 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Deterministic Framework for Named Entity Extraction in Broadcast News Video
Feb 09, 2026The growing volume of video-based news content has heightened the need for transparent and reliable methods to extract on-screen information. Yet the variability of graphical layouts, typographic conventions, and platform-specific design patterns renders manual indexing impractical. This work presents a comprehensive framework for automatically detecting and extracting personal names from broadcast and social-media-native news videos. It introduces a curated and balanced corpus of annotated frames capturing the diversity of contemporary news graphics and proposes an interpretable, modular extraction pipeline designed to operate under deterministic and auditable conditions. The pipeline is evaluated against a contrasting class of generative multimodal methods, revealing a clear trade-off between deterministic auditability and stochastic inference. The underlying detector achieves 95.8% mAP@0.5, demonstrating operationally robust performance for graphical element localisation. While generative systems achieve marginally higher raw accuracy (F1: 84.18% vs 77.08%), they lack the transparent data lineage required for journalistic and analytical contexts. The proposed pipeline delivers balanced precision (79.9%) and recall (74.4%), avoids hallucination, and provides full traceability across each processing stage. Complementary user findings indicate that 59% of respondents report difficulty reading on-screen names in fast-paced broadcasts, underscoring the practical relevance of the task. The results establish a methodologically rigorous and interpretable baseline for hybrid multimodal information extraction in modern news media.
Enhancing Object Detection with Privileged Information: A Model-Agnostic Teacher-Student Approach
Jan 05, 2026This paper investigates the integration of the Learning Using Privileged Information (LUPI) paradigm in object detection to exploit fine-grained, descriptive information available during training but not at inference. We introduce a general, model-agnostic methodology for injecting privileged information-such as bounding box masks, saliency maps, and depth cues-into deep learning-based object detectors through a teacher-student architecture. Experiments are conducted across five state-of-the-art object detection models and multiple public benchmarks, including UAV-based litter detection datasets and Pascal VOC 2012, to assess the impact on accuracy, generalization, and computational efficiency. Our results demonstrate that LUPI-trained students consistently outperform their baseline counterparts, achieving significant boosts in detection accuracy with no increase in inference complexity or model size. Performance improvements are especially marked for medium and large objects, while ablation studies reveal that intermediate weighting of teacher guidance optimally balances learning from privileged and standard inputs. The findings affirm that the LUPI framework provides an effective and practical strategy for advancing object detection systems in both resource-constrained and real-world settings.
Comparative Analysis of Image, Video, and Audio Classifiers for Automated News Video Segmentation
Mar 27, 2025News videos require efficient content organisation and retrieval systems, but their unstructured nature poses significant challenges for automated processing. This paper presents a comprehensive comparative analysis of image, video, and audio classifiers for automated news video segmentation. This work presents the development and evaluation of multiple deep learning approaches, including ResNet, ViViT, AST, and multimodal architectures, to classify five distinct segment types: advertisements, stories, studio scenes, transitions, and visualisations. Using a custom-annotated dataset of 41 news videos comprising 1,832 scene clips, our experiments demonstrate that image-based classifiers achieve superior performance (84.34\% accuracy) compared to more complex temporal models. Notably, the ResNet architecture outperformed state-of-the-art video classifiers while requiring significantly fewer computational resources. Binary classification models achieved high accuracy for transitions (94.23\%) and advertisements (92.74\%). These findings advance the understanding of effective architectures for news video segmentation and provide practical insights for implementing automated content organisation systems in media applications. These include media archiving, personalised content delivery, and intelligent video search.
A Deep Learning Framework for Visual Attention Prediction and Analysis of News Interfaces
Mar 21, 2025



News outlets' competition for attention in news interfaces has highlighted the need for demographically-aware saliency prediction models. Despite recent advancements in saliency detection applied to user interfaces (UI), existing datasets are limited in size and demographic representation. We present a deep learning framework that enhances the SaRa (Saliency Ranking) model with DeepGaze IIE, improving Salient Object Ranking (SOR) performance by 10.7%. Our framework optimizes three key components: saliency map generation, grid segment scoring, and map normalization. Through a two-fold experiment using eye-tracking (30 participants) and mouse-tracking (375 participants aged 13--70), we analyze attention patterns across demographic groups. Statistical analysis reveals significant age-based variations (p < 0.05, {\epsilon^2} = 0.042), with older users (36--70) engaging more with textual content and younger users (13--35) interacting more with images. Mouse-tracking data closely approximates eye-tracking behavior (sAUC = 0.86) and identifies UI elements that immediately stand out, validating its use in large-scale studies. We conclude that saliency studies should prioritize gathering data from a larger, demographically representative sample and report exact demographic distributions.
