 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Oct 07, 2020

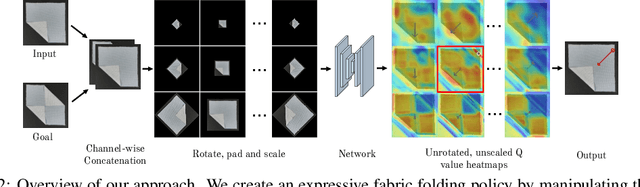
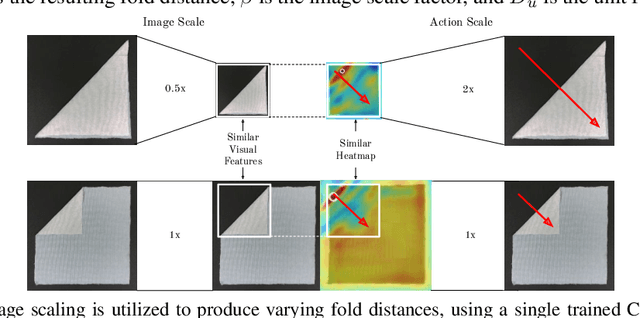
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold
Strawberry Detection using Mixed Training on Simulated and Real Data
Aug 24, 2020
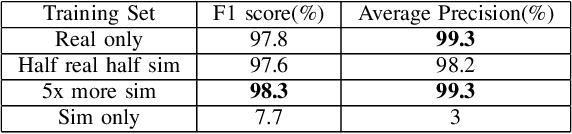
This paper demonstrates how simulated images can be useful for object detection tasks in the agricultural sector, where labeled data can be scarce and costly to collect. We consider training on mixed datasets with real and simulated data for strawberry detection in real images. Our results show that using the real dataset augmented by the simulated dataset resulted in slightly higher accuracy.
Object Handovers: a Review for Robotics
Jul 25, 2020
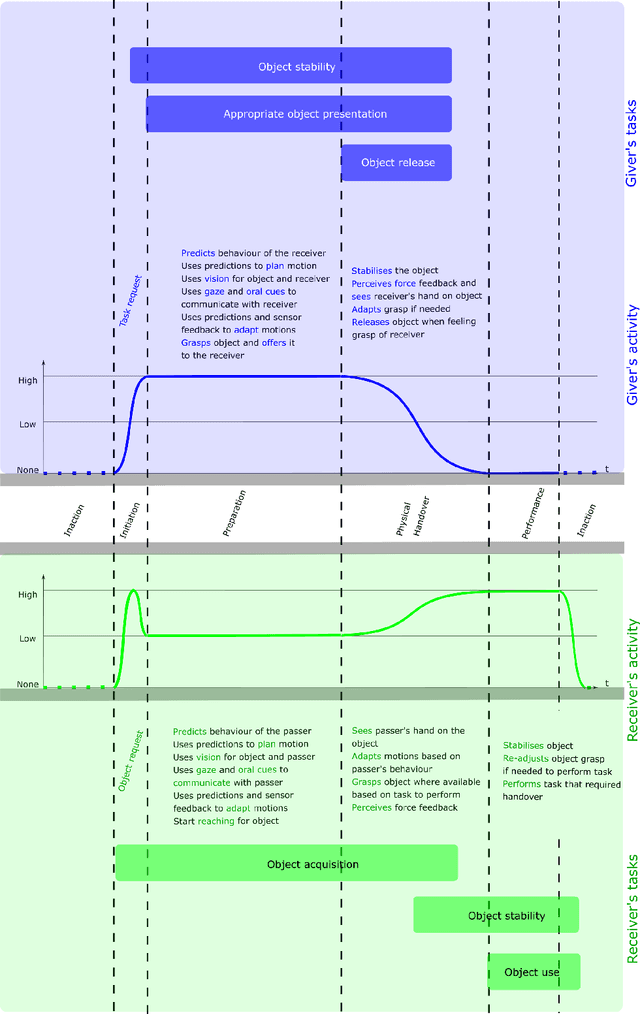
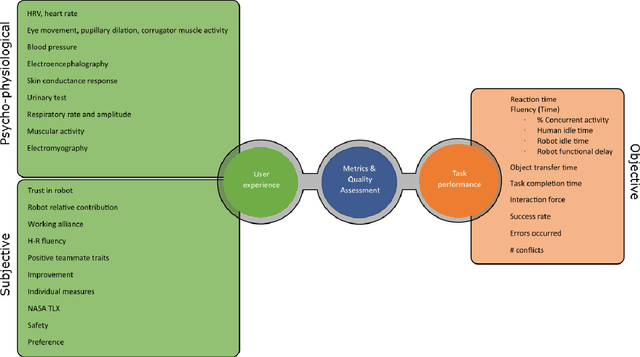
This article surveys the literature on human-robot object handovers. A handover is a collaborative joint action where an agent, the giver, gives an object to another agent, the receiver. The physical exchange starts when the receiver first contacts the object held by the giver and ends when the giver fully releases the object to the receiver. However, important cognitive and physical processes begin before the physical exchange, including initiating implicit agreement with respect to the location and timing of the exchange. From this perspective, we structure our review into the two main phases delimited by the aforementioned events: 1) a pre-handover phase, and 2) the physical exchange. We focus our analysis on the two actors (giver and receiver) and report the state of the art of robotic givers (robot-to-human handovers) and the robotic receivers (human-to-robot