 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the iterative refinement of densely connected representation levels for semantic segmentation
Apr 30, 2018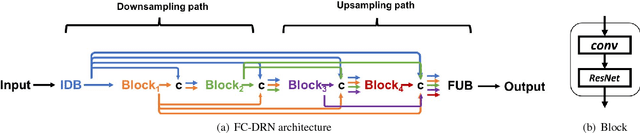


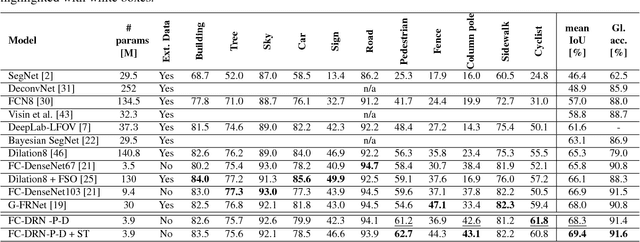
State-of-the-art semantic segmentation approaches increase the receptive field of their models by using either a downsampling path composed of poolings/strided convolutions or successive dilated convolutions. However, it is not clear which operation leads to best results. In this paper, we systematically study the differences introduced by distinct receptive field enlargement methods and their impact on the performance of a novel architecture, called Fully Convolutional DenseResNet (FC-DRN). FC-DRN has a densely connected backbone composed of residual networks. Following standard image segmentation architectures, receptive field enlargement operations that change the representation level are interleaved among residual networks. This allows the model to exploit the benefits of both residual and dense connectivity patterns, namely: gradient flow, iterative refinement of representations, multi-scale feature combination and deep supervision. In order to highlight the potential of our model, we test it on the challenging CamVid urban scene understanding benchmark and make the following observations: 1) downsampling operations outperform dilations when the model is trained from scratch, 2) dilations are useful during the finetuning step of the model, 3) coarser representations require less refinement steps, and 4) ResNets (by model construction) are good regularizers, since they can reduce the model capacity when needed. Finally, we compare our architecture to alternative methods and report state-of-the-art result on the Camvid dataset, with at least twice fewer parameters.
Graph Attention Networks
Feb 04, 2018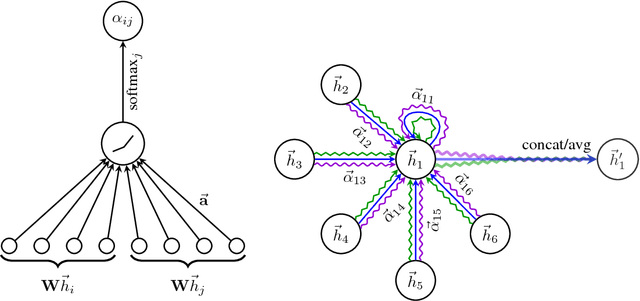
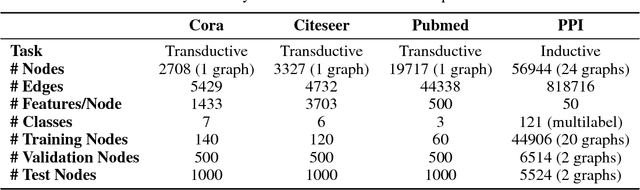

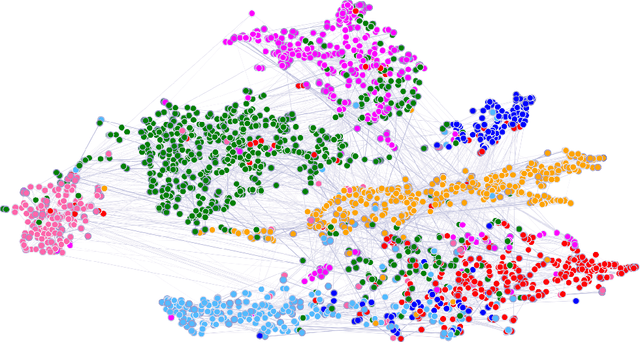
We present graph attention networks (GATs), novel neural network architectures that operate on graph-structured data, leveraging masked self-attentional layers to address the shortcomings of prior methods based on graph convolutions or their approximations. By stacking layers in which nodes are able to attend over their neighborhoods' features, we enable (implicitly) specifying different weights to different nodes in a neighborhood, without requiring any kind of costly matrix operation (such as inversion) or depending on knowing the graph structure upfront. In this way, we address several key challenges of spectral-based graph neural networks simultaneously, and make our model readily applicable to inductive as well as transductive problems. Our GAT models have achieved or matched state-of-the-art results across four established transductive and inductive graph benchmarks: the Cora, Citeseer and Pubmed citation network datasets, as well as a protein-protein interaction dataset (wherein test graphs remain unseen during training).