Towards New Benchmark for AI Alignment & Sentiment Analysis in Socially Important Issues: A Comparative Study of Human and LLMs in the Context of AGI
Jan 05, 2025



With the expansion of neural networks, such as large language models, humanity is exponentially heading towards superintelligence. As various AI systems are increasingly integrated into the fabric of societies-through recommending values, devising creative solutions, and making decisions-it becomes critical to assess how these AI systems impact humans in the long run. This research aims to contribute towards establishing a benchmark for evaluating the sentiment of various Large Language Models in socially importan issues. The methodology adopted was a Likert scale survey. Seven LLMs, including GPT-4 and Bard, were analyzed and compared against sentiment data from three independent human sample populations. Temporal variations in sentiment were also evaluated over three consecutive days. The results highlighted a diversity in sentiment scores among LLMs, ranging from 3.32 to 4.12 out of 5. GPT-4 recorded the most positive sentiment score towards AGI, whereas Bard was leaning towards the neutral sentiment. The human samples, contrastingly, showed a lower average sentiment of 2.97. The temporal comparison revealed differences in sentiment evolution between LLMs in three days, ranging from 1.03% to 8.21%. The study's analysis outlines the prospect of potential conflicts of interest and bias possibilities in LLMs' sentiment formation. Results indicate that LLMs, akin to human cognitive processes, could potentially develop unique sentiments and subtly influence societies' perceptions towards various opinions formed within the LLMs.
Correlation of Object Detection Performance with Visual Saliency and Depth Estimation
Nov 05, 2024As object detection techniques continue to evolve, understanding their relationships with complementary visual tasks becomes crucial for optimising model architectures and computational resources. This paper investigates the correlations between object detection accuracy and two fundamental visual tasks: depth prediction and visual saliency prediction. Through comprehensive experiments using state-of-the-art models (DeepGaze IIE, Depth Anything, DPT-Large, and Itti's model) on COCO and Pascal VOC datasets, we find that visual saliency shows consistently stronger correlations with object detection accuracy (mA$\rho$ up to 0.459 on Pascal VOC) compared to depth prediction (mA$\rho$ up to 0.283). Our analysis reveals significant variations in these correlations across object categories, with larger objects showing correlation values up to three times higher than smaller objects. These findings suggest incorporating visual saliency features into object detection architectures could be more beneficial than depth information, particularly for specific object categories. The observed category-specific variations also provide insights for targeted feature engineering and dataset design improvements, potentially leading to more efficient and accurate object detection systems.
Integrating Saliency Ranking and Reinforcement Learning for Enhanced Object Detection
Aug 13, 2024



With the ever-growing variety of object detection approaches, this study explores a series of experiments that combine reinforcement learning (RL)-based visual attention methods with saliency ranking techniques to investigate transparent and sustainable solutions. By integrating saliency ranking for initial bounding box prediction and subsequently applying RL techniques to refine these predictions through a finite set of actions over multiple time steps, this study aims to enhance RL object detection accuracy. Presented as a series of experiments, this research investigates the use of various image feature extraction methods and explores diverse Deep Q-Network (DQN) architectural variations for deep reinforcement learning-based localisation agent training. Additionally, we focus on optimising the detection pipeline at every step by prioritising lightweight and faster models, while also incorporating the capability to classify detected objects, a feature absent in previous RL approaches. We show that by evaluating the performance of these trained agents using the Pascal VOC 2007 dataset, faster and more optimised models were developed. Notably, the best mean Average Precision (mAP) achieved in this study was 51.4, surpassing benchmarks set by RL-based single object detectors in the literature.
