 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouter-Suggest: Dynamic Routing for Multimodal Auto-Completion in Visually-Grounded Dialogs
Jan 09, 2026Real-time multimodal auto-completion is essential for digital assistants, chatbots, design tools, and healthcare consultations, where user inputs rely on shared visual context. We introduce Multimodal Auto-Completion (MAC), a task that predicts upcoming characters in live chats using partially typed text and visual cues. Unlike traditional text-only auto-completion (TAC), MAC grounds predictions in multimodal context to better capture user intent. To enable this task, we adapt MMDialog and ImageChat to create benchmark datasets. We evaluate leading vision-language models (VLMs) against strong textual baselines, highlighting trade-offs in accuracy and efficiency. We present Router-Suggest, a router framework that dynamically selects between textual models and VLMs based on dialog context, along with a lightweight variant for resource-constrained environments. Router-Suggest achieves a 2.3x to 10x speedup over the best-performing VLM. A user study shows that VLMs significantly excel over textual models on user satisfaction, notably saving user typing effort and improving the quality of completions in multi-turn conversations. These findings underscore the need for multimodal context in auto-completions, leading to smarter, user-aware assistants.
SCULPT: Systematic Tuning of Long Prompts
Oct 28, 2024



As large language models become increasingly central to solving complex tasks, the challenge of optimizing long, unstructured prompts has become critical. Existing optimization techniques often struggle to effectively handle such prompts, leading to suboptimal performance. We introduce SCULPT (Systematic Tuning of Long Prompts), a novel framework that systematically refines long prompts by structuring them hierarchically and applying an iterative actor-critic mechanism. To enhance robustness and generalizability, SCULPT utilizes two complementary feedback mechanisms: Preliminary Assessment, which assesses the prompt's structure before execution, and Error Assessment, which diagnoses and addresses errors post-execution. By aggregating feedback from these mechanisms, SCULPT avoids overfitting and ensures consistent improvements in performance. Our experimental results demonstrate significant accuracy gains and enhanced robustness, particularly in handling erroneous and misaligned prompts. SCULPT consistently outperforms existing approaches, establishing itself as a scalable solution for optimizing long prompts across diverse and real-world tasks.
On the Necessity of World Knowledge for Mitigating Missing Labels in Extreme Classification
Aug 18, 2024Extreme Classification (XC) aims to map a query to the most relevant documents from a very large document set. XC algorithms used in real-world applications learn this mapping from datasets curated from implicit feedback, such as user clicks. However, these datasets inevitably suffer from missing labels. In this work, we observe that systematic missing labels lead to missing knowledge, which is critical for accurately modelling relevance between queries and documents. We formally show that this absence of knowledge cannot be recovered using existing methods such as propensity weighting and data imputation strategies that solely rely on the training dataset. While LLMs provide an attractive solution to augment the missing knowledge, leveraging them in applications with low latency requirements and large document sets is challenging. To incorporate missing knowledge at scale, we propose SKIM (Scalable Knowledge Infusion for Missing Labels), an algorithm that leverages a combination of small LM and abundant unstructured meta-data to effectively mitigate the missing label problem. We show the efficacy of our method on large-scale public datasets through exhaustive unbiased evaluation ranging from human annotations to simulations inspired from industrial settings. SKIM outperforms existing methods on Recall@100 by more than 10 absolute points. Additionally, SKIM scales to proprietary query-ad retrieval datasets containing 10 million documents, outperforming contemporary methods by 12% in offline evaluation and increased ad click-yield by 1.23% in an online A/B test conducted on a popular search engine. We release our code, prompts, trained XC models and finetuned SLMs at: https://github.com/bicycleman15/skim
Frugal Prompting for Dialog Models
May 24, 2023



The use of large language models (LLMs) in natural language processing (NLP) tasks is rapidly increasing, leading to changes in how researchers approach problems in the field. To fully utilize these models' abilities, a better understanding of their behavior for different input protocols is required. With LLMs, users can directly interact with the models through a text-based interface to define and solve various tasks. Hence, understanding the conversational abilities of these LLMs, which may not have been specifically trained for dialog modeling, is also important. This study examines different approaches for building dialog systems using LLMs by considering various aspects of the prompt. As part of prompt tuning, we experiment with various ways of providing instructions, exemplars, current query and additional context. The research also analyzes the representations of dialog history that have the optimal usable-information density. Based on the findings, the paper suggests more compact ways of providing dialog history information while ensuring good performance and reducing model's inference-API costs. The research contributes to a better understanding of how LLMs can be effectively used for building interactive systems.
