 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALSIFYBENCH: Evaluating Inductive Reasoning in LLMs with Rule Discovery Games
Jun 03, 2026Large language models (LLMs) are increasingly deployed as autonomous agents in scientific tasks. Yet whether these systems can effectively engage in forms of inductive reasoning relevant to scientific discovery remains an open question. In this work, we introduce FALSIFYBENCH, an evaluation framework for hypothesis-driven reasoning inspired by the classic Wason 2-4-6 task, in which agents must discover hidden semantic properties by iteratively proposing examples and receiving feedback. This task captures key elements of scientific reasoning: hypothesis generation, evidence gathering, and belief revision in response to both confirming and disconfirming evidence. Our evaluation of 12 LLMs across model families and scales shows that reasoning models are generally stronger scientific reasoners than instruction-tuned models, although no model comes close to optimal performance. The primary driver of success is the capacity for negative testing: models that actively seek to falsify their hypotheses consistently outperform those that primarily seek confirmation. Moreover, a fine-grained turn-level analysis, neglected in previous work, reveals that failure is tied to identifiable patterns in how models navigate the hypothesis space.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
A MIND for Reasoning: Meta-learning for In-context Deduction
May 20, 2025
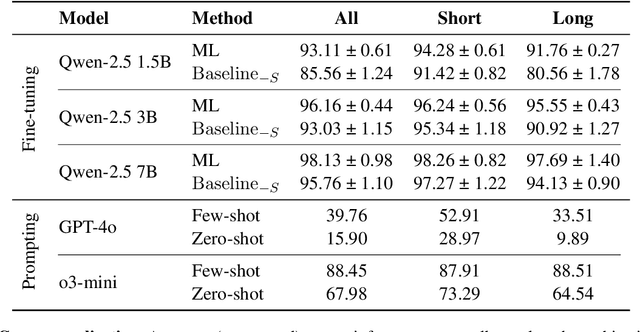
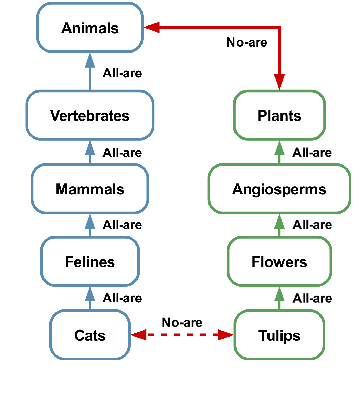

Large language models (LLMs) are increasingly evaluated on formal tasks, where strong reasoning abilities define the state of the art. However, their ability to generalize to out-of-distribution problems remains limited. In this paper, we investigate how LLMs can achieve a systematic understanding of deductive rules. Our focus is on the task of identifying the appropriate subset of premises within a knowledge base needed to derive a given hypothesis. To tackle this challenge, we propose Meta-learning for In-context Deduction (MIND), a novel few-shot meta-learning fine-tuning approach. The goal of MIND is to enable models to generalize more effectively to unseen knowledge bases and to systematically apply inference rules. Our results show that MIND significantly improves generalization in small LMs ranging from 1.5B to 7B parameters. The benefits are especially pronounced in smaller models and low-data settings. Remarkably, small models fine-tuned with MIND outperform state-of-the-art LLMs, such as GPT-4o and o3-mini, on this task.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025



Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
All-in-one: Understanding and Generation in Multimodal Reasoning with the MAIA Benchmark
Feb 24, 2025We introduce MAIA (Multimodal AI Assessment), a native-Italian benchmark designed for fine-grained investigation of the reasoning abilities of visual language models on videos. MAIA differs from other available video benchmarks for its design, its reasoning categories, the metric it uses and the language and culture of the videos. It evaluates Vision Language Models (VLMs) on two aligned tasks: a visual statement verification task, and an open-ended visual question-answering task, both on the same set of video-related questions. It considers twelve reasoning categories that aim to disentangle language and vision relations by highlight when one of two alone encodes sufficient information to solve the tasks, when they are both needed and when the full richness of the short video is essential instead of just a part of it. Thanks to its carefully taught design, it evaluates VLMs' consistency and visually grounded natural language comprehension and generation simultaneously through an aggregated metric. Last but not least, the video collection has been carefully selected to reflect the Italian culture and the language data are produced by native-speakers.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
Feb 20, 2025



