 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Federated Learning using Preference-Optimized Synthetic Data
Apr 23, 2025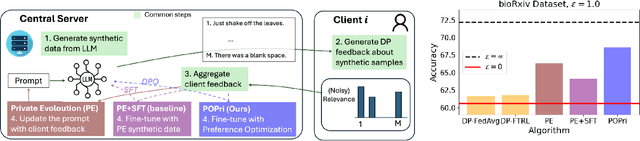
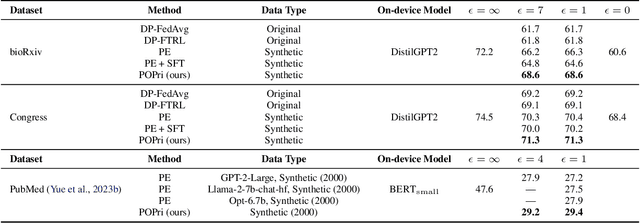
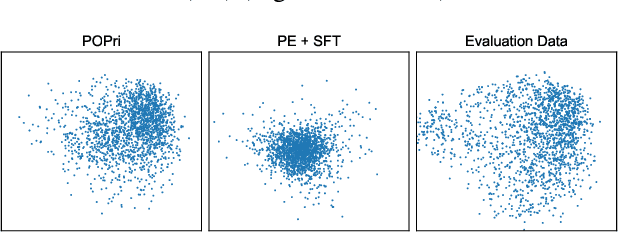

In practical settings, differentially private Federated learning (DP-FL) is the dominant method for training models from private, on-device client data. Recent work has suggested that DP-FL may be enhanced or outperformed by methods that use DP synthetic data (Wu et al., 2024; Hou et al., 2024). The primary algorithms for generating DP synthetic data for FL applications require careful prompt engineering based on public information and/or iterative private client feedback. Our key insight is that the private client feedback collected by prior DP synthetic data methods (Hou et al., 2024; Xie et al., 2024) can be viewed as a preference ranking. Our algorithm, Preference Optimization for Private Client Data (POPri) harnesses client feedback using preference optimization algorithms such as Direct Preference Optimization (DPO) to fine-tune LLMs to generate high-quality DP synthetic data. To evaluate POPri, we release LargeFedBench, a new federated text benchmark for uncontaminated LLM evaluations on federated client data. POPri substantially improves the utility of DP synthetic data relative to prior work on LargeFedBench datasets and an existing benchmark from Xie et al. (2024). POPri closes the gap between next-token prediction accuracy in the fully-private and non-private settings by up to 68%, compared to 52% for prior synthetic data methods, and 10% for state-of-the-art DP federated learning methods. The code and data are available at https://github.com/meiyuw/POPri.
PRoDeliberation: Parallel Robust Deliberation for End-to-End Spoken Language Understanding
Jun 12, 2024



Spoken Language Understanding (SLU) is a critical component of voice assistants; it consists of converting speech to semantic parses for task execution. Previous works have explored end-to-end models to improve the quality and robustness of SLU models with Deliberation, however these models have remained autoregressive, resulting in higher latencies. In this work we introduce PRoDeliberation, a novel method leveraging a Connectionist Temporal Classification-based decoding strategy as well as a denoising objective to train robust non-autoregressive deliberation models. We show that PRoDeliberation achieves the latency reduction of parallel decoding (2-10x improvement over autoregressive models) while retaining the ability to correct Automatic Speech Recognition (ASR) mistranscriptions of autoregressive deliberation systems. We further show that the design of the denoising training allows PRoDeliberation to overcome the limitations of small ASR devices, and we provide analysis on the necessity of each component of the system.
PrE-Text: Training Language Models on Private Federated Data in the Age of LLMs
Jun 05, 2024On-device training is currently the most common approach for training machine learning (ML) models on private, distributed user data. Despite this, on-device training has several drawbacks: (1) most user devices are too small to train large models on-device, (2) on-device training is communication- and computation-intensive, and (3) on-device training can be difficult to debug and deploy. To address these problems, we propose Private Evolution-Text (PrE-Text), a method for generating differentially private (DP) synthetic textual data. First, we show that across multiple datasets, training small models (models that fit on user devices) with PrE-Text synthetic data outperforms small models trained on-device under practical privacy regimes ($\epsilon=1.29$, $\epsilon=7.58$). We achieve these results while using 9$\times$ fewer rounds, 6$\times$ less client computation per round, and 100$\times$ less communication per round. Second, finetuning large models on PrE-Text's DP synthetic data improves large language model (LLM) performance on private data across the same range of privacy budgets. Altogether, these results suggest that training on DP synthetic data can be a better option than training a model on-device on private distributed data. Code is available at https://github.com/houcharlie/PrE-Text.
Augmenting text for spoken language understanding with Large Language Models
Sep 17, 2023