CORAL: Contextual Response Retrievability Loss Function for Training Dialog Generation Models
May 21, 2022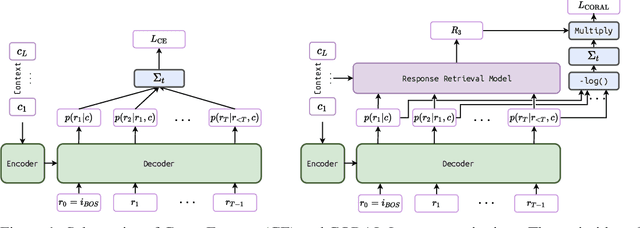

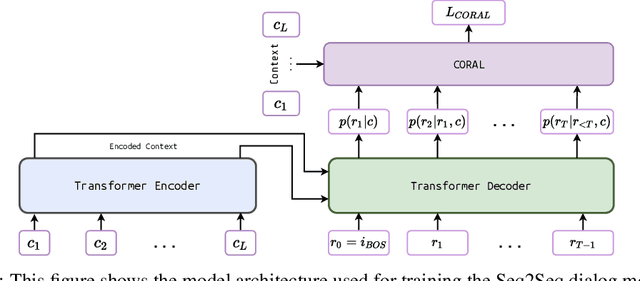
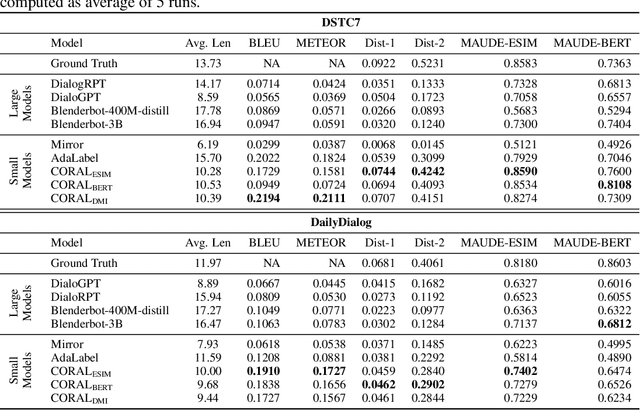
Natural Language Generation (NLG) represents a large collection of tasks in the field of NLP. While many of these tasks have been tackled well by the cross-entropy (CE) loss, the task of dialog generation poses a few unique challenges for this loss function. First, CE loss assumes that for any given input, the only possible output is the one available as the ground truth in the training dataset. In general, this is not true for any task, as there can be multiple semantically equivalent sentences, each with a different surface form. This problem gets exaggerated further for the dialog generation task, as there can be multiple valid responses (for a given context) that not only have different surface forms but are also not semantically equivalent. Second, CE loss does not take the context into consideration while processing the response and, hence, it treats all ground truths with equal importance irrespective of the context. But, we may want our final agent to avoid certain classes of responses (e.g. bland, non-informative or biased responses) and give relatively higher weightage for more context-specific responses. To circumvent these shortcomings of the CE loss, in this paper, we propose a novel loss function, CORAL, that directly optimizes recently proposed estimates of human preference for generated responses. Using CORAL, we can train dialog generation models without assuming non-existence of response other than the ground-truth. Also, the CORAL loss is computed based on both the context and the response. Extensive comparisons on two benchmark datasets show that the proposed methods outperform strong state-of-the-art baseline models of different sizes.