handovers). We report a comprehensive list of qualitative and quantitative metrics commonly used to assess the interaction. While focusing our review on the cognitive level (e.g., prediction, perception, motion planning, learning) and the physical level (e.g., motion, grasping, grip release) of the handover, we briefly discuss also the concepts of safety, social context, and ergonomics. We compare the behaviours displayed during human-to-human handovers to the state of the art of robotic assistants, and identify the major areas of improvement for robotic assistants to reach performance comparable to human interactions. Finally, we propose a minimal set of metrics that should be used in order to enable a fair comparison among the approaches.
Gesture Recognition for Initiating Human-to-Robot Handovers
Jul 20, 2020
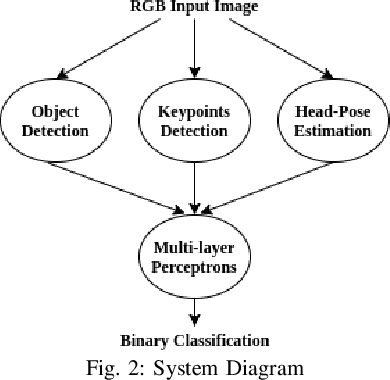
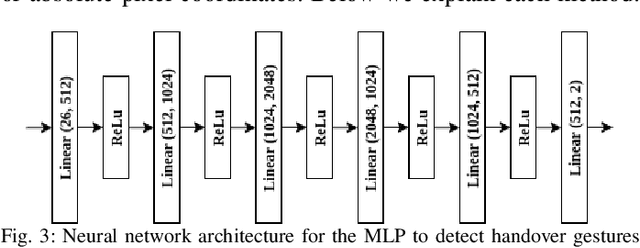

Human-to-Robot handovers are useful for many Human-Robot Interaction scenarios. It is important to recognize when a human intends to initiate handovers, so that the robot does not try to take objects from humans when a handover is not intended. We pose the handover gesture recognition as a binary classification problem in a single RGB image. Three separate neural network modules for detecting the object, human body key points and head orientation, are implemented to extract relevant features from the RGB images, and then the feature vectors are passed into a deep neural net to perform binary classification. Our results show that the handover gestures are correctly identified with an accuracy of over 90%. The abstraction of the features makes our approach modular and generalizable to different objects and human body types.
