 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Floorplan Reconstruction
Dec 31, 2020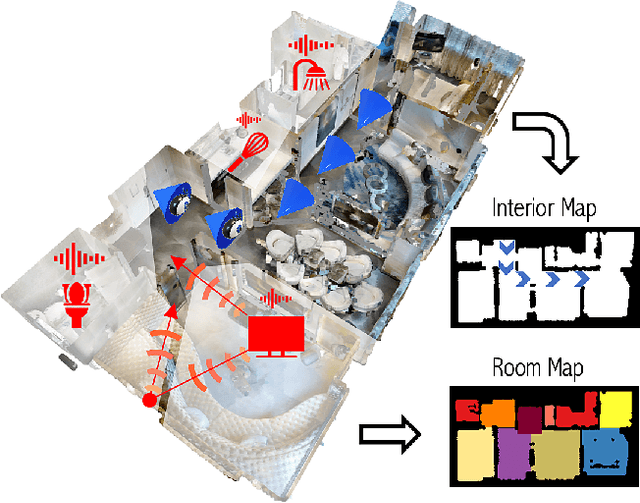
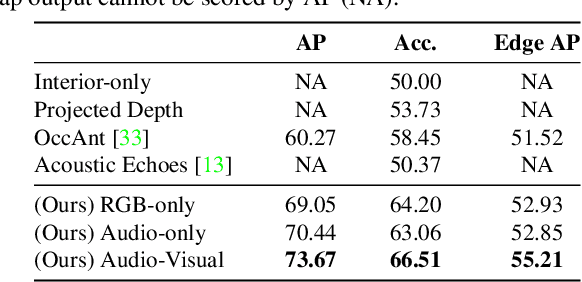
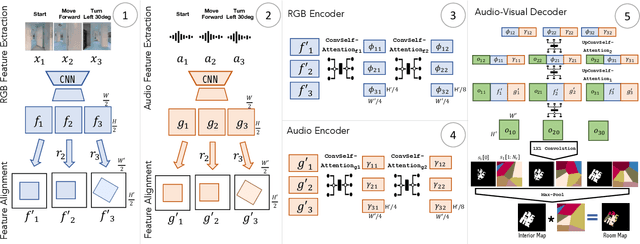
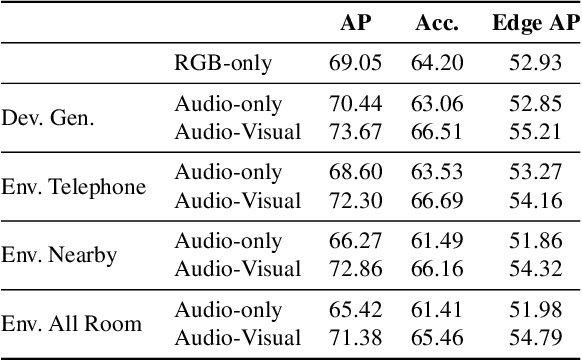
Given only a few glimpses of an environment, how much can we infer about its entire floorplan? Existing methods can map only what is visible or immediately apparent from context, and thus require substantial movements through a space to fully map it. We explore how both audio and visual sensing together can provide rapid floorplan reconstruction from limited viewpoints. Audio not only helps sense geometry outside the camera's field of view, but it also reveals the existence of distant freespace (e.g., a dog barking in another room) and suggests the presence of rooms not visible to the camera (e.g., a dishwasher humming in what must be the kitchen to the left). We introduce AV-Map, a novel multi-modal encoder-decoder framework that reasons jointly about audio and vision to reconstruct a floorplan from a short input video sequence. We train our model to predict both the interior structure of the environment and the associated rooms' semantic labels. Our results on 85 large real-world environments show the impact: with just a few glimpses spanning 26% of an area, we can estimate the whole area with 66% accuracy -- substantially better than the state of the art approach for extrapolating visual maps.
