 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Pixel Directional Boundary by Vector Transform
Mar 16, 2022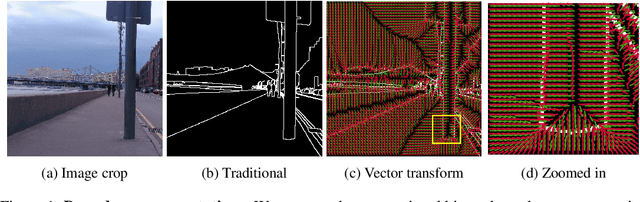
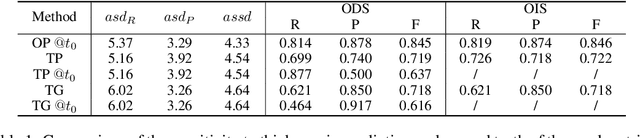
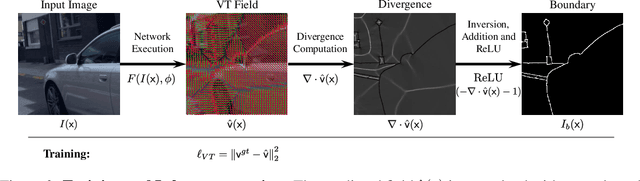
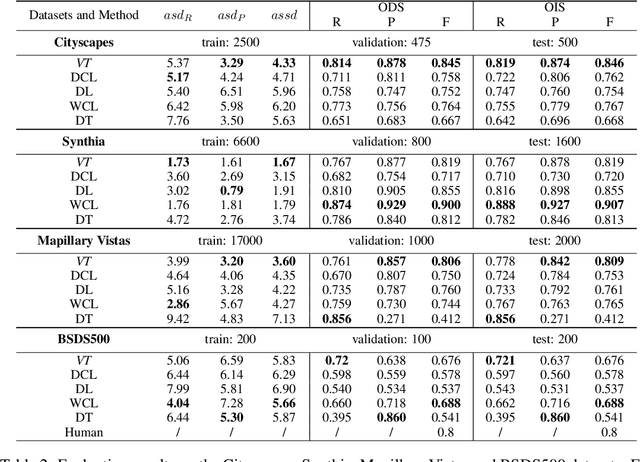
Boundaries are among the primary visual cues used by human and computer vision systems. One of the key problems in boundary detection is the label representation, which typically leads to class imbalance and, as a consequence, to thick boundaries that require non-differential post-processing steps to be thinned. In this paper, we re-interpret boundaries as 1-D surfaces and formulate a one-to-one vector transform function that allows for training of boundary prediction completely avoiding the class imbalance issue. Specifically, we define the boundary representation at any point as the unit vector pointing to the closest boundary surface. Our problem formulation leads to the estimation of direction as well as richer contextual information of the boundary, and, if desired, the availability of zero-pixel thin boundaries also at training time. Our method uses no hyper-parameter in the training loss and a fixed stable hyper-parameter at inference. We provide theoretical justification/discussions of the vector transform representation. We evaluate the proposed loss method using a standard architecture and show the excellent performance over other losses and representations on several datasets.