Object-Independent Human-to-Robot Handovers using Real Time Robotic Vision
Jun 02, 2020
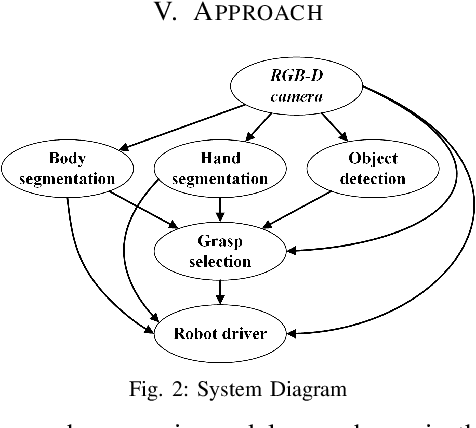
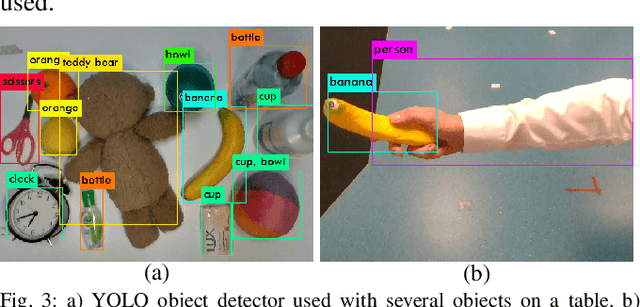

We present an approach for safe and object-independent human-to-robot handovers using real time robotic vision and manipulation. We aim for general applicability with a generic object detector, a fast grasp selection algorithm and by using a single gripper-mounted RGB-D camera, hence not relying on external sensors. The robot is controlled via visual servoing towards the object of interest. Putting a high emphasis on safety, we use two perception modules: human body part segmentation and hand/finger segmentation. Pixels that are deemed to belong to the human are filtered out from candidate grasp poses, hence ensuring that the robot safely picks the object without colliding with the human partner. The grasp selection and perception modules run concurrently in real-time, which allows monitoring of the progress. In experiments with 13 objects, the robot was able to successfully take the object from the human in 81.9% of the trials.
Supportive Actions for Manipulation in Human-Robot Coworker Teams
May 02, 2020
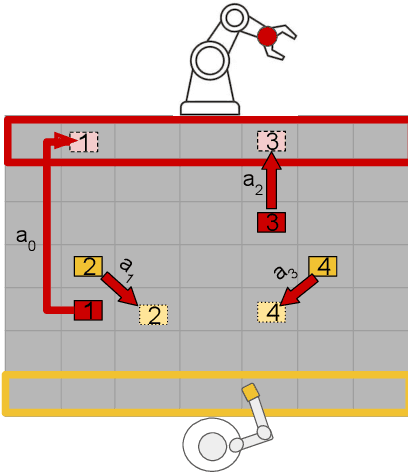
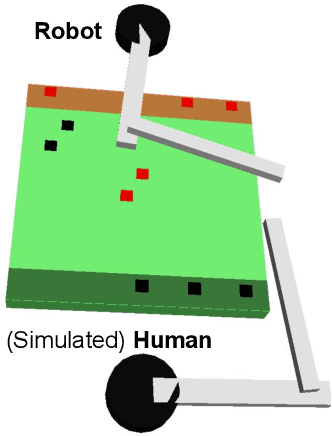

The increasing presence of robots alongside humans, such as in human-robot teams in manufacturing, gives rise to research questions about the kind of behaviors people prefer in their robot counterparts. We term actions that support interaction by reducing future interference with others as supportive robot actions and investigate their utility in a co-located manipulation scenario. We compare two robot modes in a shared table pick-and-place task: (1) Task-oriented: the robot only takes actions to further its own task objective and (2) Supportive: the robot sometimes prefers supportive actions to task-oriented ones when they reduce future goal-conflicts. Our experiments in simulation, using a simplified human model, reveal that supportive actions reduce the interference between agents, especially in more difficult tasks, but also cause the robot to take longer to complete the task. We implemented these modes on a physical robot in a user study where a human and a robot perform object placement on a shared table. Our results show that a supportive robot was perceived as a more favorable coworker by the human and also reduced interference with the human in the more difficult of two scenarios. However, it also took longer to complete the task highlighting an interesting trade-off between task-efficiency and human-preference that needs to be considered before designing robot behavior for close-proximity manipulation scenarios.