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
Oct 31, 2017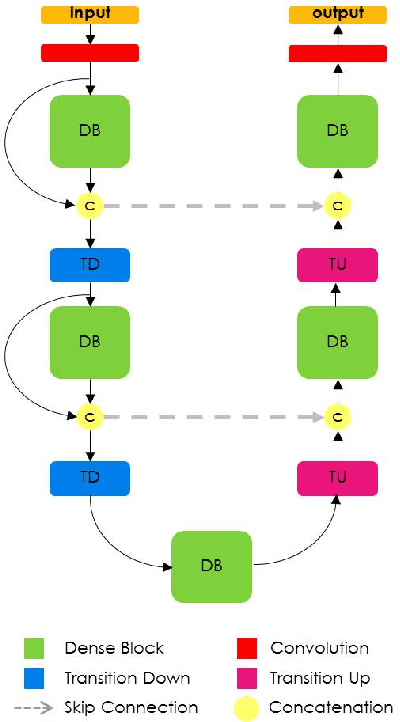

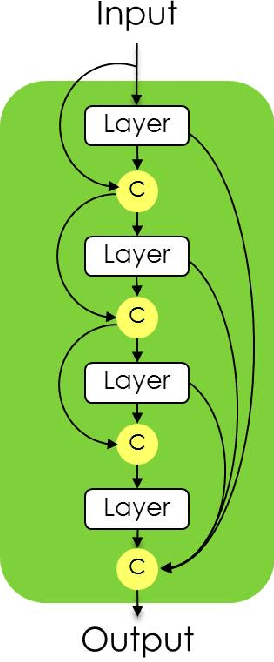

State-of-the-art approaches for semantic image segmentation are built on Convolutional Neural Networks (CNNs). The typical segmentation architecture is composed of (a) a downsampling path responsible for extracting coarse semantic features, followed by (b) an upsampling path trained to recover the input image resolution at the output of the model and, optionally, (c) a post-processing module (e.g. Conditional Random Fields) to refine the model predictions. Recently, a new CNN architecture, Densely Connected Convolutional Networks (DenseNets), has shown excellent results on image classification tasks. The idea of DenseNets is based on the observation that if each layer is directly connected to every other layer in a feed-forward fashion then the network will be more accurate and easier to train. In this paper, we extend DenseNets to deal with the problem of semantic segmentation. We achieve state-of-the-art results on urban scene benchmark datasets such as CamVid and Gatech, without any further post-processing module nor pretraining. Moreover, due to smart construction of the model, our approach has much less parameters than currently published best entries for these datasets. Code to reproduce the experiments is available here : https://github.com/SimJeg/FC-DenseNet/blob/master/train.py
Image Segmentation by Iterative Inference from Conditional Score Estimation
Aug 18, 2017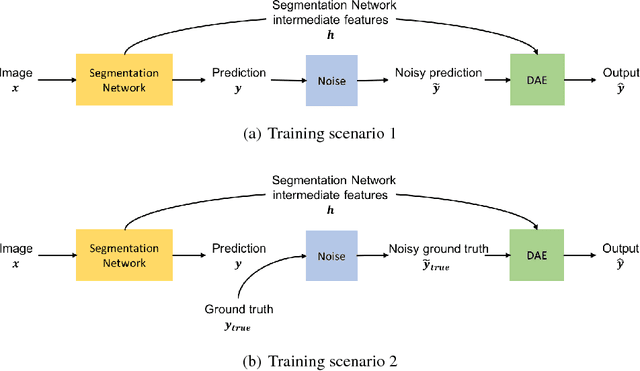
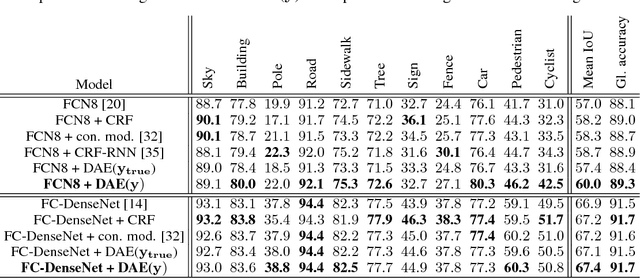
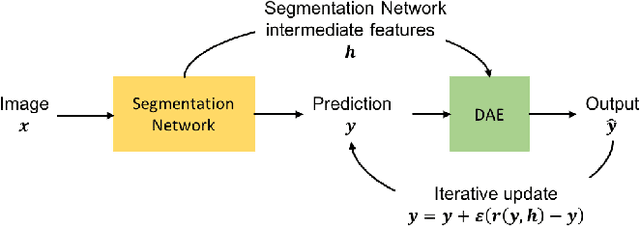

