 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAug: Retargeting behaviors to unseen situations via Generative Augmentation
Feb 22, 2023



Robot learning methods have the potential for widespread generalization across tasks, environments, and objects. However, these methods require large diverse datasets that are expensive to collect in real-world robotics settings. For robot learning to generalize, we must be able to leverage sources of data or priors beyond the robot's own experience. In this work, we posit that image-text generative models, which are pre-trained on large corpora of web-scraped data, can serve as such a data source. We show that despite these generative models being trained on largely non-robotics data, they can serve as effective ways to impart priors into the process of robot learning in a way that enables widespread generalization. In particular, we show how pre-trained generative models can serve as effective tools for semantically meaningful data augmentation. By leveraging these pre-trained models for generating appropriate "semantic" data augmentations, we propose a system GenAug that is able to significantly improve policy generalization. We apply GenAug to tabletop manipulation tasks, showing the ability to re-target behavior to novel scenarios, while only requiring marginal amounts of real-world data. We demonstrate the efficacy of this system on a number of object manipulation problems in the real world, showing a 40% improvement in generalization to novel scenes and objects.
Guiding Pretraining in Reinforcement Learning with Large Language Models
Feb 13, 2023



Reinforcement learning algorithms typically struggle in the absence of a dense, well-shaped reward function. Intrinsically motivated exploration methods address this limitation by rewarding agents for visiting novel states or transitions, but these methods offer limited benefits in large environments where most discovered novelty is irrelevant for downstream tasks. We describe a method that uses background knowledge from text corpora to shape exploration. This method, called ELLM (Exploring with LLMs) rewards an agent for achieving goals suggested by a language model prompted with a description of the agent's current state. By leveraging large-scale language model pretraining, ELLM guides agents toward human-meaningful and plausibly useful behaviors without requiring a human in the loop. We evaluate ELLM in the Crafter game environment and the Housekeep robotic simulator, showing that ELLM-trained agents have better coverage of common-sense behaviors during pretraining and usually match or improve performance on a range of downstream tasks.
Wobble control of a pendulum actuated spherical robot
Jan 16, 2023



Spherical robots can conduct surveillance in hostile, cluttered environments without being damaged, as their protective shell can safely house sensors such as cameras. However, lateral oscillations, also known as wobble, occur when these sphere-shaped robots operate at low speeds, leading to shaky camera feedback. These oscillations in a pendulum-actuated spherical robot are caused by the coupling between the forward and steering motions due to nonholonomic constraints. Designing a controller to limit wobbling in these robots is challenging due to their underactuated nature. We propose a model-based controller to navigate a pendulum-actuated spherical robot using wobble-free turning maneuvers consisting of circular arcs and straight lines. The model is developed using Lagrange-D'Alembert equations and accounts for the coupled forward and steering motions. The model is further analyzed to derive expressions for radius of curvature, precession rate, wobble amplitude, and wobble frequency during circular motions. Finally, we design an input-output feedback linearization-based controller to control the robot's heading direction and wobble. Overall, the proposed controller enables a teleoperator to command a specific forward velocity and pendulum angle as per the desired turning radius while limiting the robot's lateral oscillations to enhance the quality of camera feedback.
Pendulum Actuated Spherical Robot: Dynamic Modeling & Analysis for Wobble & Precession
Jan 14, 2023



A spherical robot has many practical advantages as the entire electronics are protected within a hull and can be carried easily by any Unmanned Aerial Vehicle (UAV). However, its use is limited due to finding mounts for sensors. Pendulum actuated spherical robot provides space for mounting sensors at the yoke. We study the non-linear dynamics of a pendulum-actuated spherical robot to analyze the dynamics of internal assembly (yoke) for mounting sensors. For such robots, we provide a coupled dynamic model that takes care of the relationship between forward and sideways motion. We further demonstrate the effects of wobbling and precession captured by our model when the bot is controlled to execute a turning maneuver while moving with a moderate forward velocity, a practical situation encountered by spherical robots moving in an indoor setting. A simulation setup based on the developed model provides visualization of the spherical robot motion.
Dexterous Manipulation from Images: Autonomous Real-World RL via Substep Guidance
Dec 19, 2022



