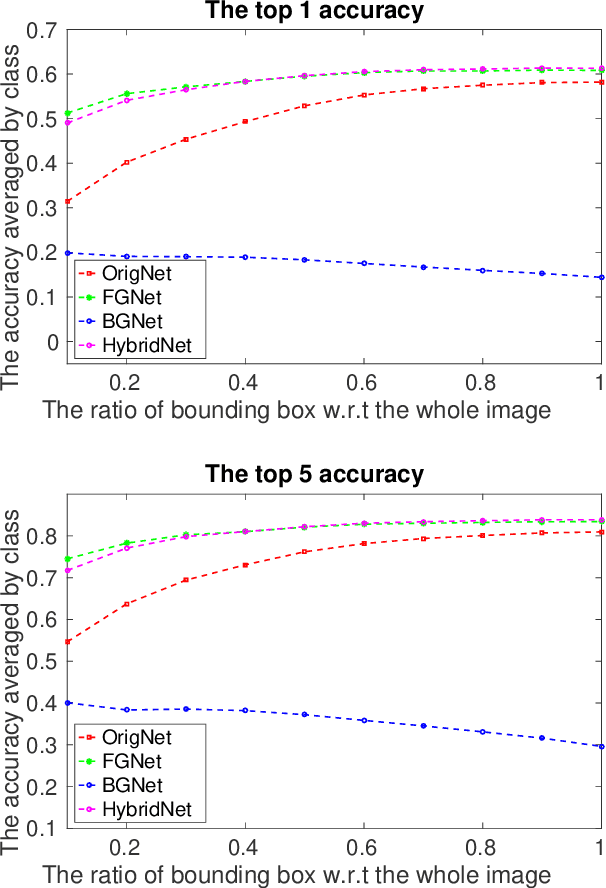
While recent deep neural networks have achieved a promising performance on object recognition, they rely implicitly on the visual contents of the whole image. In this paper, we train deep neural net- works on the foreground (object) and background (context) regions of images respectively. Consider- ing human recognition in the same situations, net- works trained on the pure background without ob- jects achieves highly reasonable recognition performance that beats humans by a large margin if only given context. However, humans still outperform networks with pure object available, which indicates networks and human beings have different mechanisms in understanding an image. Furthermore, we straightforwardly combine multiple trained networks to explore different visual cues learned by different networks. Experiments show that useful visual hints can be explicitly learned separately and then combined to achieve higher performance, which verifies the advantages of the proposed framework.
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
May 12, 2017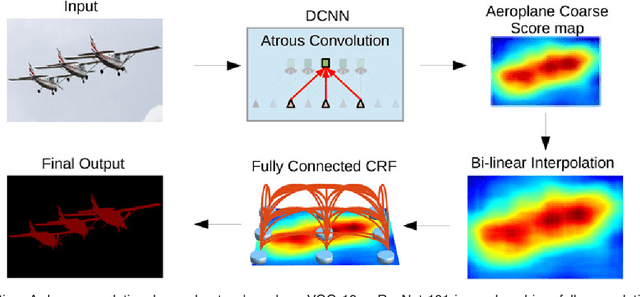
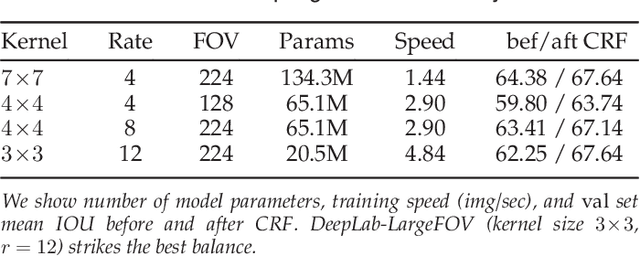
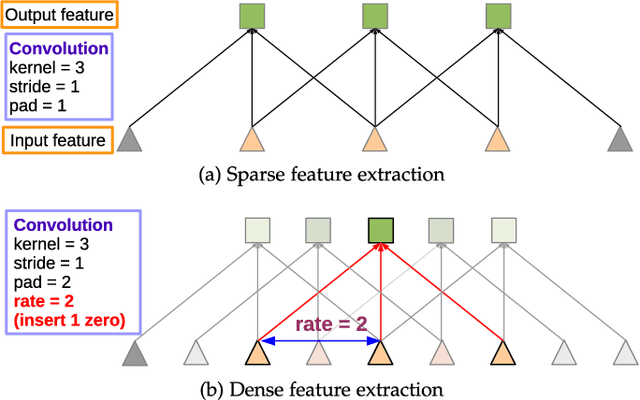
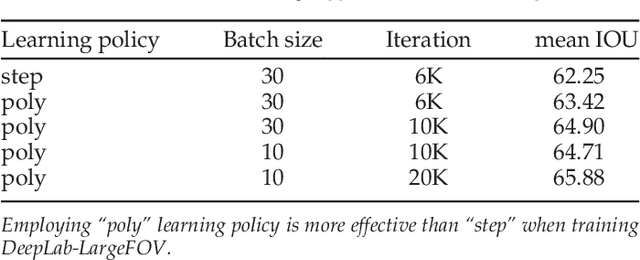
In this work we address the task of semantic image segmentation with Deep Learning and make three main contributions that are experimentally shown to have substantial practical merit. First, we highlight convolution with upsampled filters, or 'atrous convolution', as a powerful tool in dense prediction tasks. Atrous convolution allows us to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks. It also allows us to effectively enlarge the field of view of filters to incorporate larger context without increasing the number of parameters or the amount of computation. Second, we propose atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales. ASPP probes an incoming convolutional feature layer with filters at multiple sampling rates and effective