 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Iris Centre Localisation for Assistive Eye-Gaze Tracking
Nov 07, 2024

In this research work, we address the problem of robust iris centre localisation in unconstrained conditions as a core component of our eye-gaze tracking platform. We investigate the application of U-Net variants for segmentation-based and regression-based approaches to improve our iris centre localisation, which was previously based on Bayes' classification. The achieved results are comparable to or better than the state-of-the-art, offering a drastic improvement over those achieved by the Bayes' classifier, and without sacrificing the real-time performance of our eye-gaze tracking platform.
The Best of Both Worlds: a Framework for Combining Degradation Prediction with High Performance Super-Resolution Networks
Nov 09, 2022



To date, the best-performing blind super-resolution (SR) techniques follow one of two paradigms: A) generate and train a standard SR network on synthetic low-resolution - high-resolution (LR - HR) pairs or B) attempt to predict the degradations an LR image has suffered and use these to inform a customised SR network. Despite significant progress, subscribers to the former miss out on useful degradation information that could be used to improve the SR process. On the other hand, followers of the latter rely on weaker SR networks, which are significantly outperformed by the latest architectural advancements. In this work, we present a framework for combining any blind SR prediction mechanism with any deep SR network, using a metadata insertion block to insert prediction vectors into SR network feature maps. Through comprehensive testing, we prove that state-of-the-art contrastive and iterative prediction schemes can be successfully combined with high-performance SR networks such as RCAN and HAN within our framework. We show that our hybrid models consistently achieve stronger SR performance than both their non-blind and blind counterparts. Furthermore, we demonstrate our framework's robustness by predicting degradations and super-resolving images from a complex pipeline of blurring, noise and compression.
Improving Super-Resolution Performance using Meta-Attention Layers
Oct 27, 2021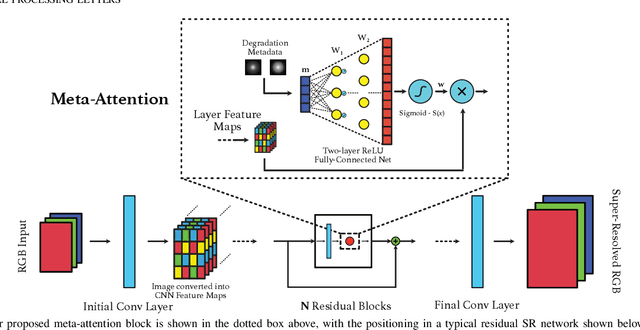
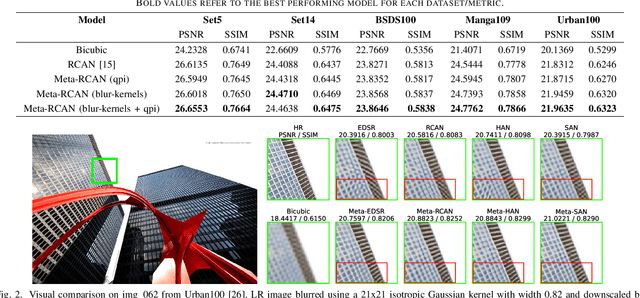
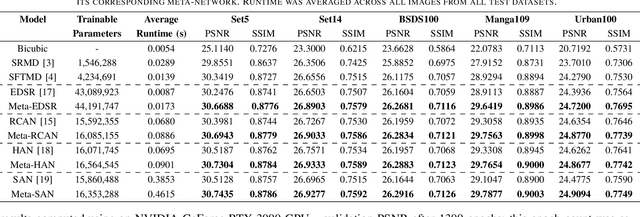
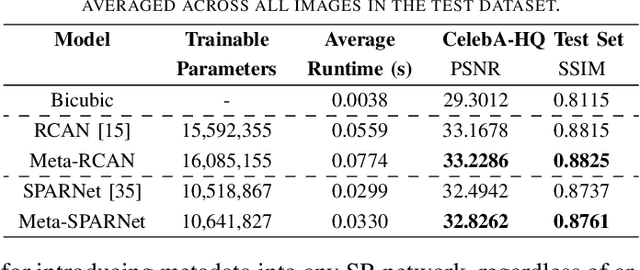
Convolutional Neural Networks (CNNs) have achieved impressive results across many super-resolution (SR) and image restoration tasks. While many such networks can upscale low-resolution (LR) images using just the raw pixel-level information, the ill-posed nature of SR can make it difficult to accurately super-resolve an image which has undergone multiple different degradations. Additional information (metadata) describing the degradation process (such as the blur kernel applied, compression level, etc.) can guide networks to super-resolve LR images with higher fidelity to the original source. Previous attempts at informing SR networks with degradation parameters have indeed been able to improve performance in a number of scenarios. However, due to the fully-convolutional nature of many SR networks, most of these metadata fusion methods either require a complete architectural change, or necessitate the addition of significant extra complexity. Thus, these approaches are difficult to introduce into arbitrary SR networks without considerable design alterations. In this paper, we introduce meta-attention, a simple mechanism which allows any SR CNN to exploit the information available in relevant degradation parameters. The mechanism functions by translating the metadata into a channel attention vector, which in turn selectively modulates the network's feature maps. Incorporating meta-attention into SR networks is straightforward, as it requires no specific type of architecture to function correctly. Extensive testing has shown that meta-attention can consistently improve the pixel-level accuracy of state-of-the-art (SOTA) networks when provided with relevant degradation metadata. For PSNR, the gain on blurred/downsampled (X4) images is of 0.2969 dB (on average) and 0.3320 dB for SOTA general and face SR models, respectively.
