 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMURAL: Meta-Learning Uncertainty-Aware Rewards for Outcome-Driven Reinforcement Learning
Paper and Code
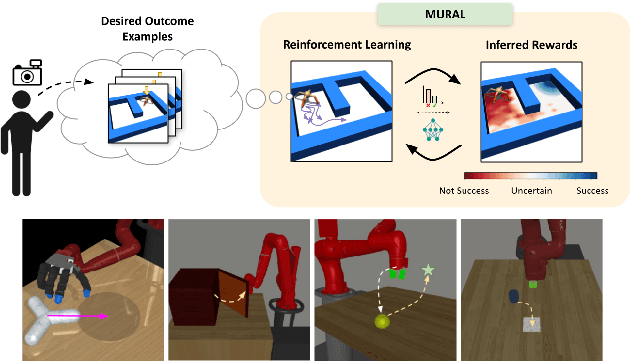
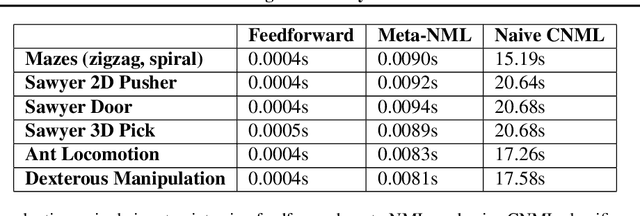

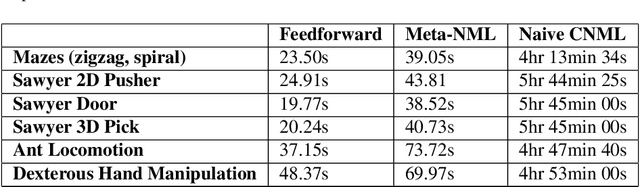
Exploration in reinforcement learning is a challenging problem: in the worst case, the agent must search for high-reward states that could be hidden anywhere in the state space. Can we define a more tractable class of RL problems, where the agent is provided with examples of successful outcomes? In this problem setting, the reward function can be obtained automatically by training a classifier to categorize states as successful or not. If trained properly, such a classifier can provide a well-shaped objective landscape that both promotes progress toward good states and provides a calibrated exploration bonus. In this work, we show that an uncertainty aware classifier can solve challenging reinforcement learning problems by both encouraging exploration and provided directed guidance towards positive outcomes. We propose a novel mechanism for obtaining these calibrated, uncertainty-aware classifiers based on an amortized technique for computing the normalized maximum likelihood (NML) distribution. To make this tractable, we propose a novel method for computing the NML distribution by using meta-learning. We show that the resulting algorithm has a number of intriguing connections to both count-based exploration methods and prior algorithms for learning reward functions, while also providing more effective guidance towards the goal. We demonstrate that our algorithm solves a number of challenging navigation and robotic manipulation tasks which prove difficult or impossible for prior methods.