Neural Closure Models for Dynamical Systems
Dec 27, 2020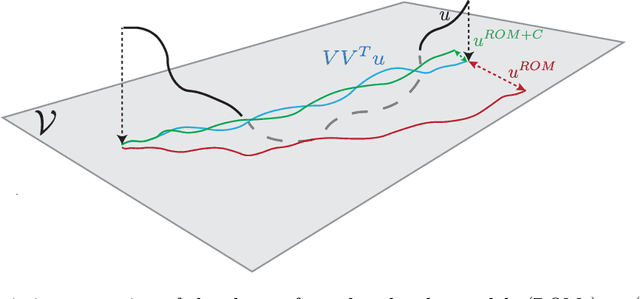
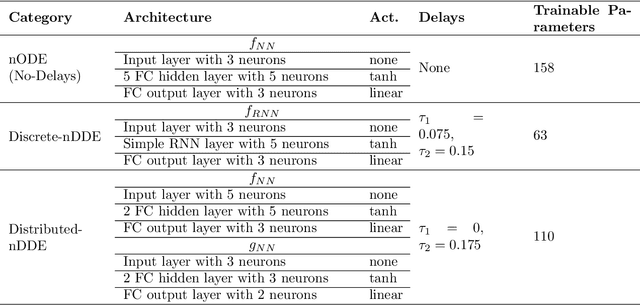
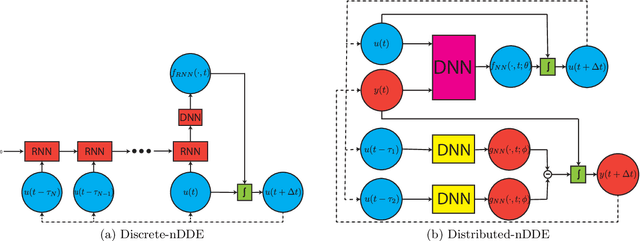
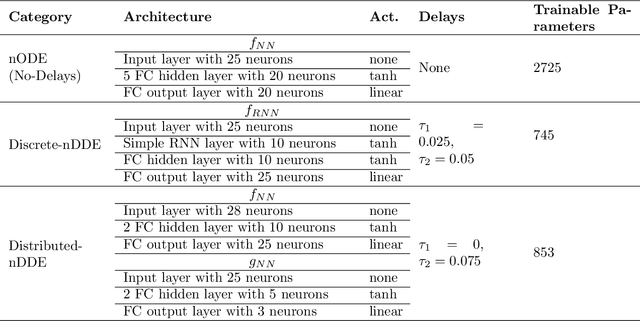
Complex dynamical systems are used for predictions in many applications. Because of computational costs, models are however often truncated, coarsened, or aggregated. As the neglected and unresolved terms along with their interactions with the resolved ones become important, the usefulness of model predictions diminishes. We develop a novel, versatile, and rigorous methodology to learn non-Markovian closure parameterizations for low-fidelity models using data from high-fidelity simulations. The new "neural closure models" augment low-fidelity models with neural delay differential equations (nDDEs), motivated by the Mori-Zwanzig formulation and the inherent delays in natural dynamical systems. We demonstrate that neural closures efficiently account for truncated modes in reduced-order-models, capture the effects of subgrid-scale processes in coarse models, and augment the simplification of complex biochemical models. We show that using non-Markovian over Markovian closures improves long-term accuracy and requires smaller networks. We provide adjoint equation derivations and network architectures needed to efficiently implement the new discrete and distributed nDDEs. The performance of discrete over distributed delays in closure models is explained using information theory, and we observe an optimal amount of past information for a specified architecture. Finally, we analyze computational complexity and explain the limited additional cost due to neural closure models.
KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA
Dec 20, 2020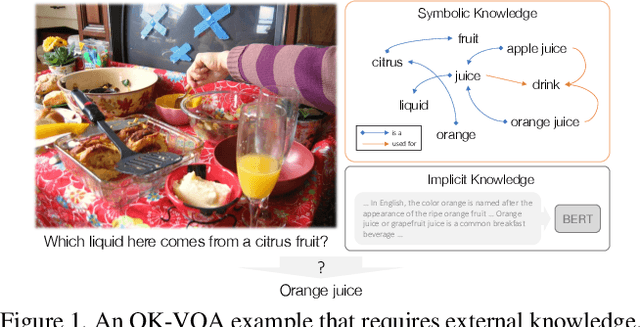



One of the most challenging question types in VQA is when answering the question requires outside knowledge not present in the image. In this work we study open-domain knowledge, the setting when the knowledge required to answer a question is not given/annotated, neither at training nor test time. We tap into two types of knowledge representations and reasoning. First, implicit knowledge which can be learned effectively from unsupervised language pre-training and supervised training data with transformer-based models. Second, explicit, symbolic knowledge encoded in knowledge bases. Our approach combines both - exploiting the powerful implicit reasoning of transformer models for answer prediction, and integrating symbolic representations from a knowledge graph, while never losing their explicit semantics to an implicit embedding. We combine diverse sources of knowledge to cover the wide variety of knowledge needed to solve knowledge-based questions. We show our approach, KRISP (Knowledge Reasoning with Implicit and Symbolic rePresentations), significantly outperforms state-of-the-art on OK-VQA, the largest available dataset for open-domain knowledge-based VQA. We show with extensive ablations that while our model successfully exploits implicit knowledge reasoning, the symbolic answer module which explicitly connects the knowledge graph to the answer vocabulary is critical to the performance of our method and generalizes to rare answers.
Neural Dynamic Policies for End-to-End Sensorimotor Learning
Dec 04, 2020
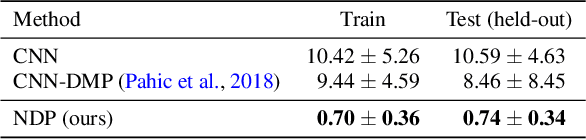
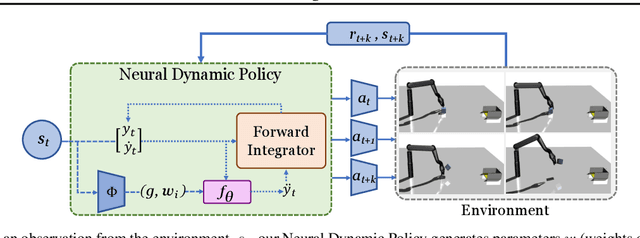

The current dominant paradigm in sensorimotor control, whether imitation or reinforcement learning, is to train policies directly in raw action spaces such as torque, joint angle, or end-effector position. This forces the agent to make decisions individually at each timestep in training, and hence, limits the scalability to continuous, high-dimensional, and long-horizon tasks. In contrast, research in classical robotics has, for a long time, exploited dynamical systems as a policy representation to learn robot behaviors via demonstrations. These techniques, however, lack the flexibility and generalizability provided by deep learning or reinforcement learning and have remained under-explored in such settings. In this work, we begin to close this gap and embed the structure of a dynamical system into deep neural network-based policies by reparameterizing action spaces via second-order differential equations. We propose Neural Dynamic Policies (NDPs) that make predictions in trajectory distribution space as opposed to prior policy learning methods where actions represent the raw control space. The embedded structure allows end-to-end policy learning for both reinforcement and imitation learning setups. We show that NDPs outperform the prior state-of-the-art in terms of either efficiency or performance across several robotic control tasks for both imitation and reinforcement learning setups. Project video and code are available at https://shikharbahl.github.io/neural-dynamic-policies/