On Architectures for Including Visual Information in Neural Language Models for Image Description
Nov 09, 2019

A neural language model can be conditioned into generating descriptions for images by providing visual information apart from the sentence prefix. This visual information can be included into the language model through different points of entry resulting in different neural architectures. We identify four main architectures which we call init-inject, pre-inject, par-inject, and merge. We analyse these four architectures and conclude that the best performing one is init-inject, which is when the visual information is injected into the initial state of the recurrent neural network. We confirm this using both automatic evaluation measures and human annotation. We then analyse how much influence the images have on each architecture. This is done by measuring how different the output probabilities of a model are when a partial sentence is combined with a completely different image from the one it is meant to be combined with. We find that init-inject tends to quickly become less influenced by the image as more words are generated. A different architecture called merge, which is when the visual information is merged with the recurrent neural network's hidden state vector prior to output, loses visual influence much more slowly, suggesting that it would work better for generating longer sentences. We also observe that the merge architecture can have its recurrent neural network pre-trained in a text-only language model (transfer learning) rather than be initialised randomly as usual. This results in even better performance than the other architectures, provided that the source language model is not too good at language modelling or it will overspecialise and be less effective at image description generation. Our work opens up new avenues of research in neural architectures, explainable AI, and transfer learning.
Transfer learning from language models to image caption generators: Better models may not transfer better
Jan 01, 2019

When designing a neural caption generator, a convolutional neural network can be used to extract image features. Is it possible to also use a neural language model to extract sentence prefix features? We answer this question by trying different ways to transfer the recurrent neural network and embedding layer from a neural language model to an image caption generator. We find that image caption generators with transferred parameters perform better than those trained from scratch, even when simply pre-training them on the text of the same captions dataset it will later be trained on. We also find that the best language models (in terms of perplexity) do not result in the best caption generators after transfer learning.
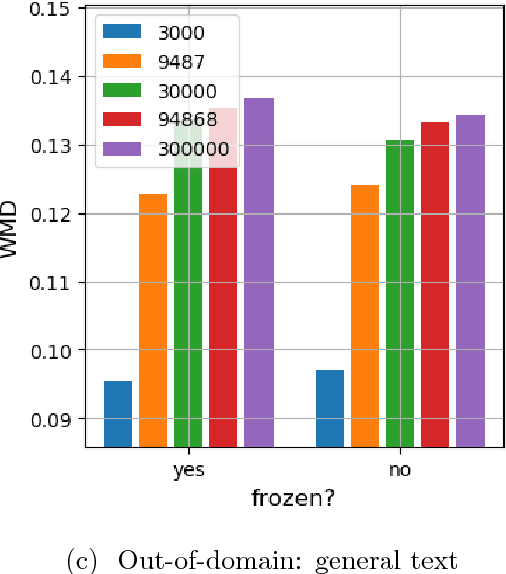
Quantifying the amount of visual information used by neural caption generators
Oct 12, 2018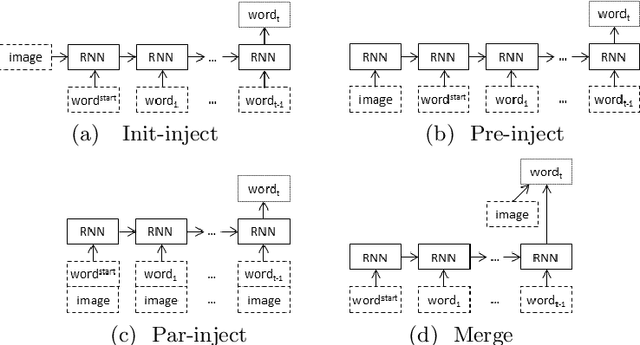
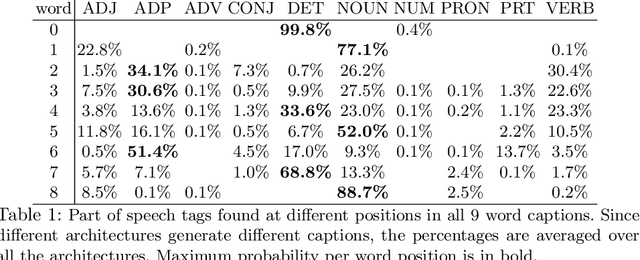
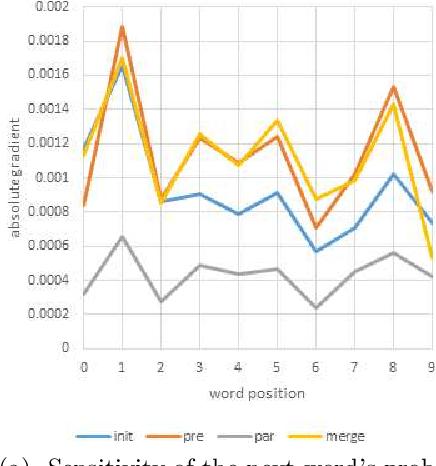
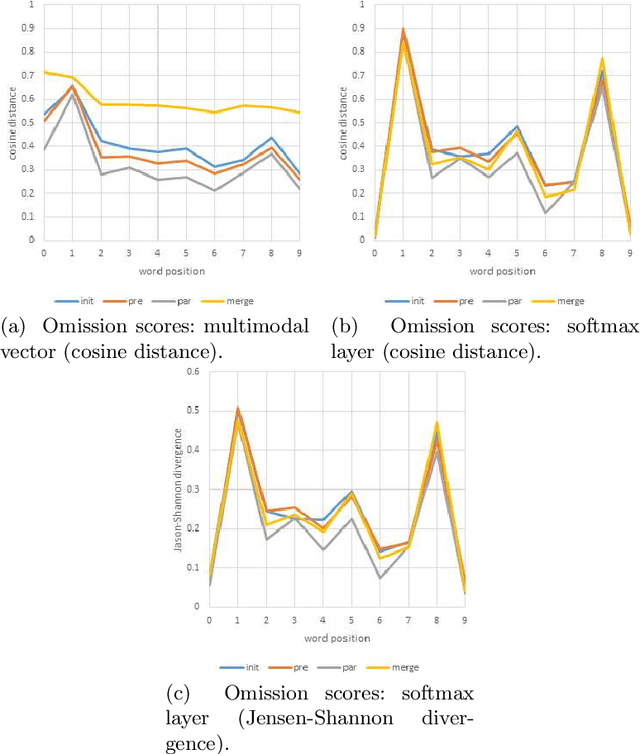
This paper addresses the sensitivity of neural image caption generators to their visual input. A sensitivity analysis and omission analysis based on image foils is reported, showing that the extent to which image captioning architectures retain and are sensitive to visual information varies depending on the type of word being generated and the position in the caption as a whole. We motivate this work in the context of broader goals in the field to achieve more explainability in AI.
