 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatics in Grounded Language Learning: Phenomena, Tasks, and Modeling Approaches
Nov 15, 2022People rely heavily on context to enrich meaning beyond what is literally said, enabling concise but effective communication. To interact successfully and naturally with people, user-facing artificial intelligence systems will require similar skills in pragmatics: relying on various types of context -- from shared linguistic goals and conventions, to the visual and embodied world -- to use language effectively. We survey existing grounded settings and pragmatic modeling approaches and analyze how the task goals, environmental contexts, and communicative affordances in each work enrich linguistic meaning. We present recommendations for future grounded task design to naturally elicit pragmatic phenomena, and suggest directions that focus on a broader range of communicative contexts and affordances.
MAPL: Parameter-Efficient Adaptation of Unimodal Pre-Trained Models for Vision-Language Few-Shot Prompting
Oct 13, 2022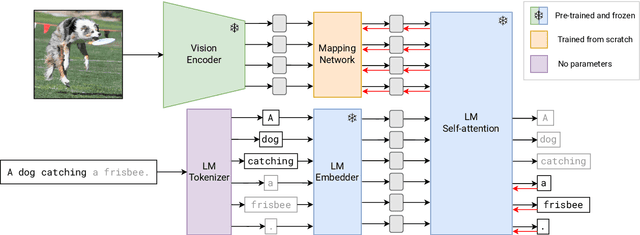

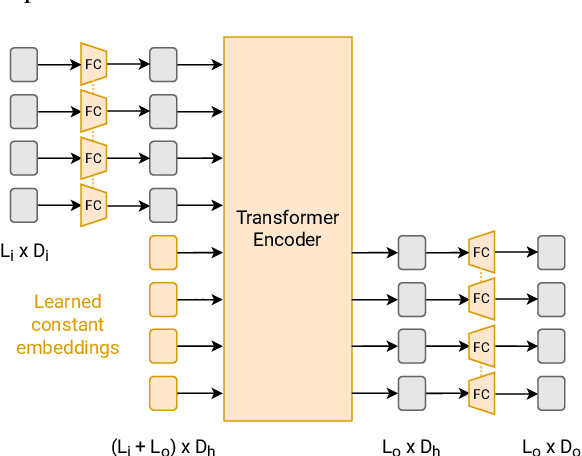
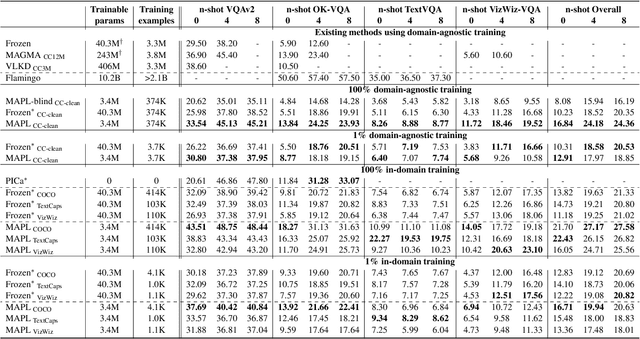
Large pre-trained models have proved to be remarkable zero- and (prompt-based) few-shot learners in unimodal vision and language tasks. We propose MAPL, a simple and parameter-efficient method that reuses frozen pre-trained unimodal models and leverages their strong generalization capabilities in multimodal vision-language (VL) settings. MAPL learns a lightweight mapping between the representation spaces of unimodal models using aligned image-text data, and can generalize to unseen VL tasks from just a few in-context examples. The small number of trainable parameters makes MAPL effective at low-data and in-domain learning. Moreover, MAPL's modularity enables easy extension to other pre-trained models. Extensive experiments on several visual question answering and image captioning benchmarks show that MAPL achieves superior or competitive performance compared to similar methods while training orders of magnitude fewer parameters. MAPL can be trained in just a few hours using modest computational resources and public datasets. We plan to release the code and pre-trained models.