ZippyPoint: Fast Interest Point Detection, Description, and Matching through Mixed Precision Discretization
Mar 07, 2022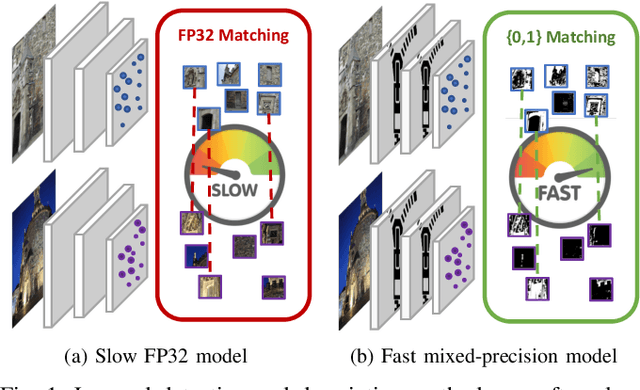
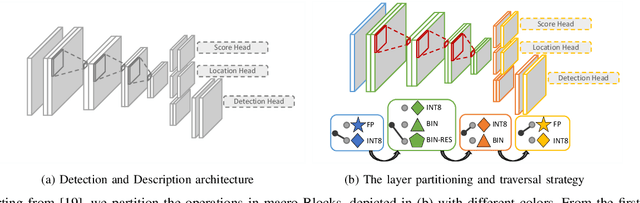
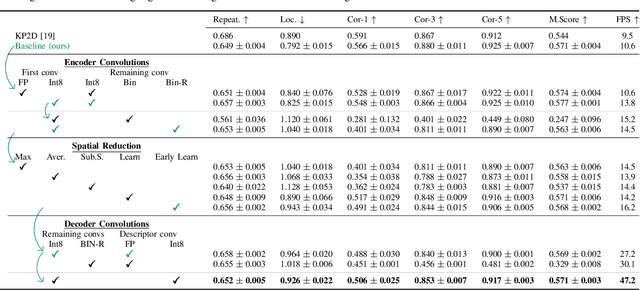

The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in local feature detection and description. These advances can be attributed to deeper networks, improved training methodologies through self-supervision, or the introduction of new building blocks, such as graph neural networks for feature matching. However, in the pursuit of increased performance, efficient architectures that generate lightweight descriptors have received surprisingly little attention. In this paper, we investigate the adaptations neural networks for detection and description require in order to enable their use in embedded platforms. To that end, we investigate and adapt network quantization techniques for use in real-time applications. In addition, we revisit common practices in descriptor quantization and propose the use of a binary descriptor normalization layer, enabling the generation of distinctive length-invariant binary descriptors. ZippyPoint, our efficient network, runs at 47.2 fps on the Apple M1 CPU. This is up to 5x faster than other learned detection and description models, making it the only real-time learned network. ZippyPoint consistently outperforms all other binary detection and descriptor methods in visual localization and homography estimation tasks. Code and trained models will be released upon publication.
TADA: Taxonomy Adaptive Domain Adaptation
Sep 10, 2021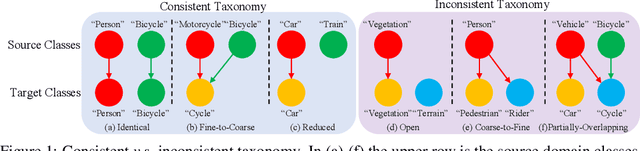
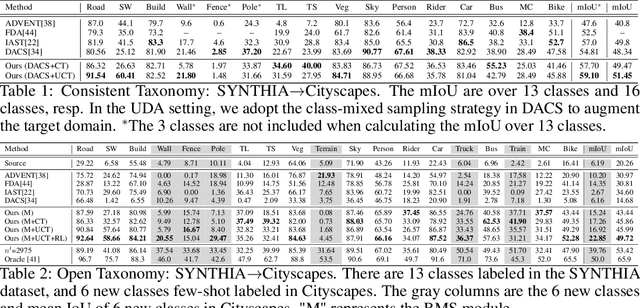
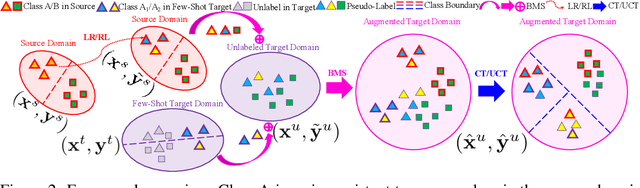
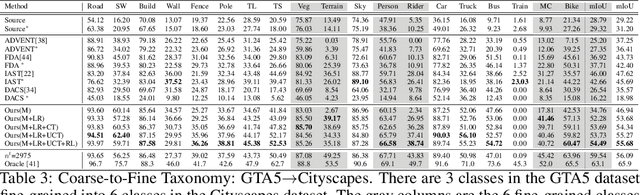
Traditional domain adaptation addresses the task of adapting a model to a novel target domain under limited or no additional supervision. While tackling the input domain gap, the standard domain adaptation settings assume no domain change in the output space. In semantic prediction tasks, different datasets are often labeled according to different semantic taxonomies. In many real-world settings, the target domain task requires a different taxonomy than the one imposed by the source domain. We therefore introduce the more general taxonomy adaptive domain adaptation (TADA) problem, allowing for inconsistent taxonomies between the two domains. We further propose an approach that jointly addresses the image-level and label-level domain adaptation. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features. We extensively evaluate the effectiveness of our framework under different TADA settings: open taxonomy, coarse-to-fine taxonomy, and partially-overlapping taxonomy. Our framework outperforms previous state-of-the-art by a large margin, while capable of adapting to new target domain taxonomies.