An XAI Approach to Deep Learning Models in the Detection of Ductal Carcinoma in Situ
Jun 27, 2021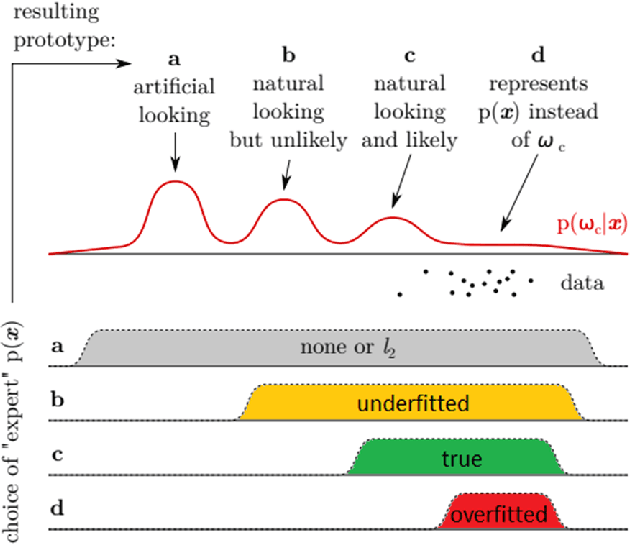
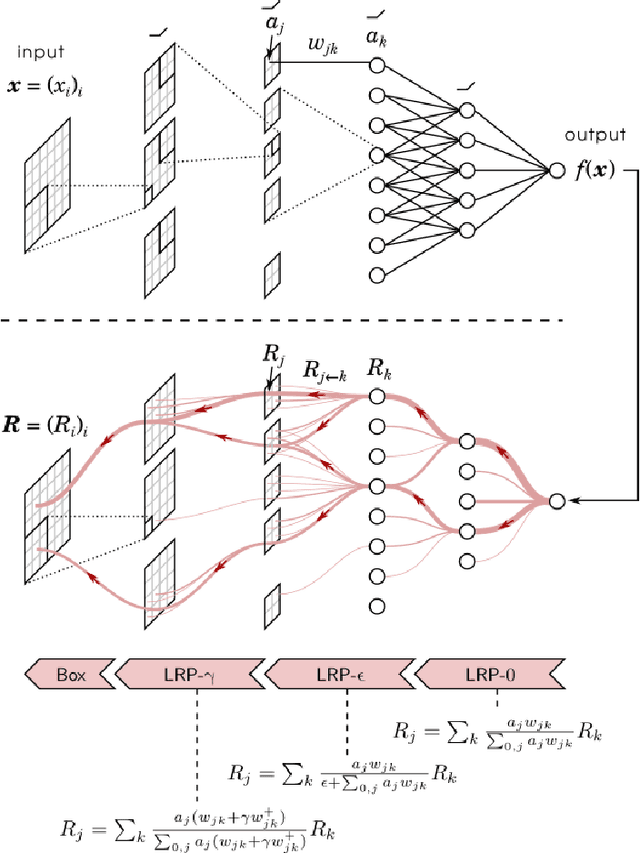
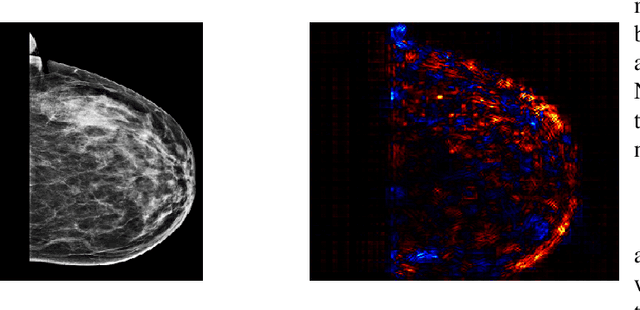
During the last decade or so, there has been an insurgence in the deep learning community to solve health-related issues, particularly breast cancer. Following the Camelyon-16 challenge in 2016, several researchers have dedicated their time to build Convolutional Neural Networks (CNNs) to help radiologists and other clinicians diagnose breast cancer. In particular, there has been an emphasis on Ductal Carcinoma in Situ (DCIS); the clinical term for early-stage breast cancer. Large companies have given their fair share of research into this subject, among these Google Deepmind who developed a model in 2020 that has proven to be better than radiologists themselves to diagnose breast cancer correctly. We found that among the issues which exist, there is a need for an explanatory system that goes through the hidden layers of a CNN to highlight those pixels that contributed to the classification of a mammogram. We then chose an open-source, reasonably successful project developed by Prof. Shen, using the CBIS-DDSM image database to run our experiments on. It was later improved using the Resnet-50 and VGG-16 patch-classifiers, analytically comparing the outcome of both. The results showed that the Resnet-50 one converged earlier in the experiments. Following the research by Montavon and Binder, we used the DeepTaylor Layer-wise Relevance Propagation (LRP) model to highlight those pixels and regions within a mammogram which contribute most to its classification. This is represented as a map of those pixels in the original image, which contribute to the diagnosis and the extent to which they contribute to the final classification. The most significant advantage of this algorithm is that it performs exceptionally well with the Resnet-50 patch classifier architecture.