Where to put the Image in an Image Caption Generator
Mar 14, 2018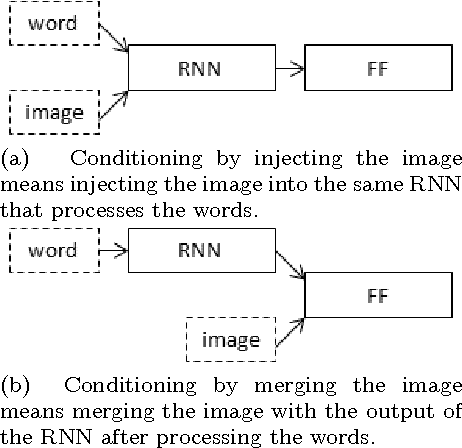
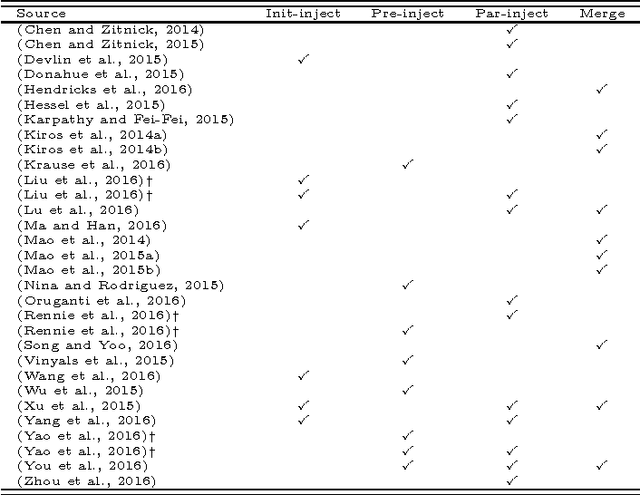
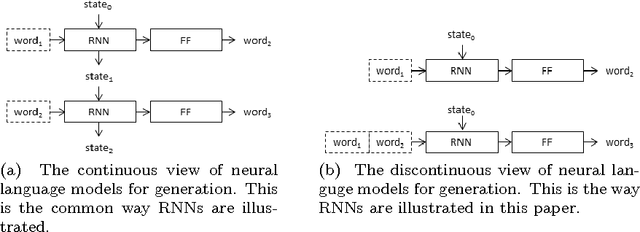

When a recurrent neural network language model is used for caption generation, the image information can be fed to the neural network either by directly incorporating it in the RNN -- conditioning the language model by `injecting' image features -- or in a layer following the RNN -- conditioning the language model by `merging' image features. While both options are attested in the literature, there is as yet no systematic comparison between the two. In this paper we empirically show that it is not especially detrimental to performance whether one architecture is used or another. The merge architecture does have practical advantages, as conditioning by merging allows the RNN's hidden state vector to shrink in size by up to four times. Our results suggest that the visual and linguistic modalities for caption generation need not be jointly encoded by the RNN as that yields large, memory-intensive models with few tangible advantages in performance; rather, the multimodal integration should be delayed to a subsequent stage.
Face2Text: Collecting an Annotated Image Description Corpus for the Generation of Rich Face Descriptions
Mar 10, 2018
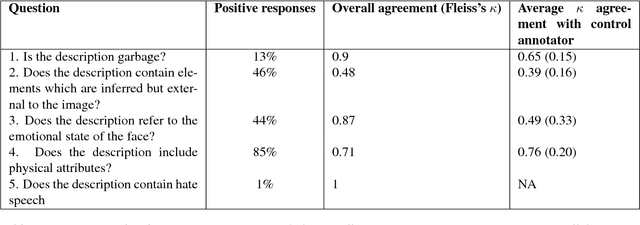
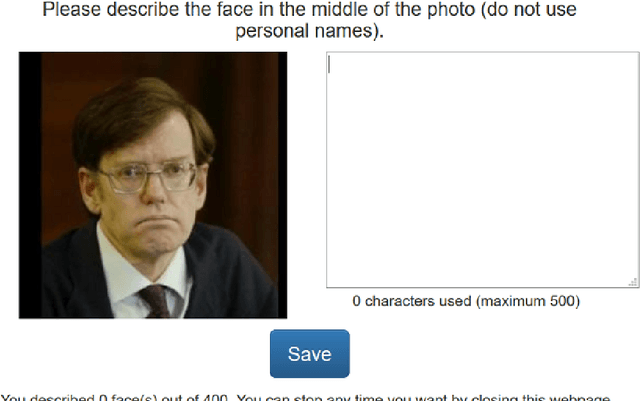
The past few years have witnessed renewed interest in NLP tasks at the interface between vision and language. One intensively-studied problem is that of automatically generating text from images. In this paper, we extend this problem to the more specific domain of face description. Unlike scene descriptions, face descriptions are more fine-grained and rely on attributes extracted from the image, rather than objects and relations. Given that no data exists for this task, we present an ongoing crowdsourcing study to collect a corpus of descriptions of face images taken `in the wild'. To gain a better understanding of the variation we find in face description and the possible issues that this may raise, we also conducted an annotation study on a subset of the corpus. Primarily, we found descriptions to refer to a mixture of attributes, not only physical, but also emotional and inferential, which is bound to create further challenges for current image-to-text methods.
What is the Role of Recurrent Neural Networks in an Image Caption Generator?