Transformer in Convolutional Neural Networks
Jun 09, 2021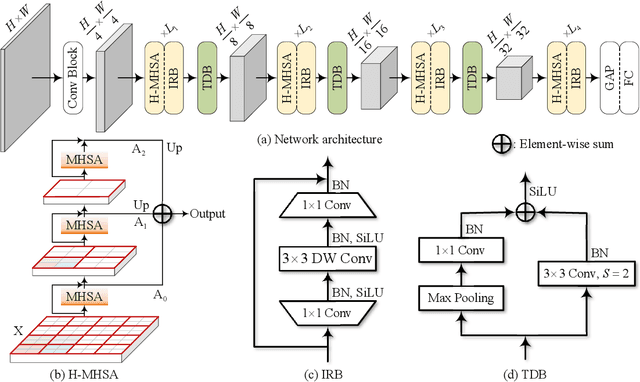
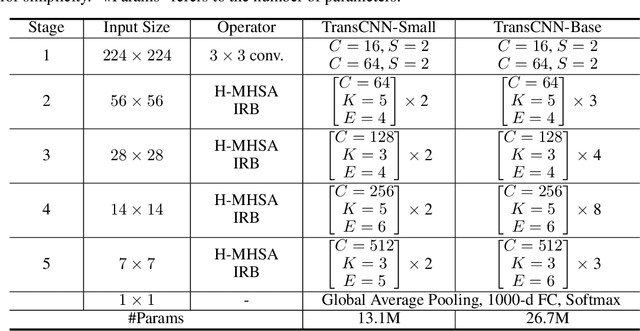

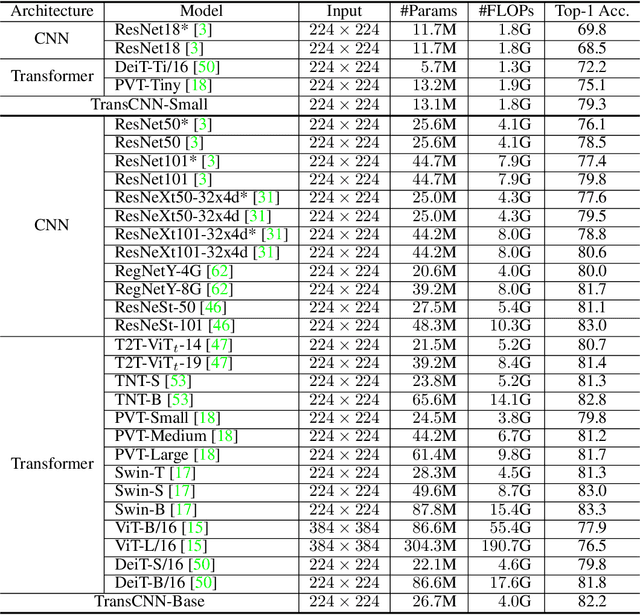
We tackle the low-efficiency flaw of vision transformer caused by the high computational/space complexity in Multi-Head Self-Attention (MHSA). To this end, we propose the Hierarchical MHSA (H-MHSA), whose representation is computed in a hierarchical manner. Specifically, our H-MHSA first learns feature relationships within small grids by viewing image patches as tokens. Then, small grids are merged into larger ones, within which feature relationship is learned by viewing each small grid at the preceding step as a token. This process is iterated to gradually reduce the number of tokens. The H-MHSA module is readily pluggable into any CNN architectures and amenable to training via backpropagation. We call this new backbone TransCNN, and it essentially inherits the advantages of both transformer and CNN. Experiments demonstrate that TransCNN achieves state-of-the-art accuracy for image recognition. Code and pretrained models are available at https://github.com/yun-liu/TransCNN. This technical report will keep updating by adding more experiments.
Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
Feb 12, 2021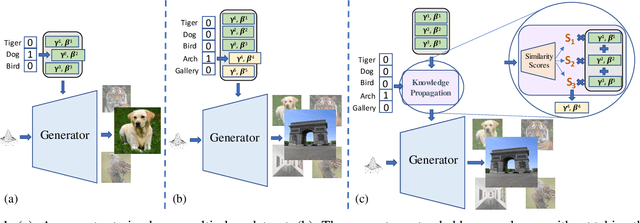



Generative adversarial networks (GANs) have shown impressive results in both unconditional and conditional image generation. In recent literature, it is shown that pre-trained GANs, on a different dataset, can be transferred to improve the image generation from a small target data. The same, however, has not been well-studied in the case of conditional GANs (cGANs), which provides new opportunities for knowledge transfer compared to unconditional setup. In particular, the new classes may borrow knowledge from the related old classes, or share knowledge among themselves to improve the training. This motivates us to study the problem of efficient conditional GAN transfer with knowledge propagation across classes. To address this problem, we introduce a new GAN transfer method to explicitly propagate the knowledge from the old classes to the new classes. The key idea is to enforce the popularly used conditional batch normalization (BN) to learn the class-specific information of the new classes from that of the old classes, with implicit knowledge sharing among the new ones. This allows for an efficient knowledge propagation from the old classes to the new classes, with the BN parameters increasing linearly with the number of new classes. The extensive evaluation demonstrates the clear superiority of the proposed method over state-of-the-art competitors for efficient conditional GAN transfer tasks. The code will be available at: https://github.com/mshahbazi72/cGANTransfer
Unsupervised Monocular Depth Reconstruction of Non-Rigid Scenes
Dec 31, 2020
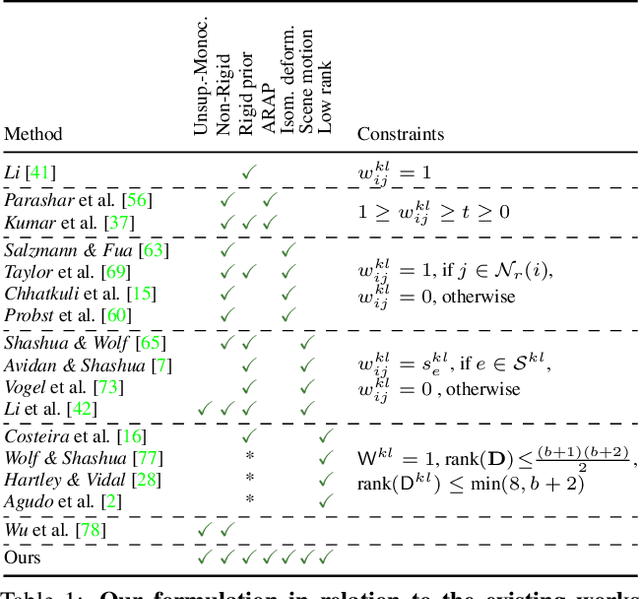
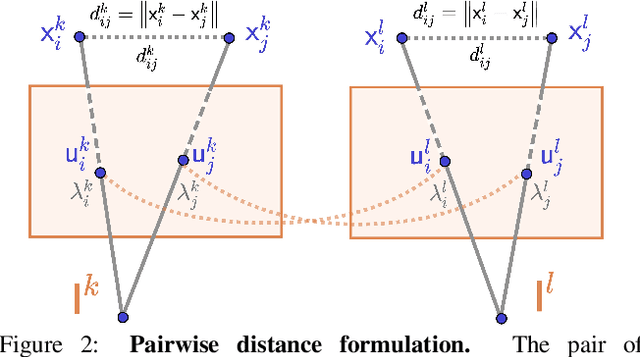
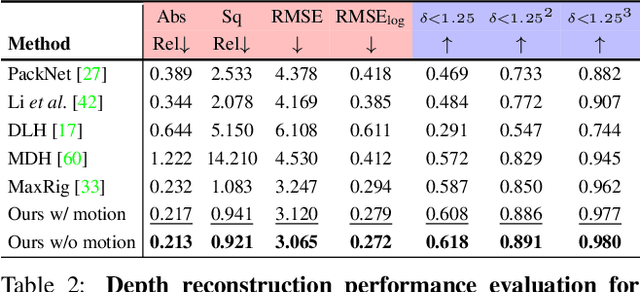