We examine three evaluation paradigms: large question-answering benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.
The Validation Gap: A Mechanistic Analysis of How Language Models Compute Arithmetic but Fail to Validate It
Feb 17, 2025The ability of large language models (LLMs) to validate their output and identify potential errors is crucial for ensuring robustness and reliability. However, current research indicates that LLMs struggle with self-correction, encountering significant challenges in detecting errors. While studies have explored methods to enhance self-correction in LLMs, relatively little attention has been given to understanding the models' internal mechanisms underlying error detection. In this paper, we present a mechanistic analysis of error detection in LLMs, focusing on simple arithmetic problems. Through circuit analysis, we identify the computational subgraphs responsible for detecting arithmetic errors across four smaller-sized LLMs. Our findings reveal that all models heavily rely on $\textit{consistency heads}$--attention heads that assess surface-level alignment of numerical values in arithmetic solutions. Moreover, we observe that the models' internal arithmetic computation primarily occurs in higher layers, whereas validation takes place in middle layers, before the final arithmetic results are fully encoded. This structural dissociation between arithmetic computation and validation seems to explain why current LLMs struggle to detect even simple arithmetic errors.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024



There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
Learning to Ask Informative Questions: Enhancing LLMs with Preference Optimization and Expected Information Gain
Jun 25, 2024



Questions are essential tools for acquiring the necessary information to complete information-seeking tasks. However, large language models (LLMs), especially open-source models, often perform poorly in generating informative questions, as measured by expected information gain (EIG). In this paper, we propose a method to enhance the informativeness of LLM-generated questions in 20-question game dialogues. We sample multiple questions from the same model (LLAMA 2-CHAT 7B) for each game and create pairs of low-EIG and high-EIG questions to apply a Direct Preference Optimization (DPO) algorithm. Our results show that this method produces more effective questions (in terms of EIG), even in domains different from those used to train the DPO model.
A Systematic Analysis of Large Language Models as Soft Reasoners: The Case of Syllogistic Inferences
Jun 17, 2024
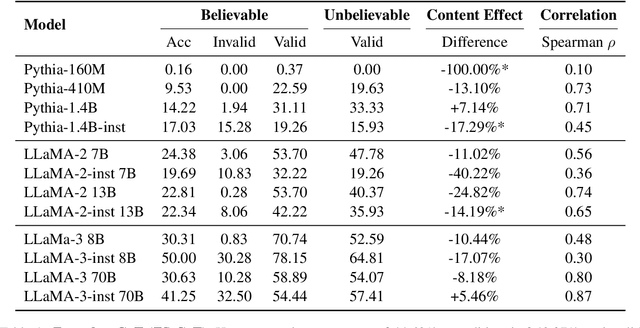


The reasoning abilities of Large Language Models (LLMs) are becoming a central focus of study in NLP. In this paper, we consider the case of syllogistic reasoning, an area of deductive reasoning studied extensively in logic and cognitive psychology. Previous research has shown that pre-trained LLMs exhibit reasoning biases, such as $\textit{content effects}$, avoid answering that $\textit{no conclusion follows}$, display human-like difficulties, and struggle with multi-step reasoning. We contribute to this research line by systematically investigating the effects of chain-of-thought reasoning, in-context learning (ICL), and supervised fine-tuning (SFT) on syllogistic reasoning, considering syllogisms with conclusions that support or violate world knowledge, as well as ones with multiple premises. Crucially, we go beyond the standard focus on accuracy, with an in-depth analysis of the conclusions generated by the models. Our results suggest that the behavior of pre-trained LLMs can be explained by heuristics studied in cognitive science and that both ICL and SFT improve model performance on valid inferences, although only the latter mitigates most reasoning biases without harming model consistency.