Predicting Relative Depth between Objects from Semantic Features
Jan 12, 2021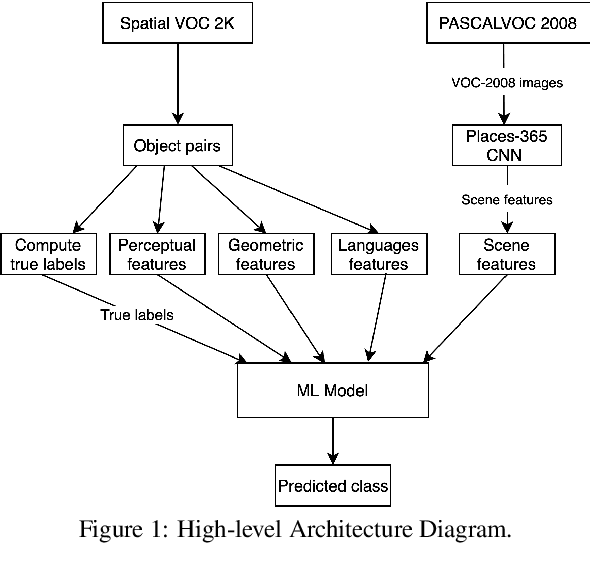

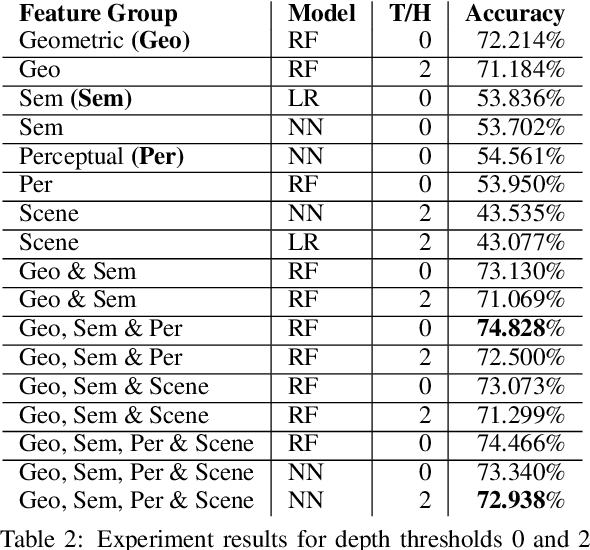
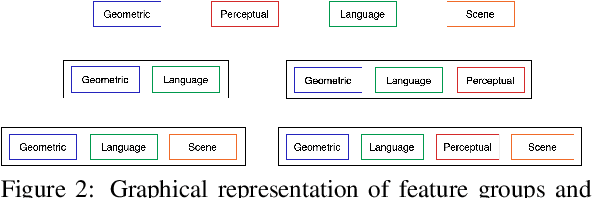
Vision and language tasks such as Visual Relation Detection and Visual Question Answering benefit from semantic features that afford proper grounding of language. The 3D depth of objects depicted in 2D images is one such feature. However it is very difficult to obtain accurate depth information without learning the appropriate features, which are scene dependent. The state of the art in this area are complex Neural Network models trained on stereo image data to predict depth per pixel. Fortunately, in some tasks, its only the relative depth between objects that is required. In this paper the extent to which semantic features can predict course relative depth is investigated. The problem is casted as a classification one and geometrical features based on object bounding boxes, object labels and scene attributes are computed and used as inputs to pattern recognition models to predict relative depth. i.e behind, in-front and neutral. The results are compared to those obtained from averaging the output of the monodepth neural network model, which represents the state-of-the art. An overall increase of 14% in relative depth accuracy over relative depth computed from the monodepth model derived results is achieved.