Monocular depth reconstruction of complex and dynamic scenes is a highly challenging problem. While for rigid scenes learning-based methods have been offering promising results even in unsupervised cases, there exists little to no literature addressing the same for dynamic and deformable scenes. In this work, we present an unsupervised monocular framework for dense depth estimation of dynamic scenes, which jointly reconstructs rigid and non-rigid parts without explicitly modelling the camera motion. Using dense correspondences, we derive a training objective that aims to opportunistically preserve pairwise distances between reconstructed 3D points. In this process, the dense depth map is learned implicitly using the as-rigid-as-possible hypothesis. Our method provides promising results, demonstrating its capability of reconstructing 3D from challenging videos of non-rigid scenes. Furthermore, the proposed method also provides unsupervised motion segmentation results as an auxiliary output.
Cluster, Split, Fuse, and Update: Meta-Learning for Open Compound Domain Adaptive Semantic Segmentation
Dec 15, 2020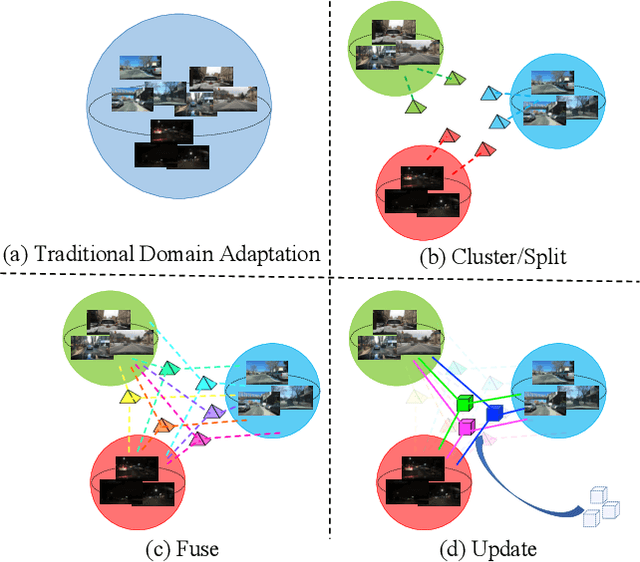
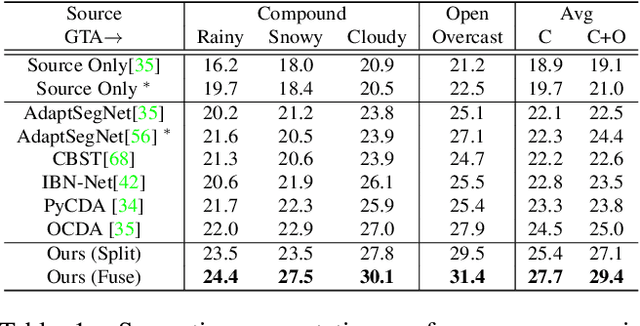
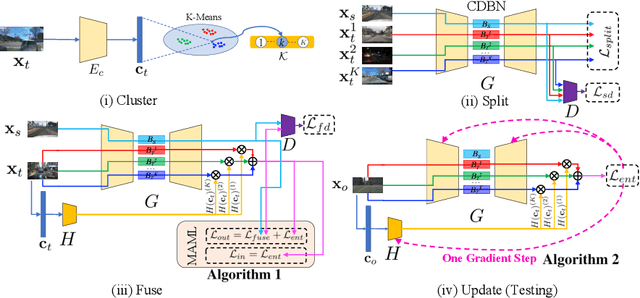
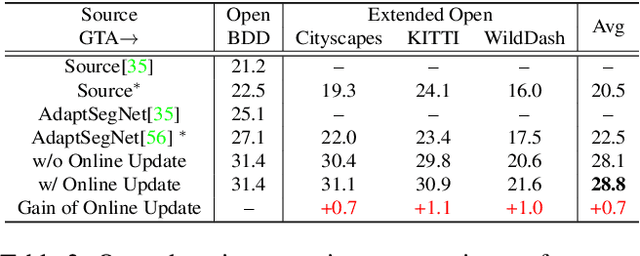
Open compound domain adaptation (OCDA) is a domain adaptation setting, where target domain is modeled as a compound of multiple unknown homogeneous domains, which brings the advantage of improved generalization to unseen domains. In this work, we propose a principled meta-learning based approach to OCDA for semantic segmentation, MOCDA, by modeling the unlabeled target domain continuously. Our approach consists of four key steps. First, we cluster target domain into multiple sub-target domains by image styles, extracted in an unsupervised manner. Then, different sub-target domains are split into independent branches, for which batch normalization