 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling multispecific antibody function with graph neural networks
Jan 30, 2026Multispecific antibodies offer transformative therapeutic potential by engaging multiple epitopes simultaneously, yet their efficacy is an emergent property governed by complex molecular architectures. Rational design is often bottlenecked by the inability to predict how subtle changes in domain topology influence functional outcomes, a challenge exacerbated by the scarcity of comprehensive experimental data. Here, we introduce a computational framework to address part of this gap. First, we present a generative method for creating large-scale, realistic synthetic functional landscapes that capture non-linear interactions where biological activity depends on domain connectivity. Second, we propose a graph neural network architecture that explicitly encodes these topological constraints, distinguishing between format configurations that appear identical to sequence-only models. We demonstrate that this model, trained on synthetic landscapes, recapitulates complex functional properties and, via transfer learning, has the potential to achieve high predictive accuracy on limited biological datasets. We showcase the model's utility by optimizing trade-offs between efficacy and toxicity in trispecific T-cell engagers and retrieving optimal common light chains. This work provides a robust benchmarking environment for disentangling the combinatorial complexity of multispecifics, accelerating the design of next-generation therapeutics.
Tokenizing Loops of Antibodies
Sep 10, 2025



The complementarity-determining regions of antibodies are loop structures that are key to their interactions with antigens, and of high importance to the design of novel biologics. Since the 1980s, categorizing the diversity of CDR structures into canonical clusters has enabled the identification of key structural motifs of antibodies. However, existing approaches have limited coverage and cannot be readily incorporated into protein foundation models. Here we introduce ImmunoGlobulin LOOp Tokenizer, Igloo, a multimodal antibody loop tokenizer that encodes backbone dihedral angles and sequence. Igloo is trained using a contrastive learning objective to map loops with similar backbone dihedral angles closer together in latent space. Igloo can efficiently retrieve the closest matching loop structures from a structural antibody database, outperforming existing methods on identifying similar H3 loops by 5.9\%. Igloo assigns tokens to all loops, addressing the limited coverage issue of canonical clusters, while retaining the ability to recover canonical loop conformations. To demonstrate the versatility of Igloo tokens, we show that they can be incorporated into protein language models with IglooLM and IglooALM. On predicting binding affinity of heavy chain variants, IglooLM outperforms the base protein language model on 8 out of 10 antibody-antigen targets. Additionally, it is on par with existing state-of-the-art sequence-based and multimodal protein language models, performing comparably to models with $7\times$ more parameters. IglooALM samples antibody loops which are diverse in sequence and more consistent in structure than state-of-the-art antibody inverse folding models. Igloo demonstrates the benefit of introducing multimodal tokens for antibody loops for encoding the diverse landscape of antibody loops, improving protein foundation models, and for antibody CDR design.
Assessing interaction recovery of predicted protein-ligand poses
Sep 30, 2024The field of protein-ligand pose prediction has seen significant advances in recent years, with machine learning-based methods now being commonly used in lieu of classical docking methods or even to predict all-atom protein-ligand complex structures. Most contemporary studies focus on the accuracy and physical plausibility of ligand placement to determine pose quality, often neglecting a direct assessment of the interactions observed with the protein. In this work, we demonstrate that ignoring protein-ligand interaction fingerprints can lead to overestimation of model performance, most notably in recent protein-ligand cofolding models which often fail to recapitulate key interactions.
ABodyBuilder3: Improved and scalable antibody structure predictions
May 31, 2024
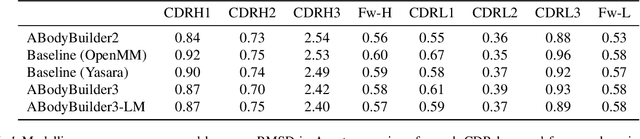


Accurate prediction of antibody structure is a central task in the design and development of monoclonal antibodies, notably to understand both their developability and their binding properties. In this article, we introduce ABodyBuilder3, an improved and scalable antibody structure prediction model based on ImmuneBuilder. We achieve a new state-of-the-art accuracy in the modelling of CDR loops by leveraging language model embeddings, and show how predicted structures can be further improved through careful relaxation strategies. Finally, we incorporate a predicted Local Distance Difference Test into the model output to allow for a more accurate estimation of uncertainties.
De novo antibody design with SE diffusion
May 13, 2024



We introduce IgDiff, an antibody variable domain diffusion model based on a general protein backbone diffusion framework which was extended to handle multiple chains. Assessing the designability and novelty of the structures generated with our model, we find that IgDiff produces highly designable antibodies that can contain novel binding regions. The backbone dihedral angles of sampled structures show good agreement with a reference antibody distribution. We verify these designed antibodies experimentally and find that all express with high yield. Finally, we compare our model with a state-of-the-art generative backbone diffusion model on a range of antibody design tasks, such as the design of the complementarity determining regions or the pairing of a light chain to an existing heavy chain, and show improved properties and designability.
Large scale paired antibody language models
Mar 26, 2024