fields-of-views, thus capturing objects as well as image context at multiple scales. Third, we improve the localization of object boundaries by combining methods from DCNNs and probabilistic graphical models. The commonly deployed combination of max-pooling and downsampling in DCNNs achieves invariance but has a toll on localization accuracy. We overcome this by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF), which is shown both qualitatively and quantitatively to improve localization performance. Our proposed "DeepLab" system sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 79.7% mIOU in the test set, and advances the results on three other datasets: PASCAL-Context, PASCAL-Person-Part, and Cityscapes. All of our code is made publicly available online.
Exploiting Symmetry and/or Manhattan Properties for 3D Object Structure Estimation from Single and Multiple Images
Mar 29, 2017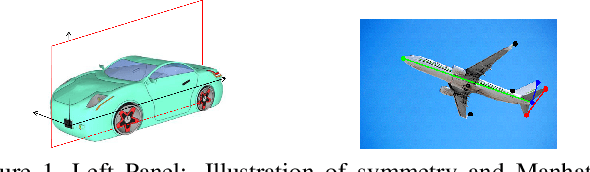
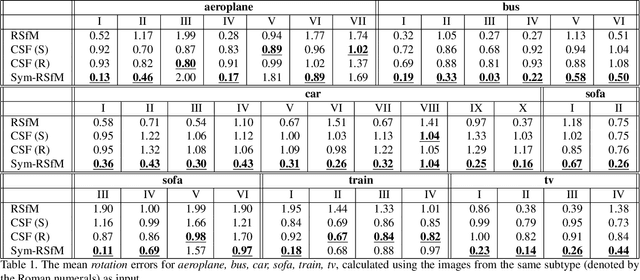

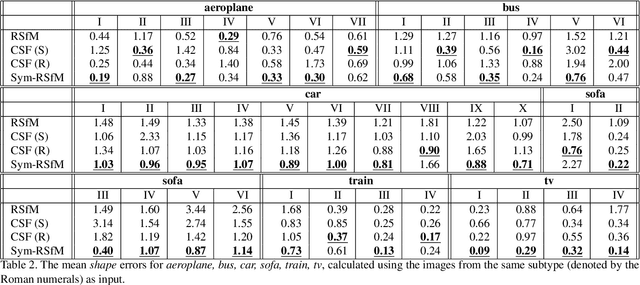
Many man-made objects have intrinsic symmetries and Manhattan structure. By assuming an orthographic projection model, this paper addresses the estimation of 3D structures and camera projection using symmetry and/or Manhattan structure cues, which occur when the input is single- or multiple-image from the same category, e.g., multiple different cars. Specifically, analysis on the single image case implies that Manhattan alone is sufficient to recover the camera projection, and then the 3D structure can be reconstructed uniquely exploiting symmetry. However, Manhattan structure can be difficult to observe from a single image due to occlusion. To this end, we extend to the multiple-image case which can also exploit symmetry but does not require Manhattan axes. We propose a novel rigid structure from motion method, exploiting symmetry and using multiple images from the same category as input. Experimental results on the Pascal3D+ dataset show that our method significantly outperforms baseline methods.