parameters are learnt to treat them independently. A meta-learner is thereafter deployed to learn to fuse sub-target domain-specific predictions, conditioned upon the style code. Meanwhile, we learn to online update the model by model-agnostic meta-learning (MAML) algorithm, thus to further improve generalization. We validate the benefits of our approach by extensive experiments on synthetic-to-real knowledge transfer benchmark datasets, where we achieve the state-of-the-art performance in both compound and open domains.
Learning Condition Invariant Features for Retrieval-Based Localization from 1M Images
Aug 27, 2020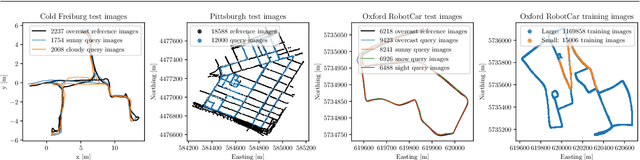

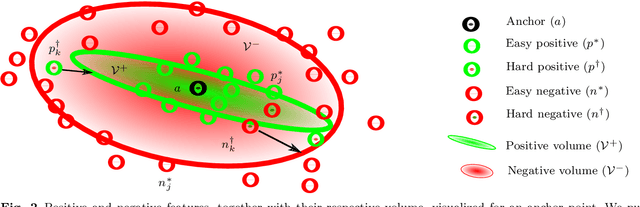
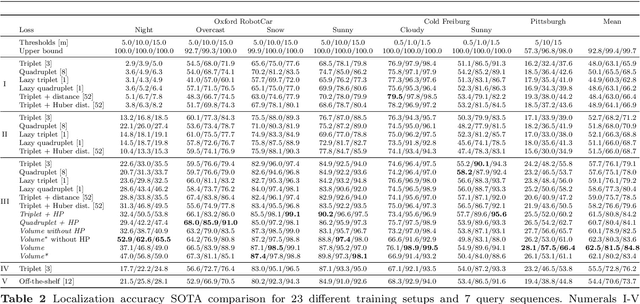
Image features for retrieval-based localization must be invariant to dynamic objects (e.g. cars) as well as seasonal and daytime changes. Such invariances are, up to some extent, learnable with existing methods using triplet-like losses, given a large number of diverse training images. However, due to the high algorithmic training complexity, there exists insufficient comparison between different loss functions on large datasets. In this paper, we train and evaluate several localization methods on three different benchmark datasets, including Oxford RobotCar with over one million images. This large scale evaluation yields valuable insights into the generalizability and performance of retrieval-based localization. Based on our findings, we develop a novel method for learning more accurate and better generalizing localization features. It consists of two main contributions: (i) a feature volume-based loss function, and (ii) hard positive and pairwise negative mining. On the challenging Oxford RobotCar night condition, our method outperforms the well-known triplet loss by 24.4% in localization accuracy within 5m.