Spoken semantic parsing (SSP) involves generating machine-comprehensible parses from input speech. Training robust models for existing application domains represented in training data or extending to new domains requires corresponding triplets of speech-transcript-semantic parse data, which is expensive to obtain. In this paper, we address this challenge by examining methods that can use transcript-semantic parse data (unpaired text) without corresponding speech. First, when unpaired text is drawn from existing textual corpora, Joint Audio Text (JAT) and Text-to-Speech (TTS) are compared as ways to generate speech representations for unpaired text. Experiments on the STOP dataset show that unpaired text from existing and new domains improves performance by 2% and 30% in absolute Exact Match (EM) respectively. Second, we consider the setting when unpaired text is not available in existing textual corpora. We propose to prompt Large Language Models (LLMs) to generate unpaired text for existing and new domains. Experiments show that examples and words that co-occur with intents can be used to generate unpaired text with Llama 2.0. Using the generated text with JAT and TTS for spoken semantic parsing improves EM on STOP by 1.4% and 2.6% absolute for existing and new domains respectively.
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023



In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
Altruistic Autonomy: Beating Congestion on Shared Roads
Oct 29, 2018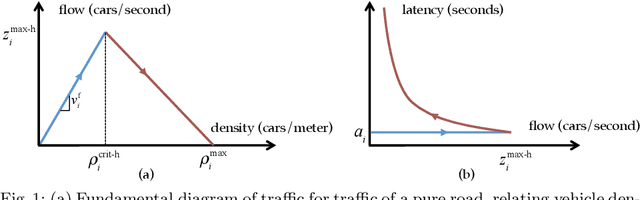
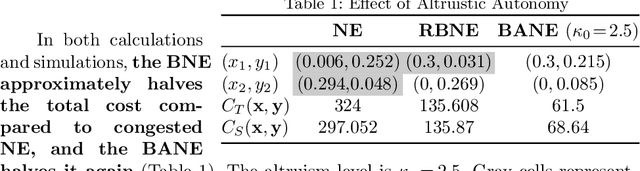
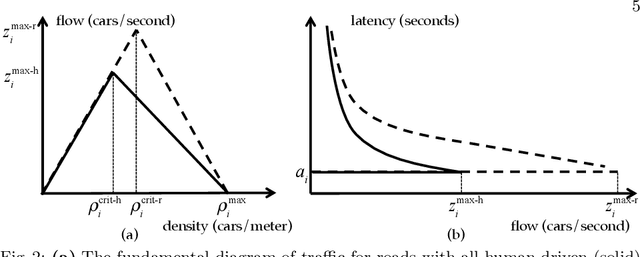
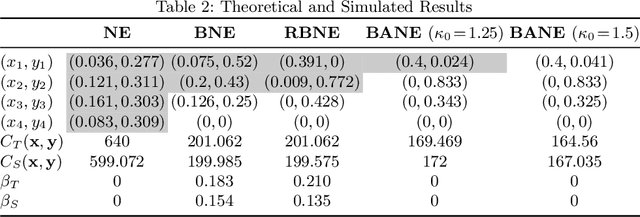
Traffic congestion has large economic and social costs. The introduction of autonomous vehicles can potentially reduce this congestion, both by increasing network throughput and by enabling a social planner to incentivize users of autonomous vehicles to take longer routes that can alleviate congestion on more direct roads. We formalize the effects of altruistic autonomy on roads shared between human drivers and autonomous vehicles. In this work, we develop a formal model of road congestion on shared roads based on the fundamental diagram of traffic. We consider a network of parallel roads and provide algorithms that compute optimal equilibria that are robust to additional unforeseen demand. We further plan for optimal routings when users have varying degrees of altruism. We find that even with arbitrarily small altruism, total latency can be unboundedly better than without altruism, and that the best selfish equilibrium can be unboundedly better than the worst selfish equilibrium. We validate our theoretical results through microscopic traffic simulations and show average latency decrease of a factor of 4 from worst-case selfish equilibrium to the optimal equilibrium when autonomous vehicles are altruistic.