A Study on Prompt-based Few-Shot Learning Methods for Belief State Tracking in Task-oriented Dialog Systems
Apr 18, 2022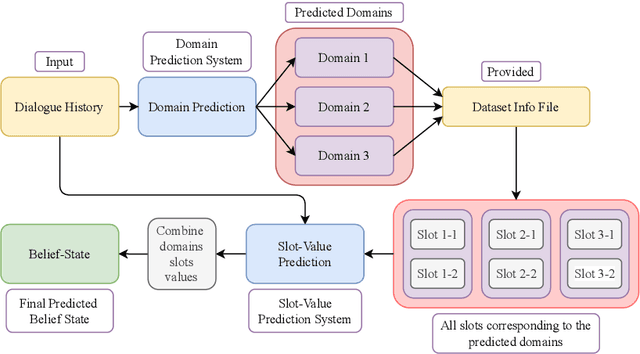
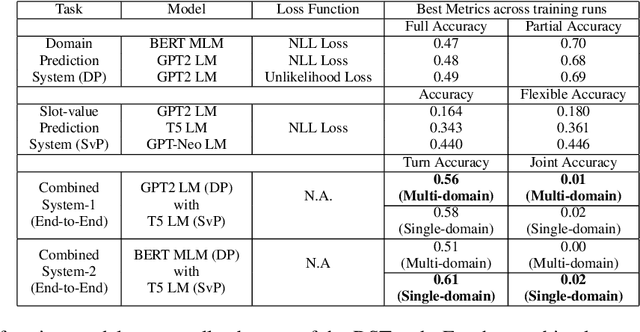
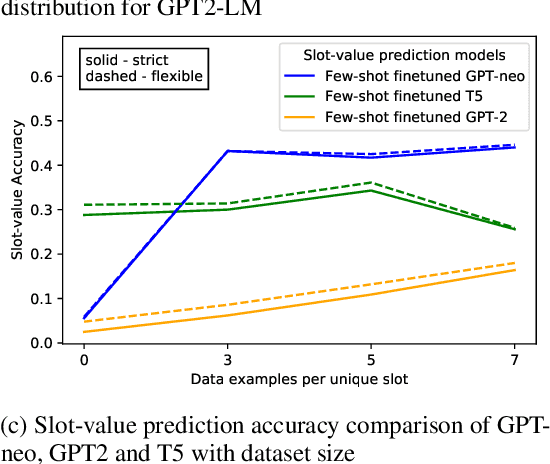
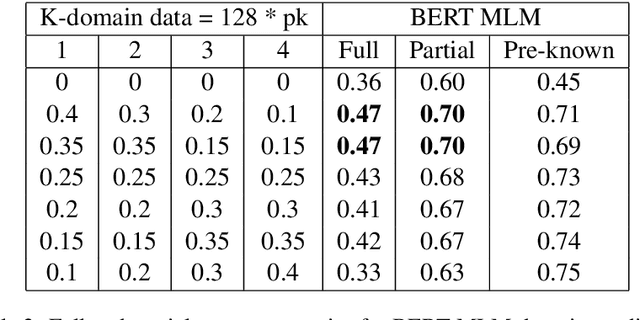
We tackle the Dialogue Belief State Tracking(DST) problem of task-oriented conversational systems. Recent approaches to this problem leveraging Transformer-based models have yielded great results. However, training these models is expensive, both in terms of computational resources and time. Additionally, collecting high quality annotated dialogue datasets remains a challenge for researchers because of the extensive annotation required for training these models. Driven by the recent success of pre-trained language models and prompt-based learning, we explore prompt-based few-shot learning for Dialogue Belief State Tracking. We formulate the DST problem as a 2-stage prompt-based language modelling task and train language models for both tasks and present a comprehensive empirical analysis of their separate and joint performance. We demonstrate the potential of prompt-based methods in few-shot learning for DST and provide directions for future improvement.