Self-Calibration Supported Robust Projective Structure-from-Motion
Jul 04, 2020
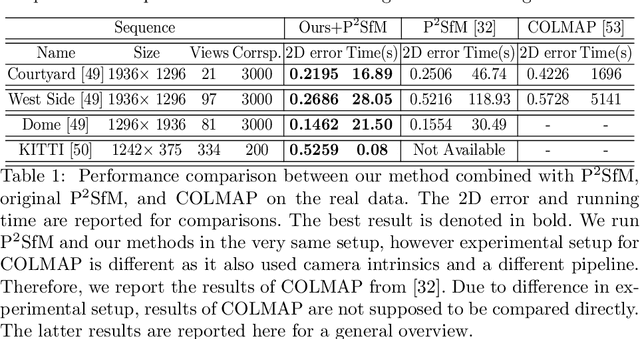
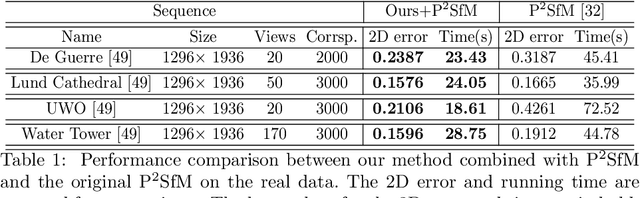
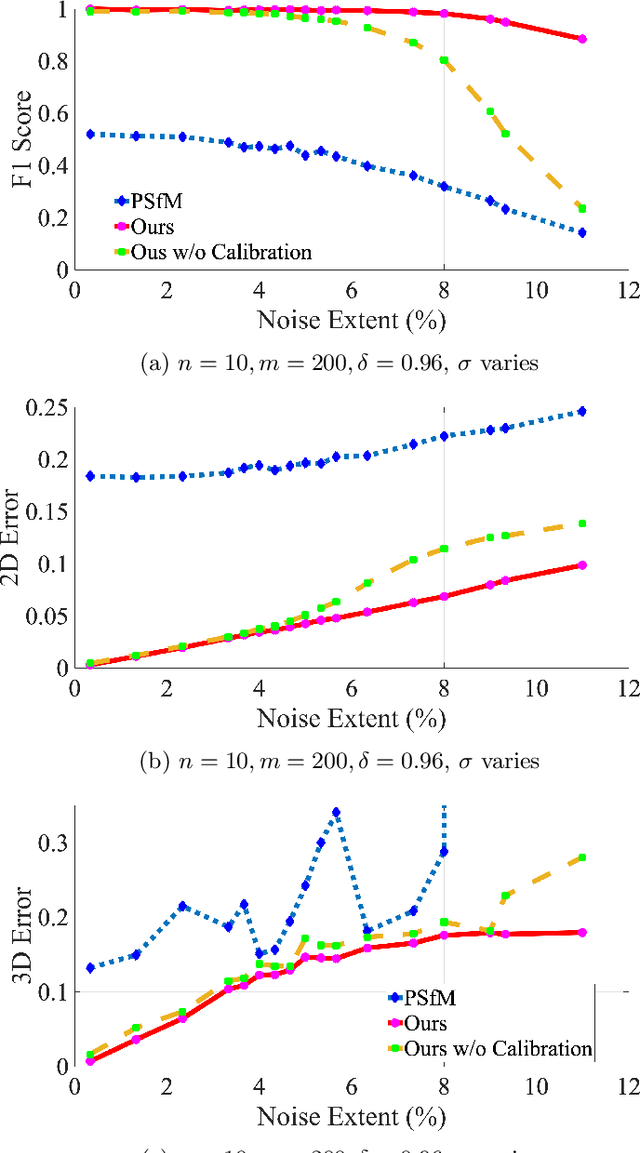
Typical Structure-from-Motion (SfM) pipelines rely on finding correspondences across images, recovering the projective structure of the observed scene and upgrading it to a metric frame using camera self-calibration constraints. Solving each problem is mainly carried out independently from the others. For instance, camera self-calibration generally assumes correct matches and a good projective reconstruction have been obtained. In this paper, we propose a unified SfM method, in which the matching process is supported by self-calibration constraints. We use the idea that good matches should yield a valid calibration. In this process, we make use of the Dual Image of Absolute Quadric projection equations within a multiview correspondence framework, in order to obtain robust matching from a set of putative correspondences. The matching process classifies points as inliers or outliers, which is learned in an unsupervised manner using a deep neural network. Together with theoretical reasoning why the self-calibration constraints are necessary, we show experimental results demonstrating robust multiview matching and accurate camera calibration by exploiting these constraints.
Geometrically Mappable Image Features
Mar 21, 2020
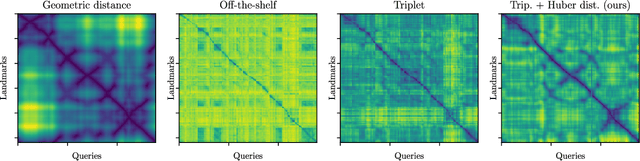