Inspired by the combination of feedforward and iterative computations in the virtual cortex, and taking advantage of the ability of denoising autoencoders to estimate the score of a joint distribution, we propose a novel approach to iterative inference for capturing and exploiting the complex joint distribution of output variables conditioned on some input variables. This approach is applied to image pixel-wise segmentation, with the estimated conditional score used to perform gradient ascent towards a mode of the estimated conditional distribution. This extends previous work on score estimation by denoising autoencoders to the case of a conditional distribution, with a novel use of a corrupted feedforward predictor replacing Gaussian corruption. An advantage of this approach over more classical ways to perform iterative inference for structured outputs, like conditional random fields (CRFs), is that it is not any more necessary to define an explicit energy function linking the output variables. To keep computations tractable, such energy function parametrizations are typically fairly constrained, involving only a few neighbors of each of the output variables in each clique. We experimentally find that the proposed iterative inference from conditional score estimation by conditional denoising autoencoders performs better than comparable models based on CRFs or those not using any explicit modeling of the conditional joint distribution of outputs.
Diet Networks: Thin Parameters for Fat Genomics
Mar 16, 2017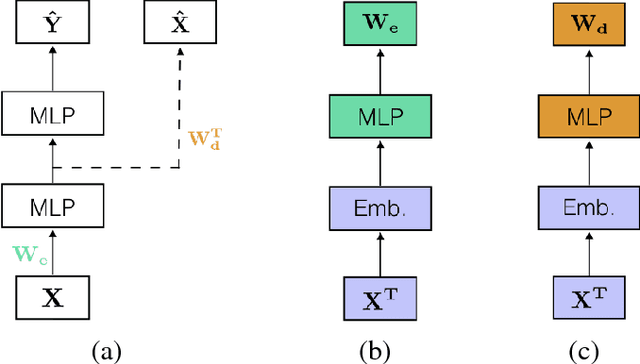
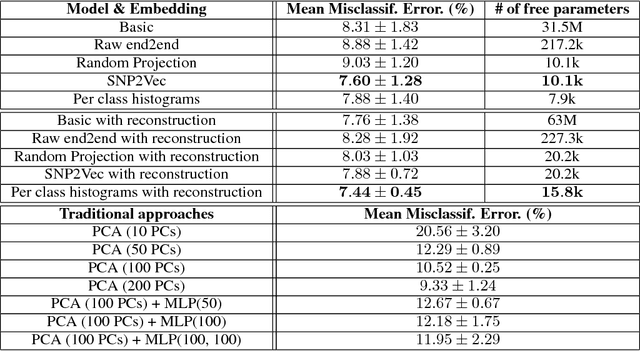
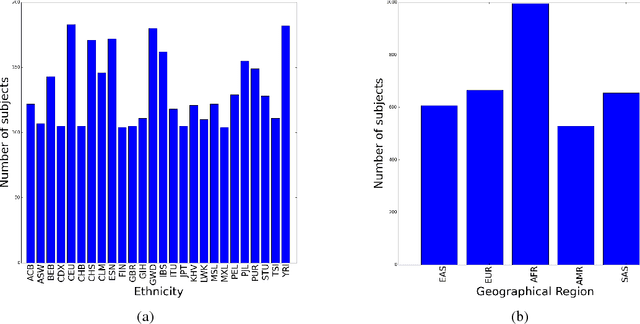
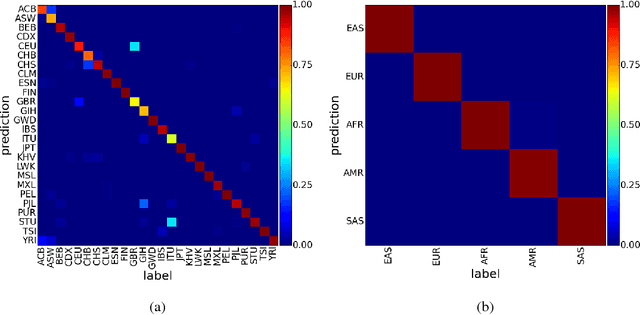