Same Object, Different Grasps: Data and Semantic Knowledge for Task-Oriented Grasping
Nov 13, 2020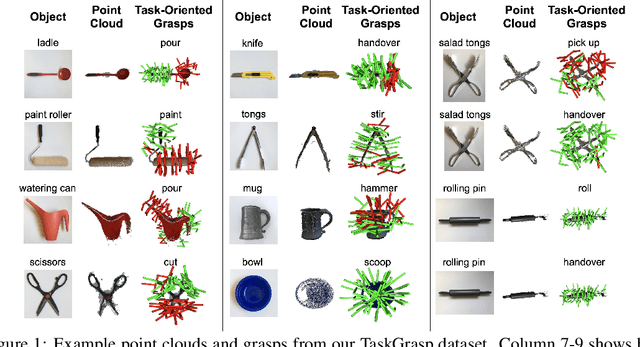

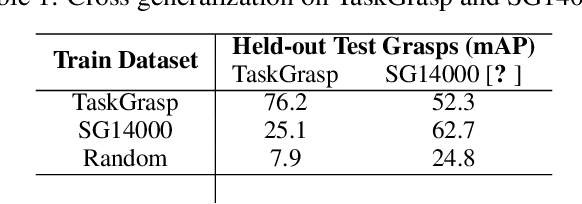

Despite the enormous progress and generalization in robotic grasping in recent years, existing methods have yet to scale and generalize task-oriented grasping to the same extent. This is largely due to the scale of the datasets both in terms of the number of objects and tasks studied. We address these concerns with the TaskGrasp dataset which is more diverse both in terms of objects and tasks, and an order of magnitude larger than previous datasets. The dataset contains 250K task-oriented grasps for 56 tasks and 191 objects along with their RGB-D information. We take advantage of this new breadth and diversity in the data and present the GCNGrasp framework which uses the semantic knowledge of objects and tasks encoded in a knowledge graph to generalize to new object instances, classes and even new tasks. Our framework shows a significant improvement of around 12% on held-out settings compared to baseline methods which do not use semantics. We demonstrate that our dataset and model are applicable for the real world by executing task-oriented grasps on a real robot on unknown objects. Code, data and supplementary video could be found at https://sites.google.com/view/taskgrasp
Transformers for One-Shot Visual Imitation
Nov 11, 2020
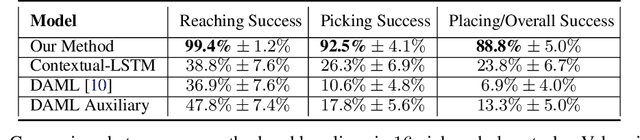
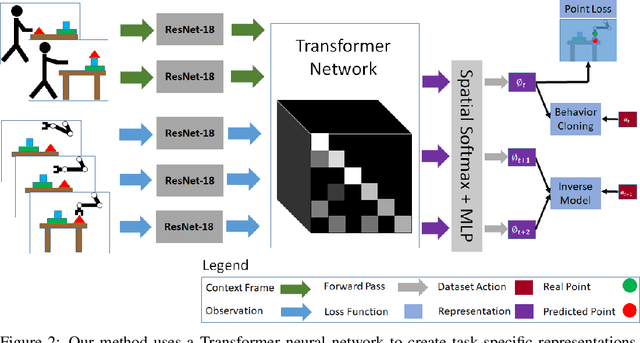

Humans are able to seamlessly visually imitate others, by inferring their intentions and using past experience to achieve the same end goal. In other words, we can parse complex semantic knowledge from raw video and efficiently translate that into concrete motor control. Is it possible to give a robot this same capability? Prior research in robot imitation learning has created agents which can acquire diverse skills from expert human operators. However, expanding these techniques to work with a single positive example during test time is still an open challenge. Apart from control, the difficulty stems from mismatches between the demonstrator and robot domains. For example, objects may be placed in different locations (e.g. kitchen layouts are different in every house). Additionally, the demonstration may come from an agent with different morphology and physical appearance (e.g. human), so one-to-one action correspondences are not available. This paper investigates techniques which allow robots to partially bridge these domain gaps, using their past experience. A neural network is trained to mimic ground truth robot actions given context video from another agent, and must generalize to unseen task instances when prompted with new videos during test time. We hypothesize that our policy representations must be both context driven and dynamics aware in order to perform these tasks. These assumptions are baked into the neural network using the Transformers attention mechanism and a self-supervised inverse dynamics loss. Finally, we experimentally determine that our method accomplishes a $\sim 2$x improvement in terms of task success rate over prior baselines in a suite of one-shot manipulation tasks.