Learning to Place Objects onto Flat Surfaces in Human-Preferred Orientations
Apr 01, 2020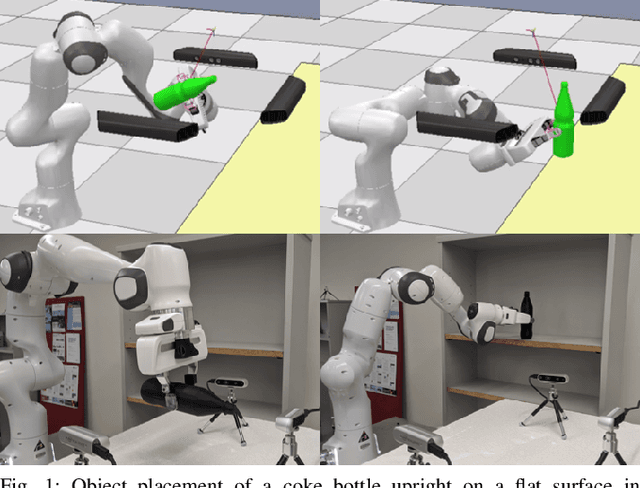
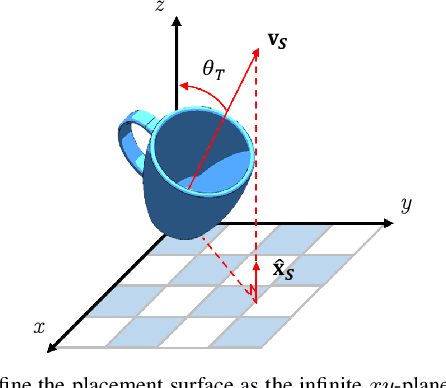
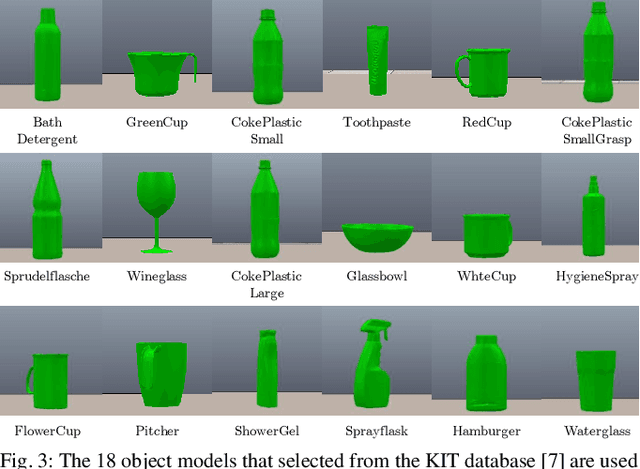
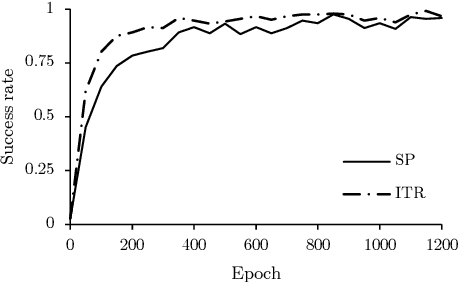
We study the problem of placing a grasped object on an empty flat surface in a human-preferred orientation, such as placing a cup on its bottom rather than on its side. We aim to find the required object rotation such that when the gripper is opened after the object makes a contact with the surface, the object would be stably placed in the desired orientation. We use two neural networks in an iterative fashion. At every iteration, Placement Rotation CNN (PR-CNN) estimates the required object rotation which is executed by the robot, and then Placement Stability CNN (PS-CNN) estimates if the object would be stable if it is placed in its current orientation. In simulation experiments, our approach places objects in human-preferred orientations with a success rate of 86.1% using a dataset of 18 everyday objects. A real-world implementation is presented, which serves as a proof-of-concept for direct sim-to-real transfer. We observe that sometimes it is impossible to place a grasped object in a desired orientation without re-grasping, which motivates future research for grasping with intention to place objects.