Complex and contact-rich robotic manipulation tasks, particularly those that involve multi-fingered hands and underactuated object manipulation, present a significant challenge to any control method. Methods based on reinforcement learning offer an appealing choice for such settings, as they can enable robots to learn to delicately balance contact forces and dexterously reposition objects without strong modeling assumptions. However, running reinforcement learning on real-world dexterous manipulation systems often requires significant manual engineering. This negates the benefits of autonomous data collection and ease of use that reinforcement learning should in principle provide. In this paper, we describe a system for vision-based dexterous manipulation that provides a "programming-free" approach for users to define new tasks and enable robots with complex multi-fingered hands to learn to perform them through interaction. The core principle underlying our system is that, in a vision-based setting, users should be able to provide high-level intermediate supervision that circumvents challenges in teleoperation or kinesthetic teaching which allow a robot to not only learn a task efficiently but also to autonomously practice. Our system includes a framework for users to define a final task and intermediate sub-tasks with image examples, a reinforcement learning procedure that learns the task autonomously without interventions, and experimental results with a four-finger robotic hand learning multi-stage object manipulation tasks directly in the real world, without simulation, manual modeling, or reward engineering.
JAX-Accelerated Neuroevolution of Physics-informed Neural Networks: Benchmarks and Experimental Results
Dec 15, 2022



This paper introduces the use of evolutionary algorithms for solving differential equations. The solution is obtained by optimizing a deep neural network whose loss function is defined by the residual terms from the differential equations. Recent studies have used stochastic gradient descent (SGD) variants to train these physics-informed neural networks (PINNs), but these methods can struggle to find accurate solutions due to optimization challenges. When solving differential equations, it is important to find the globally optimum parameters of the network, rather than just finding a solution that works well during training. SGD only searches along a single gradient direction, so it may not be the best approach for training PINNs with their accompanying complex optimization landscapes. In contrast, evolutionary algorithms perform a parallel exploration of different solutions in order to avoid getting stuck in local optima and can potentially find more accurate solutions. However, evolutionary algorithms can be slow, which can make them difficult to use in practice. To address this, we provide a set of five benchmark problems with associated performance metrics and baseline results to support the development of evolutionary algorithms for enhanced PINN training. As a baseline, we evaluate the performance and speed of using the widely adopted Covariance Matrix Adaptation Evolution Strategy (CMA-ES) for solving PINNs. We provide the loss and training time for CMA-ES run on TensorFlow, and CMA-ES and SGD run on JAX (with GPU acceleration) for the five benchmark problems. Our results show that JAX-accelerated evolutionary algorithms, particularly CMA-ES, can be a useful approach for solving differential equations. We hope that our work will support the exploration and development of alternative optimization algorithms for the complex task of optimizing PINNs.
Forged Image Detection using SOTA Image Classification Deep Learning Methods for Image Forensics with Error Level Analysis
Nov 28, 2022The advancement in the area of computer vision has been brought using deep learning mechanisms. Image Forensics is one of the major areas of computer vision application. Forgery of images is sub-category of image forensics and can be detected using Error Level Analysis. Using such images as an input, this can turn out to be a binary classification problem which can be leveraged using variations of convolutional neural networks. In this paper we perform transfer learning with state-of-the-art image classification models over error level analysis induced CASIA ITDE v.2 dataset. The algorithms used are VGG-19, Inception-V3, ResNet-152-V2, XceptionNet and EfficientNet-V2L with their respective methodologies and results.
Learning Robust Real-World Dexterous Grasping Policies via Implicit Shape Augmentation
Oct 24, 2022



Dexterous robotic hands have the capability to interact with a wide variety of household objects to perform tasks like grasping. However, learning robust real world grasping policies for arbitrary objects has proven challenging due to the difficulty of generating high quality training data. In this work, we propose a learning system (ISAGrasp) for leveraging a small number of human demonstrations to bootstrap the generation of a much larger dataset containing successful grasps on a variety of novel objects. Our key insight is to use a correspondence-aware implicit generative model to deform object meshes and demonstrated human grasps in order to generate a diverse dataset of novel objects and successful grasps for supervised learning, while maintaining semantic realism. We use this dataset to train a robust grasping policy in simulation which can be deployed in the real world. We demonstrate grasping performance with a four-fingered Allegro hand in both simulation and the real world, and show this method can handle entirely new semantic classes and achieve a 79% success rate on grasping unseen objects in the real world.
Unpacking Reward Shaping: Understanding the Benefits of Reward Engineering on Sample Complexity
Oct 18, 2022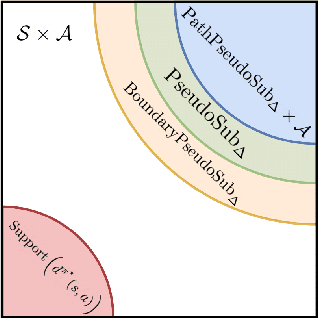