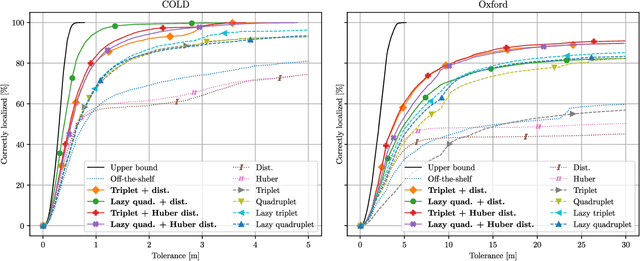

Vision-based localization of an agent in a map is an important problem in robotics and computer vision. In that context, localization by learning matchable image features is gaining popularity due to recent advances in machine learning. Features that uniquely describe the visual contents of images have a wide range of applications, including image retrieval and understanding. In this work, we propose a method that learns image features targeted for image-retrieval-based localization. Retrieval-based localization has several benefits, such as easy maintenance and quick computation. However, the state-of-the-art features only provide visual similarity scores which do not explicitly reveal the geometric distance between query and retrieved images. Knowing this distance is highly desirable for accurate localization, especially when the reference images are sparsely distributed in the scene. Therefore, we propose a novel loss function for learning image features which are both visually representative and geometrically relatable. This is achieved by guiding the learning process such that the feature and geometric distances between images are directly proportional. In our experiments we show that our features not only offer significantly better localization accuracy, but also allow to estimate the trajectory of a query sequence in absence of the reference images.
* Implementation available at https://github.com/janinethoma/geometrically_mappable