Rethinking Evaluation Practices in Visual Question Answering: A Case Study on Out-of-Distribution Generalization
May 24, 2022
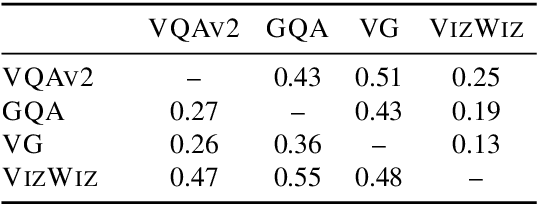
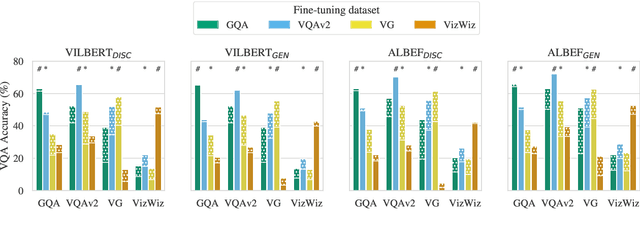
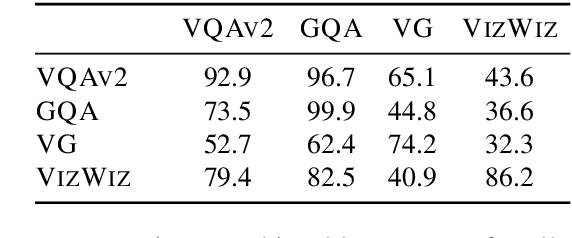
Vision-and-language (V&L) models pretrained on large-scale multimodal data have demonstrated strong performance on various tasks such as image captioning and visual question answering (VQA). The quality of such models is commonly assessed by measuring their performance on unseen data that typically comes from the same distribution as the training data. However, we observe that these models exhibit poor out-of-distribution (OOD) generalization on the task of VQA. To better understand the underlying causes of poor generalization, we comprehensively investigate performance of two pretrained V&L models under different settings (i.e. classification and open-ended text generation) by conducting cross-dataset evaluations. We find that these models tend to learn to solve the benchmark, rather than learning the high-level skills required by the VQA task. We also argue that in most cases generative models are less susceptible to shifts in data distribution, while frequently performing better on our tested benchmarks. Moreover, we find that multimodal pretraining improves OOD performance in most settings. Finally, we revisit assumptions underlying the use of automatic VQA evaluation metrics, and empirically show that their stringent nature repeatedly penalizes models for correct responses.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
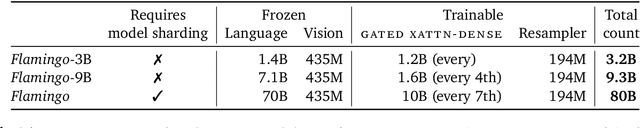
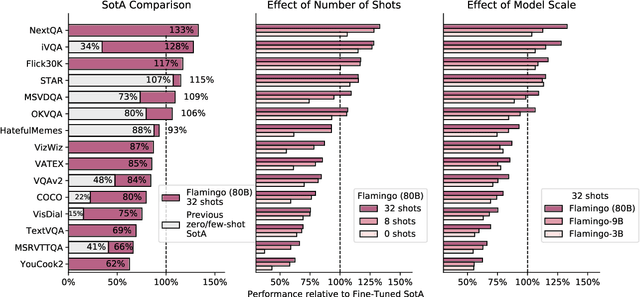
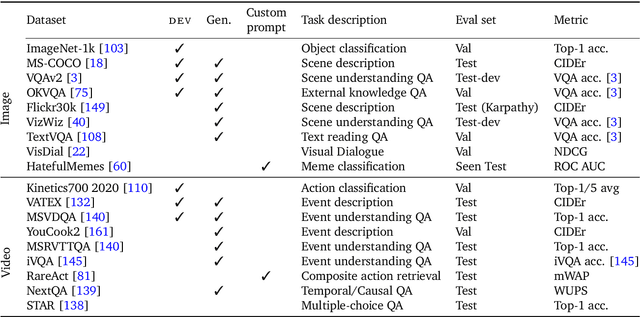
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
A Systematic Investigation of Commonsense Understanding in Large Language Models
Oct 31, 2021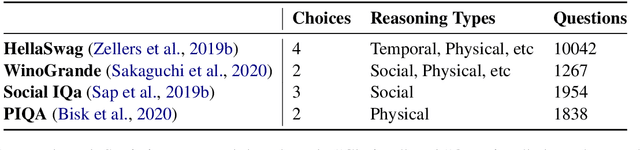
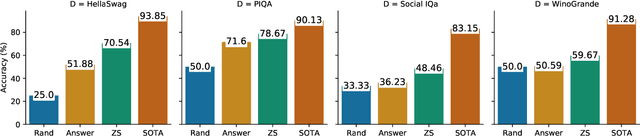

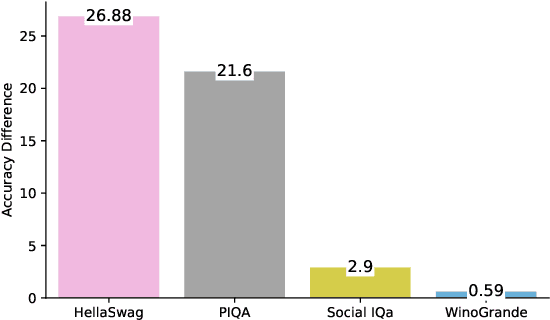
Large language models have shown impressive performance on many natural language processing (NLP) tasks in a zero-shot setting. We ask whether these models exhibit commonsense understanding -- a critical component of NLP applications -- by evaluating models against four commonsense benchmarks. We find that the impressive zero-shot performance of large language models is mostly due to existence of dataset bias in our benchmarks. We also show that the zero-shot performance is sensitive to the choice of hyper-parameters and similarity of the benchmark to the pre-training datasets. Moreover, we did not observe substantial improvements when evaluating models in a few-shot setting. Finally, in contrast to previous work, we find that leveraging explicit commonsense knowledge does not yield substantial improvement.