Antibodies are proteins produced by the immune system that can identify and neutralise a wide variety of antigens with high specificity and affinity, and constitute the most successful class of biotherapeutics. With the advent of next-generation sequencing, billions of antibody sequences have been collected in recent years, though their application in the design of better therapeutics has been constrained by the sheer volume and complexity of the data. To address this challenge, we present IgBert and IgT5, the best performing antibody-specific language models developed to date which can consistently handle both paired and unpaired variable region sequences as input. These models are trained comprehensively using the more than two billion unpaired sequences and two million paired sequences of light and heavy chains present in the Observed Antibody Space dataset. We show that our models outperform existing antibody and protein language models on a diverse range of design and regression tasks relevant to antibody engineering. This advancement marks a significant leap forward in leveraging machine learning, large scale data sets and high-performance computing for enhancing antibody design for therapeutic development.
Inverse folding for antibody sequence design using deep learning
Oct 30, 2023We consider the problem of antibody sequence design given 3D structural information. Building on previous work, we propose a fine-tuned inverse folding model that is specifically optimised for antibody structures and outperforms generic protein models on sequence recovery and structure robustness when applied on antibodies, with notable improvement on the hypervariable CDR-H3 loop. We study the canonical conformations of complementarity-determining regions and find improved encoding of these loops into known clusters. Finally, we consider the applications of our model to drug discovery and binder design and evaluate the quality of proposed sequences using physics-based methods.
Multilingual End to End Entity Linking
Jun 15, 2023



Entity Linking is one of the most common Natural Language Processing tasks in practical applications, but so far efficient end-to-end solutions with multilingual coverage have been lacking, leading to complex model stacks. To fill this gap, we release and open source BELA, the first fully end-to-end multilingual entity linking model that efficiently detects and links entities in texts in any of 97 languages. We provide here a detailed description of the model and report BELA's performance on four entity linking datasets covering high- and low-resource languages.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023



Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.
Leveraging universality of jet taggers through transfer learning
Mar 11, 2022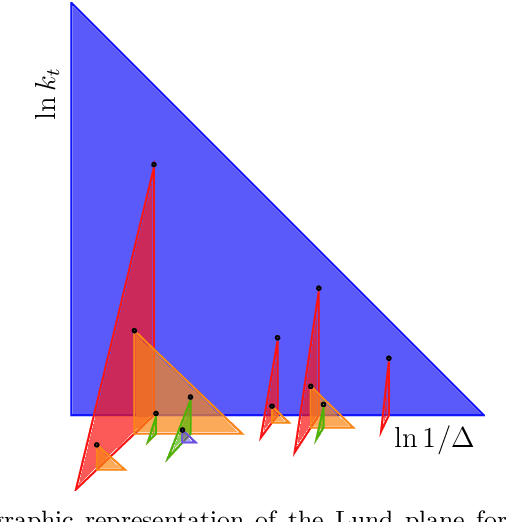
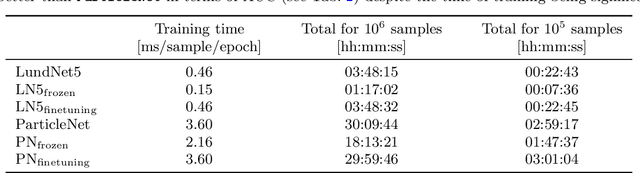
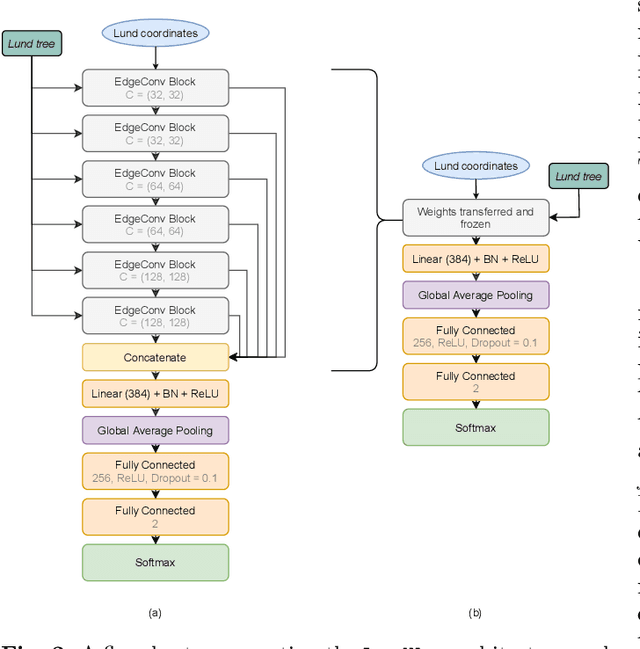

A significant challenge in the tagging of boosted objects via machine-learning technology is the prohibitive computational cost associated with training sophisticated models. Nevertheless, the universality of QCD suggests that a large amount of the information learnt in the training is common to different physical signals and experimental setups. In this article, we explore the use of transfer learning techniques to develop fast and data-efficient jet taggers that leverage such universality. We consider the graph neural networks LundNet and ParticleNet, and introduce two prescriptions to transfer an existing tagger into a new signal based either on fine-tuning all the weights of a model or alternatively on freezing a fraction of them. In the case of $W$-boson and top-quark tagging, we find that one can obtain reliable taggers using an order of magnitude less data with a corresponding speed-up of the training process. Moreover, while keeping the size of the training data set fixed, we observe a speed-up of the training by up to a factor of three. This offers a promising avenue to facilitate the use of such tools in collider physics experiments.