Aug 25, 2017
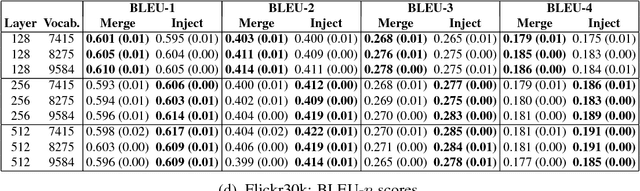
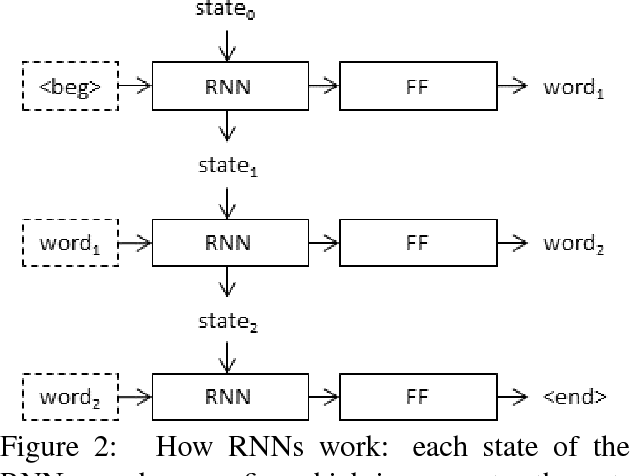
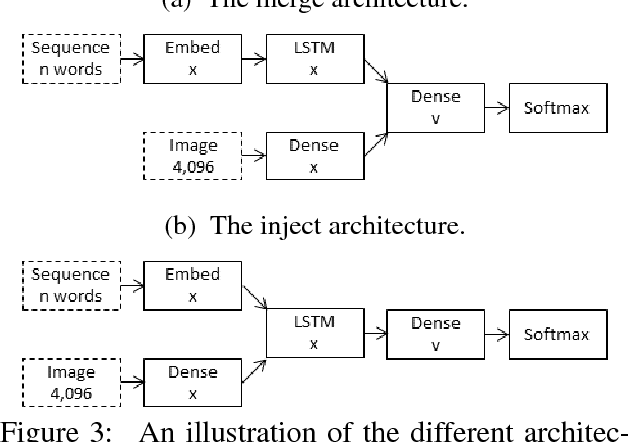
In neural image captioning systems, a recurrent neural network (RNN) is typically viewed as the primary `generation' component. This view suggests that the image features should be `injected' into the RNN. This is in fact the dominant view in the literature. Alternatively, the RNN can instead be viewed as only encoding the previously generated words. This view suggests that the RNN should only be used to encode linguistic features and that only the final representation should be `merged' with the image features at a later stage. This paper compares these two architectures. We find that, in general, late merging outperforms injection, suggesting that RNNs are better viewed as encoders, rather than generators.
The Cyborg Astrobiologist: Porting from a wearable computer to the Astrobiology Phone-cam
Jul 05, 2007
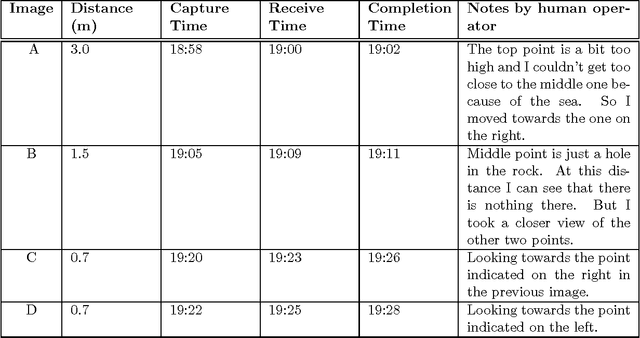
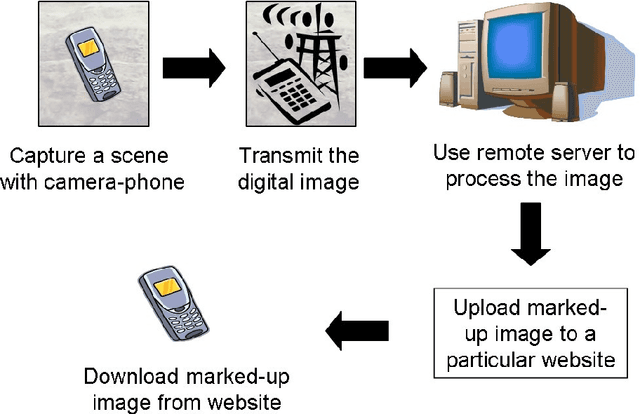

We have used a simple camera phone to significantly improve an `exploration system' for astrobiology and geology. This camera phone will make it much easier to develop and test computer-vision algorithms for future planetary exploration. We envision that the `Astrobiology Phone-cam' exploration system can be fruitfully used in other problem domains as well.
* 15 pages, 4 figures, accepted for publication in the International Journal of Astrobiology