Probing Image-Language Transformers for Verb Understanding
Jun 16, 2021

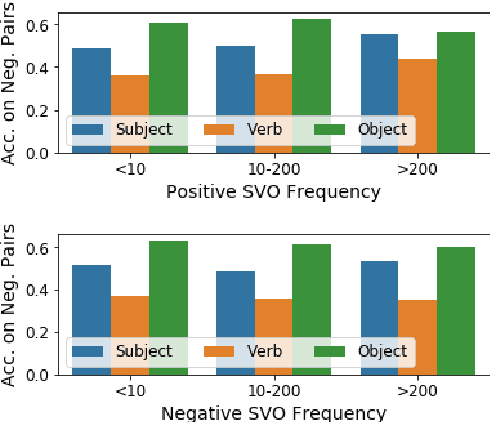
Multimodal image-language transformers have achieved impressive results on a variety of tasks that rely on fine-tuning (e.g., visual question answering and image retrieval). We are interested in shedding light on the quality of their pretrained representations -- in particular, if these models can distinguish different types of verbs or if they rely solely on nouns in a given sentence. To do so, we collect a dataset of image-sentence pairs (in English) consisting of 421 verbs that are either visual or commonly found in the pretraining data (i.e., the Conceptual Captions dataset). We use this dataset to evaluate pretrained image-language transformers and find that they fail more in situations that require verb understanding compared to other parts of speech. We also investigate what category of verbs are particularly challenging.
Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
Jan 31, 2021
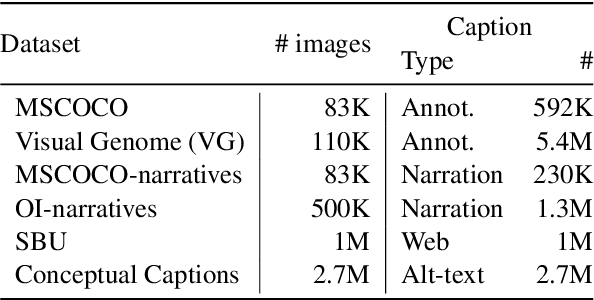
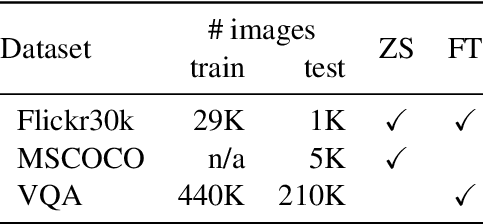
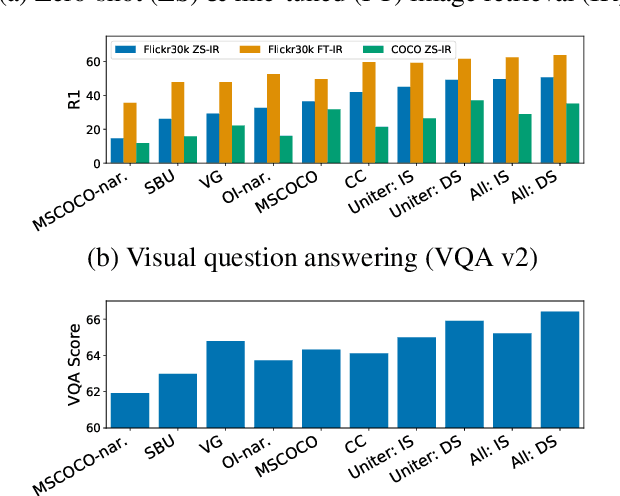
Recently multimodal transformer models have gained popularity because their performance on language and vision tasks suggest they learn rich visual-linguistic representations. Focusing on zero-shot image retrieval tasks, we study three important factors which can impact the quality of learned representations: pretraining data, the attention mechanism, and loss functions. By pretraining models on six datasets, we observe that dataset noise and language similarity to our downstream task are important indicators of