Ask Your Humans: Using Human Instructions to Improve Generalization in Reinforcement Learning
Nov 01, 2020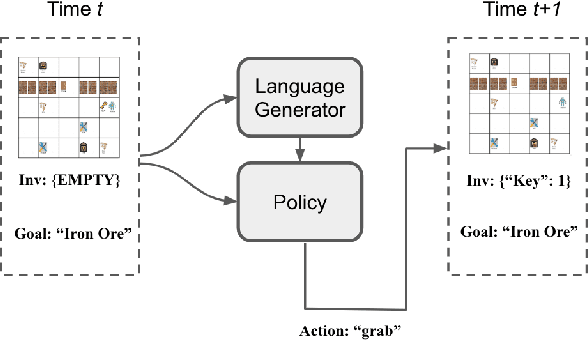
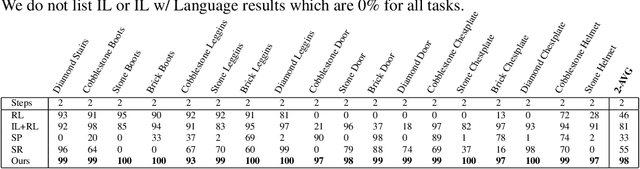
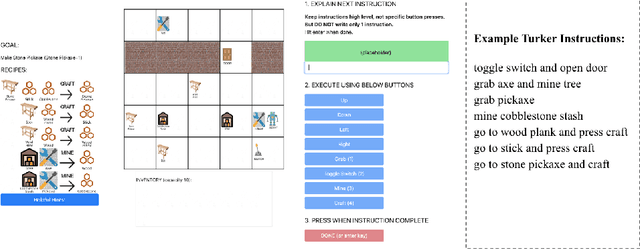

Complex, multi-task problems have proven to be difficult to solve efficiently in a sparse-reward reinforcement learning setting. In order to be sample efficient, multi-task learning requires reuse and sharing of low-level policies. To facilitate the automatic decomposition of hierarchical tasks, we propose the use of step-by-step human demonstrations in the form of natural language instructions and action trajectories. We introduce a dataset of such demonstrations in a crafting-based grid world. Our model consists of a high-level language generator and low-level policy, conditioned on language. We find that human demonstrations help solve the most complex tasks. We also find that incorporating natural language allows the model to generalize to unseen tasks in a zero-shot setting and to learn quickly from a few demonstrations. Generalization is not only reflected in the actions of the agent, but also in the generated natural language instructions in unseen tasks. Our approach also gives our trained agent interpretable behaviors because it is able to generate a sequence of high-level descriptions of its actions.
Visual Imitation Made Easy
Aug 11, 2020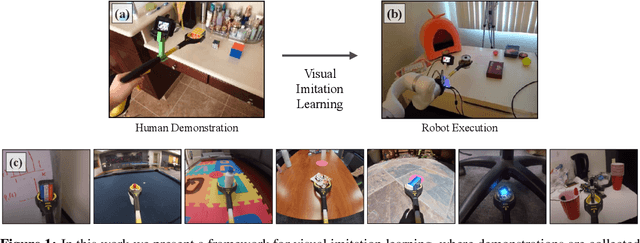



Visual imitation learning provides a framework for learning complex manipulation behaviors by leveraging human demonstrations. However, current interfaces for imitation such as kinesthetic teaching or teleoperation prohibitively restrict our ability to efficiently collect large-scale data in the wild. Obtaining such diverse demonstration data is paramount for the generalization of learned skills to novel scenarios. In this work, we present an alternate interface for imitation that simplifies the data collection process while allowing for easy transfer to robots. We use commercially available reacher-grabber assistive tools both as a data collection device and as the robot's end-effector. To extract action information from these visual demonstrations, we use off-the-shelf Structure from Motion (SfM) techniques in addition to training a finger detection network. We experimentally evaluate on two challenging tasks: non-prehensile pushing and prehensile stacking, with 1000 diverse demonstrations for each task. For both tasks, we use standard behavior cloning to learn executable policies from the previously collected offline demonstrations. To improve learning performance, we employ a variety of data augmentations and provide an extensive analysis of its effects. Finally, we demonstrate the utility of our interface by evaluating on real robotic scenarios with previously unseen objects and achieve a 87% success rate on pushing and a 62% success rate on stacking. Robot videos are available at https://dhiraj100892.github.io/Visual-Imitation-Made-Easy.