Model-free vision-based shaping of deformable plastic materials
Jan 30, 2020


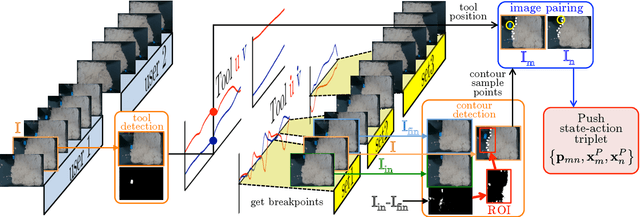
We address the problem of shaping deformable plastic materials using non-prehensile actions. Shaping plastic objects is challenging, since they are difficult to model and to track visually. We study this problem, by using kinetic sand, a plastic toy material which mimics the physical properties of wet sand. Inspired by a pilot study where humans shape kinetic sand, we define two types of actions: \textit{pushing} the material from the sides and \textit{tapping} from above. The chosen actions are executed with a robotic arm using image-based visual servoing. From the current and desired view of the material, we define states based on visual features such as the outer contour shape and the pixel luminosity values. These are mapped to actions, which are repeated iteratively to reduce the image error until convergence is reached. For pushing, we propose three methods for mapping the visual state to an action. These include heuristic methods and a neural network, trained from human actions. We show that it is possible to obtain simple shapes with the kinetic sand, without explicitly modeling the material. Our approach is limited in the types of shapes it can achieve. A richer set of action types and multi-step reasoning is needed to achieve more sophisticated shapes.
Embracing Contact: Pushing Multiple Objects with Robot's Forearm
Jun 17, 2019

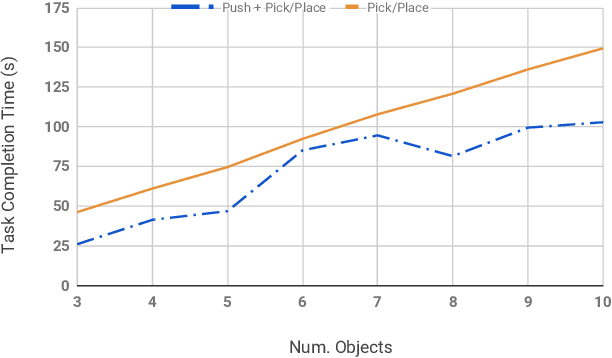
Grasping is the dominant approach for robot manipulation, but only a single object can be grasped at a time. Nonprehensile manipulation offers richer set of interactions, however state-of-the-art is limited to using the end-effector only. We propose using a robot link (forearm) to push multiple objects at once. In a simulated task where the robot's task is to sort two kinds of objects into their respective goal regions, we show that a greedy strategy that uses a combination of forearm pushes and pick and place operations reduces task completion time by %28 compared to picking and placing each object individually.
Practical Robot Learning from Demonstrations using Deep End-to-End Training
Jun 07, 2019
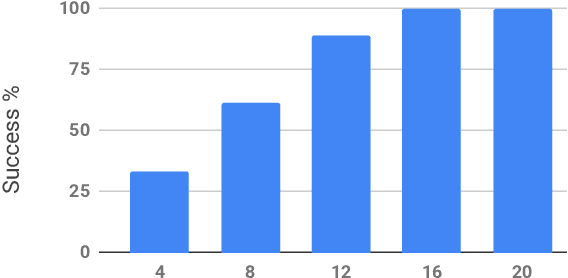
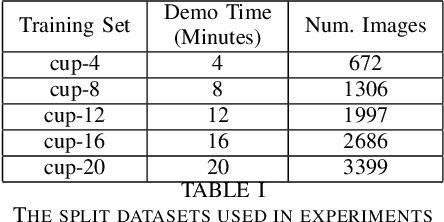
Robots need to learn behaviors in intuitive and practical ways for widespread deployment in human environments. To learn a robot behavior end-to-end, we train a variant of the ResNet that maps eye-in-hand camera images to end-effector velocities. In our setup, a human teacher demonstrates the task via joystick. We show that a simple servoing task can be learned in less than an hour including data collection, model training and deployment time. Moreover, 16 minutes of demonstrations were enough for the robot to learn the task.