Semi-Supervised Sparse Representation Based Classification for Face Recognition with Insufficient Labeled Samples
Mar 24, 2017

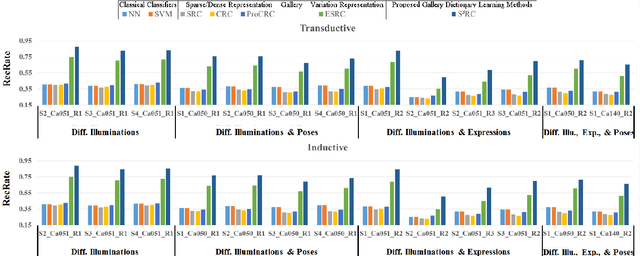

This paper addresses the problem of face recognition when there is only few, or even only a single, labeled examples of the face that we wish to recognize. Moreover, these examples are typically corrupted by nuisance variables, both linear (i.e., additive nuisance variables such as bad lighting, wearing of glasses) and non-linear (i.e., non-additive pixel-wise nuisance variables such as expression changes). The small number of labeled examples means that it is hard to remove these nuisance variables between the training and testing faces to obtain good recognition performance. To address the problem we propose a method called Semi-Supervised Sparse Representation based Classification (S$^3$RC). This is based on recent work on sparsity where faces are represented in terms of two dictionaries: a gallery dictionary consisting of one or more examples of each person, and a variation dictionary representing linear nuisance variables (e.g., different lighting conditions, different glasses). The main idea is that (i) we use the variation dictionary to characterize the linear nuisance variables via the sparsity framework, then (ii) prototype face images are estimated as a gallery dictionary via a Gaussian Mixture Model (GMM), with mixed labeled and unlabeled samples in a semi-supervised manner, to deal with the non-linear nuisance variations between labeled and unlabeled samples. We have done experiments with insufficient labeled samples, even when there is only a single labeled sample per person. Our results on the AR, Multi-PIE, CAS-PEAL, and LFW databases demonstrate that the proposed method is able to deliver significantly improved performance over existing methods.
Multi-Context Attention for Human Pose Estimation
Feb 24, 2017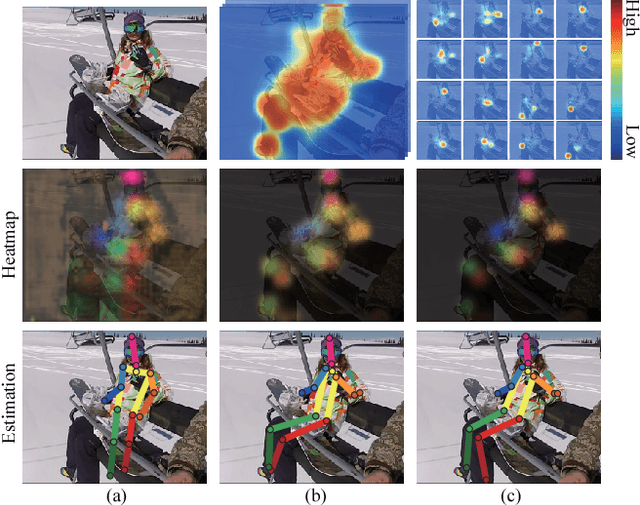
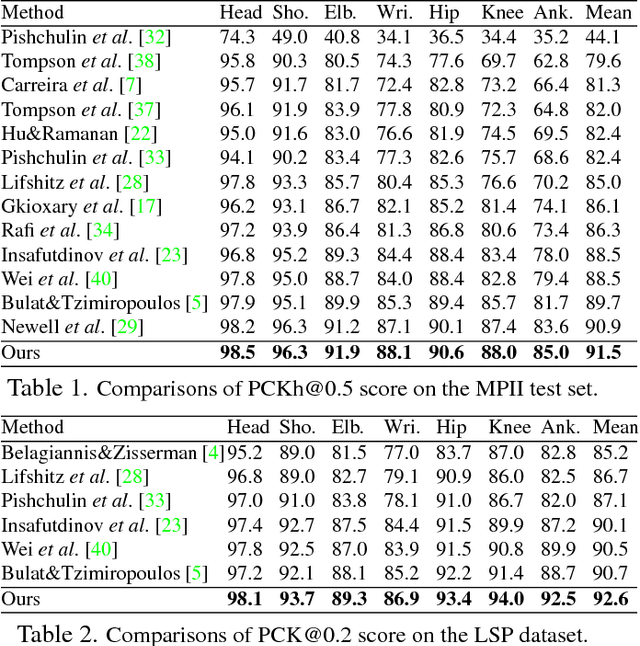
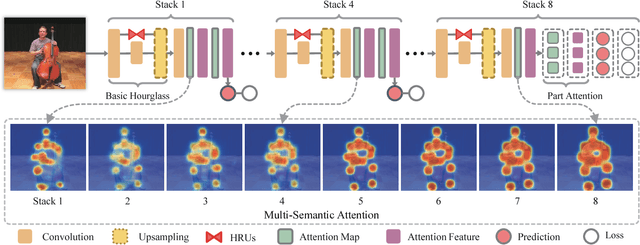
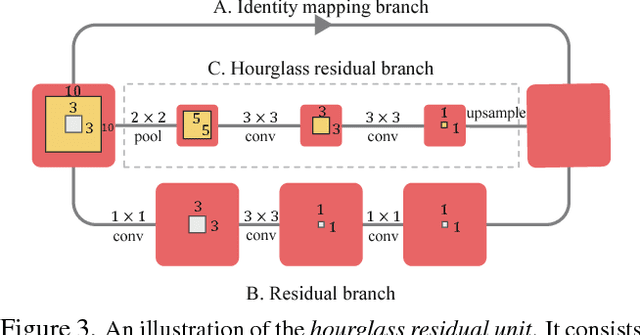