Demystifying Contrastive Self-Supervised Learning: Invariances, Augmentations and Dataset Biases
Jul 29, 2020

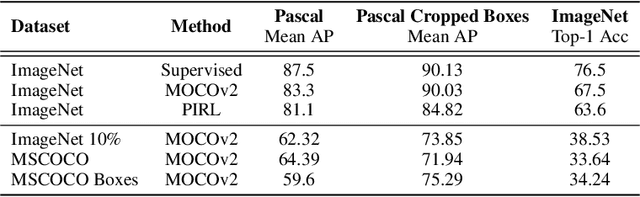
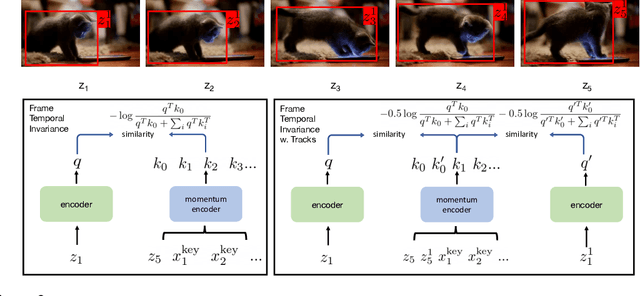
Self-supervised representation learning approaches have recently surpassed their supervised learning counterparts on downstream tasks like object detection and image classification. Somewhat mysteriously the recent gains in performance come from training instance classification models, treating each image and it's augmented versions as samples of a single class. In this work, we first present quantitative experiments to demystify these gains. We demonstrate that approaches like MOCO and PIRL learn occlusion-invariant representations. However, they fail to capture viewpoint and category instance invariance which are crucial components for object recognition. Second, we demonstrate that these approaches obtain further gains from access to a clean object-centric training dataset like Imagenet. Finally, we propose an approach to leverage unstructured videos to learn representations that possess higher viewpoint invariance. Our results show that the learned representations outperform MOCOv2 trained on the same data in terms of invariances encoded and the performance on downstream image classification and semantic segmentation tasks.
Implicit Mesh Reconstruction from Unannotated Image Collections
Jul 16, 2020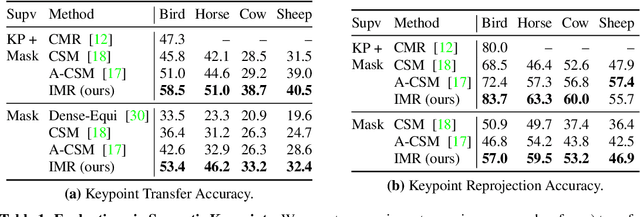
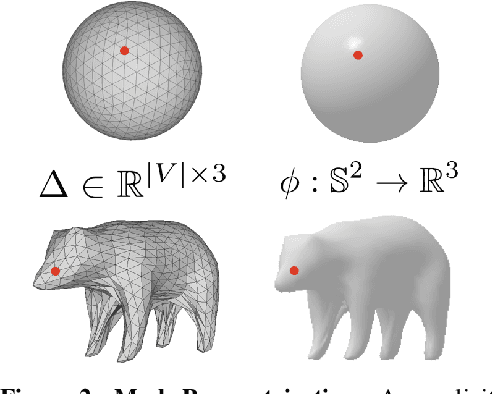
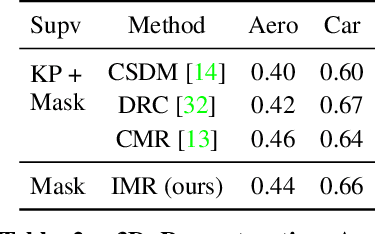
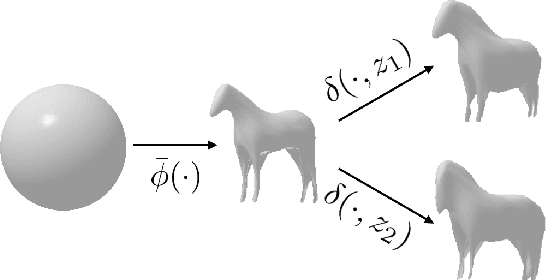
We present an approach to infer the 3D shape, texture, and camera pose for an object from a single RGB image, using only category-level image collections with foreground masks as supervision. We represent the shape as an image-conditioned implicit function that transforms the surface of a sphere to that of the predicted mesh, while additionally predicting the corresponding texture. To derive supervisory signal for learning, we enforce that: a) our predictions when rendered should explain the available image evidence, and b) the inferred 3D structure should be geometrically consistent with learned pixel to surface mappings. We empirically show that our approach improves over prior work that leverages similar supervision, and in fact performs competitively to methods that use stronger supervision. Finally, as our method enables learning with limited supervision, we qualitatively demonstrate its applicability over a set of about 30 object categories.