Representation Learning for Conversational Data using Discourse Mutual Information Maximization
Dec 04, 2021
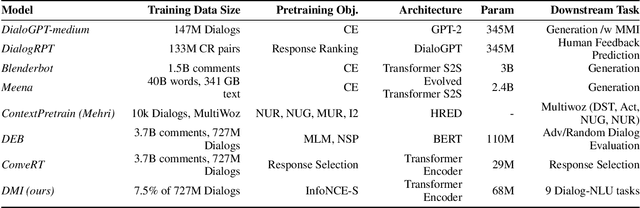
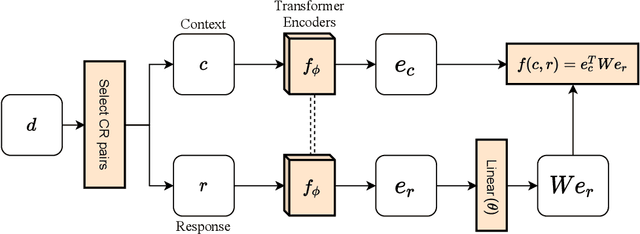

Although many pretrained models exist for text or images, there have been relatively fewer attempts to train representations specifically for dialog understanding. Prior works usually relied on finetuned representations based on generic text representation models like BERT or GPT-2. But, existing pretraining objectives do not take the structural information of text into consideration. Although generative dialog models can learn structural features too, we argue that the structure-unaware word-by-word generation is not suitable for effective conversation modeling. We empirically demonstrate that such representations do not perform consistently across various dialog understanding tasks. Hence, we propose a structure-aware Mutual Information based loss-function DMI (Discourse Mutual Information) for training dialog-representation models, that additionally captures the inherent uncertainty in response prediction. Extensive evaluation on nine diverse dialog modeling tasks shows that our proposed DMI-based models outperform strong baselines by significant margins, even with small-scale pretraining. Our models show the most promising performance on the dialog evaluation task DailyDialog++, in both random and adversarial negative scenarios.
Exploring Effects of Random Walk Based Minibatch Selection Policy on Knowledge Graph Completion
Apr 12, 2020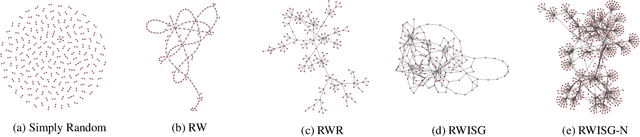
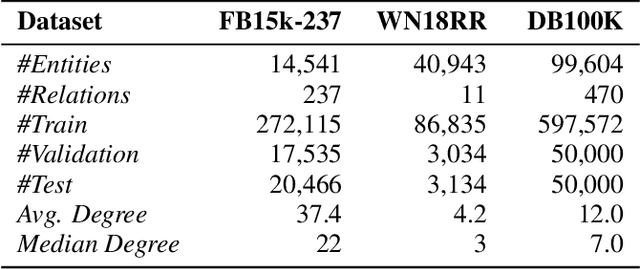
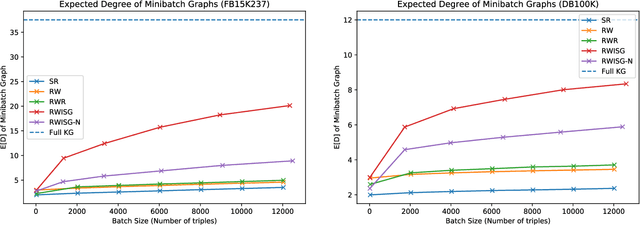
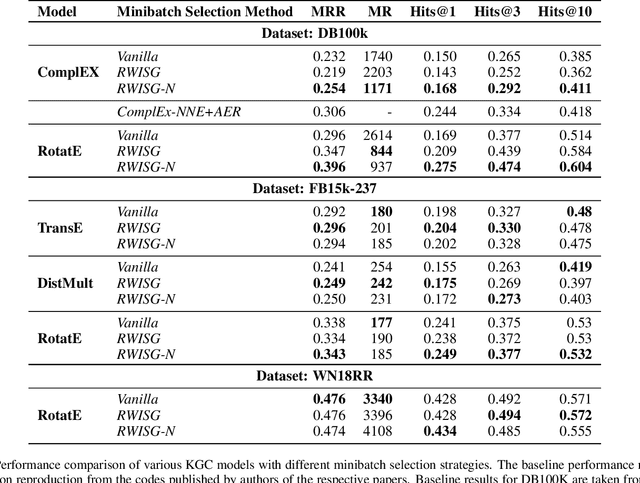
