 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking AI Agents for Addressing Scientific Challenges Across Scales
Jun 10, 2026AI agents are increasingly being developed to accelerate scientific discovery, yet their practical capabilities in real research settings remain poorly understood. Existing benchmarks for AI agents rarely capture the complexity, heterogeneity, and extended reasoning required by scientific work, whereas benchmarks for scientific tasks often reduce research to static, direct problems and provide limited support for interactive evaluation. Here, we introduce SciAgentArena, a systematic benchmark for evaluating AI agents in real-world scientific research scenarios drawn from emerging needs across multiple domains. SciAgentArena comprises approximately 200 tasks with stepwise verification and an interactive, agent-agnostic environment for assessing diverse AI agents. Using this benchmark, we find that current agents can contribute effectively to well-specified data-analysis workflows, particularly when the task structure and evaluation criteria are clear. However, their performance remains uneven across scientific contexts: agents struggle to generate genuinely novel insights, sustain self-directed exploration, and formulate robust solutions for open-ended research questions. We further characterize common failure modes across agents and identify opportunities for improving their reliability, autonomy, and scientific reasoning. Together, SciAgentArena provides a practical framework for measuring progress in AI agents for science and for guiding the design of future agents capable of addressing complex scientific challenges. Full codes, tasks, and datasets can be accessed via this link: https://sciagentarena.github.io/.
AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
May 27, 2026Scientific research proceeds through iterative cycles of hypothesis generation, experiment design, execution, and revision. AI agents can automate parts of this process, but existing approaches typically follow a single research trajectory or coordinate through a central planner with fixed objectives. As a result, they struggle to sustain parallel exploration, adapt as experimental evidence changes, or preserve knowledge of failed directions over long-running experiments. We introduce AutoScientists, a decentralized team of AI agents for long-running computational scientific experimentation. Agents interpret a shared experimental state, self-organize into teams around promising hypotheses, critique proposals before using experimental compute, and share successes and failures to reduce redundant exploration. Under matched experimental budgets, AutoScientists improves over prior AI agents across biomedical machine learning, language-model training optimization, and protein fitness prediction. On BioML-Bench, spanning biomedical imaging, protein engineering, single-cell omics, and drug discovery, AutoScientists achieves a mean leaderboard percentile of 74.4% across 24 tasks, improving over the strongest AI agent by +8.33%. On GPT training optimization, AutoScientists reaches a target validation bits-per-byte 1.9x faster than Autoresearch and continues discovering improvements from a starting champion where the single-agent approach finds none (7 vs. 0 accepted improvements). On ProteinGym fitness prediction, AutoScientists discovers a method for ACE2-Spike binding that improves over the current state-of-the-art model by +12.5% in Spearman correlation. Applied without modification across all 217 ProteinGym assays, the same method improves over the prior state of the art by +6.5% (Spearman correlation).
Evaluating Relational Reasoning in LLMs with REL
Apr 14, 2026Relational reasoning is the ability to infer relations that jointly bind multiple entities, attributes, or variables. This ability is central to scientific reasoning, but existing evaluations of relational reasoning in large language models often focus on structured inputs such as tables, graphs, or synthetic tasks, and do not isolate the difficulty introduced by higher-arity relational binding. We study this problem through the lens of Relational Complexity (RC), which we define as the minimum number of independent entities or operands that must be simultaneously bound to apply a relation. RC provides a principled way to vary reasoning difficulty while controlling for confounders such as input size, vocabulary, and representational choices. Building on RC, we introduce REL, a generative benchmark framework spanning algebra, chemistry, and biology that varies RC within each domain. Across frontier LLMs, performance degrades consistently and monotonically as RC increases, even when the total number of entities is held fixed. This failure mode persists with increased test-time compute and in-context learning, suggesting a limitation tied to the arity of the required relational binding rather than to insufficient inference steps or lack of exposure to examples. Our results identify a regime of higher-arity reasoning in which current models struggle, and motivate re-examining benchmarks through the lens of relational complexity.
Tokenizing Loops of Antibodies
Sep 10, 2025