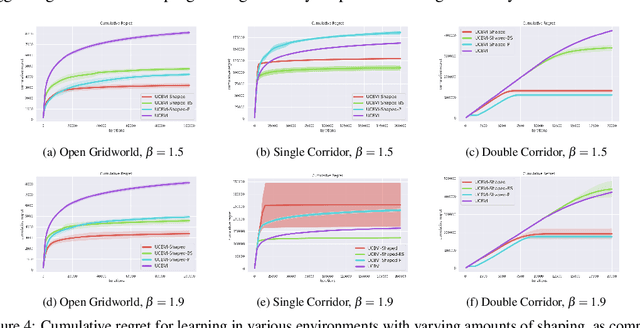
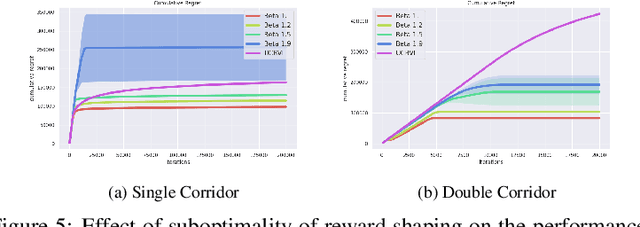
Reinforcement learning provides an automated framework for learning behaviors from high-level reward specifications, but in practice the choice of reward function can be crucial for good results -- while in principle the reward only needs to specify what the task is, in reality practitioners often need to design more detailed rewards that provide the agent with some hints about how the task should be completed. The idea of this type of ``reward-shaping'' has been often discussed in the literature, and is often a critical part of practical applications, but there is relatively little formal characterization of how the choice of reward shaping can yield benefits in sample complexity. In this work, we build on the framework of novelty-based exploration to provide a simple scheme for incorporating shaped rewards into RL along with an analysis tool to show that particular choices of reward shaping provably improve sample efficiency. We characterize the class of problems where these gains are expected to be significant and show how this can be connected to practical algorithms in the literature. We confirm that these results hold in practice in an experimental evaluation, providing an insight into the mechanisms through which reward shaping can significantly improve the complexity of reinforcement learning while retaining asymptotic performance.
Distributionally Adaptive Meta Reinforcement Learning
Oct 06, 2022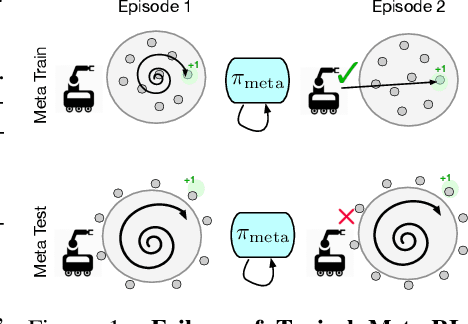

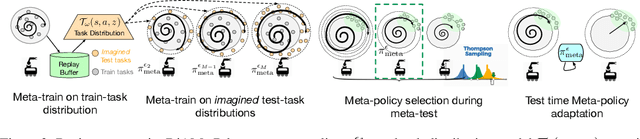
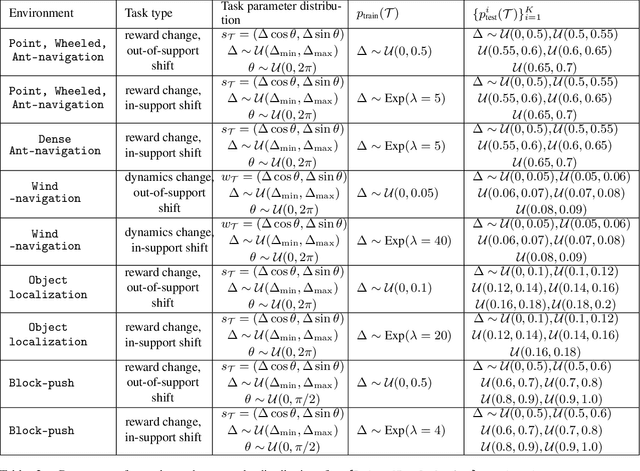
Meta-reinforcement learning algorithms provide a data-driven way to acquire policies that quickly adapt to many tasks with varying rewards or dynamics functions. However, learned meta-policies are often effective only on the exact task distribution on which they were trained and struggle in the presence of distribution shift of test-time rewards or transition dynamics. In this work, we develop a framework for meta-RL algorithms that are able to behave appropriately under test-time distribution shifts in the space of tasks. Our framework centers on an adaptive approach to distributional robustness that trains a population of meta-policies to be robust to varying levels of distribution shift. When evaluated on a potentially shifted test-time distribution of tasks, this allows us to choose the meta-policy with the most appropriate level of robustness, and use it to perform fast adaptation. We formally show how our framework allows for improved regret under distribution shift, and empirically show its efficacy on simulated robotics problems under a wide range of distribution shifts.