In this paper, we have explored the effects of different minibatch sampling techniques in Knowledge Graph Completion. Knowledge Graph Completion (KGC) or Link Prediction is the task of predicting missing facts in a knowledge graph. KGC models are usually trained using margin, soft-margin or cross-entropy loss function that promotes assigning a higher score or probability for true fact triplets. Minibatch gradient descent is used to optimize these loss functions for training the KGC models. But, as each minibatch consists of only a few randomly sampled triplets from a large knowledge graph, any entity that occurs in a minibatch, occurs only once in most cases. Because of this, these loss functions ignore all other neighbors of any entity, whose embedding is being updated at some minibatch step. In this paper, we propose a new random-walk based minibatch sampling technique for training KGC models that optimizes the loss incurred by a minibatch of closely connected subgraph of triplets instead of randomly selected ones. We have shown results of experiments for different models and datasets with our sampling technique and found that the proposed sampling algorithm has varying effects on these datasets/models. Specifically, we find that our proposed method achieves state-of-the-art performance on the DB100K dataset.
Incorporating Domain Knowledge into Medical NLI using Knowledge Graphs
Aug 31, 2019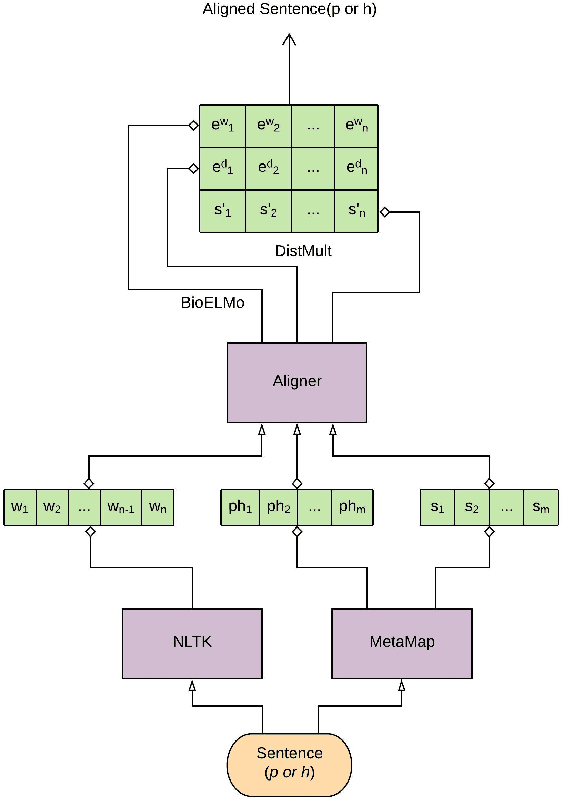
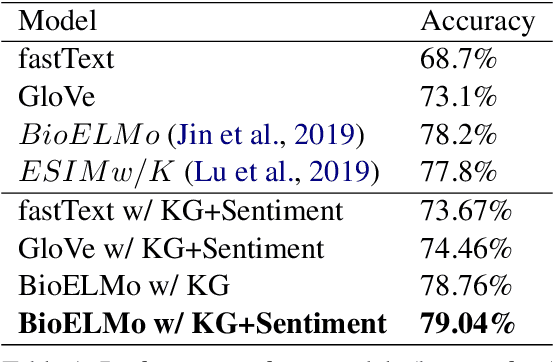
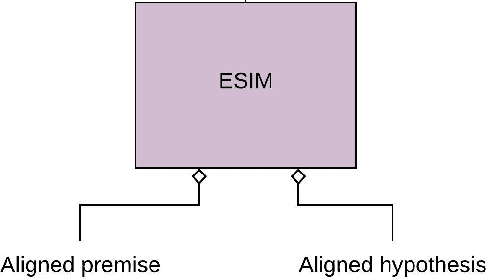
Recently, biomedical version of embeddings obtained from language models such as BioELMo have shown state-of-the-art results for the textual inference task in the medical domain. In this paper, we explore how to incorporate structured domain knowledge, available in the form of a knowledge graph (UMLS), for the Medical NLI task. Specifically, we experiment with fusing embeddings obtained from knowledge graph with the state-of-the-art approaches for NLI task (ESIM model). We also experiment with fusing the domain-specific sentiment information for the task. Experiments conducted on MedNLI dataset clearly show that this strategy improves the baseline BioELMo architecture for the Medical NLI task.