Learning tasks such as those involving genomic data often poses a serious challenge: the number of input features can be orders of magnitude larger than the number of training examples, making it difficult to avoid overfitting, even when using the known regularization techniques. We focus here on tasks in which the input is a description of the genetic variation specific to a patient, the single nucleotide polymorphisms (SNPs), yielding millions of ternary inputs. Improving the ability of deep learning to handle such datasets could have an important impact in precision medicine, where high-dimensional data regarding a particular patient is used to make predictions of interest. Even though the amount of data for such tasks is increasing, this mismatch between the number of examples and the number of inputs remains a concern. Naive implementations of classifier neural networks involve a huge number of free parameters in their first layer: each input feature is associated with as many parameters as there are hidden units. We propose a novel neural network parametrization which considerably reduces the number of free parameters. It is based on the idea that we can first learn or provide a distributed representation for each input feature (e.g. for each position in the genome where variations are observed), and then learn (with another neural network called the parameter prediction network) how to map a feature's distributed representation to the vector of parameters specific to that feature in the classifier neural network (the weights which link the value of the feature to each of the hidden units). We show experimentally on a population stratification task of interest to medical studies that the proposed approach can significantly reduce both the number of parameters and the error rate of the classifier.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
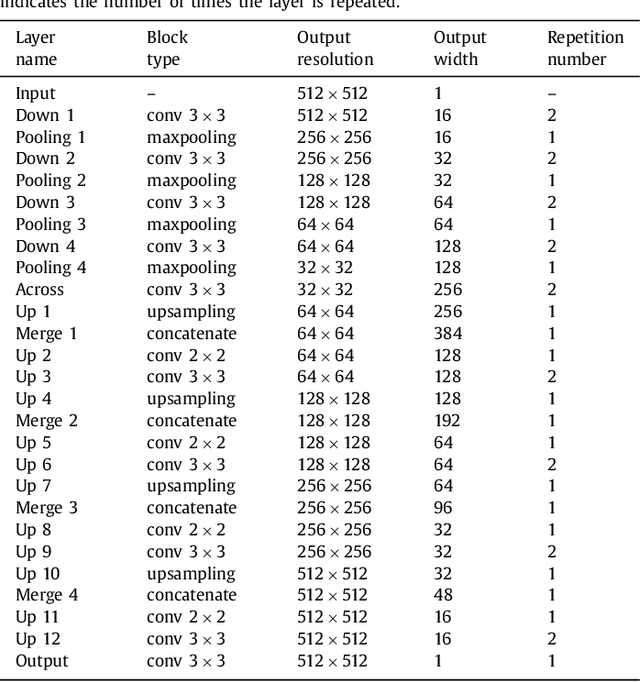
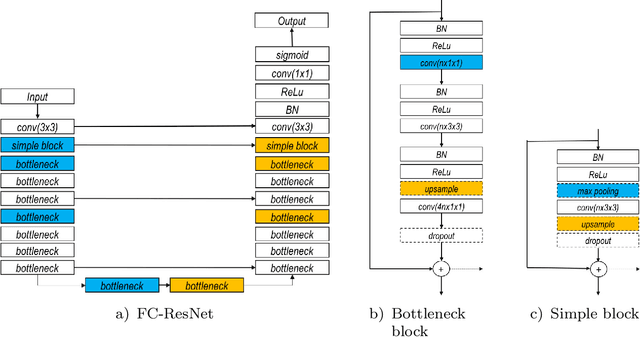
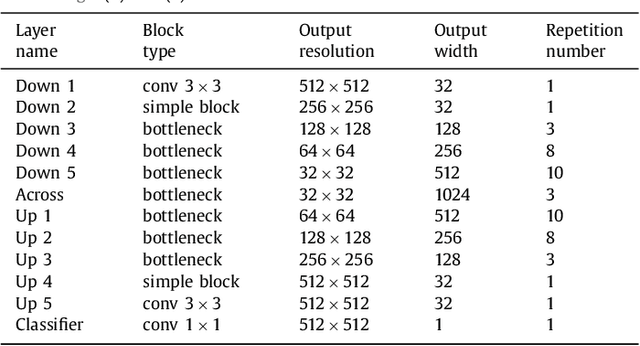
In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.