model performance. Through architectural analysis, we learn that models with a multimodal attention mechanism can outperform deeper models with modality specific attention mechanisms. Finally, we show that successful contrastive losses used in the self-supervised learning literature do not yield similar performance gains when used in multimodal transformers
Competition in Cross-situational Word Learning: A Computational Study
Dec 06, 2020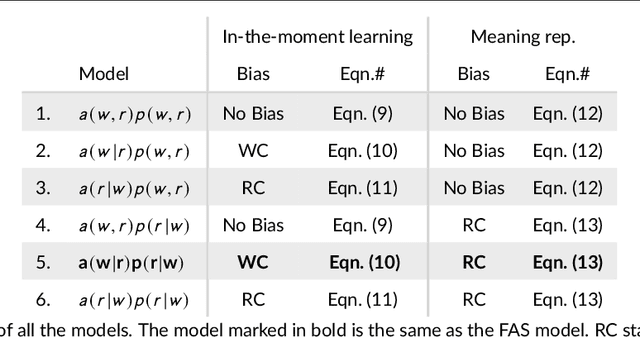

Children learn word meanings by tapping into the commonalities across different situations in which words are used and overcome the high level of uncertainty involved in early word learning experiences. In a set of computational studies, we show that to successfully learn word meanings in the face of uncertainty, a learner needs to use two types of competition: words competing for association to a referent when learning from an observation and referents competing for a word when the word is used.
Learning to Segment Actions from Observation and Narration
May 07, 2020

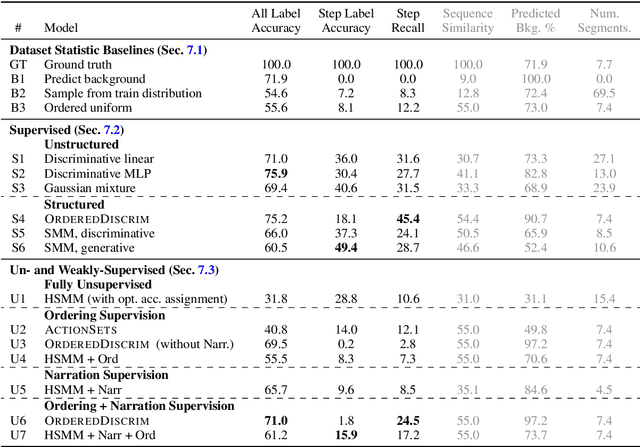
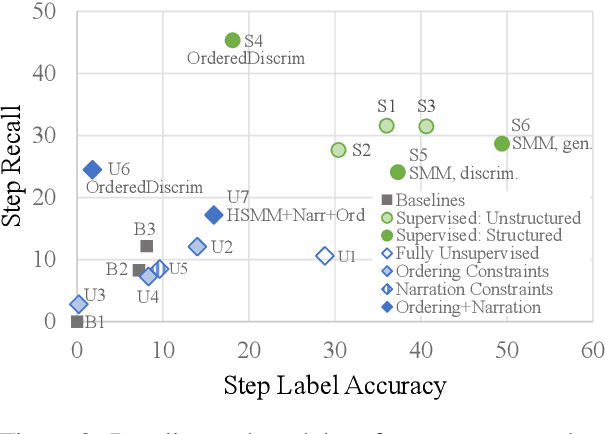
We apply a generative segmental model of task structure, guided by narration, to action segmentation in video. We focus on unsupervised and weakly-supervised settings where no action labels are known during training. Despite its simplicity, our model performs competitively with previous work on a dataset of naturalistic instructional videos. Our model allows us to vary the sources of supervision used in training, and we find that both task structure and narrative language provide large benefits in segmentation quality.