In this paper, we propose to incorporate convolutional neural networks with a multi-context attention mechanism into an end-to-end framework for human pose estimation. We adopt stacked hourglass networks to generate attention maps from features at multiple resolutions with various semantics. The Conditional Random Field (CRF) is utilized to model the correlations among neighboring regions in the attention map. We further combine the holistic attention model, which focuses on the global consistency of the full human body, and the body part attention model, which focuses on the detailed description for different body parts. Hence our model has the ability to focus on different granularity from local salient regions to global semantic-consistent spaces. Additionally, we design novel Hourglass Residual Units (HRUs) to increase the receptive field of the network. These units are extensions of residual units with a side branch incorporating filters with larger receptive fields, hence features with various scales are learned and combined within the HRUs. The effectiveness of the proposed multi-context attention mechanism and the hourglass residual units is evaluated on two widely used human pose estimation benchmarks. Our approach outperforms all existing methods on both benchmarks over all the body parts.
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Jun 07, 2016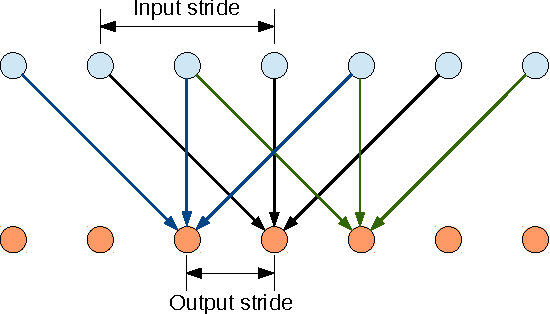

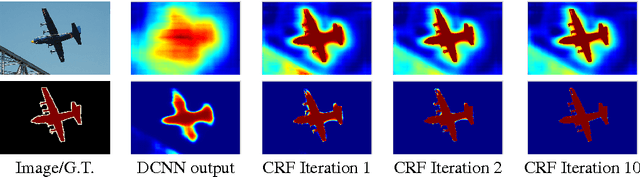

Deep Convolutional Neural Networks (DCNNs) have recently shown state of the art performance in high level vision tasks, such as image classification and object detection. This work brings together methods from DCNNs and probabilistic graphical models for addressing the task of pixel-level classification (also called "semantic image segmentation"). We show that responses at the final layer of DCNNs are not sufficiently localized for accurate object segmentation. This is due to the very invariance properties that make DCNNs good for high level tasks. We overcome this poor localization property of deep networks by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF). Qualitatively, our "DeepLab" system is able to localize segment boundaries at a level of accuracy which is beyond previous methods. Quantitatively, our method sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 71.6% IOU accuracy in the test set. We show how these results can be obtained efficiently: Careful network re-purposing and a novel application of the 'hole' algorithm from the wavelet community allow dense computation of neural net responses at 8 frames per second on a modern GPU.