A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images
Dec 02, 2016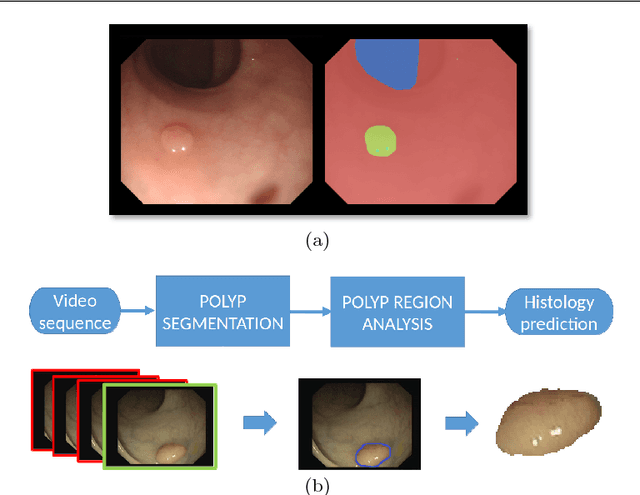
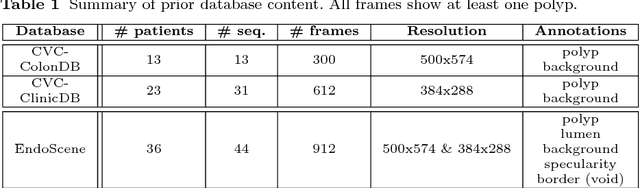

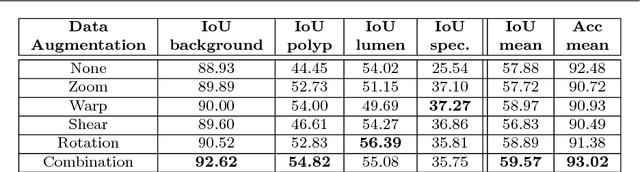
Colorectal cancer (CRC) is the third cause of cancer death worldwide. Currently, the standard approach to reduce CRC-related mortality is to perform regular screening in search for polyps and colonoscopy is the screening tool of choice. The main limitations of this screening procedure are polyp miss-rate and inability to perform visual assessment of polyp malignancy. These drawbacks can be reduced by designing Decision Support Systems (DSS) aiming to help clinicians in the different stages of the procedure by providing endoluminal scene segmentation. Thus, in this paper, we introduce an extended benchmark of colonoscopy image, with the hope of establishing a new strong benchmark for colonoscopy image analysis research. We provide new baselines on this dataset by training standard fully convolutional networks (FCN) for semantic segmentation and significantly outperforming, without any further post-processing, prior results in endoluminal scene segmentation.