The complementarity-determining regions of antibodies are loop structures that are key to their interactions with antigens, and of high importance to the design of novel biologics. Since the 1980s, categorizing the diversity of CDR structures into canonical clusters has enabled the identification of key structural motifs of antibodies. However, existing approaches have limited coverage and cannot be readily incorporated into protein foundation models. Here we introduce ImmunoGlobulin LOOp Tokenizer, Igloo, a multimodal antibody loop tokenizer that encodes backbone dihedral angles and sequence. Igloo is trained using a contrastive learning objective to map loops with similar backbone dihedral angles closer together in latent space. Igloo can efficiently retrieve the closest matching loop structures from a structural antibody database, outperforming existing methods on identifying similar H3 loops by 5.9\%. Igloo assigns tokens to all loops, addressing the limited coverage issue of canonical clusters, while retaining the ability to recover canonical loop conformations. To demonstrate the versatility of Igloo tokens, we show that they can be incorporated into protein language models with IglooLM and IglooALM. On predicting binding affinity of heavy chain variants, IglooLM outperforms the base protein language model on 8 out of 10 antibody-antigen targets. Additionally, it is on par with existing state-of-the-art sequence-based and multimodal protein language models, performing comparably to models with $7\times$ more parameters. IglooALM samples antibody loops which are diverse in sequence and more consistent in structure than state-of-the-art antibody inverse folding models. Igloo demonstrates the benefit of introducing multimodal tokens for antibody loops for encoding the diverse landscape of antibody loops, improving protein foundation models, and for antibody CDR design.
Empowering Biomedical Discovery with AI Agents
Apr 03, 2024



We envision 'AI scientists' as systems capable of skeptical learning and reasoning that empower biomedical research through collaborative agents that integrate machine learning tools with experimental platforms. Rather than taking humans out of the discovery process, biomedical AI agents combine human creativity and expertise with AI's ability to analyze large datasets, navigate hypothesis spaces, and execute repetitive tasks. AI agents are proficient in a variety of tasks, including self-assessment and planning of discovery workflows. These agents use large language models and generative models to feature structured memory for continual learning and use machine learning tools to incorporate scientific knowledge, biological principles, and theories. AI agents can impact areas ranging from hybrid cell simulation, programmable control of phenotypes, and the design of cellular circuits to the development of new therapies.
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems
Jul 17, 2023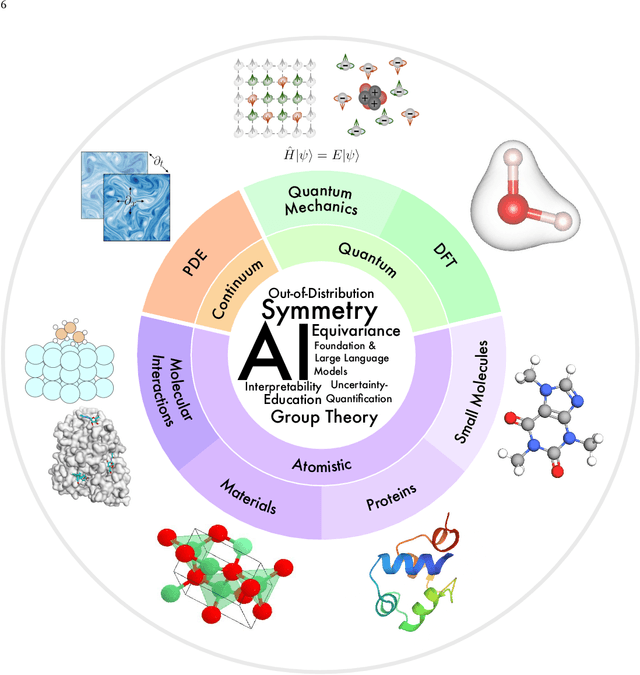



Advances in artificial intelligence (AI) are fueling a new paradigm of discoveries in natural sciences. Today, AI has started to advance natural sciences by improving, accelerating, and enabling our understanding of natural phenomena at a wide range of spatial and temporal scales, giving rise to a new area of research known as AI for science (AI4Science). Being an emerging research paradigm, AI4Science is unique in that it is an enormous and highly interdisciplinary area. Thus, a unified and technical treatment of this field is needed yet challenging. This paper aims to provide a technically thorough account of a subarea of AI4Science; namely, AI for quantum, atomistic, and continuum systems. These areas aim at understanding the physical world from the subatomic (wavefunctions and electron density), atomic (molecules, proteins, materials, and interactions), to macro (fluids, climate, and subsurface) scales and form an important subarea of AI4Science. A unique advantage of focusing on these areas is that they largely share a common set of challenges, thereby allowing a unified and foundational treatment. A key common challenge is how to capture physics first principles, especially symmetries, in natural systems by deep learning methods. We provide an in-depth yet intuitive account of techniques to achieve equivariance to symmetry transformations. We also discuss other common technical challenges, including explainability, out-of-distribution generalization, knowledge transfer with foundation and large language models, and uncertainty quantification. To facilitate learning and education, we provide categorized lists of resources that we found to be useful. We strive to be thorough and unified and hope this initial effort may trigger more community interests and efforts to further advance AI4Science.