Free as in Free Word Order: An Energy Based Model for Word Segmentation and Morphological Tagging in Sanskrit
Oct 25, 2018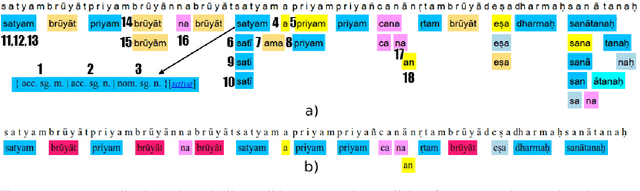
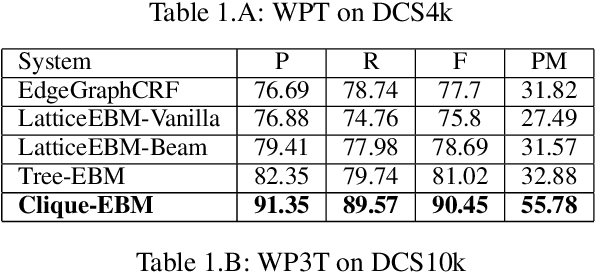
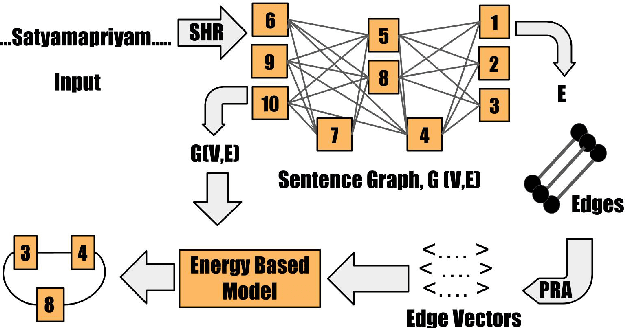
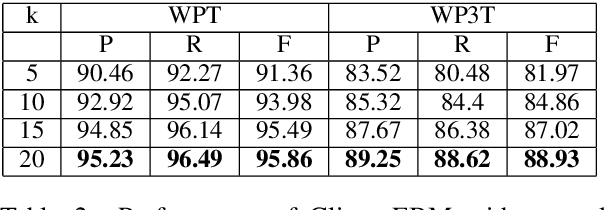
The configurational information in sentences of a free word order language such as Sanskrit is of limited use. Thus, the context of the entire sentence will be desirable even for basic processing tasks such as word segmentation. We propose a structured prediction framework that jointly solves the word segmentation and morphological tagging tasks in Sanskrit. We build an energy based model where we adopt approaches generally employed in graph based parsing techniques (McDonald et al., 2005a; Carreras, 2007). Our model outperforms the state of the art with an F-Score of 96.92 (percentage improvement of 7.06%) while using less than one-tenth of the task-specific training data. We find that the use of a graph based ap- proach instead of a traditional lattice-based sequential labelling approach leads to a percentage gain of 12.6% in F-Score for the segmentation task.