ReSeg: A Recurrent Neural Network-based Model for Semantic Segmentation
May 24, 2016
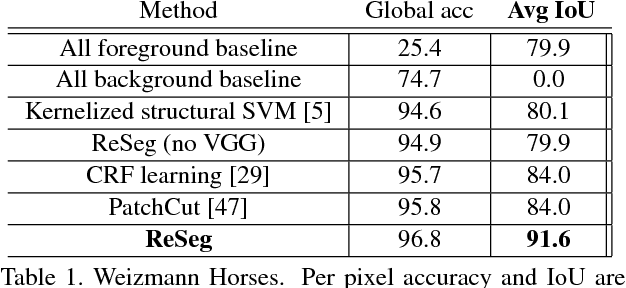

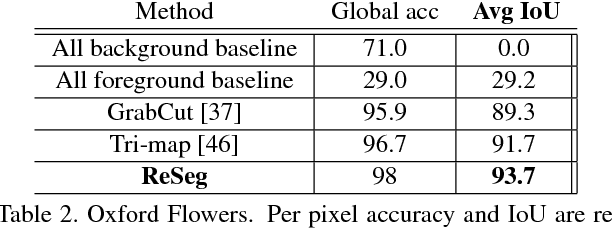
We propose a structured prediction architecture, which exploits the local generic features extracted by Convolutional Neural Networks and the capacity of Recurrent Neural Networks (RNN) to retrieve distant dependencies. The proposed architecture, called ReSeg, is based on the recently introduced ReNet model for image classification. We modify and extend it to perform the more challenging task of semantic segmentation. Each ReNet layer is composed of four RNN that sweep the image horizontally and vertically in both directions, encoding patches or activations, and providing relevant global information. Moreover, ReNet layers are stacked on top of pre-trained convolutional layers, benefiting from generic local features. Upsampling layers follow ReNet layers to recover the original image resolution in the final predictions. The proposed ReSeg architecture is efficient, flexible and suitable for a variety of semantic segmentation tasks. We evaluate ReSeg on several widely-used semantic segmentation datasets: Weizmann Horse, Oxford Flower, and CamVid; achieving state-of-the-art performance. Results show that ReSeg can act as a suitable architecture for semantic segmentation tasks, and may have further applications in other structured prediction problems. The source code and model hyperparameters are available on https://github.com/fvisin/reseg.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Unsupervised Deep Feature Extraction for Remote Sensing Image Classification
Nov 25, 2015
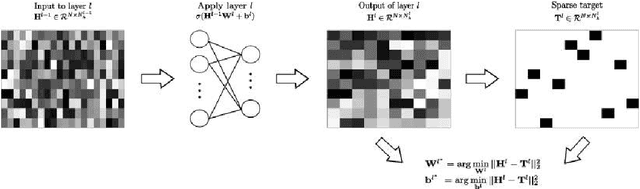

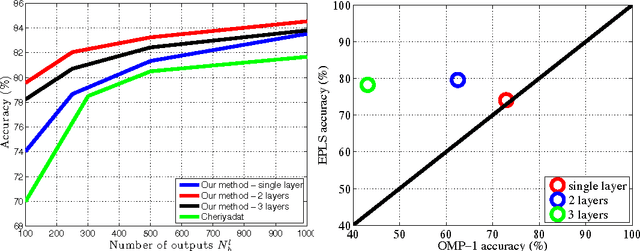
This paper introduces the use of single layer and deep convolutional networks for remote sensing data analysis. Direct application to multi- and hyper-spectral imagery of supervised (shallow or deep) convolutional networks is very challenging given the high input data dimensionality and the relatively small amount of available labeled data. Therefore, we propose the use of greedy layer-wise unsupervised pre-training coupled with a highly efficient algorithm for unsupervised learning of sparse features. The algorithm is rooted on sparse representations and enforces both population and lifetime sparsity of the extracted features, simultaneously. We successfully illustrate the expressive power of the extracted representations in several scenarios: classification of aerial scenes, as well as land-use classification in very high resolution (VHR), or land-cover classification from multi- and hyper-spectral images. The proposed algorithm clearly outperforms standard Principal Component Analysis (PCA) and its kernel counterpart (kPCA), as well as current state-of-the-art algorithms of aerial classification, while being extremely computationally efficient at learning representations of data. Results show that single layer convolutional networks can extract powerful discriminative features only when the receptive field accounts for neighboring pixels, and are preferred when the classification requires high resolution and detailed results. However, deep architectures significantly outperform single layers variants, capturing increasing levels of abstraction and complexity throughout the feature hierarchy.